Kotlin DSL: Theory and Practice
Developing application tests is not the most pleasant thing. This process takes a long time, requires a lot of concentration and is extremely in demand. The Kotlin language provides a set of tools that makes it quite easy to build your own problem-oriented language (DSL). There is an experience when Kotlin DSL replaced builders and static methods for testing the resource planning module, which turned the addition of new tests and support for old ones from a routine into an exciting process.
In the course of the article we will examine all the main tools from the developer’s arsenal and how they can be combined to solve testing problems. We will make the journey from designing the Perfect Test to running the most approximate, clean and understandable test for the Kotlin-based resource planning system.
The article will be useful to practicing engineers, those who consider Kotlin as a language for comfortable writing compact tests, and those who want to improve the testing process in their project.
The article is based on the report of Ivan Osipov ( i_osipov ) at the JPoint conference. Further narration is conducted from his face. Ivan works as a programmer at Haulmont. The main product of the company is CUBA, a platform for developing enterprise and various web applications. Including on this platform are made and outsourcing projects, among which was recently a project in the field of education, in which Ivan was engaged in building a schedule for an educational institution. It so happened that for the last three years, Ivan somehow worked with the planners, and specifically in Haulmont during the year they are testing this very scheduler.
For those who want to run examples - keep a link to GitHub . Under the link you will find all the code that today we will parse, run and write with you. Open the code and go!

Today we will discuss:
Today I will talk in detail about the tools that we have in the language, I will show you several demos, and we will write the whole test from beginning to end. At the same time, I would like to be more objective, so I’ll tell you about some minuses that I identified for myself during development.
Let's start by talking about the scheduling module. So, the construction of the schedule takes place in several stages. Each of these steps must be tested separately. It should be understood that despite the fact that the stages are different, we have a common data model.

This process can be represented as follows: at the entrance there are some data with a general model, at the output - a schedule. The data is validated, filtered, and then training groups are built. This refers to the subject area of the schedule for an educational institution. On the basis of the constructed groups and on the basis of some other data, we post a lesson. Today we will talk only about the last stage - about the placement of classes.

A little about testing the scheduler.
First, as you already understood, the different stages should be tested separately. There is a more or less standard test run process: there is data initialization, there is a launch of the scheduler, there is a check of the results of this scheduler itself. There are a huge number of different business cases that need to be covered and different situations that need to be taken into account so that when creating a schedule these situations are also preserved.
A model is sometimes spreading, and in order to create a single entity, it is necessary to initialize five additional entities, or even more. Thus, a large amount of code is obtained in total, which we write again and again for each test. Support for such tests takes a significant amount of time. If you want to update the model, and this sometimes happens, the scale of changes affects the tests.
Let's write a test:

Let's write the simplest test so that you generally understand the picture.
What is the first thing that comes to mind when you think about testing? Perhaps these are a few primitive tests of this type: you create a class, you create a method in it, mark it with the Test annotation. As a result, we use the JUnit capabilities, and initialize some data, default values, then test-specific values, do the same for the rest of the model, and finally, create a scheduler object, pass our data to it, we start, we receive results and we check them. More or less standard process. But it obviously has duplication of code. The first thing that comes to mind is the ability to render everything into static methods. Since there are a bunch of default values, why not hide it?

This is a good first step towards reducing duplication.

Looking at this, you realize that I would like to keep the model more compact. Here we have a pattern-builder, in which the default value is initialized somewhere under the hood, and test-specific values are immediately initialized. It is getting better already, however, we still write the boilerplate code, and we write it again each time. Imagine 200 tests - 200 times you have to write these three lines. Obviously, I would like to get rid of it somehow. Developing the idea, we come to a certain limit. So, for example, we can create a pattern builder for everything.

You can create a scheduler from scratch to the end, set all the values we need, start planning and everything is great. If you look in detail at this example and analyze it in detail, it turns out that a large amount of unnecessary code is being written. I would like to make the tests more readable, so that you can take a look and immediately understand, without delving into patterns, and so on.
So, we have some amount of unnecessary code. Simple mathematics suggests that there are 55% more letters than we need, and I would like to somehow get away from them.

After some time, the support of our tests turns out to be more expensive, because the code needs to be supported more. Sometimes, if we do not make any effort, readability either leaves much to be desired, or it turns out acceptable, but we would like even better. Perhaps later we will start adding some frameworks, libraries to make tests easier to write. Due to this, we increase the level of entry into the testing of our application. Here we already have a complex application, the level of entry into its testing is significant, and we increase it even more.
It's great to say how bad everything is, but let's think about how very good it would be. An ideal example that we would like to receive as a result:

Imagine that there is some declaration in which we say that this is a test with a specific name, and you want to use the space to separate words in the title, and not CamelCase. We build a schedule, we have some data, and the results of the scheduler are checked. Since we work mainly with Java, and all the code of the main application is written in this language, I also want to have compatible testing capabilities. I would like to initialize the data as obvious as possible to the reader. I want to initialize some common data and part of the model that we need. For example, create students, teachers, and describe when they are available. This is our perfect example.

Looking at it all, it starts to seem like it looks like some problem-oriented language. You need to understand what it is and what is the difference. Languages can be divided into two types: general-purpose languages (that which we constantly write with, we solve absolutely any problems and we cope with absolutely everything) and problem-oriented languages. For example, SQL helps us perfectly pull data from the database, and some other languages also help to solve other specific problems.

One way to implement problem-oriented languages is embedded languages, or internal ones. Such languages are implemented on the basis of a general-purpose language. That is, several constructions of our general-purpose language form something like a basis - that which we use when working with a problem-oriented language. At the same time, of course, it becomes possible in a problem-oriented language to use all the features and features that come from the general-purpose language.

Take another look at our perfect example and think about which language to choose. We have three options.

The first option is Groovy. Wonderful, dynamic language, which showed itself perfectly in the construction of problem-oriented languages. Again you can give an example of the build file in Gradle, which many of us use. There is Scala, which has a huge amount of opportunities to realize something of its own. And finally, there is Kotlin, which also helps us to build a problem-oriented language, and today it is about him that will be discussed. I would not want to make wars and compare Kotlin with something else, rather, it remains on your conscience. Today I will show you what Kotlin has for developing problem-oriented languages. When you want to compare it and say that some language is better, you can return to this article and easily see the difference.

What does Kotlin give us for developing a problem-oriented language?
First, it is static typing, and all that follows from here. At the compilation stage, a large number of problems are detected, and this saves a lot, especially if you don’t want to get problems related to syntax and writing in tests.
Then, there is a great type inference system that comes from Kotlin. This is great because there is no need to write some types again and again, everything is output by the compiler with a bang.
Thirdly, there is an excellent support for the development environment, and it is not surprising, because the same company makes the development environment as it is today, and it does Kotlin.
Finally, inside the DSL, obviously, we can use Kotlin. In my subjective opinion, supporting DSL is much easier than supporting utility classes. As you will see later, readability turns out to be a little better than builders. What I mean by "better": you get a little less syntax that you need to write - the one who will read your problem-oriented language, will perceive it faster. Finally, writing your bike is much more fun! But in fact, implementing a problem-oriented language is much easier than learning a new framework.
I will remind once again the link to GitHub , if you want to write demos further, then you can go in and pick up the code by reference.
We proceed to the design of our ideal, but now on Kotlin. Let's take a look at our example:

And in stages we will begin to rebuild it.
We have a test that turns into a function in Kotlin, which can be called using spaces.

Mark with Test annotation , which is available to us from JUnit. In Kotlin, you can use the abbreviated form of writing functions and through = get rid of the extra curly braces for the function itself.
Schedule is turning into a block. The same thing happens with a lot of designs, since we still work at Kotlin.

Let's move on to the rest. Curly brackets appear again, we cannot get rid of them, but at least we will try to get closer to our example. By producing constructions with spaces, we could somehow refine and make them somehow different, but it seems to me that it would be better to do the usual methods that will encapsulate the processing, but on the whole it will be obvious to the user. .

Our student turns into a block in which there is a work with properties, with methods, and we will analyze it further.

Finally, teachers. Here we have some nested blocks.

In the code below, we proceed to the checks. We need Java compatibility tests - and yes, Kotlin is compatible with Java.


Let us turn to the list of tools that we have. Here I gave a sign maybe, it lists everything that is needed to develop problem-oriented languages in Kotlin. You can come back to it from time to time and refresh your memory.
The table shows some comparison of problem-oriented syntax and ordinary syntax, which is available in the language.
Let's start with the most basic brick that we have in Kotlin - this is lambda.
Today, under the type of lambda, I will simply mean a functional type. Lambda are identified as follows:
We initialize the lambda using curly brackets, inside them we can write some code that will be called. That is the lambda, as a matter of fact, simply in itself hides this code. Running such a lambda looks like a function call, just parentheses.

If we want to pass some parameter, first, we need to describe it in a type.
Secondly, we have access to the default identifier it, which we can use, however, if it does not suit us somehow, you can set your own parameter name and use them.

In this case, we can skip the use of this parameter and use the underscore character in order not to produce identifiers. In this case, to ignore the identifier one could write nothing at all, but in the general case for several parameters there is the mentioned "_".

If we want to pass more than one parameter, we need to explicitly identify their identifiers.

Finally, what will happen if we try to pass lambda into some function and run it there. It looks like in the initial approximation as follows: we have a function to which we pass lambda in curly brackets, and if lambda is written as the last parameter in Kotlin, we can, as it were, take it out of these brackets.

If nothing is left in the brackets, we can abolish the brackets. For those familiar with Groovy, this should be familiar.

Where does it apply? Absolutely everywhere. That is, those curly braces, about which we have already spoken, we use them, these are the very lambdas.

Now look at one of the varieties of lambda, I call them lambda with context. You will come across some other names, for example, lambda with receiver, and they differ from ordinary lambda when declaring a type like this: on the left we add some sort of context, it can be any class.

What is it for? This is necessary so that inside the lambda we have access to the keyword this - this is the key word that points us to our context, that is, to some object that we have associated with our lambda. So, for example, we can create a lambda that will output some string, naturally, we will use the string class to declare the context and the call to such a lambda will look like this:



If you want to pass the context as a parameter, you can do it just as well. However, we cannot completely convey the context, that is, lambda with context requires - attention! - context, yes. What happens if we start transmitting the lambda with the context to some method? Here we look again at our exec method:

Rename it to the student method - nothing has changed:

So we gradually move towards our construction, the student construction, which hides all initialization under braces.

Let's get into it. We have some kind of student function that takes a lambda with a Student context.

Obviously, we need a context.

Here we create an object and run this lambda on it.

As a result, we can also initialize some default values before launching the lambda, so we encapsulate everything we need under the function.

Due to this, inside the lambda we get access to the keyword this - that for which, probably, there are lambdas with context.

Naturally, we can get rid of this keyword and we get the opportunity to write such constructions.

Again, if we have not only proper, but also some methods, we can also call them, it looks quite natural.

All these lambdas in code are lambdas with context. There is a huge number of contexts, they somehow intersect and allow us to build our problem-oriented language.

Summarizing by lambda - we have the usual lambda, is with the context, and those, and others can use.

Kotlin has a limited set of statements that you can override using conventions and the keyword operator.
Let's look at the teacher and his accessibility. Suppose we say that the teacher works on Mondays from 8 am for 1 hour. We also want to say that, in addition to this one hour, it works from 13.00 for 1 hour. I want to express this with the + operator . How can I do that?

There is some availability method that takes lambda with context

Let's see what DayPointer is. This is a pointer to a table of availability of some teacher, and the day in his own schedule. We also have a time function that will somehow convert some strings into integer indices: we have a class for this in Kotlin
On the left there is
Now let's take a look at the key design that starts everything, which our DSL starts with. Its implementation is a little different, and now we'll figure it out.
Kotlin has a singleton concept built right into the language. For this, a keyword is used instead of the class keyword

If you look at the result of decompiling (that is, in the development environment, click Tools -> Kotlin -> Show Kotlin Bytecode -> Decompile), you can see the following implementation of the singleton:

This is just a normal class, and nothing supernatural happens here.
There is another interesting tool - this operator

In fact, parentheses allow us to call the invoke method and it has an operator modifier. If we give a lambda with a context to this operator, then we will have such a construction.

To create instances each time is something else, so we can combine previous knowledge and current knowledge.
We will make a singleton, call its schedule, inside it we will declare the invoke operator, inside we will create a context, and it will be lambda with the context, this is the one that we create here. It turns out a single point of entry into our DSL, and as a result, we get the same construction - schedule with curly braces.

Great, we talked about schedule, let's take a look at our checks.
We have teachers, we have built a schedule, and we want to check that there is an object in the schedule of this teacher on a certain day, with which we will work.

I would like to use square brackets and access our schedule in a way that is visually similar to accessing arrays.

This can be done using the operator: get / set:

Here we are not doing anything new, just follow the agreements. In the case of the set operator, you must additionally pass the values to our method:

So, the square brackets for reading turn into get, and the square brackets through which we assign turn into set.
Further text can either read or watch the video on the link . The video has a clear start time, but the end time is not specified - in principle, once started, you can watch it to the end of the article.
For convenience, I will summarize the essence of the video right in the text.
Let's write a test. We have some schedule object, and if we go through ctrl + b to implement it, we will see everything that I mentioned before.

Inside the schedule object, we want to initialize the data, then perform some checks, and within the data we would like to say that:

And here one of the minuses of Kotlin and problem-oriented languages is manifested in principle: it is quite difficult to address some objects that we created earlier. In this demo, I will specify everything as indices, that is, rus is index 0, mathematics is index 2. And the teacher naturally, also leads something. He does not just go to work, but does something. For readers of this article, I would like to suggest another addressing option, you can create unique tags and save entities to the Map for them, and when you need to refer to one of them, you can always find it by tag. We continue to disassemble the DSL.
Here's what needs to be noted: first, we have the + operator, to the implementation of which we can also go and see that we actually have a DayPointer class, which helps us to link this all with the help of an operator.
And due to the fact that we have access to the context, the development environment tells us that we have a context in our key word that some collection is available to us, and we will use it.

That is, we have a collection of events. An event in itself encapsulates a set of properties, for example: that there is a student, a teacher, on what day for what lesson they meet.

We continue to write the test further.

Here, again, we use the get operator, it is not so easy to switch to its implementation, but we can do it.

In fact, we simply follow the agreement, thanks to which we gain access to this structure.
Let's go back to the presentation and continue the conversation about Kotlin. We wanted the checks implemented on Kotlin, and we went through these events: The

Event is essentially an encapsulated set of 4 properties. I want to lay out this event on a set of properties, like a tuple. In Russian, such a construction is called multi-declaration (I found only such a translation), or a destructuring declaration , and it works like this:

If someone of you is not familiar with this feature, it works like this: you can take an event, and on the spot, where it is used, using parentheses, decompose it into a set of properties.

This works because we have a componentN method, that is, it is a method that is generated by the compiler thanks to the data modifier, which we write in front of the class.

At the same time a large number of other methods arrive to us. We are interested in the componentN method, which is generated based on the properties listed in the primary-constructor parameters.

If we didn’t have a data modifier, we would have to manually write an operator that would do the same thing.


So, we have some componentN methods, and they are laid out in such a call:

In fact, this is syntactic sugar over the call of several methods.
We have already spoken about some availability table, and, in fact, I have deceived you. It happens. No

No additional class is needed: you can take a matrix of Boolean values and rename for more obviousness. This can be done using a so-called typealias or type alias . Unfortunately, we don’t get any additional bonuses, it’s just a renaming. If you take and the availability rename back to the matrix of boolean values, nothing will change at all. The code both worked and will work.
Let's take a look at the teacher, just at this very accessibility, and talk about it:
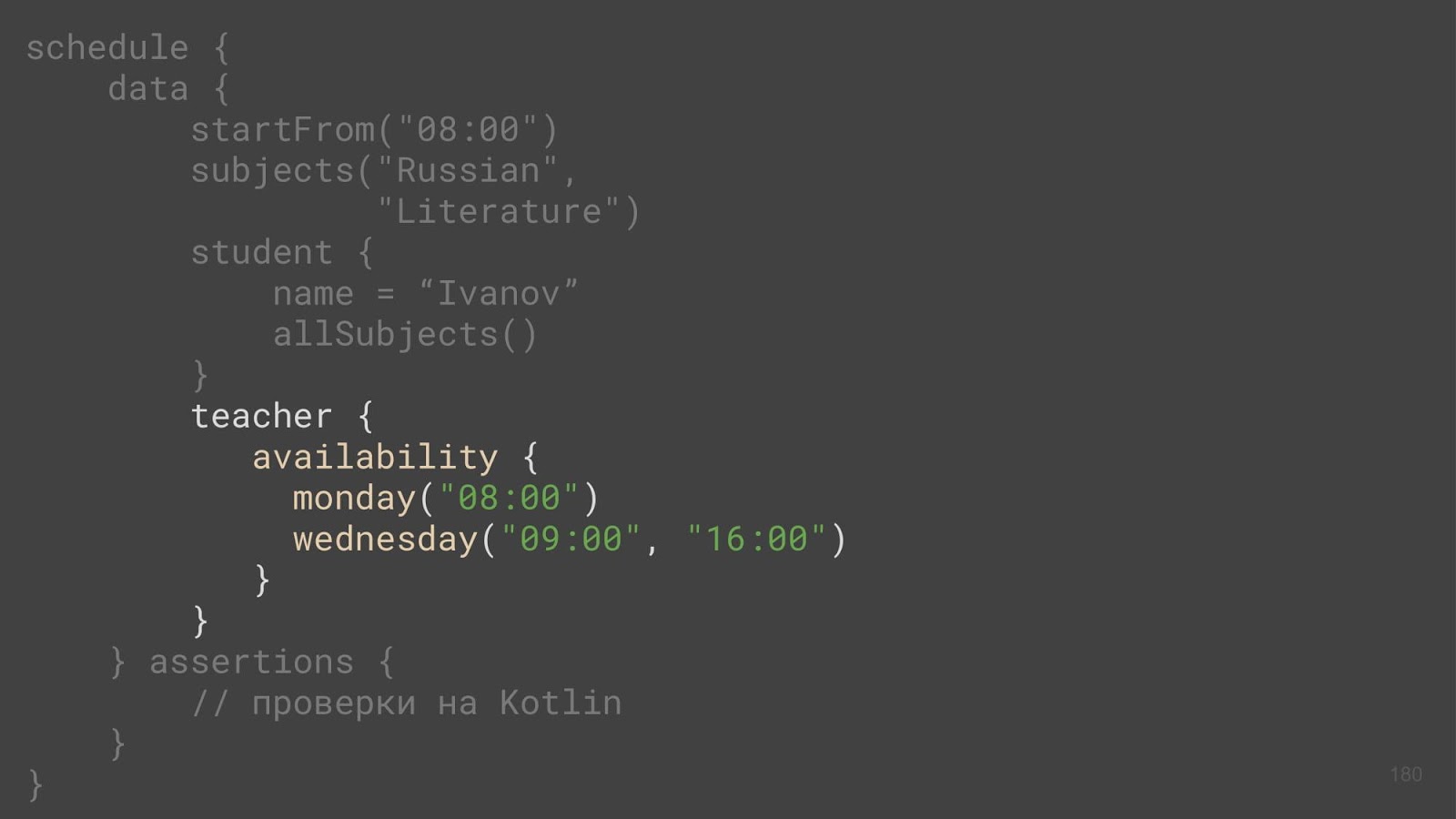
We have a teacher, and he calls the availability method (have you lost the thread of reasoning yet? :-). Where did he come from? That is, a teacher is some kind of entity that has a class, and this is a business code. And there can be no additional method.

This method appears due to the extension-functions. We take and fasten to our class some other one function that we can run on objects of this class.
If we pass this function some lambda and then run it on an existing property, then everything is fine - the availability method in its implementation initializes the availability property. You can get rid of it. We already know about the invoke operator, which can be attached to a type, and at the same time be an extension-function. If we transfer lambda to this operator, then right there, on the keyword this, we can launch this lambda. As a result, when we work with a teacher, accessibility is a property of the teacher, and not some additional method, and no rhsinchron occurs here.

As a bonus, extension-functions can be created for nullable types. This is good, because if there is a variable with a nullable type that contains a null value, our function is ready for this, and it will not fall from NullPointer. Inside this function, this may be null, and this needs to be handled.

Summarizing by extension-functions: it is necessary to understand that there is access only to the public API of the class, and the class itself is not modified in any way. The extension function is determined by the type of the variable, not by the actual type. Moreover, a member of the class with the same signature will take precedence. You can create an extension-function for one class, but write it in a completely different class, and within this extension-function there will be access to two contexts simultaneously. It turns out the intersection of contexts. And finally, this is a great opportunity to take and fasten operators to any place we want.

The next tool is infix functions. Another dangerous hammer in the hands of the developer. Why dangerous? What you see is code. This code can be written in Kotlin, and do not do so! Please do not do this. But nevertheless, the approach is good. Due to this, it is possible to get rid of dots, parentheses - from all that noisy syntax that we are trying to get as far as possible and make our code a bit cleaner.

How it works? Let's take a simpler example - a variable of type integer. Let's create an extension-function for it, let's call it shouldBeEqual, it will do something, but this is not interesting anymore. If we add an infix modifier to the left of it, that's enough. You can get rid of points and parentheses, but there are a couple of nuances.

Based on this, the construction of data and assertions, fastened together, is implemented.

Let's get into it. We have a SchedulingContext - the general context of launching scheduling. There is a data function that returns the result of this planning. At the same time, we create an extension-function and an infix-function assertions at the same time, which will run a lambda that checks our values.

There is a subject, an object and an action, and you need to somehow bind them. In this case, the result of executing data with curly braces is the subject. The lambda we pass to the assertions method is an object, and the assertions method itself is an action. It all seems to be glued together.

Speaking about infix functions, it is important to understand that this is a step to get rid of noisy syntax. However, we must necessarily have a subject and an object of this action, and we need to use the infix modifier. Maybe exactly one parameter - that is, zero parameters can not be, two can not be, three - well, you understand. It is possible to transfer to this function, for example, lambdas, and thus constructions that you have not seen before are obtained.
Let's move on to the next demo. It is better to look at the video, and not read the text.
Now everything looks ready: you saw the infix function, you saw the extension functions, the destructuring declaration is ready.
Let us return to our presentation, and here we will move on to one rather important point when building problem-oriented languages — something to think about is context control.

There are situations when we can take a DSL and reuse it right inside it, but we do not want to do that. Our user (perhaps an inexperienced user) writes data inside data, and this makes no sense. We would like to somehow forbid him to do it.
Before Kotlin version 1.1, we had to do the following: in response to the fact that we

After the version of Kotlin 1.1, a remarkable annotation appeared
However, there is one such special case when we work with our business model. It is usually written in Java. There is a context, there is an annotation that needs to be labeled context. What do you think, what is the context inside the student method? The class


We would like to somehow control this situation too, because in this case there is access to the following construction: to create a student inside the students. I do not want to cause you any wrong associations, but we want to prohibit it, this is wrong.

We have three options.

Thus, even at this level, you can control the context, but with some restrictions that you need to be able to bypass.

Summarizing about context control. Protect your users from errors. It is clear that users will not make some mistakes, because this is obvious, but it is still desirable to control it. Moreover, the implementation of such control takes not so much money and time. Use the @DslMarker annotation, which you mark your own annotations with. In situations where you cannot use the @DslMarker annotation, use the @Deprecated annotation to help you get around those cases that do not work yet.
So, the context control demo:

First, the reuse of DSL parts. Today you have already seen that addressing entities created using DSL can be problematic. There are ways to get around this, but it is advisable to think about this in advance in order to have a plan for this.
Imagine that you have a piece of code, and you just want to repeat it, for example, in a cycle to be able to create students, many, many times the same students, or any other entity. How to do it? You can use the for loop - not the best option. You can create an additional method inside your DSL, and this will be a better solution, however, such problems will have to be solved right at the DSL level. Watch out for the this keyword and the default name for the it parameter. Fortunately, with the Kotlin version 1.2.20 we have hints that are visible right in the development environment. The gray code tells us what context we are working with or what is it.
Nesting can be a problem. You have built a wonderful DSL, but the initialization of the model goes in-depth-in-depth, and in the end you often use a horizontal scroll than a vertical one. It is desirable to hide the default values under the default implementation. A user who needs just a student does not want to know about any training program, nor about anything else, he just wants to create a student without details, does not even want to designate a name. Try to shorten the syntax. For example, specify some default values, pass lambda empty, etc.
Finally, the documentation. In my subjective opinion, the best documentation for your problem-oriented language is more examples of this DSL. It's great when you have Kotlin-docks, this is a good bonus. However, if the DSL user has no idea what designs are available, he and Kotlin-docks have nowhere to look. Did you ever feel that way? When you come to write a Gradle-file, at the very beginning, you don’t understand what it is and need some examples. You don't care about any contexts, you want examples, and this is the best documentation that new DSL users can use.

Don't pop the DSLs in all the slots, please. This really want to do when you own this tool. I want to say, let's create a DSL here, maybe here and here. First of all, this is ungrateful work. Secondly, it is still desirable to apply this at the destination. Where it really helps you solve some problem.
Finally, learn Kotlin. Learn the features that come to this language, new features, thanks to which your code will be cleaner, shorter, more compact, it will be much easier to read. And when you return to testing again (for example, you have added something, you need to do a test), it will be much more pleasant to do it, because the DSL is as compact and comfortable as possible, and you have no problems creating a dozen students. Just a couple of lines this is done.
Train on "cats" as the hero of a famous movie. In my opinion, at first it is easier to introduce Kotlin into your project as a test. This is a good opportunity to check the language, try it, look at its features. This is such a battlefield, on which even if it does not work out - nothing terrible, you can still use it.
Finally, pre-design the DSL. Today I showed some perfect example, and we went through stages to build a problem-oriented language. If you design a DSL in advance, it will ultimately be much easier, you will not be able to redo it 10 times, you will not be soared that the contexts are somehow intersected and logically strongly connected. Just pre-design your DSL — it's pretty easy to do on a piece of paper when you know a set of designs that I told you today.
And finally, contacts for communication. My name is Ivan Osipov, Telegram: @ivan_osipov , Twitter: @_osipov_ , Habr: i_osipov . I will wait for your comments.
In the course of the article we will examine all the main tools from the developer’s arsenal and how they can be combined to solve testing problems. We will make the journey from designing the Perfect Test to running the most approximate, clean and understandable test for the Kotlin-based resource planning system.
The article will be useful to practicing engineers, those who consider Kotlin as a language for comfortable writing compact tests, and those who want to improve the testing process in their project.
The article is based on the report of Ivan Osipov ( i_osipov ) at the JPoint conference. Further narration is conducted from his face. Ivan works as a programmer at Haulmont. The main product of the company is CUBA, a platform for developing enterprise and various web applications. Including on this platform are made and outsourcing projects, among which was recently a project in the field of education, in which Ivan was engaged in building a schedule for an educational institution. It so happened that for the last three years, Ivan somehow worked with the planners, and specifically in Haulmont during the year they are testing this very scheduler.
For those who want to run examples - keep a link to GitHub . Under the link you will find all the code that today we will parse, run and write with you. Open the code and go!
Today we will discuss:
- what are problem-oriented languages;
- embedded problem-oriented languages;
- scheduling for educational institutions;
- how it is all tested with Kotlin.
Today I will talk in detail about the tools that we have in the language, I will show you several demos, and we will write the whole test from beginning to end. At the same time, I would like to be more objective, so I’ll tell you about some minuses that I identified for myself during development.
Let's start by talking about the scheduling module. So, the construction of the schedule takes place in several stages. Each of these steps must be tested separately. It should be understood that despite the fact that the stages are different, we have a common data model.
This process can be represented as follows: at the entrance there are some data with a general model, at the output - a schedule. The data is validated, filtered, and then training groups are built. This refers to the subject area of the schedule for an educational institution. On the basis of the constructed groups and on the basis of some other data, we post a lesson. Today we will talk only about the last stage - about the placement of classes.
A little about testing the scheduler.
First, as you already understood, the different stages should be tested separately. There is a more or less standard test run process: there is data initialization, there is a launch of the scheduler, there is a check of the results of this scheduler itself. There are a huge number of different business cases that need to be covered and different situations that need to be taken into account so that when creating a schedule these situations are also preserved.
A model is sometimes spreading, and in order to create a single entity, it is necessary to initialize five additional entities, or even more. Thus, a large amount of code is obtained in total, which we write again and again for each test. Support for such tests takes a significant amount of time. If you want to update the model, and this sometimes happens, the scale of changes affects the tests.
Let's write a test:
Let's write the simplest test so that you generally understand the picture.
What is the first thing that comes to mind when you think about testing? Perhaps these are a few primitive tests of this type: you create a class, you create a method in it, mark it with the Test annotation. As a result, we use the JUnit capabilities, and initialize some data, default values, then test-specific values, do the same for the rest of the model, and finally, create a scheduler object, pass our data to it, we start, we receive results and we check them. More or less standard process. But it obviously has duplication of code. The first thing that comes to mind is the ability to render everything into static methods. Since there are a bunch of default values, why not hide it?
This is a good first step towards reducing duplication.
Looking at this, you realize that I would like to keep the model more compact. Here we have a pattern-builder, in which the default value is initialized somewhere under the hood, and test-specific values are immediately initialized. It is getting better already, however, we still write the boilerplate code, and we write it again each time. Imagine 200 tests - 200 times you have to write these three lines. Obviously, I would like to get rid of it somehow. Developing the idea, we come to a certain limit. So, for example, we can create a pattern builder for everything.
You can create a scheduler from scratch to the end, set all the values we need, start planning and everything is great. If you look in detail at this example and analyze it in detail, it turns out that a large amount of unnecessary code is being written. I would like to make the tests more readable, so that you can take a look and immediately understand, without delving into patterns, and so on.
So, we have some amount of unnecessary code. Simple mathematics suggests that there are 55% more letters than we need, and I would like to somehow get away from them.
After some time, the support of our tests turns out to be more expensive, because the code needs to be supported more. Sometimes, if we do not make any effort, readability either leaves much to be desired, or it turns out acceptable, but we would like even better. Perhaps later we will start adding some frameworks, libraries to make tests easier to write. Due to this, we increase the level of entry into the testing of our application. Here we already have a complex application, the level of entry into its testing is significant, and we increase it even more.
Perfect test
It's great to say how bad everything is, but let's think about how very good it would be. An ideal example that we would like to receive as a result:
Imagine that there is some declaration in which we say that this is a test with a specific name, and you want to use the space to separate words in the title, and not CamelCase. We build a schedule, we have some data, and the results of the scheduler are checked. Since we work mainly with Java, and all the code of the main application is written in this language, I also want to have compatible testing capabilities. I would like to initialize the data as obvious as possible to the reader. I want to initialize some common data and part of the model that we need. For example, create students, teachers, and describe when they are available. This is our perfect example.
Domain Specific Language
Looking at it all, it starts to seem like it looks like some problem-oriented language. You need to understand what it is and what is the difference. Languages can be divided into two types: general-purpose languages (that which we constantly write with, we solve absolutely any problems and we cope with absolutely everything) and problem-oriented languages. For example, SQL helps us perfectly pull data from the database, and some other languages also help to solve other specific problems.
One way to implement problem-oriented languages is embedded languages, or internal ones. Such languages are implemented on the basis of a general-purpose language. That is, several constructions of our general-purpose language form something like a basis - that which we use when working with a problem-oriented language. At the same time, of course, it becomes possible in a problem-oriented language to use all the features and features that come from the general-purpose language.
Take another look at our perfect example and think about which language to choose. We have three options.
The first option is Groovy. Wonderful, dynamic language, which showed itself perfectly in the construction of problem-oriented languages. Again you can give an example of the build file in Gradle, which many of us use. There is Scala, which has a huge amount of opportunities to realize something of its own. And finally, there is Kotlin, which also helps us to build a problem-oriented language, and today it is about him that will be discussed. I would not want to make wars and compare Kotlin with something else, rather, it remains on your conscience. Today I will show you what Kotlin has for developing problem-oriented languages. When you want to compare it and say that some language is better, you can return to this article and easily see the difference.
What does Kotlin give us for developing a problem-oriented language?
First, it is static typing, and all that follows from here. At the compilation stage, a large number of problems are detected, and this saves a lot, especially if you don’t want to get problems related to syntax and writing in tests.
Then, there is a great type inference system that comes from Kotlin. This is great because there is no need to write some types again and again, everything is output by the compiler with a bang.
Thirdly, there is an excellent support for the development environment, and it is not surprising, because the same company makes the development environment as it is today, and it does Kotlin.
Finally, inside the DSL, obviously, we can use Kotlin. In my subjective opinion, supporting DSL is much easier than supporting utility classes. As you will see later, readability turns out to be a little better than builders. What I mean by "better": you get a little less syntax that you need to write - the one who will read your problem-oriented language, will perceive it faster. Finally, writing your bike is much more fun! But in fact, implementing a problem-oriented language is much easier than learning a new framework.
I will remind once again the link to GitHub , if you want to write demos further, then you can go in and pick up the code by reference.
Designing an ideal on Kotlin
We proceed to the design of our ideal, but now on Kotlin. Let's take a look at our example:
And in stages we will begin to rebuild it.
We have a test that turns into a function in Kotlin, which can be called using spaces.
Mark with Test annotation , which is available to us from JUnit. In Kotlin, you can use the abbreviated form of writing functions and through = get rid of the extra curly braces for the function itself.
Schedule is turning into a block. The same thing happens with a lot of designs, since we still work at Kotlin.
Let's move on to the rest. Curly brackets appear again, we cannot get rid of them, but at least we will try to get closer to our example. By producing constructions with spaces, we could somehow refine and make them somehow different, but it seems to me that it would be better to do the usual methods that will encapsulate the processing, but on the whole it will be obvious to the user. .
Our student turns into a block in which there is a work with properties, with methods, and we will analyze it further.
Finally, teachers. Here we have some nested blocks.
In the code below, we proceed to the checks. We need Java compatibility tests - and yes, Kotlin is compatible with Java.
Arsenal of DSL development at Kotlin
Let us turn to the list of tools that we have. Here I gave a sign maybe, it lists everything that is needed to develop problem-oriented languages in Kotlin. You can come back to it from time to time and refresh your memory.
The table shows some comparison of problem-oriented syntax and ordinary syntax, which is available in the language.
Lambda in Kotlin
val lambda: () -> Unit = { }Let's start with the most basic brick that we have in Kotlin - this is lambda.
Today, under the type of lambda, I will simply mean a functional type. Lambda are identified as follows:
(типы параметров) -> возвращаемый тип. We initialize the lambda using curly brackets, inside them we can write some code that will be called. That is the lambda, as a matter of fact, simply in itself hides this code. Running such a lambda looks like a function call, just parentheses.
If we want to pass some parameter, first, we need to describe it in a type.
Secondly, we have access to the default identifier it, which we can use, however, if it does not suit us somehow, you can set your own parameter name and use them.
In this case, we can skip the use of this parameter and use the underscore character in order not to produce identifiers. In this case, to ignore the identifier one could write nothing at all, but in the general case for several parameters there is the mentioned "_".
If we want to pass more than one parameter, we need to explicitly identify their identifiers.
Finally, what will happen if we try to pass lambda into some function and run it there. It looks like in the initial approximation as follows: we have a function to which we pass lambda in curly brackets, and if lambda is written as the last parameter in Kotlin, we can, as it were, take it out of these brackets.
If nothing is left in the brackets, we can abolish the brackets. For those familiar with Groovy, this should be familiar.
Where does it apply? Absolutely everywhere. That is, those curly braces, about which we have already spoken, we use them, these are the very lambdas.
Now look at one of the varieties of lambda, I call them lambda with context. You will come across some other names, for example, lambda with receiver, and they differ from ordinary lambda when declaring a type like this: on the left we add some sort of context, it can be any class.
What is it for? This is necessary so that inside the lambda we have access to the keyword this - this is the key word that points us to our context, that is, to some object that we have associated with our lambda. So, for example, we can create a lambda that will output some string, naturally, we will use the string class to declare the context and the call to such a lambda will look like this:
If you want to pass the context as a parameter, you can do it just as well. However, we cannot completely convey the context, that is, lambda with context requires - attention! - context, yes. What happens if we start transmitting the lambda with the context to some method? Here we look again at our exec method:
Rename it to the student method - nothing has changed:
So we gradually move towards our construction, the student construction, which hides all initialization under braces.
Let's get into it. We have some kind of student function that takes a lambda with a Student context.
Obviously, we need a context.
Here we create an object and run this lambda on it.
As a result, we can also initialize some default values before launching the lambda, so we encapsulate everything we need under the function.
Due to this, inside the lambda we get access to the keyword this - that for which, probably, there are lambdas with context.
Naturally, we can get rid of this keyword and we get the opportunity to write such constructions.
Again, if we have not only proper, but also some methods, we can also call them, it looks quite natural.
Application
All these lambdas in code are lambdas with context. There is a huge number of contexts, they somehow intersect and allow us to build our problem-oriented language.
Summarizing by lambda - we have the usual lambda, is with the context, and those, and others can use.
Operators
Kotlin has a limited set of statements that you can override using conventions and the keyword operator.
Let's look at the teacher and his accessibility. Suppose we say that the teacher works on Mondays from 8 am for 1 hour. We also want to say that, in addition to this one hour, it works from 13.00 for 1 hour. I want to express this with the + operator . How can I do that?
There is some availability method that takes lambda with context
AvailabilityTable. This means that there is some class that is called this, and the monday method is declared in this class. This method returns DayPointer, because We need to attach our operator to something.Let's see what DayPointer is. This is a pointer to a table of availability of some teacher, and the day in his own schedule. We also have a time function that will somehow convert some strings into integer indices: we have a class for this in Kotlin
IntRange. On the left there is
DayPointer, on the right there is time, and we would like to combine them with the + operator . To do this in the class, DayPointeryou can create our operator. It will take a range of Int values and return DayPointerso that we can chain our DSL together again and again. Now let's take a look at the key design that starts everything, which our DSL starts with. Its implementation is a little different, and now we'll figure it out.
Kotlin has a singleton concept built right into the language. For this, a keyword is used instead of the class keyword
object. If we create a method inside a singleton, then we can refer to it so that there is no need to create an instance of this class again. We simply refer to it as a static method in the class. If you look at the result of decompiling (that is, in the development environment, click Tools -> Kotlin -> Show Kotlin Bytecode -> Decompile), you can see the following implementation of the singleton:
This is just a normal class, and nothing supernatural happens here.
There is another interesting tool - this operator
invoke. Imagine that we have some class A, we have its instance, and we would like to run this instance, that is, to call parentheses to an object of this class, and we can do this thanks to the operator invoke. In fact, parentheses allow us to call the invoke method and it has an operator modifier. If we give a lambda with a context to this operator, then we will have such a construction.
To create instances each time is something else, so we can combine previous knowledge and current knowledge.
We will make a singleton, call its schedule, inside it we will declare the invoke operator, inside we will create a context, and it will be lambda with the context, this is the one that we create here. It turns out a single point of entry into our DSL, and as a result, we get the same construction - schedule with curly braces.
Great, we talked about schedule, let's take a look at our checks.
We have teachers, we have built a schedule, and we want to check that there is an object in the schedule of this teacher on a certain day, with which we will work.
I would like to use square brackets and access our schedule in a way that is visually similar to accessing arrays.
This can be done using the operator: get / set:
Here we are not doing anything new, just follow the agreements. In the case of the set operator, you must additionally pass the values to our method:
So, the square brackets for reading turn into get, and the square brackets through which we assign turn into set.
Demo: object, operators
Further text can either read or watch the video on the link . The video has a clear start time, but the end time is not specified - in principle, once started, you can watch it to the end of the article.
For convenience, I will summarize the essence of the video right in the text.
Let's write a test. We have some schedule object, and if we go through ctrl + b to implement it, we will see everything that I mentioned before.
Inside the schedule object, we want to initialize the data, then perform some checks, and within the data we would like to say that:
- our school is open from 8 am;
- there is a set of items for which we will build a schedule;
- There are some teachers who have described some accessibility;
- there is a student;
- In principle, for a student, we only need to say that he is studying a particular subject.
And here one of the minuses of Kotlin and problem-oriented languages is manifested in principle: it is quite difficult to address some objects that we created earlier. In this demo, I will specify everything as indices, that is, rus is index 0, mathematics is index 2. And the teacher naturally, also leads something. He does not just go to work, but does something. For readers of this article, I would like to suggest another addressing option, you can create unique tags and save entities to the Map for them, and when you need to refer to one of them, you can always find it by tag. We continue to disassemble the DSL.
Here's what needs to be noted: first, we have the + operator, to the implementation of which we can also go and see that we actually have a DayPointer class, which helps us to link this all with the help of an operator.
And due to the fact that we have access to the context, the development environment tells us that we have a context in our key word that some collection is available to us, and we will use it.
That is, we have a collection of events. An event in itself encapsulates a set of properties, for example: that there is a student, a teacher, on what day for what lesson they meet.
We continue to write the test further.
Here, again, we use the get operator, it is not so easy to switch to its implementation, but we can do it.
In fact, we simply follow the agreement, thanks to which we gain access to this structure.
Let's go back to the presentation and continue the conversation about Kotlin. We wanted the checks implemented on Kotlin, and we went through these events: The
Event is essentially an encapsulated set of 4 properties. I want to lay out this event on a set of properties, like a tuple. In Russian, such a construction is called multi-declaration (I found only such a translation), or a destructuring declaration , and it works like this:
If someone of you is not familiar with this feature, it works like this: you can take an event, and on the spot, where it is used, using parentheses, decompose it into a set of properties.
This works because we have a componentN method, that is, it is a method that is generated by the compiler thanks to the data modifier, which we write in front of the class.
At the same time a large number of other methods arrive to us. We are interested in the componentN method, which is generated based on the properties listed in the primary-constructor parameters.
If we didn’t have a data modifier, we would have to manually write an operator that would do the same thing.
So, we have some componentN methods, and they are laid out in such a call:
In fact, this is syntactic sugar over the call of several methods.
We have already spoken about some availability table, and, in fact, I have deceived you. It happens. No
avaiabilityTabledoes not exist, is not in nature, but is a matrix of Boolean values. No additional class is needed: you can take a matrix of Boolean values and rename for more obviousness. This can be done using a so-called typealias or type alias . Unfortunately, we don’t get any additional bonuses, it’s just a renaming. If you take and the availability rename back to the matrix of boolean values, nothing will change at all. The code both worked and will work.
Let's take a look at the teacher, just at this very accessibility, and talk about it:
We have a teacher, and he calls the availability method (have you lost the thread of reasoning yet? :-). Where did he come from? That is, a teacher is some kind of entity that has a class, and this is a business code. And there can be no additional method.
This method appears due to the extension-functions. We take and fasten to our class some other one function that we can run on objects of this class.
If we pass this function some lambda and then run it on an existing property, then everything is fine - the availability method in its implementation initializes the availability property. You can get rid of it. We already know about the invoke operator, which can be attached to a type, and at the same time be an extension-function. If we transfer lambda to this operator, then right there, on the keyword this, we can launch this lambda. As a result, when we work with a teacher, accessibility is a property of the teacher, and not some additional method, and no rhsinchron occurs here.
As a bonus, extension-functions can be created for nullable types. This is good, because if there is a variable with a nullable type that contains a null value, our function is ready for this, and it will not fall from NullPointer. Inside this function, this may be null, and this needs to be handled.
Summarizing by extension-functions: it is necessary to understand that there is access only to the public API of the class, and the class itself is not modified in any way. The extension function is determined by the type of the variable, not by the actual type. Moreover, a member of the class with the same signature will take precedence. You can create an extension-function for one class, but write it in a completely different class, and within this extension-function there will be access to two contexts simultaneously. It turns out the intersection of contexts. And finally, this is a great opportunity to take and fasten operators to any place we want.
The next tool is infix functions. Another dangerous hammer in the hands of the developer. Why dangerous? What you see is code. This code can be written in Kotlin, and do not do so! Please do not do this. But nevertheless, the approach is good. Due to this, it is possible to get rid of dots, parentheses - from all that noisy syntax that we are trying to get as far as possible and make our code a bit cleaner.
How it works? Let's take a simpler example - a variable of type integer. Let's create an extension-function for it, let's call it shouldBeEqual, it will do something, but this is not interesting anymore. If we add an infix modifier to the left of it, that's enough. You can get rid of points and parentheses, but there are a couple of nuances.
Based on this, the construction of data and assertions, fastened together, is implemented.
Let's get into it. We have a SchedulingContext - the general context of launching scheduling. There is a data function that returns the result of this planning. At the same time, we create an extension-function and an infix-function assertions at the same time, which will run a lambda that checks our values.
There is a subject, an object and an action, and you need to somehow bind them. In this case, the result of executing data with curly braces is the subject. The lambda we pass to the assertions method is an object, and the assertions method itself is an action. It all seems to be glued together.
Speaking about infix functions, it is important to understand that this is a step to get rid of noisy syntax. However, we must necessarily have a subject and an object of this action, and we need to use the infix modifier. Maybe exactly one parameter - that is, zero parameters can not be, two can not be, three - well, you understand. It is possible to transfer to this function, for example, lambdas, and thus constructions that you have not seen before are obtained.
Let's move on to the next demo. It is better to look at the video, and not read the text.
Now everything looks ready: you saw the infix function, you saw the extension functions, the destructuring declaration is ready.
Let us return to our presentation, and here we will move on to one rather important point when building problem-oriented languages — something to think about is context control.
There are situations when we can take a DSL and reuse it right inside it, but we do not want to do that. Our user (perhaps an inexperienced user) writes data inside data, and this makes no sense. We would like to somehow forbid him to do it.
Before Kotlin version 1.1, we had to do the following: in response to the fact that we
SchedulingContexthave a data method, we had toDataContextto create another data method, into which we accept lambda (let it be without implementation), should mark this method with an annotation @Deprecatedand tell the compiler not to compile it. You see that this method runs - do not compile. Using this approach, we will even get some meaningful message when we write non-meaningful code. After the version of Kotlin 1.1, a remarkable annotation appeared
@DslMarker. This annotation is needed to label derived annotations. They, in turn, we will mark out the problem-oriented languages. For each problem-oriented language, you can create one annotation that you mark@DslMarkerand you will hang it on every context that is needed. There is no longer any need to write additional methods that need to be prohibited from compiling - it just works. Not compiled. However, there is one such special case when we work with our business model. It is usually written in Java. There is a context, there is an annotation that needs to be labeled context. What do you think, what is the context inside the student method? The class
Student. This is a piece of our business model, Kotlin is not there. We would like to somehow control this situation too, because in this case there is access to the following construction: to create a student inside the students. I do not want to cause you any wrong associations, but we want to prohibit it, this is wrong.
We have three options.
- Create a whole context that is responsible for our student. Let's call it StudentContext. We will describe all the properties there, and then we will create a student on the basis of it. Some such madness - a bunch of code is written, probably more than for production.
- The second option is to take and create an interface that reflects our student, that is, simply lists the properties. But we reuse the same interface in our tests. Take the StudentContext and say that it implements some IStudent interface by delegating the implementation of this interface to another object. That is, the Student object is created right there on the spot, and the entire implementation of the IStudent interface for the StudentContext is taken from it. Mark annotation DslMarker and great, everything works.
- Favorite way: let's use the deprecated annotation and forbid compiling the wrong code. Just list what we need. Usually in the hierarchy of entities is an entity that contains the identifier. On this entity, we can hang an extension-function, which we forbid to call. Including the student inside the student.
Thus, even at this level, you can control the context, but with some restrictions that you need to be able to bypass.
Summarizing about context control. Protect your users from errors. It is clear that users will not make some mistakes, because this is obvious, but it is still desirable to control it. Moreover, the implementation of such control takes not so much money and time. Use the @DslMarker annotation, which you mark your own annotations with. In situations where you cannot use the @DslMarker annotation, use the @Deprecated annotation to help you get around those cases that do not work yet.
So, the context control demo:
Cons and problems
First, the reuse of DSL parts. Today you have already seen that addressing entities created using DSL can be problematic. There are ways to get around this, but it is advisable to think about this in advance in order to have a plan for this.
Imagine that you have a piece of code, and you just want to repeat it, for example, in a cycle to be able to create students, many, many times the same students, or any other entity. How to do it? You can use the for loop - not the best option. You can create an additional method inside your DSL, and this will be a better solution, however, such problems will have to be solved right at the DSL level. Watch out for the this keyword and the default name for the it parameter. Fortunately, with the Kotlin version 1.2.20 we have hints that are visible right in the development environment. The gray code tells us what context we are working with or what is it.
Nesting can be a problem. You have built a wonderful DSL, but the initialization of the model goes in-depth-in-depth, and in the end you often use a horizontal scroll than a vertical one. It is desirable to hide the default values under the default implementation. A user who needs just a student does not want to know about any training program, nor about anything else, he just wants to create a student without details, does not even want to designate a name. Try to shorten the syntax. For example, specify some default values, pass lambda empty, etc.
Finally, the documentation. In my subjective opinion, the best documentation for your problem-oriented language is more examples of this DSL. It's great when you have Kotlin-docks, this is a good bonus. However, if the DSL user has no idea what designs are available, he and Kotlin-docks have nowhere to look. Did you ever feel that way? When you come to write a Gradle-file, at the very beginning, you don’t understand what it is and need some examples. You don't care about any contexts, you want examples, and this is the best documentation that new DSL users can use.
Don't pop the DSLs in all the slots, please. This really want to do when you own this tool. I want to say, let's create a DSL here, maybe here and here. First of all, this is ungrateful work. Secondly, it is still desirable to apply this at the destination. Where it really helps you solve some problem.
Finally, learn Kotlin. Learn the features that come to this language, new features, thanks to which your code will be cleaner, shorter, more compact, it will be much easier to read. And when you return to testing again (for example, you have added something, you need to do a test), it will be much more pleasant to do it, because the DSL is as compact and comfortable as possible, and you have no problems creating a dozen students. Just a couple of lines this is done.
Train on "cats" as the hero of a famous movie. In my opinion, at first it is easier to introduce Kotlin into your project as a test. This is a good opportunity to check the language, try it, look at its features. This is such a battlefield, on which even if it does not work out - nothing terrible, you can still use it.
Finally, pre-design the DSL. Today I showed some perfect example, and we went through stages to build a problem-oriented language. If you design a DSL in advance, it will ultimately be much easier, you will not be able to redo it 10 times, you will not be soared that the contexts are somehow intersected and logically strongly connected. Just pre-design your DSL — it's pretty easy to do on a piece of paper when you know a set of designs that I told you today.
And finally, contacts for communication. My name is Ivan Osipov, Telegram: @ivan_osipov , Twitter: @_osipov_ , Habr: i_osipov . I will wait for your comments.
Minute advertising. If you liked this report from the JPoint conference - note that on October 19-20, St. Petersburg will host Joker 2018 - the largest Java conference in Russia. His program will also have a lot of interesting things. The conference was announced quite recently, but the site already has the first speakers and reports.