360 pivot or what solutions we used. Part 1
Today, only the lazy does not make a project in the field of online travel. This is logical in principle, since the market is growing rapidly, although there are few free niches and the business is complex. Many have already managed to raise serious investments in hotel reservation services or online ticket sales.
In December last year, we entered this market with the iknow.travel project, betting on combining the sale of airline tickets and a content resource, but after 3 months (in February) we decided to rewrite the project from scratch, and we did not even withdraw the ticket part from test at that time.
About why this was done in terms of the project development strategy, we will post a separate post in the near future. Now we want to describe what tasks we had to solve and what technologies were used on the way from the initial releaseair tickets + content to the travel designer (the development of the new version took 3 months).
WHAT HAPPENED
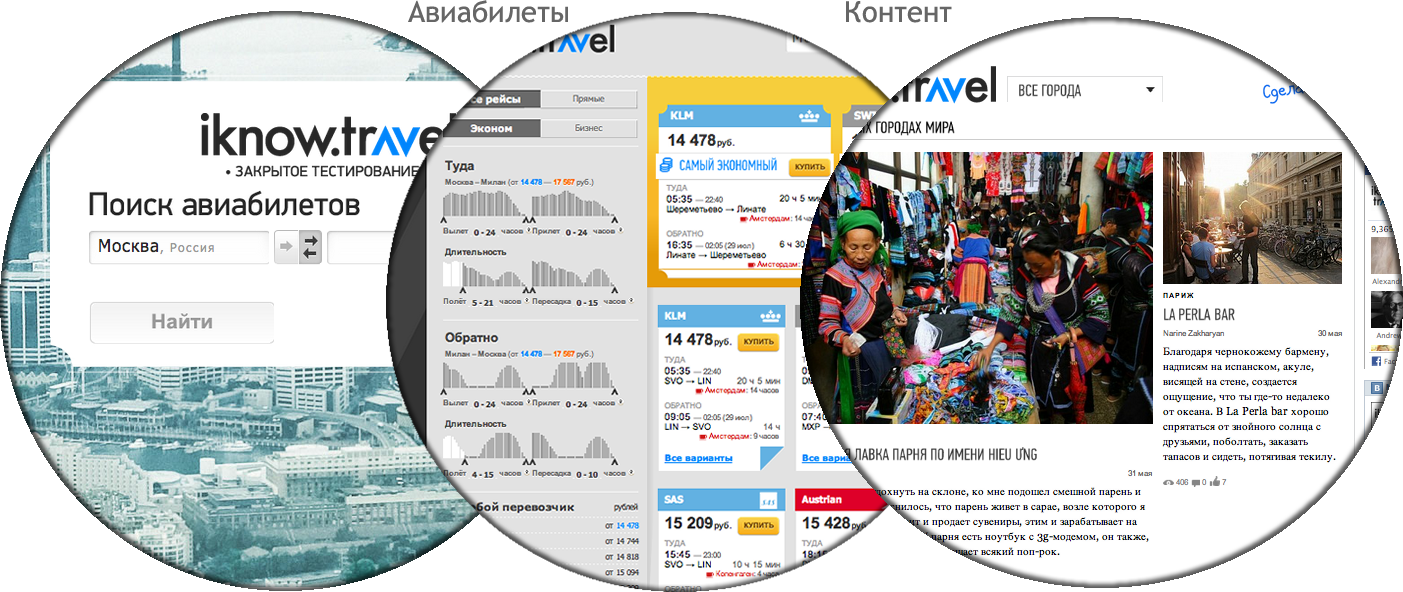
What has become

WHAT THEY WERE DOING
Initially, we set a goal: to leave the site completely open to search engines, while making it in the style of a single-page application. One-page sites have difficulty with SEO. Google in such cases recommends the so-called Hash Fragments . The bottom line is this: all links start with "#!", And the robot only replaces "#!" to "? _escaped_fragment =", makes a request and waits in response to static HTML. And it works. We preferred the good old method. Most of the site is accessible in HTML, which allows search engines to see pages as on a regular static site (although there were no compromises). True rumor has it that Googlebot already understands AJAXbut somehow we are not inclined to trust them. And with a regular browser we work on HTML5 PushState (which is supported in all modern browsers except IE 9), with an automatic transition to hash URL if HTML5 PushState is not available. And how would you do?
It is customary for us to choose a language for the task. For the server frontend, node.js. was the best choice. This fairly popular platform allowed us to split code and patterns between client and server. JavaScript is a good functional language. But pure JS is exhausting with a lack of syntactic sugar and tedious with support, so we use CoffeeScript.
Our client is written based on Backbone. Backbone - JS framework for interactive applications. Everything is built on the basis of 4 concepts:
Their interpretation in Backbone differs from the generally accepted. Firstly, the model is separated from the base. Included is a binding to the REST CRUD API, but there are adapters to HTML5 LocalStorage , WebSockets . Secondly, View is usually not even a View at all, but a controller in the usual sense. I will make a reservation that terminology is a purely subjective matter, and the Backbone authors directly say: their preparations are open for any approaches . It is very important to choose and adhere to one approach. What do you think?
By the way, for starting with Backbone, we recommend that you look at this (we will be happy to translate for Habr - write, if necessary).
In parallel with the choice of the technology stack on which the client will be built, we were faced with the question of choosing a DBMS for data storage.
Since the subject area was new for us, it was obvious that we should not rely on the fact that once designed, the model will be good enough so that it does not have to be changed as the project is developed and developed. In NoSQL, we expected to get a higher query execution speed, more convenient and simple storage of complex data, and flexibility. The understanding that we will repeatedly change the base scheme completely nullified the chances of relational databases being in the technology stack of our project.
Based on the analysis of several variants of NoSQL DBMS, we opted for MongoDB, because of the good combination of wide features with high speed. In particular, we were attracted by MongoDB's ability to index arrays, convenient sharding and replication, and good documentation. MongoDB also speaks in favor of good support for this DBMS and its application in many successful projects (a full list is here , among them are such giants as Disney, Craiglist, Foursquare).
Although we initially designed the data storage scheme taking into account the peculiarities of document-oriented DBMSs, in order to reduce both the query execution time and the database size, we had to repeatedly change the database scheme. For example, we were faced with the need to support large multidimensional indexes to ensure fast filtering of posts, but our attempt to optimize the data storage scheme to ensure maximum query execution speed led to an exponential increase in the size of both the indexes and the data itself, as a result of which we realized that not we will be able to maintain such a base because of its RAM requirements. As a result, we found a rather beautiful solution that ensured high speed of execution of all queries without excessive increase in the size of indexes and data. However, despite the fact
If you are interested to see what happened in the end and how it works, then for the test we posted the updated project here .
To access air tickets (if anyone wants to get in there) on the old site, use the code: i3n7wt0a8el
If you throw the post somewhere, then tell me where. Thanks in advance for the feedback. In many respects, we had to move quickly (in time for the holiday season) and intuitively, because a similar system was built for the first time. We will be happy to answer your questions.
In December last year, we entered this market with the iknow.travel project, betting on combining the sale of airline tickets and a content resource, but after 3 months (in February) we decided to rewrite the project from scratch, and we did not even withdraw the ticket part from test at that time.
About why this was done in terms of the project development strategy, we will post a separate post in the near future. Now we want to describe what tasks we had to solve and what technologies were used on the way from the initial releaseair tickets + content to the travel designer (the development of the new version took 3 months).
WHAT HAPPENED
What has become
WHAT THEY WERE DOING
Initially, we set a goal: to leave the site completely open to search engines, while making it in the style of a single-page application. One-page sites have difficulty with SEO. Google in such cases recommends the so-called Hash Fragments . The bottom line is this: all links start with "#!", And the robot only replaces "#!" to "? _escaped_fragment =", makes a request and waits in response to static HTML. And it works. We preferred the good old method. Most of the site is accessible in HTML, which allows search engines to see pages as on a regular static site (although there were no compromises). True rumor has it that Googlebot already understands AJAXbut somehow we are not inclined to trust them. And with a regular browser we work on HTML5 PushState (which is supported in all modern browsers except IE 9), with an automatic transition to hash URL if HTML5 PushState is not available. And how would you do?
NEXT, STACK SELECTION
It is customary for us to choose a language for the task. For the server frontend, node.js. was the best choice. This fairly popular platform allowed us to split code and patterns between client and server. JavaScript is a good functional language. But pure JS is exhausting with a lack of syntactic sugar and tedious with support, so we use CoffeeScript.
BACKBONE
Our client is written based on Backbone. Backbone - JS framework for interactive applications. Everything is built on the basis of 4 concepts:
- Model
- View
- Collection
- Router
Their interpretation in Backbone differs from the generally accepted. Firstly, the model is separated from the base. Included is a binding to the REST CRUD API, but there are adapters to HTML5 LocalStorage , WebSockets . Secondly, View is usually not even a View at all, but a controller in the usual sense. I will make a reservation that terminology is a purely subjective matter, and the Backbone authors directly say: their preparations are open for any approaches . It is very important to choose and adhere to one approach. What do you think?
By the way, for starting with Backbone, we recommend that you look at this (we will be happy to translate for Habr - write, if necessary).
Mongodb
In parallel with the choice of the technology stack on which the client will be built, we were faced with the question of choosing a DBMS for data storage.
Since the subject area was new for us, it was obvious that we should not rely on the fact that once designed, the model will be good enough so that it does not have to be changed as the project is developed and developed. In NoSQL, we expected to get a higher query execution speed, more convenient and simple storage of complex data, and flexibility. The understanding that we will repeatedly change the base scheme completely nullified the chances of relational databases being in the technology stack of our project.
Based on the analysis of several variants of NoSQL DBMS, we opted for MongoDB, because of the good combination of wide features with high speed. In particular, we were attracted by MongoDB's ability to index arrays, convenient sharding and replication, and good documentation. MongoDB also speaks in favor of good support for this DBMS and its application in many successful projects (a full list is here , among them are such giants as Disney, Craiglist, Foursquare).
Although we initially designed the data storage scheme taking into account the peculiarities of document-oriented DBMSs, in order to reduce both the query execution time and the database size, we had to repeatedly change the database scheme. For example, we were faced with the need to support large multidimensional indexes to ensure fast filtering of posts, but our attempt to optimize the data storage scheme to ensure maximum query execution speed led to an exponential increase in the size of both the indexes and the data itself, as a result of which we realized that not we will be able to maintain such a base because of its RAM requirements. As a result, we found a rather beautiful solution that ensured high speed of execution of all queries without excessive increase in the size of indexes and data. However, despite the fact
RESULT
If you are interested to see what happened in the end and how it works, then for the test we posted the updated project here .
To access air tickets (if anyone wants to get in there) on the old site, use the code: i3n7wt0a8el
If you throw the post somewhere, then tell me where. Thanks in advance for the feedback. In many respects, we had to move quickly (in time for the holiday season) and intuitively, because a similar system was built for the first time. We will be happy to answer your questions.