Low-level implementation of the trie prefix tree in PHP
Foreword
The implementation of trie in PHP described here makes a too-fat dictionary, which, respectively, is loaded into memory for quite a long time, which levels out quite a good speed of its work. Search speed is ~ 80 thousand words per second. The dictionary is made from the list of lecmas of the opencorpora.org dictionary and includes 389844 words. The uncompressed dictionary weighs ~ 150mb, and the compressed gzip ~ 6mb. However, quite good performance results prove that in pure PHP you can make a fully functional prefix tree trie.
In advance, I ask programmers with the makings of literary critics not to write malicious comments. This article should be interesting to beginners, like myself. Those who are too lazy to read can immediately see the code on github .
How it all began
For quite some time now I have been carrying out the idea of writing a morphological analyzer for my PHP projects, which will be able to quickly carry out a morphological analysis of given words, as well as the transformation of words into the desired morphological form.
PHP already has a similar library called phpmorhy. It works quite quickly and I would use it and would not invent anything, but the dictionary compiler in it is made as a separate non-PHP application, which makes it impossible for me to use this library. The library itself is built on the basis of the AOT dictionary that has not been updated for a long time, which further reduces its usefulness.
Weeks and months went by, I read the article of the habrovchanin, then the articleI. Segalovich about the fast morphological algorithm for a search engine, then a bunch of different articles.
Little by little I was ripe to write my own
I took the opencorpora.org dictionary, put it in mysql and got a search speed of 2 thousand words per second. I need to load the dictionary into memory, I think. And here it turns out that in order to be available in PHP by regular data structures like an array or an object, it is necessary to store a dictionary for 3 million. About 2 GB of RAM is needed. All trie implementations in php that I came across were suitable only as a tutorial for demonstrating the logic of the work, since they themselves were built on native PHP data storage structures.
Dictionary storage device and working principle
Wherever I managed to read, listen or watch about the prefix tree trie is not explained exactly how the data will be stored in memory. Here we have a knot, but his heirs, but the flag is the end of the word that is not shown under the hood. Therefore, the storage method I had to invent myself.
As is known, the prefix tree trie consists of nodes. The node stores the prefix, links to subsequent nodes (descendants) and a pointer to the fact that this prefix is the last in the chain. Quite lucidly about trie tells a Hindu here .
The nodes in my trie implementation are fixed-length data blocks of 154 bytes. The first 6 bytes (48 bits) contain the bit mask of the heirs. The first 46 bits are the Russian alphabet, numerals, quotes, hyphens and apostrophes. An apostrophe has been added because the opencorpora.org dictionary contains the word “iv dévoire”, which uses exactly the apostrophe sign. The 47th bit is used to store the word end flag. The following 148 bytes after the bitmask are used to store references to node heirs. 3 bytes for each character (46 * 3 = 148).
Nodes are stored as binary data in a row. Access to the desired site is carried out using the functions substr () and subsequent unpacking unpack ().
The use of fixed-length nodes simplifies the addressing process. To switch to the desired node, it is enough to know its sequence number (id) and the length of the node. We multiply the sequence number by the length and find out the offset relative to the beginning of the line - everything is very simple.
rice 1 Storage Scheme
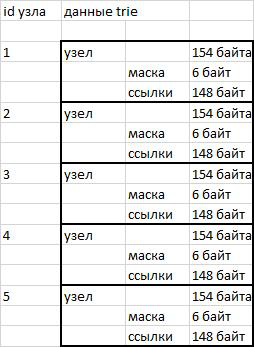
disadvantages
The storage scheme used simplifies addressing, but it devours the place. To store 380 thousand words requires just over a million nodes. 154 bytes * 1,000,000 nodes = 146.86 megabytes. Those. about 400 bytes per word. If you write words into a plain text file in utf8 encoding, then the same 380 thousand words can fit in 16 megabytes.
Plans
In order to use memory more rationally, I want to go to a variable length of nodes, then, as a reference, it is necessary to record not the node id, but its location in bytes. Determining where the link to the desired node will be stored will be as follows. For example, the word "abb".
The letter “a” is the first in the alphabet, so the node is also the first one, respectively, the offset 0. We read 6 bytes, starting from 0.
$str = substr($dic, 0, 6);Unpack the line:
$mask = (ord($str[5]) << 40) + (ord($str[4]) << 32) + (ord($str[3]) << 24) + (ord($str[2]) << 16) + (ord($str[1]) << 8) + ord($str[0]);We look in the mask of the 2nd bit (the letter "b")
bit_get($mask, 2);The bit is set, now we count the number of raised bits in the mask to 2. Assume that the bits of the letter “a” in our node are also raised, so our bit of the letter “b” will be the second bit raised. We consider the offset to read the link.
$offset = 6 + 3;6 bytes mask + 3 bytes, which occupies the first link, it turns out 9 bytes. We read the necessary piece of a line.
$str = substr($dic, $offset, 3);Unpack the link:
$ref = (ord($str[2]) << 16) + (ord($str[1]) << 8) + ord($str[0]);Go to the next node and repeat everything again. In the last letter we check the presence of 47 bits in the mask, if it is installed - there is a word in our trie.
I hope that it will be possible to keep the speed not lower than 50 thousand words per second.
Acknowledgments
I want to thank the forum participants nulled.cc and php.ru for their help with bitwise functions.









