Mybuild - build system for modular applications
 A recent article about the new build system for Qt reminded me of the situation that was in our project several years ago - then we were also looking for a suitable build system. The project is quite complex and it needs to have a flexible configuration system. As a result, we now use and develop our own build system Mybuild .
A recent article about the new build system for Qt reminded me of the situation that was in our project several years ago - then we were also looking for a suitable build system. The project is quite complex and it needs to have a flexible configuration system. As a result, we now use and develop our own build system Mybuild . Who cares to find out what we did, and what kind of project it is that needed its own build system, welcome to cat.
about the project
 Our project is called Embox . It is a modular and configurable OS for embedded systems. As you can see, configurability was originally laid down in the idea of the project, hence the desire to have a flexible build system.
Our project is called Embox . It is a modular and configurable OS for embedded systems. As you can see, configurability was originally laid down in the idea of the project, hence the desire to have a flexible build system. Initially, the project was small (although it is now not very large), and we had enough self-made makefiles, in them we also set all the configuration options. With the development of the project, ideas appeared how we could describe not just the source code for the assembly, but the modules, and even be able to set parameters for them, write dependencies, and so on.
Another build system
As often happens, appetite comes with eating. Functionality (and along with it crutches) grew like a snowball, it became quite unprofitable to maintain the resulting build infrastructure, and it was simply uncomfortable, and at one point we decided to stop and look first at the ready-made solutions.
Criticism of Make and its derivatives can be found in the mapron article , which I mentioned at the beginning. I add that in our case we also considered the Kbuild assembly system used in the Linux kernel. I allow myself a little criticism of her.
- Assembly and configuration files are separated. Therefore, you have to describe in several places (Makefile + Kconfig).
- Configuration parameters are set by #define directives, which sometimes leads to "#ifdef nightmare" in the code.
- No namespaces for options.
Of course, there are advantages:
- Kbuild supports specifying dependencies between options.
- There are several graphical (and pseudo-graphical) configuration tools.
- Sustainable development and community support.
One way or another, at that time it seemed to us that such a system was too complicated for a relatively small project. In addition, we already had small developments, and therefore it was decided to formulate the requirements and try to implement our assembly system.
So, we want to:
- Application modules were described in a simple, intuitive language, preferably together with the available configuration options.
- The module description, if possible, contained all the necessary information for its further use, including user documentation, available unit tests and so on.
- The build system did not drag out a lot of dependencies like a Python interpreter or a Java machine.
Since we started with regular makefiles, the resulting build system is written in pure GNU Make.
A bit about implementation
Saying "on pure GNU Make", I was a little cunning. If you ever tried to write something more complicated than examples from the manual, you probably also drew attention to the poverty of the built-in language. Therefore, the first thing we started with is the fight against the wretchedness of the language. In general, this topic deserves a separate article in the “Abnormal Programming” hub, here I will only touch on the main points (maybe someone will come in handy in my projects).
Improving Make Syntax
Make is a line-based language, so when writing complex functions in multiple lines, a backslash is used. Besides the fact that this is just inconvenient, it prevents the use of comments inside the function, since Make has only single-line comments (starting with a grid and valid until the end of the line).
Having fixed this restriction, we can now write multiline functions without backslashes, using comments inside functions and code indentation (in tabs or spaces). In addition, we added features such as lambda expressions, inline simple functions, and others to the language. Here’s how you can now rewrite, for example, the function of turning the list:
It was | Has become |
|---|---|
| |
Add OOP
Now that you can write more or less readable code, add one more bun. There is no typing in Make; any data is represented as a string. However, in any application there is a need to structure the data, so we implemented a set of macros that allows you to define classes, as well as functions for creating objects, calling methods, etc. For example, the following code when calling the greet function displays “Privet, Habrahabr”.
define class-Greeter
$(field greeting,
$(or $(value 1),Hello))
# Arg 1: who to greet.
$(method sayHello,
$(info $(get-field greeting), $1!))
endef
define greet
$(for greeter <- $(new Greeter,Privet),
$(invoke greeter->sayHello,Habrahabr)
$(greeter))# <- Return the instance.
endef
After these two improvements, development went much faster, allowing us to tackle the logic of the build system itself.
Thinking about the syntax
First you need to determine the language for the description of modules and configurations. As a rule, an internal or external DSL is used for a new language. An internal DSL is a subset of some general-purpose language, usually one that you plan to use for interpretation. In the case of GNU Make and its clumsy language, this is not at all an option, and only the external DSL remains, that is, an independent language for describing the assembly.
I will not beat around the bush and say right away that the resulting language is very similar to Java. Personally, I like the Java syntax, although it is verbose, but in many ways simple and straightforward. Like Java, Mybuild DSL has packages and imports, and the module description is similar to the class description. Files written in this language, we call my-files (by their extension).
/* Our first example */
module HelloWorld {
source "hello.c"
}
Building a language parser
Now you need to implement the parser of this language. There are also many options, ranging from a self-written parser, using, for example, the recursive descent method or some kind of library of combinators, and ending with various parser generators. As a result of several experiments, we settled on the latter option, as the most general, and therefore convenient for development, especially at the stage of active development of the language. We took GOLD Parser Builder (http://goldparser.org/) as the generator, it uses a simple grammar description language, has a built-in debugger, and most importantly, it has the ability to flexibly configure the generated parser (in our case, it is also implemented on Make )
The result of the parser is a parse tree.

Building an object model
So, I want to extract as much information from my files as possible, as well as have easy access to it at all stages of the assembly. It is clear that you need to have some kind of internal representation. That is, now you need to turn the parse tree into a semantic model.
At about the same stage, we simultaneously thought about language support from any IDE. In our case, this is Eclipse, since more than half of the developers in the project use this particular environment. To develop the plugin, we used the Xtext framework , which grammar can generate a full-fledged editor with syntax highlighting, auto-completion and other joys of the modern IDE. It’s worth saying here that Xtext itself is based on EMF- A well-known modeling framework. This prompted the idea to use EMF technology to develop the assembly system itself.
Thus, we get an EMF model describing the structure of our DSL (we were kindly generated by Xtext). Now you need to turn the model into classes on Make. Here the Xpand project comes to our aid (it is developed by the same company as Xtext), which allows us to generate text from the model using the template.
The last step is to write a glue-code that creates model objects for the necessary nodes of the parse tree.
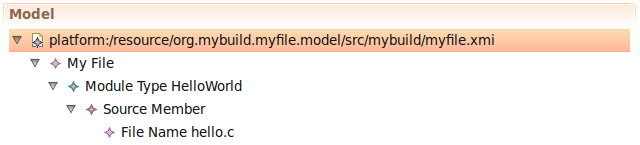
Back to the requirements
Dependencies
One of the first points in our requirements was the ability to define inter-module dependencies. First of all, this is necessary to simplify the configuration of the final application by the user.
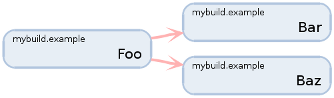
In the my-file, the designation of the dependence is as follows.
module Foo {
depends Bar, Baz
}
Now that we have a complete graph of all the modules described in the project, constructing the closure of the subgraph of the required modules is quite simple.
For ease of development, Mybuild can visualize a graph of modules using Graphviz . And as an example, here's a graph visualization of the modules for one of the simple Embox configurations.

Runtime boot order
Having a complete understanding of the system modules and the dependencies between them, why not use this knowledge for anything other than the actual assembly of the project? For example, based on this information, you can determine the order in which modules are loaded during system execution. Indeed, as a rule, loading a module only makes sense after loading all of its dependencies.
To do this, the assembly includes a specially generated source in C, in which the nodes and edges of the dependency graph are statically defined. When compiling the modules themselves, it is possible to associate with the module the function of its initialization, which will be called by the bootloader manager after resolving all the dependencies.
Build Options and Options
The next task that we decided was to specify the parameters for specific modules. The construction is used to describe the parameter
option, and access to the parameter value can be obtained at compile time, using a special macro. | |
configuration Main {
include HelloWorld(greeting = "Hello, Habrahabr!")
}
Linker Script Processing
The next problem, which was somewhat specific for the project, was that we wanted to process not only the source codes (in C and assembler languages) and header files, but also other resources, in our case, for example, special linker scripts. The makefile for preprocessing and including an additional linker script in the assembly in the previous version of the build system was the following (moreover, such code had to be written for each special linker script).
$(IMAGE): $($_heap_lds)
$($_heap_lds): $($_SELFDIR)/heap.lds.S $(AUTOCONF_DIR)/config.lds.h
@$(MKDIR) $(@D) \
&& $(CPP) -P -undef $(CPPFLAGS) \
-imacros $(AUTOCONF_DIR)/config.lds.h \
-MMD -MT $@ -MF $@.d -o $@ $<
-include $($_heap_lds).d
Now it looks like this, and the build system decides for itself what to do with the heap.lds.S file:
module HeapAlloc {
source "heap.lds.S"
}
Processing other resources
In the previous example, the definition of the type of file specified in source occurred by its extension (.lds.S). Sometimes it is required to mark certain files so that they are processed in a special way. For example, in our project, these are files whose contents should be available at runtime.
Here we used the annotation mechanism, borrowed again from Java. The first thing that we implemented with their help is the ability to mark a resource as requiring copying to a folder with a root file system, that is:
module Httpd {
@ InitFS source "index.html"
}
Annotations can be set for any type of objects in our system, whether it be modules, their dependencies, files with source code or parameters, as well as other annotations. Thus, we hope that the language has good opportunities for its expansion.
Inheritance and abstract modules
And finally, I will describe one very interesting, in my opinion, feature that we have not seen in other similar projects, namely the ability to specify interfaces and their implementations.
Since we have a highly configurable OS, we need a simple opportunity to change such system algorithms as, for example, a planning strategy. Not a scheduling policy that is set for each process using flags
SCHED_FIFOorSCHED_OTHER, namely, the algorithm by which the scheduler manages all threads (possibly, given the policy). For example, now the project implements three planning strategies. For the simplest systems, you can use a primitive scheduler that does not take into account either priorities or other flow attributes. And there is a strategy that uses priorities and takes into account how long the thread has been running. It was a small digression. So, there was a need for at least simple inheritance, so that you can describe the requirements for the system using interfaces, and determine its specific properties using their implementations. Well, since there was a need, we decided it in this way:
@ DefaultImpl(TrivialSchedStrategy)
abstract module SchedStrategy { }
module TrivialSchedStrategy extends SchedStrategy {
source "trivial.c", "trivial.h"
}
module PriorityBasedSchedStrategy extends SchedStrategy {
source "priority_based.c", "priority_based.h"
}
As you can see, the annotation (
@DefaultImpl) here also did not exist, in this case, if the configuration does not explicitly specify the module that implements SchedStrategy, then the module is used by default TrivialSchedStrategy.Conclusion
This, of course, is not all the capabilities of our system, for example, you can still specify specific compilation flags for a module, associate a set of unit tests with it, and so on. But I'm afraid that the article turned out to be overloaded anyway, so whoever is interested in learning more about Mybuild, maybe feel it with his hands or even look into the code, he may find more information on the project wiki .
Of course, much remains to be realized and polished. At a minimum, we have not yet tried to untie Mybuild from the parent Embox project, in some pieces there is not enough documentation and so on.
References
Thank you for reading to the end, I will be glad to answer your questions and suggestions in the comments.