Adult Containers (Part 01): A Practical Terminology Guide
You may ask, why deal with terminology if the concept of containers looks quite simple and understandable? However, quite often incorrect use of terms creates obstacles to the development of containers. For example, people often believe that the terms “containers” and “images” are interchangeable, although in fact there are important conceptual differences between them. Another example: in the container world, the “repository” means not at all what you think. In addition, container technology is much more than just docker.

So, without mastering the terminology, it will be difficult to understand how docker differs from CRI-O, rkt or lxc / lxd; or assess the role of the Open Container Initiative in standardizing container technologies.
Getting started with Linux containers is easy, but it soon becomes clear that this simplicity is deceptive. This usually happens like this: having spent just a couple of minutes installing a docker or another container engine, you are already entering your first commands. Another couple of minutes - and you have already created your first image of the container and posted it to the public. Then you habitually go to the production-environment architecture, and then suddenly you realize that for this you need to first deal with the mass of terms and technologies that are behind all this. Worse, many of the following terms are used interchangeably, which creates a lot of confusion for newbies.
Having mastered the terminology outlined in this document, you will better understand the technological basis of the containers. In addition, it will help you and your colleagues speak the same language, as well as consciously and purposefully design the architecture of container environments according to the specifics of the tasks to be solved. In turn, from the point of view of the IT community and the industry as a whole, the overall growth in the understanding of container technologies contributes to the emergence of new architectures and solutions. Please note that this article is intended for a reader who already has an idea of how to run containers.
Before turning to the terminology of containers, we define what the container itself is. The term “container” means two things at once. Like a regular Linux program, a container can be in one of two states: working and non-working. In a non-running state, a container is a file or a set of files stored on disk. The terms Container Image and Container Repository are related to this condition. When you enter the container launch command, the container engine unpacks the necessary files and metadata and sends them to the Linux kernel. Running a container is very similar to running a regular Linux process and requires API calls to the Linux kernel. This API call usually initiates additional isolation and mounts a copy of the files that are in the container image. After the container is running, this is just a linux process. The procedure for launching containers, as well as the format of the images of containers stored on disk, are defined and regulated by standards.
There are several container image formats ( Docker , Appc , LXD ), but the industry is gradually moving towards a single standard Open Container Initiative , sometimes called Open Containers or simply OCI. This standard specifies the container image format specification.which defines a disk format for storing container images, as well as metadata, which, in turn, determine such things as hardware architecture and operating system (Linux, Windows, etc.). A single industry-wide image format is key to the emergence of a software ecosystem that allows developers, Open Source projects, and software vendors to create compatible images and various tools, such as electronic signatures, scanning, assembling, launching, moving, and managing container images.
In addition, there are several container engines, such as Docker , CRI-O , Railcar , RKT , LXC. The container engine takes the image of the container and turns it into a container (that is, into a running process). The procedure for such a transformation is also defined by the OCI standard, which includes the container execution specification and the reference implementation of the runtime environment, called RunC, which is an open source model that is regulated by the corresponding development community. Many container engines use this model to interact with the host kernel when creating containers.
Tools that support container image format and container runtime specificationsOCI standards provide portability across the ecosystem of various container platforms, container engines and supporting tools on various cloud platforms and local architectures. Understanding the terminology, standards and architecture of container systems will allow you to fruitfully communicate with other professionals and design scalable and supported containerized applications and environments that ensure productive use of containers for years to come.
In the simplest definition, a container image is a file that is downloaded from the registry server and is used locally as a mount point when the container is started. Despite the fact that the term "container image" is used quite often, it can mean different things. The fact is that although Docker, RKT and even LXD work on the principle just described - that is, they download remote files and run them as containers, each of these technologies interprets the image of the container in its own way. LXD operates with monolithic (single-layer) images, and docker and RKT use OCI images, which can contain several layers.
Strictly speaking, the container image on the registry server is far from one file. When people use the term “container image”, they often mean a repository and mean a set of container image layers and metadata that contain additional information about these layers.
In addition, the concept of a container image implicitly implies the existence of a format for such an image.
Initially, each container engine, including LXD, RKT and Docker, had its own image format. Some of these formats allow only one layer, others support a tree structure of several layers. Today, almost all the basic container tools and engines have switched to the OCI format , which defines how the layers and metadata should be arranged in the container image. In fact, the OCI format defines an image of a container, which consists of separate tar files for each layer and a common manifest.json file containing metadata.
The standard Open Container Initiative (OCI) , which was originally based on the Docker V2 image format, successfully combined a large ecosystem of container engines, cloud platforms and tools (security scanners, tools for signing, creating and moving containers) and allows you to protect your investment in knowledge and tools.
The container engine is the part of the software that accepts user requests, including command line parameters, downloads images and, from the end user's point of view, launches containers. There are many container engines, including docker, RKT, CRI-O and LXD. In addition, many cloud platforms, PaaS services and container platforms have their own engines that understand Docker or OCI format. The presence of an industry standard for image format ensures the interoperability of all these platforms.
Going down a level, we can say that most container engines actually run containers not themselves, but through an OCI-compatible runtime environment, like runc. Usually, the container runtime does the following things:
Containers have existed in operating systems for quite some time, because in fact it is just a running instance of a container image. A container is a standard Linux process that is usually created using the clone () system call instead of fork () or exec (). In addition, additional isolation measures are often applied to containers using cgroups , SELinux, or AppArmor .
A container host is a system on which containerized processes are run, which are often called containers for simplicity. This could be, for example, a virtual machine RHEL Atomic Host , located in a public cloud or running on bare hardware in a corporate data center. When the container image (in other words, the repository) from the registry server is downloaded to the local container host, it is said that it gets into the local cache.
To determine which repositories are synchronized with the local cache, use the following command:
The registry server is essentially a file server that is used to store docker repositories. Typically, the registry server is specified by the DNS name and, optionally, the port number. Most of the benefits of the docker ecosystem are due to the ability to download and upload repositories to registry servers.

If the docker daemon does not find a copy of the repository in the local cache, it automatically downloads it from the registry server. In most Linux distributions, the docker daemon will use the docker.io site for this, but in some distributions you can configure it in your own way. For example, Red Hat Enterprise Linux first tries to boot from registry.access.redhat.com, and only then with docker.io (Docker Hub).
Here it must be emphasized that the registry server is implicitly considered trusted. Therefore, you have to decide for yourself how much you trust the contents of one or another registry and, accordingly, allow or deny it. In addition to security, there are other aspects that should be taken care of in advance, for example, software licensing issues or compliance control. The ease with which docker allows users to download software makes the issue of trust extremely important.
Red Hat Enterprise Linux allows you to configure the default docker registry. In addition, RHEL7 and RHEL7 Atomic allow you to add or block registry servers through the configuration file :
In RHEL7 and RHEL 7 Atomic, the default Red Hat registry server is used:
In some cases, for security reasons, it makes sense to block public docker registries, such as DockerHub:
Red Hat also offers its integrated registry server as part of the OpenShift Container Platform , as well as the Quay Enterprise stand-alone corporate registry server and Quay.io cloud, private and public repositories .
People usually start by installing a container host and first simply downloading the desired container images. Then they move on to creating their own images and upload them to the registry server to make available to the rest of the team. After some time, there is a need to combine several containers so that they can be deployed as one unit. And, finally, at some point, these units need to be made part of the production pipeline (development-QA-production). This is how people usually come to realize that they need an orchestration system.
The container orchestration system implements only two things:
These two things actually provide a number of benefits:
Open source communities and software vendors offer many different orchestration tools. Initially, the big three of these tools included Swarm , Mesos and Kubernetes , but today Kubernetes has actually become the industry standard, as even Docker and Mesosphere have stated their support , not to mention almost all major service providers. However, if you are looking for a corporate orchestration system, we recommend that you look at Red Hat OpenShift .
The container runtime is a low-level component that is commonly used as part of a container engine, but can also be used in manual mode for testing containers. The OCI standard defines a reference implementation of the runtime environment known as runc . This is the most widely used implementation, however there are other OCI-compliant runtimes , such as crun , railcar, and katacontainers . Docker, CRI-O and many other container engines use runc.
The container runtime is responsible for the following things:
A little historical digest: when the Docker engine first appeared, it used LXC as the runtime environment. Then the Docker developers wrote their own library for running containers called libcontainer. It was written in the Golang language and became part of the Docker engine. After establishing the OCI organization, Docker contributed the libcontainer source code to this project and released this library as a separate utility called runc, which then became the reference implementation of the container execution environment within the OCI standard and is used in other container engines such as CRI-O . Runc is a very simple utility that just waits for it to be passed a mount point (directory) and metadata (config.json). More information about runc can be found here .
For a deeper understanding, see Container Standards Overview , as well as Container Runtime .
Repositories are often called images or images of containers, although in reality the repositories consist of one or several layers. The layers of the image in the repository are interconnected by parent-child relationships, and each layer of the image contains differences from the parent layer.
Let's view the repository layers on a local container host. Since starting from version 1.7 in Docker there is no built-in tool for viewing image layers in the local repository (but there are tools for online registries), we will use the Dockviz utility . Note that each layer has a tag and a universal unique identifier (UUID). To view the abbreviated UUIDs that are usually unique within the same machine, we use the following command (if you need a full UUID, use the same command with the -no-trunc option):
docker run --rm --privileged -v / var / run / docker.sock: /var/run/docker.sock nate / dockviz images -t
As you can see, the docker.io/registry repository actually consists of multiple layers. However, more importantly, the user can, in principle, “launch” the container from any step in this ladder of layers, for example, by entering the command below (it is completely correct, but no one can guarantee that it has been tested or will work correctly at all). Typically, the image collector tags (creates names) those layers that should be used as a starting point:
Repositories are arranged in a similar way because whenever the collector creates a new image, the differences are saved as another layer. There are two main ways to create new layers in the repository. First, when creating an image manually, each confirmation of changes creates a new layer. If the collector creates an image using the Docker file, each directive in the file creates a new layer. Therefore, it is always useful to be able to see what has changed in the repository between the layers.
Although the user can specify the starting layer for mounting and launching the container in the repository, he does not need to do that. When the image collector creates a new repository, it will usually mark the layers most suitable for this role. These markers are called tags and are a tool with which the image collector can tell the image consumer which layers are best to use. Usually tags are used to indicate software versions within the repository. However, neither the OCI, nor any other standard does not regulate the use of tags, which opens up unlimited scope for confusion during collaboration. Therefore, we advise you to carefully document the tags if they are used not only for marking software versions.
In addition, there is one special tag - latest, which usually points to a layer containing the latest version of the software in the repository. This tag simply points to the image layer, like any other tag, and therefore can also be used incorrectly.
To remotely view the tags available in the repository, run the following command (the jq utility makes the output much more readable):
When using the docker command, the repository is specified on the command line, not the image. For example, in the following command, “rhel7” is a repository.
In fact, this command automatically expands to the following:
However, many believe that this is the image or the image of the container. In fact, to get a list of locally accessible repositories, the docker images subcommand is used. Formally, these repositories can be viewed as images of containers, but it is important to clearly understand that these repositories actually consist of layers and include metadata contained in a file called “manifest” (manifest.json):
Specifying the repository in the command line, we actually ask the container engine to do some of the work for us. In the example above, the docker daemon (namely the daemon, not the client tool) has a configured list of servers to search for, and therefore will look for the “rhel7” repository on each of them.
In the example above, we specified only the repository name, but in the docker client, you can also specify the full URL. To understand how to do this, we divide the full URL into its parts.

In other words, it all comes down to the form:
The full URL consists of the server name, the namespace and, optionally, the tag. In fact, when specifying a URL, there are a lot of nuances, and as you study the docker ecosystem, you will see that many things are not necessary to specify. In particular, look at the commands below: they are all correct and lead to the same result:
Namespaces are a tool for dividing repositories into groups. In the DockerHub public registry, the namespace is usually the name of the user who shared the image, but can also be a group name or a logical name.
Red Hat uses namespaces to separate groups of repositories for products listed on the Red Hat Federated Registry server . An example of the results of the survey registry.access.redhat.com below. Note that the last line in this example actually points to another registry server. This is due to the fact that Red Hat is working to display repositories on the registry servers of our partners:
Please note that sometimes the full URL can be omitted. In the example above, there is a default repository for each namespace. If the user specifies only the fedora namespace, then the repository with the latest tag is downloaded to the local server. Therefore, the following commands lead to the same result:
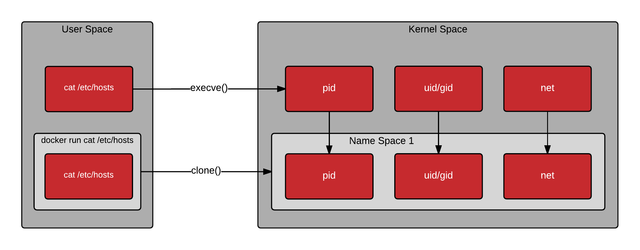
Kernel namespaces are fundamentally different from the namespaces that we discussed above when we talked about repositories and registry servers. When discussing containers, the kernel's namespace is perhaps the most important data structure, thanks to which containers exist, at least in their current form. Kernel namespaces allow each container to have its own mount points, network interfaces, user IDs, process IDs, etc.
When you enter a command in the Bash shell and press Enter, Bash asks the kernel to create a normal Linux process using the exec system call (). The container is different in that when you send a request to the container engine, for example, docker, the docker daemon asks the kernel to create a containerized process using another system call called clone () . The clone () system call is special in that it can create a process with its own virtual mount points, process IDs, user IDs, network interfaces, hostname, and so on.
Therefore, although Linux does not have a single data structure for representing containers, the kernel’s namespace and the clone () system call are the closest ones to the role.
To be continued…
So, without mastering the terminology, it will be difficult to understand how docker differs from CRI-O, rkt or lxc / lxd; or assess the role of the Open Container Initiative in standardizing container technologies.
Introduction
Getting started with Linux containers is easy, but it soon becomes clear that this simplicity is deceptive. This usually happens like this: having spent just a couple of minutes installing a docker or another container engine, you are already entering your first commands. Another couple of minutes - and you have already created your first image of the container and posted it to the public. Then you habitually go to the production-environment architecture, and then suddenly you realize that for this you need to first deal with the mass of terms and technologies that are behind all this. Worse, many of the following terms are used interchangeably, which creates a lot of confusion for newbies.
- Container
- Image (Image)
- Container Image
- Image Layer
- Registry (Registry)
- Repository (Repository)
- Tag
- Base Image
- Platform Image
- Layer (Layer)
Having mastered the terminology outlined in this document, you will better understand the technological basis of the containers. In addition, it will help you and your colleagues speak the same language, as well as consciously and purposefully design the architecture of container environments according to the specifics of the tasks to be solved. In turn, from the point of view of the IT community and the industry as a whole, the overall growth in the understanding of container technologies contributes to the emergence of new architectures and solutions. Please note that this article is intended for a reader who already has an idea of how to run containers.
Containers: Basics
Before turning to the terminology of containers, we define what the container itself is. The term “container” means two things at once. Like a regular Linux program, a container can be in one of two states: working and non-working. In a non-running state, a container is a file or a set of files stored on disk. The terms Container Image and Container Repository are related to this condition. When you enter the container launch command, the container engine unpacks the necessary files and metadata and sends them to the Linux kernel. Running a container is very similar to running a regular Linux process and requires API calls to the Linux kernel. This API call usually initiates additional isolation and mounts a copy of the files that are in the container image. After the container is running, this is just a linux process. The procedure for launching containers, as well as the format of the images of containers stored on disk, are defined and regulated by standards.
There are several container image formats ( Docker , Appc , LXD ), but the industry is gradually moving towards a single standard Open Container Initiative , sometimes called Open Containers or simply OCI. This standard specifies the container image format specification.which defines a disk format for storing container images, as well as metadata, which, in turn, determine such things as hardware architecture and operating system (Linux, Windows, etc.). A single industry-wide image format is key to the emergence of a software ecosystem that allows developers, Open Source projects, and software vendors to create compatible images and various tools, such as electronic signatures, scanning, assembling, launching, moving, and managing container images.
In addition, there are several container engines, such as Docker , CRI-O , Railcar , RKT , LXC. The container engine takes the image of the container and turns it into a container (that is, into a running process). The procedure for such a transformation is also defined by the OCI standard, which includes the container execution specification and the reference implementation of the runtime environment, called RunC, which is an open source model that is regulated by the corresponding development community. Many container engines use this model to interact with the host kernel when creating containers.
Tools that support container image format and container runtime specificationsOCI standards provide portability across the ecosystem of various container platforms, container engines and supporting tools on various cloud platforms and local architectures. Understanding the terminology, standards and architecture of container systems will allow you to fruitfully communicate with other professionals and design scalable and supported containerized applications and environments that ensure productive use of containers for years to come.
Basic dictionary
Container image
In the simplest definition, a container image is a file that is downloaded from the registry server and is used locally as a mount point when the container is started. Despite the fact that the term "container image" is used quite often, it can mean different things. The fact is that although Docker, RKT and even LXD work on the principle just described - that is, they download remote files and run them as containers, each of these technologies interprets the image of the container in its own way. LXD operates with monolithic (single-layer) images, and docker and RKT use OCI images, which can contain several layers.
Strictly speaking, the container image on the registry server is far from one file. When people use the term “container image”, they often mean a repository and mean a set of container image layers and metadata that contain additional information about these layers.
In addition, the concept of a container image implicitly implies the existence of a format for such an image.
Container image format
Initially, each container engine, including LXD, RKT and Docker, had its own image format. Some of these formats allow only one layer, others support a tree structure of several layers. Today, almost all the basic container tools and engines have switched to the OCI format , which defines how the layers and metadata should be arranged in the container image. In fact, the OCI format defines an image of a container, which consists of separate tar files for each layer and a common manifest.json file containing metadata.
The standard Open Container Initiative (OCI) , which was originally based on the Docker V2 image format, successfully combined a large ecosystem of container engines, cloud platforms and tools (security scanners, tools for signing, creating and moving containers) and allows you to protect your investment in knowledge and tools.
Container engine
The container engine is the part of the software that accepts user requests, including command line parameters, downloads images and, from the end user's point of view, launches containers. There are many container engines, including docker, RKT, CRI-O and LXD. In addition, many cloud platforms, PaaS services and container platforms have their own engines that understand Docker or OCI format. The presence of an industry standard for image format ensures the interoperability of all these platforms.
Going down a level, we can say that most container engines actually run containers not themselves, but through an OCI-compatible runtime environment, like runc. Usually, the container runtime does the following things:
- Handles user input
- Processes parameters passed through an API (most often with a container orchestration system)
- Download container images from registry server
- Unpacks and saves the image of the container to disk using the Graph Driver driver (block or file, depending on the driver)
- Prepares the mount point of the container, usually in the copy-on-write repository (again, block or file, depending on the driver)
- Prepares the metadata that will be passed to the runtime environment to correctly start the container using:
- Causes the container runtime.
Container
Containers have existed in operating systems for quite some time, because in fact it is just a running instance of a container image. A container is a standard Linux process that is usually created using the clone () system call instead of fork () or exec (). In addition, additional isolation measures are often applied to containers using cgroups , SELinux, or AppArmor .
Container host
A container host is a system on which containerized processes are run, which are often called containers for simplicity. This could be, for example, a virtual machine RHEL Atomic Host , located in a public cloud or running on bare hardware in a corporate data center. When the container image (in other words, the repository) from the registry server is downloaded to the local container host, it is said that it gets into the local cache.
To determine which repositories are synchronized with the local cache, use the following command:
[root @ rhel7 ~] # docker images -a REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE registry.access.redhat.com/rhel7 latest 6883d5422f4e 3 weeks ago 201.7 MB
Registry Server
The registry server is essentially a file server that is used to store docker repositories. Typically, the registry server is specified by the DNS name and, optionally, the port number. Most of the benefits of the docker ecosystem are due to the ability to download and upload repositories to registry servers.
If the docker daemon does not find a copy of the repository in the local cache, it automatically downloads it from the registry server. In most Linux distributions, the docker daemon will use the docker.io site for this, but in some distributions you can configure it in your own way. For example, Red Hat Enterprise Linux first tries to boot from registry.access.redhat.com, and only then with docker.io (Docker Hub).
Here it must be emphasized that the registry server is implicitly considered trusted. Therefore, you have to decide for yourself how much you trust the contents of one or another registry and, accordingly, allow or deny it. In addition to security, there are other aspects that should be taken care of in advance, for example, software licensing issues or compliance control. The ease with which docker allows users to download software makes the issue of trust extremely important.
Red Hat Enterprise Linux allows you to configure the default docker registry. In addition, RHEL7 and RHEL7 Atomic allow you to add or block registry servers through the configuration file :
vi / etc / sysconfig / docker
In RHEL7 and RHEL 7 Atomic, the default Red Hat registry server is used:
ADD_REGISTRY = '- add-registry registry.access.redhat.com'
In some cases, for security reasons, it makes sense to block public docker registries, such as DockerHub:
# BLOCK_REGISTRY = '- block-registry'
Red Hat also offers its integrated registry server as part of the OpenShift Container Platform , as well as the Quay Enterprise stand-alone corporate registry server and Quay.io cloud, private and public repositories .
Container Orchestration
People usually start by installing a container host and first simply downloading the desired container images. Then they move on to creating their own images and upload them to the registry server to make available to the rest of the team. After some time, there is a need to combine several containers so that they can be deployed as one unit. And, finally, at some point, these units need to be made part of the production pipeline (development-QA-production). This is how people usually come to realize that they need an orchestration system.
The container orchestration system implements only two things:
- Dynamically dispatch container loads across cluster computers (often referred to as “distributed computing”)
- Provides a standard application description file (kube yaml, docker compose, etc.)
These two things actually provide a number of benefits:
- The ability to manage the containers that make up the application, independently of each other, which allows to effectively solve the following tasks:
- Recycling large clusters of container hosts
- Fulfillment of failures at the level of individual containers (processes that have ceased to respond, memory exhaustion)
- Failover at the level of container hosts (disks, network, reboot)
- Fault handling at the container engine level (damage, restart)
- Individual scaling of containers up and down
- Ease of deploying new instances of the same application in new environments, both cloud and traditional, for example:
- On machines of developers controlled by the orchestration system
- In a shared development environment in a private namespace
- In a shared development environment in an internal public namespace for visibility and testing
- In QA internal environment
- In a test load environment dynamically exposed and revoked in the cloud
- In a reference environment to check production compatibility
- In production environment
- In a disaster recovery environment
- In a new production environment containing updated container hosts, container engines or orchestration tools
- In the new production environment, which is no different from the main, but located in a different region
Open source communities and software vendors offer many different orchestration tools. Initially, the big three of these tools included Swarm , Mesos and Kubernetes , but today Kubernetes has actually become the industry standard, as even Docker and Mesosphere have stated their support , not to mention almost all major service providers. However, if you are looking for a corporate orchestration system, we recommend that you look at Red Hat OpenShift .
Advanced Dictionary
Container Runtime
The container runtime is a low-level component that is commonly used as part of a container engine, but can also be used in manual mode for testing containers. The OCI standard defines a reference implementation of the runtime environment known as runc . This is the most widely used implementation, however there are other OCI-compliant runtimes , such as crun , railcar, and katacontainers . Docker, CRI-O and many other container engines use runc.
The container runtime is responsible for the following things:
- Gets the mount point of the container provided by the container engine (for testing it may just be a directory)
- Receives container metadata provided by the container engine (during testing this can be a manually assembled config.json file)
- Communicates with the OS kernel to start containerized processes (via the clone system call)
- Configures cgroups
- Configures SELinux Policy
- Configures App Armor Rules
A little historical digest: when the Docker engine first appeared, it used LXC as the runtime environment. Then the Docker developers wrote their own library for running containers called libcontainer. It was written in the Golang language and became part of the Docker engine. After establishing the OCI organization, Docker contributed the libcontainer source code to this project and released this library as a separate utility called runc, which then became the reference implementation of the container execution environment within the OCI standard and is used in other container engines such as CRI-O . Runc is a very simple utility that just waits for it to be passed a mount point (directory) and metadata (config.json). More information about runc can be found here .
For a deeper understanding, see Container Standards Overview , as well as Container Runtime .
Image layers
Repositories are often called images or images of containers, although in reality the repositories consist of one or several layers. The layers of the image in the repository are interconnected by parent-child relationships, and each layer of the image contains differences from the parent layer.
Let's view the repository layers on a local container host. Since starting from version 1.7 in Docker there is no built-in tool for viewing image layers in the local repository (but there are tools for online registries), we will use the Dockviz utility . Note that each layer has a tag and a universal unique identifier (UUID). To view the abbreviated UUIDs that are usually unique within the same machine, we use the following command (if you need a full UUID, use the same command with the -no-trunc option):
docker run --rm --privileged -v / var / run / docker.sock: /var/run/docker.sock nate / dockviz images -t
23─2332d8973c93 Virtual Size: 187.7 MB │ └─ea358092da77 Virtual Size: 187.9 MB │ └─a467a7c6794f Virtual Size: 187.9 MB │ └─ca4d7b1b9a51 Virtual Size: 187.9 MB │ └─4084976dd96d Virtual Size: 384.2 MB │ └─943128b20e28 Virtual Size: 386.7 MB │ └─db20cc018f56 Virtual Size: 386.7 MB │ └─45b3c59b9130 Virtual Size: 398.2 MB │ └─91275de1a5d7 Virtual Size: 422.8 MB │ └─e7a97058d51f Virtual Size: 422.8 MB │ └─d5c963edfcb2 Virtual Size: 422.8 MB │ └─5cfc0ce98e02 Virtual Size: 422.8 MB │ └─7728f71a4bcd Virtual Size: 422.8 MB │ └─0542f67da01b Virtual Size: 422.8 MB Tags: docker.io/registry:latest
As you can see, the docker.io/registry repository actually consists of multiple layers. However, more importantly, the user can, in principle, “launch” the container from any step in this ladder of layers, for example, by entering the command below (it is completely correct, but no one can guarantee that it has been tested or will work correctly at all). Typically, the image collector tags (creates names) those layers that should be used as a starting point:
docker run -it 45b3c59b9130 bash
Repositories are arranged in a similar way because whenever the collector creates a new image, the differences are saved as another layer. There are two main ways to create new layers in the repository. First, when creating an image manually, each confirmation of changes creates a new layer. If the collector creates an image using the Docker file, each directive in the file creates a new layer. Therefore, it is always useful to be able to see what has changed in the repository between the layers.
Tags
Although the user can specify the starting layer for mounting and launching the container in the repository, he does not need to do that. When the image collector creates a new repository, it will usually mark the layers most suitable for this role. These markers are called tags and are a tool with which the image collector can tell the image consumer which layers are best to use. Usually tags are used to indicate software versions within the repository. However, neither the OCI, nor any other standard does not regulate the use of tags, which opens up unlimited scope for confusion during collaboration. Therefore, we advise you to carefully document the tags if they are used not only for marking software versions.
In addition, there is one special tag - latest, which usually points to a layer containing the latest version of the software in the repository. This tag simply points to the image layer, like any other tag, and therefore can also be used incorrectly.
To remotely view the tags available in the repository, run the following command (the jq utility makes the output much more readable):
curl -s registry.access.redhat.com/v1/repositories/rhel7/tags | jq
{
"7.0-21": "e1f5733f050b2488a17b7630cb038bfbea8b7bdfa9bdfb99e63a33117e28d02f",
"7.0-23": "bef54b8f8a2fdd221734f1da404d4c0a7d07ee9169b1443a338ab54236c8c91a",
"7.0-27": "8e6704f39a3d4a0c82ec7262ad683a9d1d9a281e3c1ebbb64c045b9af39b3940",
"7.1-11": "d0a516b529ab1adda28429cae5985cab9db93bfd8d301b3a94d22299af72914b",
"7.1-12": "275be1d3d0709a06ff1ae38d0d5402bc8f0eeac44812e5ec1df4a9e99214eb9a",
"7.1-16": "82ad5fa11820c2889c60f7f748d67aab04400700c581843db0d1e68735327443",
"7.1-24": "c4f590bbcbe329a77c00fea33a3a960063072041489012061ec3a134baba50d6",
"7.1-4": "10acc31def5d6f249b548e01e8ffbaccfd61af0240c17315a7ad393d022c5ca2",
"7.1-6": "65de4a13fc7cf28b4376e65efa31c5c3805e18da4eb01ad0c8b8801f4a10bc16",
"7.1-9": "e3c92c6cff3543d19d0c9a24c72cd3840f8ba3ee00357f997b786e8939efef2f",
"7.2": "6c3a84d798dc449313787502060b6d5b4694d7527d64a7c99ba199e3b2df834e",
"7.2-2": "58958c7fafb7e1a71650bc7bdbb9f5fd634f3545b00ec7d390b2075db511327d",
"7.2-35": "6883d5422f4ec2810e1312c0e3e5a902142e2a8185cd3a1124b459a7c38dc55b",
"7.2-38": "6c3a84d798dc449313787502060b6d5b4694d7527d64a7c99ba199e3b2df834e",
"latest": "6c3a84d798dc449313787502060b6d5b4694d7527d64a7c99ba199e3b2df834e"
}
Repository
When using the docker command, the repository is specified on the command line, not the image. For example, in the following command, “rhel7” is a repository.
docker pull rhel7
In fact, this command automatically expands to the following:
docker pull registry.access.redhat.com/rhel7:latest
However, many believe that this is the image or the image of the container. In fact, to get a list of locally accessible repositories, the docker images subcommand is used. Formally, these repositories can be viewed as images of containers, but it is important to clearly understand that these repositories actually consist of layers and include metadata contained in a file called “manifest” (manifest.json):
docker images REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE registry.access.redhat.com/rhel7 latest 6883d5422f4e 4 weeks ago 201.7 MB registry.access.redhat.com/rhel latest 6883d5422f4e 4 weeks ago 201.7 MB registry.access.redhat.com/rhel6 latest 05c3d56ba777 4 weeks ago 166.1 MB registry.access.redhat.com/rhel6/rhel latest 05c3d56ba777 4 weeks ago 166.1 MB ...
Specifying the repository in the command line, we actually ask the container engine to do some of the work for us. In the example above, the docker daemon (namely the daemon, not the client tool) has a configured list of servers to search for, and therefore will look for the “rhel7” repository on each of them.
In the example above, we specified only the repository name, but in the docker client, you can also specify the full URL. To understand how to do this, we divide the full URL into its parts.
In other words, it all comes down to the form:
REGISTRY / NAMESPACE / REPOSITORY [: TAG]
The full URL consists of the server name, the namespace and, optionally, the tag. In fact, when specifying a URL, there are a lot of nuances, and as you study the docker ecosystem, you will see that many things are not necessary to specify. In particular, look at the commands below: they are all correct and lead to the same result:
docker pull registry.access.redhat.com/rhel7/rhel:latest docker pull registry.access.redhat.com/rhel7/rhel docker pull registry.access.redhat.com/rhel7 docker pull rhel7 / rhel: latest
Namespaces
Namespaces are a tool for dividing repositories into groups. In the DockerHub public registry, the namespace is usually the name of the user who shared the image, but can also be a group name or a logical name.
Red Hat uses namespaces to separate groups of repositories for products listed on the Red Hat Federated Registry server . An example of the results of the survey registry.access.redhat.com below. Note that the last line in this example actually points to another registry server. This is due to the fact that Red Hat is working to display repositories on the registry servers of our partners:
registry.access.redhat.com/rhel7/rhel registry.access.redhat.com/openshift3/mongodb-24-rhel7 registry.access.redhat.com/rhscl/mongodb-26-rhel7 registry.access.redhat.com/rhscl_beta/mongodb-26-rhel7 registry-mariadbcorp.rhcloud.com/rhel7/mariadb-enterprise-server:10.0
Please note that sometimes the full URL can be omitted. In the example above, there is a default repository for each namespace. If the user specifies only the fedora namespace, then the repository with the latest tag is downloaded to the local server. Therefore, the following commands lead to the same result:
docker pull fedora docker pull docker.io/fedora docker pull docker.io/library/fedora:latest
Kernel namespaces
Kernel namespaces are fundamentally different from the namespaces that we discussed above when we talked about repositories and registry servers. When discussing containers, the kernel's namespace is perhaps the most important data structure, thanks to which containers exist, at least in their current form. Kernel namespaces allow each container to have its own mount points, network interfaces, user IDs, process IDs, etc.
When you enter a command in the Bash shell and press Enter, Bash asks the kernel to create a normal Linux process using the exec system call (). The container is different in that when you send a request to the container engine, for example, docker, the docker daemon asks the kernel to create a containerized process using another system call called clone () . The clone () system call is special in that it can create a process with its own virtual mount points, process IDs, user IDs, network interfaces, hostname, and so on.
Therefore, although Linux does not have a single data structure for representing containers, the kernel’s namespace and the clone () system call are the closest ones to the role.
To be continued…