MIT course "Computer Systems Security". Lecture 2: "Control of hacker attacks", part 1
- Transfer
- Tutorial
Massachusetts Institute of Technology. Lecture course # 6.858. "Security of computer systems." Nikolai Zeldovich, James Mykens. year 2014
Computer Systems Security is a course on the development and implementation of secure computer systems. Lectures cover threat models, attacks that compromise security, and security methods based on the latest scientific work. Topics include operating system (OS) security, capabilities, information flow control, language security, network protocols, hardware protection and security in web applications.
Lecture 1: "Introduction: threat models" Part 1 / Part 2 / Part 3
Lecture 2: "Control of hacker attacks" Part 1 / Part 2 / Part 3
James Mickens: From the previous lecture, we learned all about buffer overflow attacks, and today we will continue to discuss some of the methods for launching these attacks. The basic idea of an attack by buffer overflow is as follows.

First of all, I note that these attacks affect several different circumstances. The first thing they use is that the system software is often written in C.
By system software, I mean databases, compilers, network servers, and so on. You can also remember such a thing as your favorite command shell. All this “software” is usually written in C. Why in C? Because, firstly, it's faster, and secondly, C is considered a high-level assembler that best meets the needs of a wide variety of hardware platforms. Therefore, all critical systems are written in this low-level programming language. The problem with software written in C is that it actually uses “raw” memory addresses and does not have any tools or software modules to check them. In some cases, this can lead to disastrous consequences.
Why in C there is no checking of array indices, that is, there is no checking of boundaries? One of the reasons is that the hardware does not. And people who write in C usually want the highest possible speed of program execution. Another reason is that in C, as we will discuss later, it is actually very difficult to determine the semantics of what a pointer is and within what limits it should act. Therefore, in some cases, it would be very difficult to automate software processes in the C language.
Let us discuss some technologies that are actually trying to create some type of automatic memory management. But, as we will see, none of these methods is completely "bulletproof."
In addition, buffer overflow attacks use knowledge of the x86 architecture, for example, in which direction the stack grows. What is the calling convention for functions? When you access the C function, what does the stack look like? And when you select an object on the heap, what do these main selected structures look like?
Let's look at a simple example. This is very similar to what you saw in the last lecture. So, here we have a standard read request, and then we get a buffer, right here, next is the canonical int i , followed by the infamous gets command . And below we have other necessary things.

So, as we discussed at a lecture last week, this is problematic, right? Because this operation getsdoes not check buffer boundaries. If the user fills the buffer with data and we use this unsafe function here, then we can actually overflow the buffer. We can rewrite the entire contents of the stack. Let me remind you how it looks.
At the bottom is an array of "i". Above it is a buffer, at its bottom is the first address, at the top - the last one. In any case, above the buffer, we have the saved value of the break pointer - the saved value EBP. Above it is the return address for the function, and even higher are some things from the previous frame.
And do not forget that here at our bottom, to the left of “i”, we have an ESP stack pointer, which goes in there, and a new break pointer is included in the saved EBP section. The return address includes ESP, and the remainder of the previous frame - break point.

I recall that the way the stack overflows is that the accumulation of data occurs upwards, in the direction of this arrow to the right. When the gets operation is initiated, we start writing the bytes to the buffer, in the end, it will start overwriting everything that is located higher in the stack. In principle, everything should look familiar to you.
What does an attacker do to take advantage of this? Basically enters a long sequence of data. Therefore, the key idea is that such a technique can be used to attack.
And if the return address is captured by the attacker, he can determine where the function will jump after the overflow. That is, the only thing a hacker can do is intercept the return address and jump wherever he wants. Basically, attackers run code with the privileges of controlling the interception process.
So, if this process was high-priority, let's say it was started as root or admin, no matter how we call the superuser of your favorite operating system, now this program, which is controlled by the attacker, can do whatever it wants using the privileges of this priority. Thus, a hacker can read files or send spam if he has damaged the mail server. He can even beat the firewalls, because the idea of a firewall is that there are “good” machines behind it, and “bad” machines behind it. Usually, computers inside the firewall "trust" each other, and if you manage to hack at least one computer inside a secure firewall, it will be great. Because now you can just skip the many checks that these computers usually undertake in relation to "foreign" machines,
There is a thing that you should have thought about and which I thought as a student:
“Great, we were shown how to overflow the buffer, but why can't the operating system stop it? Is she not acting like the Guardians of the Galaxy, which protects good from evil things happening around? ”
It is important to note that the OS does not constantly monitor you. While the hardware observes, it extracts the instructions and decodes them and does a lot of this. But as a first approximation, what does the OS do? It basically sets the page tables that allow the application to work, and if you ask the operating system, for example, send a network packet, or you want to make some kind of IPC request, or similar things, you can contact your OS for help. But the operating system does not monitor every instruction that your application executes. In other words, when this buffer is full, the OS does not follow at all how the memory of this stack is used. All this address space belongs to you, as the initiator of the process, and this does not apply to the OS. You can do whatever you want with this, and the operating system cannot help you with problems.
Later we will discuss some things that the OS can do in relation to hardware in order to protect against this type of attack. Let me remind you again - in fact, only the hardware keeps track of what you are doing and reacts to it. Thus, you can use some special types of protection, we will discuss this further.
This is how a buffer overflow looks. How are we going to fix all these things?
One way to prevent buffer overflow is simply to avoid errors in the C code. This is a constructive approach, because if your program has no errors, then the attacker cannot use them. However, this is easier said than done. There are some very simple things that programmers can do to ensure safety “hygiene”. For example, functions such as gets, which, as we now know, can be called "go-tos", or "seize the operating system", which is a security breach.
So, when you compile your code using a modern compiler such as GCC or Visual Studio, they will point out the flaws of such functions. They will say: “Hey, you use a dangerous thing, better consider the possibility of using the fgets function or other functions that really can monitor the observance of borders.” This is one of the simple things programmers can do.
But note that many applications actually manipulate buffers without resorting to all of these functions. This is very common in network servers, which define their own parsing procedures, and then make sure that the data is extracted from the buffer as they want. Thus, simply limiting oneself with the selection of the correct command functions cannot completely solve the problem.
Another circumstance that makes this approach difficult is that it is not always obvious that the problem is caused by an error in a program written in C. If you have ever worked on a large-scale program that was written in C, you know , how difficult it is with the determinants of functions that have 18 stars above the pointer void *. I think only Zeus knows what this can mean, right? With C type languages, even a programmer can have a hard time understanding whether an error has occurred or not.
In general, one of the main topics of our lectures will be that C is the product of the devil. And we use it only because, as always, we want to be the fastest, right? But since “hardware” is getting faster and faster, we also use more “advanced” languages to write bulk system code. However, it does not always make sense to write your C code, even if you think it will be faster this way. We will discuss this issue later.

So, the first approach to solving a problem is to avoid errors in program code C, and the second is to create tools that help programmers to find such errors. An example of such a tool is static code analysis, static code analysis. Later we will talk about it in detail, and now I will say that static analysis is a way to analyze the source code of your program before it is launched, and helps to detect potential problems.
Imagine that you have such a function, call it void foo (int, * p) , it contains integer data and a pointer. Suppose it declares an integer offset value int off . This function declares another pointer and adds an offset to it: int * z = p + off. Even now, when writing a function, static code analysis can tell us that this offset variable is not initialized.

Thus, it is possible, analyzing the program, to answer the question whether our function will work properly. And in this example it is very simple to see the answer “no, not be”, because there is no initialization of the offset. Static analysis is software, and in the process of how you use a popular compiler to build your code, it will tell you: “Hey, buddy, this thing is not initialized. Are you sure you want to do that? ” This is one of the simplest examples of using static analysis.
Another example considers the case when we have a branch of a function, that is, its execution under a certain condition.
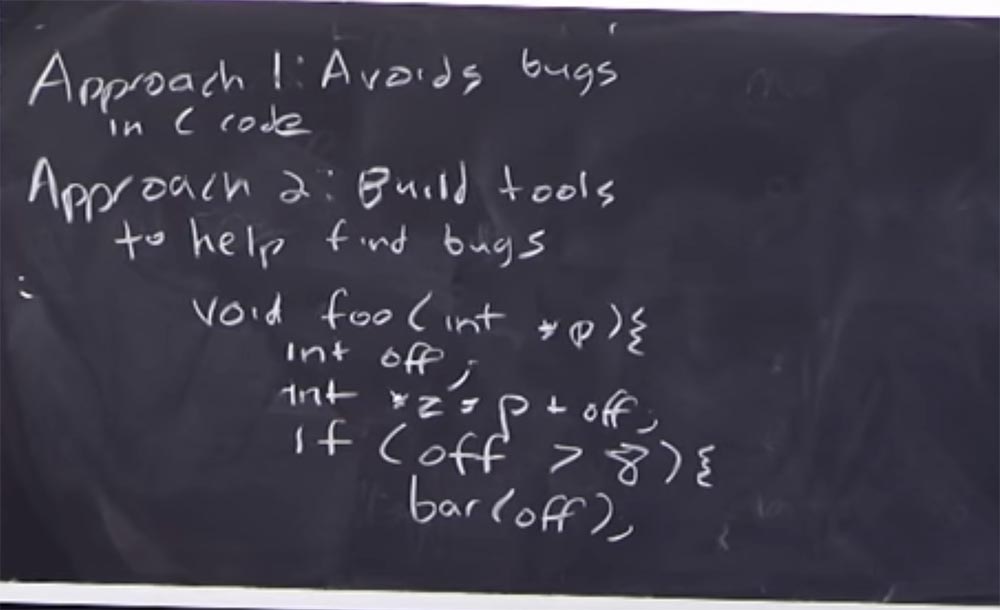
So, if the offset is greater than 8, if (off> 8) , then this leads to the call of some function bar (off) . So, this condition tells us what the offset value is. Even ignoring the fact that the offset is not initialized, when analyzing this branch of the function, we still know that it can be greater than 8. Therefore, when we start to carry out the static analysis of bar, we learn that the offset can take only certain values. I note once again that this is a very superficial introduction to static analysis; later we will consider this tool in more detail. But this example shows how some types of errors can be detected even without executing code.
So, another thing you might think about is that it does the same thing as static analysis. This is software fuzzing. His idea is that you take all the functions in your program code, and then enter random values in them. This overlaps all variants of the values and formats of your code. That is, Fuzzing is a tool to automatically search for vulnerabilities by submitting invalid data to the program input or data in the wrong format. For example, you enter 2, 4, 8, and 15 values in module testing and get the message that the number 15 is probably wrong, because all the numbers are even, and it is odd.
In fact, you need to look at how many branches of the program in general affect your test code, because these are usually the places where the "bugs" are hidden. Programmers do not think about such "back streets" and as a result they pass some unit tests, one can say most of these tests. However, they do not examine all the "nooks" of the program, and this is where static analysis can help. Again, using things like the concept of constraints. For example, in our program chunk, this is a branch condition of a function that defined an offset of more than eight. In this way, we can find out that this offset is static. And if you use automatic Fuzzing to generate input data based on this constraint, then we can ensure that one of the input values for the bias is less than 8, one equals 8 and one is greater than 8.

So, this is the main idea behind the concept of creating tools that help programmers find errors. Even a partial analysis of the code can be very useful when you are working with the C language. Many of the tools that we consider that serve to prevent buffer overflow or to check the initialization of variables are not able to detect all the problems of program code. But they can bring practical benefits in improving the security of these programs. The disadvantage of these tools is that they are not complete. Prospective progress is not complete progress. Therefore, you need to actively explore the problem of protection against exploits in programs written in C, and in other programs. We considered 2 approaches to solving the buffer overflow protection problem, but there are other approaches.
So, the third approach is to use a memory-safe language, or a language that provides memory security. These languages include Python, Java, c #. I don't want to put Perl on a par with them because “bad people” use it. This way, you can use a memory-safe language, and it seems like the most obvious thing you can do. I just explained to you that basically C is a high-level assembly encoder, but it provides “raw” pointers and does other undesirable things, so why not just use one of these high-level programming languages?
There are several reasons for this. First of all, there are many code elements in these languages inherited from C. Everything is fine if you start a new project and use one of the high-level languages for it that provides memory security. But what if you were given a large binary file or a large distribution of source code that was written in C and maintained for 10 to 15 years, it was a project of generations, I mean, even children of our children will continue to work on it ? In this case, you can not say: "I just rewrite it all in C # and change the world!".
And the problem is not just in C, there are systems that you have to fear even more, since they use the codes Fortran and COBOL, things from the time of the Civil War. Why it happens? Because, being engineers, we want to think that we can just build everything ourselves, and it will be amazing, it will be as I want, and I will call my variables as I want.
But in the real world it does not happen. You appear at work, and you have this system that already exists, and you look at the basis of the code and think, why does it not do what is needed? And then they say to you: “Listen, we will do everything you want, but only in the second version of the program, and now you have to make what we have, because otherwise customers will take their money back.”
So, how do we cope with the huge problem of forced use of outdated code? As you learned, one of the advantages of systems with erroneous definition of boundaries is that they work great with this outdated code. This is one of the reasons why you can’t get rid of the buffer overflow problem simply by switching to languages that provide safe memory usage.

What if we need low-level access to hardware? For example, to update drivers and other things.
So, another problem arises if you need low-level access to hardware, which happens when writing drivers for some devices. In this case, you really need the advantages that C gives, for example, the ability to look at registers and similar function elements.
Further, the need to use C occurs when you care about system performance. Usually they say that if you need productivity, write in C, otherwise everything will work too slowly. However, now this problem is not so acute, because people have compilers with powerful optimization processes. In addition, there are things that actually reduce the cost of using these memory-safe languages. I will briefly tell you what JIT is. Let's think about the language of Java, or Java Script. This is a very high level language, dynamically dense, with automatic control and other "buns". When these languages first appeared, they were always interpreted. By interpretation, I mean that, in fact, they did not initially follow the “raw” x86 instructions.
Instead, these languages were compiled to some intermediate form, that is, their source code is translated into one of the intermediate representations, called bytecode. You may have heard about such things as JVM, java virtual machine bytecode. In fact, you had a looped program that took these bytecodes and executed the high-level instructions encoded in them. For example, some JVM bytecodes dealt with such things as pushing and pushing information out of the stack. That is, you have a program that will loop, manage this stack, and emulate these operations. However, its performance was very low. That is, you had a kind of interpreter working in this cycle, which reduced speed.
To increase productivity, people began to use these high-level languages and dynamically, on the fly, generate x86 code for them. Since JIT compilation is a form of dynamic compilation, it allows the use of adaptive optimization and dynamic recompilation. Therefore, JIT compilation can show better performance in terms of performance than static compilation.
From the point of view of timely compilation, this means that I take your piece of JavaScript code and spend a little time in advance to create a real machine instruction, a “raw” 32-bit code that will work directly on bare metal. I take a part of the initial performance for JIT compilation, but then my program actually works on a “bare” hard drive. Therefore, thanks to the use of tools such as JIT interpreters, the statement that C programs are more productive does not sound so convincing.

There are also such “crazy” things, such as asm.js - a subset of JavaScript, the scripts written on it are subject to effective compilation. There are a few tricks you can do, such as compiling JavaScript into a very limited subset of the language that operates on arrays only. This eliminates many of the side effects of dynamic typing in standard JavaScript, and you can actually get JavaScript code to work with C or C ++ performance.
Let's consider the case when your program is actually object-oriented, associated with IO. It has nothing to do with the processor. In other words, your program spends most of its time waiting for network input, entering disk data, waiting for user input, and so on. You do not need to have a lightning speed of calculations, because your program does not actually spend a lot of time doing such things.
Therefore, you need a reasonable approach to addressing the issue of program performance. For example, I will ask someone to come here and write me a very simple program for parsing a text file. Most will spend all their time trying to do this work in C or C ++, because it's faster and you can use templates and all that. But for this there is a one-line solution in Python, which, in fact, works just as fast. And it can be adapted for this task much easier. So you should be critical about performance requirements.
So, we discussed three ways to do things to avoid buffer overflow.
First of all, you need to try not to make mistakes when writing code. The second approach to solving the problem is to create tools that will help detect errors. And the third way is that you can use these tools while the program is running. You can hope that the features of their language environment will not allow you to see the "raw" memory addresses, that is, you can use memory protection. However, it should be remembered that many programs use outdated C and C ++ code, which makes it difficult to use the second and third ways to solve a problem.
So, how can we prevent the buffer overflow problem with the above? Besides the option to quit computer science altogether and become, for example, an artist? How does a buffer overflow actually occur?
When a buffer overflow occurs, an attacker uses two things. The first thing the attack is aimed at is the seizure of control over the instruction pointer. I mean that somehow the attacker finds in the code some place to which the program can make a jump against his will. This is usually necessary, but not enough for a successful attack. Because, secondly, the attacker must make the pointer direct the program to execute malicious code. Since we are trying to basically replace the legal IP address, we need the instruction pointer to point to a useful place in the program code for the attacker. Interestingly, in many cases, to introduce some useful code into a program is not made up for a hacker. We covered some of the attacks on the shell code in the last lecture, and you know that you can embed this attack code into a string. Our lecture and the following lectures will tell you how you can use the existing application code to get the program to turn in an unexpected direction and do some “bad” things.
Therefore, as a rule, figuring out what code the attacker wants to run is not as difficult as figuring out how to make the program go to the right place in memory. The reason for the difficulty is that the hacker must somehow know where to go. As we will soon see, and as you saw in the last lecture, attacks on the shell consist in the possibility to use this hard-coded place in memory where the instruction pointer should be sent. So, some of the remedies that we’ll talk about can randomize things in terms of code layout, heap layout, and thus make it harder for a hacker to figure out exactly where the things are.

So let's first consider the simple prevention approach. This is the idea of stack canaries, "stack canaries", so named by analogy with canaries in a coal mine, which by their singing warn miners about the release of hazardous gas. The main idea of the “stack canary” is that during a buffer overflow, we allow an attacker to rewrite the return address if we can actually intercept this rewrite earlier and jump to where the hacker wants to send us. Simply put, we need to detect a buffer overflow before running the execution of malicious code.
Draw a diagram of our stack. We need to make the attacker first "hit the canary" before he gets to the return address. And if we can detect this before returning from the function, then we can find "evil."
28:30 min.
Continued:
Course MIT "Security of computer systems." Lecture 2: "Control of hacker attacks", part 2
Full version of the course is available here .
Thank you for staying with us. Do you like our articles? Want to see more interesting materials? Support us by placing an order or recommending to friends, 30% discount for Habr's users on a unique analogue of the entry-level servers that we invented for you: The whole truth about VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps from $ 20 or how to share the server? (Options are available with RAID1 and RAID10, up to 24 cores and up to 40GB DDR4).
Dell R730xd 2 times cheaper? Only we have 2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV from $ 249 in the Netherlands and the USA! Read aboutHow to build the infrastructure of the building. class c using servers Dell R730xd E5-2650 v4 worth 9000 euros for a penny?