Odorless filtering and non-linear estimation *
 * from English "Unscented filtering and nonlinear estimation" (by Google Translate )
* from English "Unscented filtering and nonlinear estimation" (by Google Translate )Upon requestdmitriyn decided to publish his vision on the so-called “Unscented Kalman filter”, which is the extension of Kalman's linear filtering to the case when the equations of dynamics and observation of the system are non-linear and cannot be linearized adequately.
As the name of this filtering method is
UPD : Added a comment to the section "USING UT"
INTRODUCTION
In a previous article on linear Kalman filtering, one of the possible approaches to the synthesis of PK for the case of a linearized simplified mathematical model of a dynamic system is described. The Kalman filter described there is sometimes referred to in the literature as “conventional Kalman Filter” [ 2]. He received this name, because gives the smallest standard error only if several hypotheses (conventions) are observed - for example, the noise is white and distributed according to the normal law, the expectation of noise is zero, there are no correlations between noise and cross-connections between phase coordinates. These restrictions are quite serious and in practice often hypotheses are violated. There are techniques that allow circumventing these restrictions (for example, adding a coordinate filter for the color noise generator to the phase vector filter and introducing a dummy disturbance for the “shifted” noise). All of them lead to an increase in computational complexity (the dimension of the problem is growing) and difficulties in the synthesis of a filter that is resistant to violation of conventions.
There is also an “Extended Kalman filter” [ 1], which in its structure is similar to the linear version, characterized in that the equations of dynamics and observations contain nonlinear (power, trigonometric, etc.) functions of phase coordinates (see equations below). This difference also implies the presence of cross-links between phase coordinates (for example, the product of two coordinates).
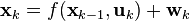
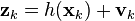
When using EKF, it is necessary at each iteration step to calculate the Jacobian, the matrix of partial derivatives of the phase coordinates. Because of this, computational complexity greatly increases and the question of stability of discretized differential equations arises even more sharply. In essence, EKF implements a layer of linearization of a nonlinear dynamic system. This is the main reason why the EKF may be ineffective. Using a strongly nonlinear model of a dynamical system leads to a very poor conditionality of the problem, i.e. small error in setting parameters mat. models will lead to large computational errors. As a result, the algorithm will lose robustness (resistance to errors).
The unscented Kalman filter (UKF) [ 3] uses a different approach ("unscented transform").
After writing the last paragraph, I personally had even more questions. Like St. Augustine, who knew what time was, until he was asked about time. Below I will try to clarify to myself and you, dear readers, the essence of the non-linear filtering method under consideration.
UNSCENTED TRANSFORM
Perhaps I'll start with a more detailed description of the two main problems of a linear Kalman filter (FC) and non-linear (extended, EKF). The first problem is interference conventions. As stated above, linear FC assumes that the noise is “white” and distributed according to the normal law. If the noise is “colored”, then we must synthesize a digital shaping filter, when passing “white” noise through which we get noise with a spectral characteristic equivalent (ideally) or close to the existing de facto. The phase vector of this filter is added to the phase vector of the FC. This in turn increases the dimension of the problem. Suppose this problem is not too serious. But there is a second - the problem of non-linearity of the mathematical model. Due to nonlinearity, we must implement some approximator that allows us to linearize the nonlinear matrix function (see “H” in the equation above) and thereby provide the ability to separate variables. The variables must be separated so that it is possible to make equations for the components of the phase vector. In EKF, linearization is performed by calculating the Jacobian, i.e. for each equation in "h" partial derivatives are calculated for each of the phase variables. By itself, this operation is already a problem - a large amount of computation. In addition, for the calculation of Jacobian, Taylor series expansion (multidimensional) of the form is used: for each equation in "h" partial derivatives are calculated for each of the phase variables. By itself, this operation is already a problem - a large amount of computation. In addition, for the calculation of Jacobian, Taylor series expansion (multidimensional) of the form is used: for each equation in "h" partial derivatives are calculated for each of the phase variables. By itself, this operation is already a problem - a large amount of computation. In addition, for the calculation of Jacobian, Taylor series expansion (multidimensional) of the form is used:

In this case, only the first member of the series is taken, and the rest are assumed to be negligible. Thus, using this linearization, we obtain an expression of the form:
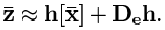
In this equation, “De” is the operator for calculating the total differential of the matrix function.
If the nonlinearity of the mathematical model is small (the model is almost linear), this statement can be considered true. However, in practice, the nonlinearities of the model are such that they do not allow the rejection of the expansion terms of the second and / or more orders of smallness. In such cases, linearization in EKF gives rise to a computational error, which cannot be neglected. In some particular cases, it is possible to do without expanding into a Taylor series, but these are particular solutions that are rigidly tied to one specific object. There is also a solution that truncates the Taylor series to a second-order term of smallness [6]. It involves the calculation of the Hessian, a tensor of second-order derivatives. Just please, do not make me chew what it is. It is enough to realize that this makes the EKF more difficult and complicates its implementation.
So, FC can be applied to a nonlinear model of an object if some transformation is known that allows you to project the current value of the phase vector (make a “non-linear” forecast) to the next iteration step. If such an (adequate) transformation is unknown, then we use EKF with its, often also inadequate, linearization and very large computational load. Thus, we need a method that can do without the linearization used in EKF, and does not have greater computational complexity compared to EKF. This method is Unscented Transformation (UT, do not confuse this abbreviation with a computer game).
UT's main idea is to
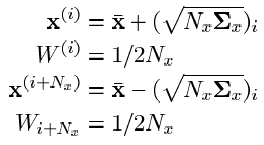
In these expressions, " Nx " is the dimension of the desired phase vector; "i "is the index of the sigma point (i = 1 .. Nx );" Wi "is the weight of the i- th sigma point;
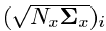 - i- th column of the matrix square root of the covariance matrix of the initial nonlinear model transformation times the dimension of the phase vector.
- i- th column of the matrix square root of the covariance matrix of the initial nonlinear model transformation times the dimension of the phase vector.It should be noted that this is not the only option for a set of sigma points. The above expressions uniquely characterize the distribution statistics only for the first and second moments (expectation and variance). UT, which characterize the statistics of the distribution of the desired vector up to moments of higher orders, differ in the number of sigma points (generally speaking, their number will not necessarily be greater than for the expressions above) and the choice of weights. For simplicity, I omit the details. I will give only as an example the expression for UT, taking into account the higher orders of moments of the statistics of the distribution of the phase vector:
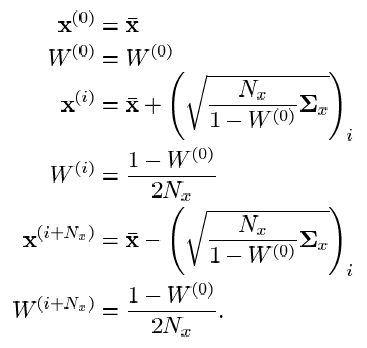
In principle, about UT itself, in short, everything. Why it is needed and how it is used in UKF is written below. It remains to make a reservation about the moment characteristics of high orders. What it is? An intuitive analogy is the position, speed and acceleration of a moving body. If we consider the position as a first-order moment, then the speed will be the second moment (the rate of change of position), and the acceleration - the third (rate of change of speed). You can calculate the derivative of acceleration - we get the fourth moment. But does it make practical sense? Similarly with moment characteristics in statistics - in most cases, expectation and variance are enough. From the statistical accuracy of UT, i.e. the filtering efficiency depends on the method of choosing sigma points, but certainly not so much
UT APPLICATION
As mentioned above, UT is a method that allows you to get rid of the linearization procedure in nonlinear stochastic estimation. So far, we have only learned that with the help of UT it is possible to select a set of points that accurately characterize the statistics of the desired vector (phase vector). What does this give us? The key point in Kalman filtering is the calculation of the cross-covariance matrix (see the Kk matrix in the previous article ). This matrix in linear FC is calculated as a solution to the matrix Riccati equation. In the case of non-linear mat. system model, this procedure is greatly complicated. UT allows you to get the cross-covariance matrix in an alternative way. The following is a step-by-step filtering procedure using the UT method.
- We find the statistical parameters of the desired vector (phase vector or observation vector - the vector of the output signals of the sensors). The obtained statistical characteristics can be considered constant or updated in real time.
- Based on the obtained statistics, we compute a set of sigma points.
- We pass these points through the original nonlinear mat. dynamic process model:
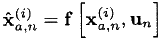
- We calculate the forecast of expectation and covariance:

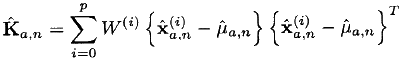
- We pass the points obtained in the third step through the observation model (in the general case, also non-linear):

- We calculate the forecast of observation (in the form of a weighted average of the values in the previous step):
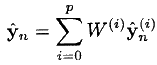
- We compute the covariance of observation:
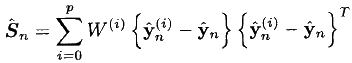
- We find the required cross-covariance matrix:
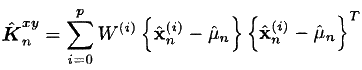
- Finally, we use the standard FC expressions:

The last block of expressions is copied from article [3] as is. In my opinion, something is wrong with her. It is unclear where the “yn” without kryzha and the cross-covariance matrix without identification marks came from. But it doesn’t matter. About the "standard expressions of FC" I already wrote. All you need to do is substitute the matrix gain found through the UT of the Kalman (aka cross-covariance matrix) and calculate the corrected estimate of the phase vector.
One more remark about the phase vector. In the expressions above, there is a phase vector with the index “a” (Xa, n) - this is a phase vector supplemented with (augmented) coordinates for process and observation noises. At the very beginning, I wrote that there is such a technique to circumvent the restrictions on the spectral characteristic of interference. So, in the expressions above, the transition from augmented to normal vectors is somehow quietly made (there is also a “mu” expectation there is also simple and augmented).
CONCLUSION
So, with the help of UT, we were able to calculate the forecast of the phase vector and the cross-covariance matrix without linearization. Substituting their values in standard expressions for the correction phase of the FC forecast (see “Measurement Update” in the article on linear FC), we obtained estimates of the phase vector. The most resource-intensive procedure in this case is the calculation of the matrix square root in the formation of a set of sigma points. The overall complexity of the UKF is no more than that of the EKF. The main advantages of UKF are the generality of synthesis for different tasks (the synthesis procedure does not depend on which object you are working with), as well as the stability of the resulting algorithm (the numerical conditionality of UT is higher than the conditionality of the linearization procedure in EKF) and the absence of bias in the estimates obtained (again, due to for rejection of linearization).
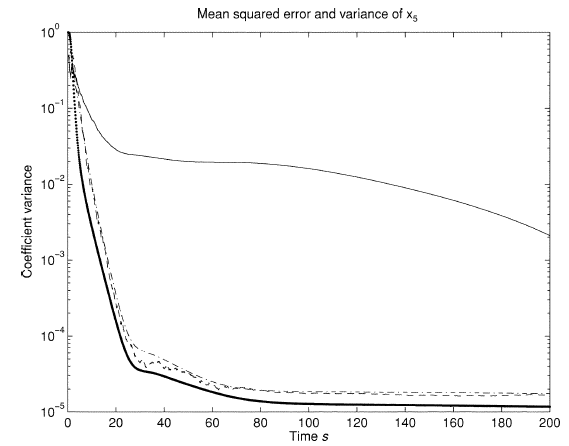
Fig. 1. Graphs of the mean square error and variance of the estimates for EKF and UKF
In this figure, a thin line is the mean square error for EKF (mean-squarred errors). Scatter plot (bold, at the very bottom) - estimated covariances. Two other graphs are for UKF. The EKF has lower covariance estimates (it smoothes somewhat better), but the RMSE in its estimates is very high. UKF covariance and standard deviation are approximately at the same level. By the way, it seemed to me that there was some kind of mistake. Dispersion is the square of the standard deviation. How can they be together? Here, either I misinterpreted the terms (cited in brackets above), or still the estimates of covariances and standard deviations are separate.
UPDI also want to note that I myself have not yet fully understood how this method works, and whether I correctly understood its essence. I'll try to implement it - it seems like a really simple algorithm to implement. I'll see how he shows himself, how time will be.
In the meantime, your thoughts, suggestions, comments ... AND THANKS FOR ATTENTION!
LIST OF REFERENCES:
- UKF at Wiki
- A Discussion Related to Orbit Determination Using Nonlinear Sigma Point Kalman Filter
- Julier, SJ; Uhlmann, JK (1997). "A new extension of the Kalman filter to nonlinear systems." Int. Symp Aerospace / Defense Sensing, Simul. and Controls 3. Retrieved 2008-05-03.
- Fuzzy strong tracking unscented Kalman filter
- Unscented Transform
- M. Athans, RP Wishner, and A. Bertolini, “Suboptimal state
estimation for continuous-time nonlinear systems from discrete
noisy measurements,” IEEE Trans. Automat. Contr., Vol. AC-13,
pp. 504-518, Oct. 1968.