Open-source solution for declining data read latency with Apache Cassandra
- Transfer

One of the world's largest Apache Cassandra databases is deployed on Instagram. The project began using Cassandra in 2012 in order to replace Redis and support the implementation of such application functions as Fraud Recognition, Ribbon and Direct. At first, Cassandra clusters worked in AWS, but later engineers migrated them to the Facebook infrastructure along with all other Instagram systems. Cassandra performed very well in terms of reliability and fault tolerance. At the same time, the delay metrics for reading data could clearly be improved.
Last year, the Instagram team at Cassandra began working on a project aimed at significantly reducing the delay in reading data at Cassandra, which engineers called Rocksandra. In this material, the author tells us that she encouraged the team to implement this project, the difficulties that had to be overcome and the performance metrics that engineers use in both internal and external cloud environments.
Grounds for the transition
Instagram actively and widely uses Apache Cassandra as a key-value storage service. Most Instagram requests are online, so in order to provide a reliable and enjoyable user experience for hundreds of millions of Instagram users, SLAs are very demanding on system performance.
Instagram has a five nines reliability rating. This means that the number of failures at any given time cannot exceed 0.001%. In order to improve performance, engineers actively monitor the throughput and latency of various Cassandra clusters, and make sure that 99% of all requests fit into a certain indicator (P99 delay).
Below is a graph showing the client-side delay for one of the Cassandra combat clusters. The blue color indicates the average read speed (5 ms), and orange - the read speed for 99%, varying from 25-60 ms. Its changes are highly dependent on client traffic.
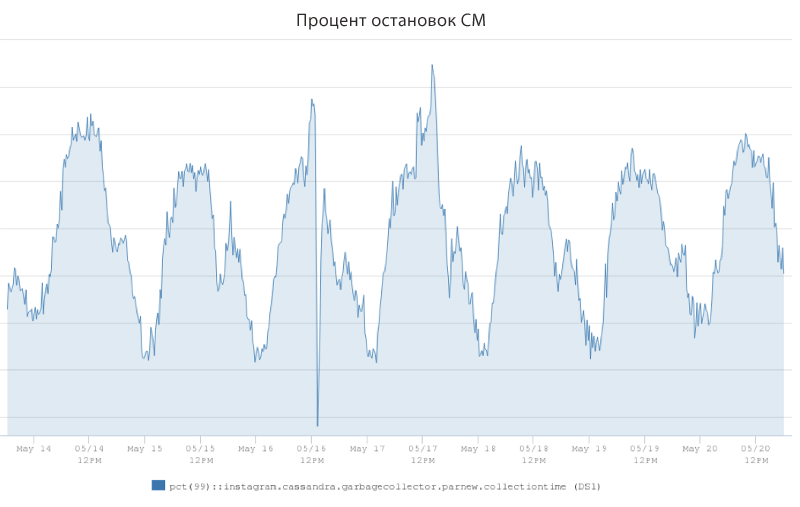

The study found that sudden surges in latency were largely due to the work of the JVM garbage collector. Engineers introduced a metric called “percentage of SM stops” to measure the percentage of time it took to “stop the world” with the Cassandra server, and was accompanied by a denial of service to customer requests. Here is a graph above showing the amount of time (in percent) that was spent on stopping the CM using the example of one of the combat servers Cassandra. The figure ranged from 1.25% at the moments of the smallest traffic to 2.5% at peak times.
The graph shows that this Cassandra server instance could spend 2.5% of its work on garbage collection instead of servicing customer requests. The collector's preventive operations obviously had a significant effect on the P99 delay, and therefore it became clear that if we could reduce the CM stopping rate, then the engineers could significantly reduce the P99 delay indicator.
Decision
Apache Cassandra is a Java-based distributed database, with its own data storage engine based on LSM trees. Engineers discovered that such engine components as a memory table, a compression tool, read / write paths, and some others created many objects in Java dynamic memory, which caused the JVM to perform many additional utility operations. To reduce the impact of storage mechanisms on the work of the garbage collector, the support team considered various approaches and ultimately decided to develop a C ++ engine and replace the existing counterpart with it.
Engineers did not want to do everything from scratch, and therefore decided to take RocksDB as a basis.
RocksDB is a high-performance, open source embedded database for storing key-value type. It is written in C ++, and its API has official language bindings for C ++, C, and Java. RocksDB is optimized for high performance, especially on fast drives such as SSDs. It is widely used in the industry as a storage engine for MySQL, mongoDB, and other popular databases.
Difficulties
In the process of implementing the new storage engine on RocksDB, engineers faced three difficult tasks and solved them.
The first difficulty was that Cassandra still lacks an architecture that allows connecting third-party data handlers. This means that the work of the existing engine is closely interconnected with other components of the database. To find a balance between large-scale refactoring and fast iterations, engineers identified the API of the new engine, including the most common interfaces for reading, writing, and streams. Thus, the support team was able to implement new data processing mechanisms behind the API and insert them into the appropriate code execution paths inside Cassandra.
The second difficulty was that Cassandra supports structured data types and table schemas, while RocksDB provides only key-value interfaces. Engineers carefully defined the encoding and decoding algorithms to support the Cassandra data model within the framework of the RocksDB data structures and ensured the continuity of the semantics of similar queries between the two databases.
The third difficulty was associated with such an important component for any distributed database as working with data streams. Whenever a node is added or removed from a Cassandra cluster, it needs to properly distribute data between different nodes for load balancing within the cluster. The existing implementations of these mechanisms were based on obtaining detailed data from the existing database engine. Therefore, engineers had to separate them from each other, create an abstraction layer and implement a new thread processing option using the RocksDB API. In order to obtain high bandwidth of streams, the support team now first distributes data to temporary sst files, and then uses a special API RocksDB to “swallow” files, allowing them to mass-download simultaneously to the RocksDB instance.
Performance indicators
After almost a year of development and testing, the engineers completed the first version of the implementation and successfully “rolled out” it on several combat Instagram Cassandra clusters. On one of the battle clusters, the P99 delay dropped from 60 ms to 20 ms. Observations also showed that the SM stops in this cluster fell from 2.5% to 0.3%, that is, almost 10 times!
The engineers also wanted to see if Rocksandra could do well in a public cloud. The support team set up a Cassandra cluster in the AWS environment using three i3.8 xlarge EC2 instances, each with a 32-core processor, 244 GB of RAM, and a zero raid of four NVMe flash drives.
For comparative tests, we used NDBench , and the default for the framework scheme of the table.
TABLE emp (
emp_uname textPRIMARY KEY,
emp_dept text,
emp_first text,
emp_last text
)Engineers have pre-loaded 250 million 6 rows of 6 KB each (each server has about 500 GB of data). Next, set up 128 readers and writers in NDBench.
The support team tested various loads and measured the average read / write latency / P99 / P999. The graphs below show that Rocksandra showed significantly lower and more stable read and write latency.


Engineers also tested the load in read mode without writing and found that with the same P99 read delay (2 ms), Rocksandra is able to provide a more than 10-fold increase in information reading speed (300 K / s for Rocksandra against 30 K / s for C * 3.0).


Future plans
The Instagram support team has unlocked the Rocksandra code and performance framework . You can download them from Github and try them in your own environment. Be sure to tell us what came of it!
As a next step, the team is actively working to add broader support for C * functionality, such as secondary indexes, repair, and more. And besides, engineers are developing the architecture of the connected database engine in C * , in order to transfer these developments to the Apache Cassandra community in the future.
