KBookOCR for Linux. FineReader killer for Linux at the initial stage
Introduction
Perhaps each of us experienced a period in our life which was accompanied by the active digitization of analogs of the material. I mean the need to work with text from non-digital sources. This refers not only to the problem of scanning, but also a lot of material that unfortunately reaches the end consumer is not quite in a usable form. And I think each of us very often flashed thoughts in the head about the distributor of the book in djvu or pdf format in which all the content was presented graphically without the possibility of using materials for our activities.
For Windows users, there is the option of using FineReader, which easily carried out the recognition process with all the consequences.
Linux - solution to the problem
But what about people who are able to use more advanced operating systems while maintaining their finances at an acceptable level? Of course, there are projects of console utilities for recognizing text. On the basis of one of the most developed open technologies, OCR created a whole distribution kit for deploying a server for OCR with a web interface for communicating with this same server. But I don’t think that the end consumer is interested in such monstrous decisions. And the technology itself is implemented in many distributions in the form of a console application that can operate not with popular formats, of which it is most often necessary to “tear out” the text (djvu, pdf), but with graphic files, which complicates the process of use.
Of course, this state of affairs and the Linux love for optimizing everything and everyone led to the appearance of the BookOCR project, the founders of which are the wonderful person mr-protos , who is not yet on Habré. Further, his article on the creation of BookOCR:
BookOCR
mr-protos created a moderately simple bash script bookocr.sh:
bookocr.tar.xz (posted on dropbox)
The algorithm of his work:
1. checking the file extension (.djvu or .pdf. In case of another extension, the script will give a warning);
2. page-by-page conversion of the file to .png for further recognition. (the result is added to a temporary folder ~ / .tmp_pdf or ~ / .tmp_djvu);
3. recognition of converted pages using OCR;
4. combining paginated text files into one;
5. Delete the temporary folder.
Script Usage:
bookocr.sh <path_to_pdf_or_djvu>
Note: the finished file is created in the same directory as the source.
For the script to work, the following packages must be installed on the system:
- cuneiform
- ghostscript
- djvulibre-bin
- libtiff-tools
- libnotify-bin
The quality of the recognized text depends primarily on the quality of the original file and on the operation of the cuneiform package.
KBookOCR
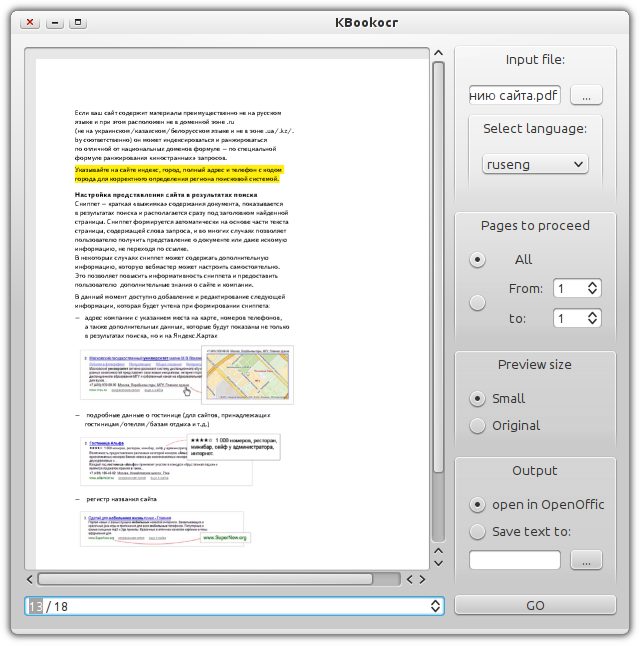
Of course, this project was the impetus for another ambitious idea, which, together with the author of BookOCR, was brought to life by your humble servant b0noI . The idea was to implement a system suitable for use by visual aesthetes who prefer a visually beautiful design (this is at least), and as a maximum create a Linux-based project that would allow FineReader to be executed in an equally convenient and aesthetically beautiful way.
For development, the Qt library was selected. On the one hand, this project is an add-on on the BookOCR project, but it is not so simple. Since the integration had to make significant changes to the original script. There were special problems when implementing the preview of djvu files, since if the poppler project exists for pdf, then in the indicated cases the preview had to be implemented by a third-party bash utility. That is why, when installing KbookOCR, along with KbookOCR itself, not only BookOCR is installed, but also a console utility that is used to obtain the image used in the preview.
Current status of the project
Already, the project has reached the stage of the finished first version and is undergoing active public testing (download for Ubuntu deb x86 ). What can FineReader's first public and open source killer do ?:
- preview a document that needs to be recognized (scroll through pages);
- specify recognition language. Currently, there is no language recognition in the document, but it is planned to do so. There is also no way to specify a dual document recognition language (with the exception of rus / eng);
- resize previews. Two options are available - original size or reduced;
- it can be recognized by a given range or the entire document;
- saving the recognized document. Two options are available - either save the result in a regular text file, or open the result in OpenOffice Writer.
Roadmap
In the next version, the release date of which, unfortunately, is not known, it is planned to implement and add:
- work with the scanner;
- Auto detect language in the document;
- more flexible preview. with drawing thumbnails of pages, as well as with a more flexible indication of the display scale;
- more flexible indication of the recognition range.
In a very distant future, options are being considered for specifying recognition zones, types of zones, as well as recognizing not only text but also formatting the document in accordance with the original.
Afterword
And although KbookOCR is the latest creation of our duet, the program is not our first and only creation. In the next series, we will tell you about our first joint Linux project - KbashPod for podcasts.
UPD:
Update to version 1.2:
- Scanner support (via scanimage);
- Output the result in html, rtf format (via cuneiform);
- Text formatting processing (via cuneiform);
- Dynamic zoom preview.
References
BookOCR
bookocr.tar.xz
KBookOCR 1.2
KBookOCR on kde-apps.org
The authors
mr-protos
b0noI