Twitter publishes its FlockDB
It's nice that many large companies continue the tradition of laying out serious things from internal development in Open Source.
Twitter recently posted FlockDB
"FlockDB is a database that stores graph data. At the same time, it is not a database optimized for graph traversal operations. FlockDB is optimized for working with very large lists of adjacent graph vertices , fast read and write arithmetic and page "page-able set arithmetic queries."
The main objective of the project was to solve Twitter problems with working with very large graphs of social data of users (followers, operations mention , etc.). The migration ended 9 months ago and they seem to be happy with everything now.
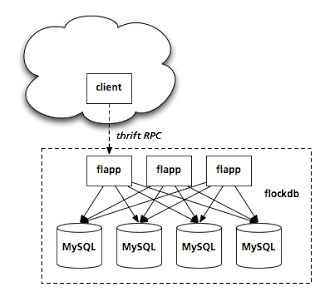
Currently, the system stores 13 billion graph edges and supports 20 thousand writes and 100 thousand reads per second.
More details on the product can be found here .
Sources are available on github .
Twitter recently posted FlockDB
"FlockDB is a database that stores graph data. At the same time, it is not a database optimized for graph traversal operations. FlockDB is optimized for working with very large lists of adjacent graph vertices , fast read and write arithmetic and page "page-able set arithmetic queries."
The main objective of the project was to solve Twitter problems with working with very large graphs of social data of users (followers, operations mention , etc.). The migration ended 9 months ago and they seem to be happy with everything now.
Currently, the system stores 13 billion graph edges and supports 20 thousand writes and 100 thousand reads per second.
More details on the product can be found here .
Sources are available on github .