A million books and how not to read them
Peace and love to IT brothers from the humanities!
I decided to talk about how IT is applied (with benefit!) In the field of the humanities.

Million books is the name of Google’s book digitization project, which everyone sees on Google Books. A million books were successfully converted to electronic format in 2007. Now Google’s new challenge is to digitize 30 million books.
And a new question arose for the humanities: what now to do with all this sea of literature? What to do with the millions of books that are published these days?
First, it’s clear that you cannot read a million books.
Secondly, it is clear that the humanities should read this.
Indeed, the fundamental difference between humanities and natural scientists is the obligation to keep abreast of the entire volume of fiction. You may not have read Kalevala, but you should be aware of what it is and how it is.
What to do?
Of course, call for help new technologies. First of all, data mining. To do this, the MONK project was launched at Northwestern University and the University of Illinois .
MONK consists of a database and programs that detect repeating patterns in texts. MorphAdorner keeps track of the linkages between individual words and sentences, parts of speech, and tokens. It also takes into account the variety of dialects. The program is capable of learning and self-learning, classifying texts and calculating probabilities (for example, by the frequency of occurrence of a word in several texts, calculate the probability of occurrence of text in the following). Thus, using this tool, you can get a kind of DNA of any text.
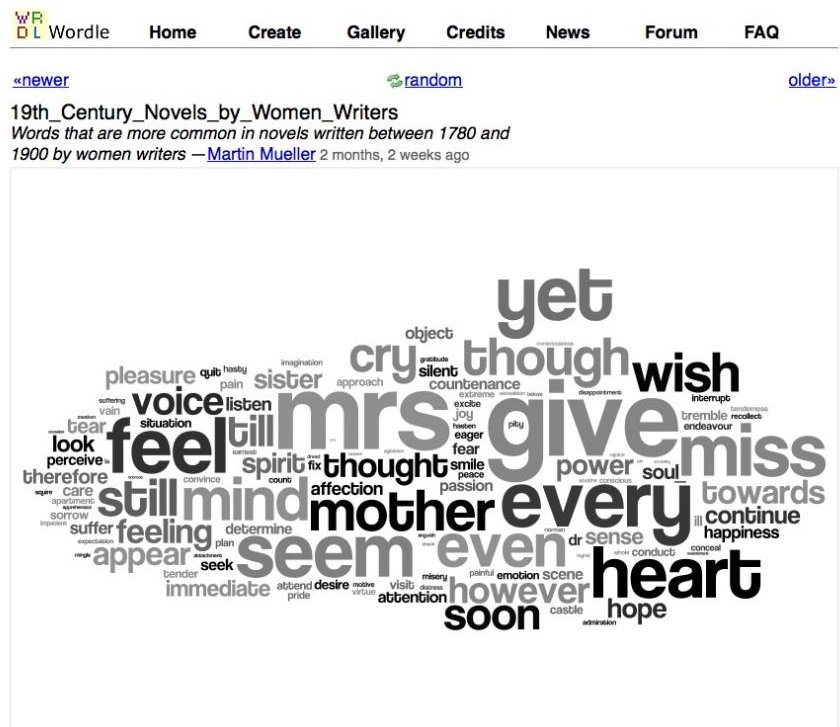
You can also find the main linguistic pattern of groups of texts united on one basis: for example, the DNA of texts written by women between 1790 and 1900 looks like this:
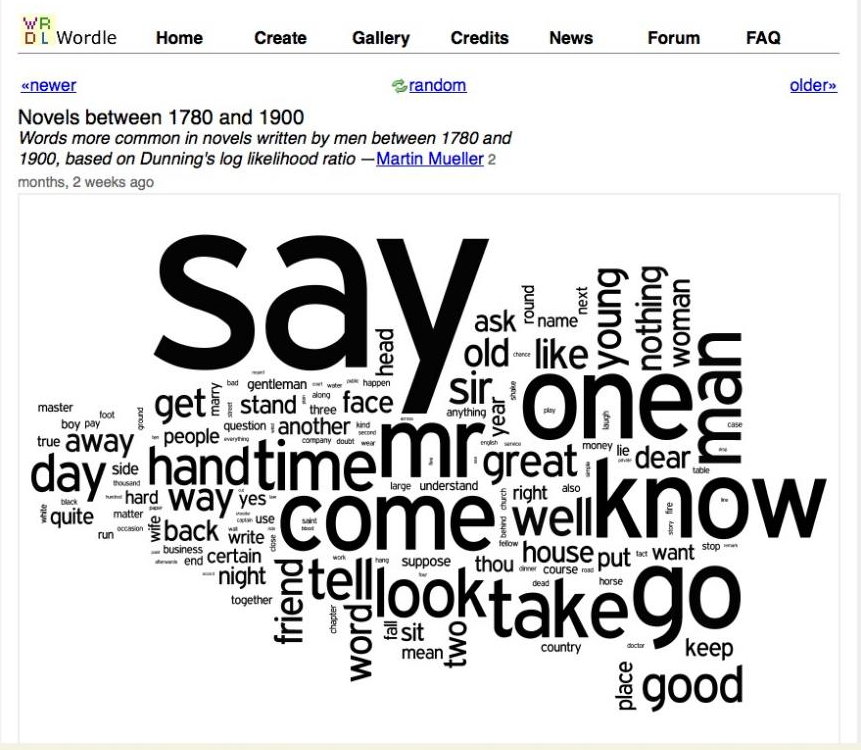
And the DNA of texts written by men of the same period is like this:
Now MONK has high hopes. For example, with its help they hope to determine the authorship of dubious texts, to find out the year the text was written, and even the gender of the author. And of course - it just eliminates the need to read a million books to keep abreast of what is written in them.
The following source was used freely when writing: How Not to Read a Million Books by Tanya Clement et al.
I decided to talk about how IT is applied (with benefit!) In the field of the humanities.
Million books is the name of Google’s book digitization project, which everyone sees on Google Books. A million books were successfully converted to electronic format in 2007. Now Google’s new challenge is to digitize 30 million books.
And a new question arose for the humanities: what now to do with all this sea of literature? What to do with the millions of books that are published these days?
First, it’s clear that you cannot read a million books.
Secondly, it is clear that the humanities should read this.
Indeed, the fundamental difference between humanities and natural scientists is the obligation to keep abreast of the entire volume of fiction. You may not have read Kalevala, but you should be aware of what it is and how it is.
What to do?
Of course, call for help new technologies. First of all, data mining. To do this, the MONK project was launched at Northwestern University and the University of Illinois .
MONK consists of a database and programs that detect repeating patterns in texts. MorphAdorner keeps track of the linkages between individual words and sentences, parts of speech, and tokens. It also takes into account the variety of dialects. The program is capable of learning and self-learning, classifying texts and calculating probabilities (for example, by the frequency of occurrence of a word in several texts, calculate the probability of occurrence of text in the following). Thus, using this tool, you can get a kind of DNA of any text.
You can also find the main linguistic pattern of groups of texts united on one basis: for example, the DNA of texts written by women between 1790 and 1900 looks like this:
And the DNA of texts written by men of the same period is like this:
Now MONK has high hopes. For example, with its help they hope to determine the authorship of dubious texts, to find out the year the text was written, and even the gender of the author. And of course - it just eliminates the need to read a million books to keep abreast of what is written in them.
The following source was used freely when writing: How Not to Read a Million Books by Tanya Clement et al.