Work with program version numbers
And everything works on my car!
From the profanity of programmers.
In order for programmers, testers and users of the program to understand where and what happens, where an error occurred or when you can look at a new feature, use the program version. The easiest way is a single number increasing by one each assembly. Sometimes this method is the best. What about other products?
My IE has version number 8.0.6001.18828, and Paint has version 6.0, but the build number is 6002.
The following syntax is used to indicate version numbers of Microsoft Office products:
aa.bbbb.cccc
* aa: Office version.
* bbbb: Version of the executable file of the program, for example Excel.exe.
* cccc: Version of the Mso.dll file.
But the most original was Donald Knuth. Since version 3.0, TeX uses a characteristic version numbering system: each update adds an additional decimal digit to the version number, so that it asymptotically approaches π. This reflects the fact that the current version of TeX - 3.1415926 - is very stable and only minor updates are possible (see en.wikipedia.org/wiki/TeX ).
Forget about Knut's joke for now. How is it more convenient? In my seminar on setting up a backtracker, I talk about various attribute groups. There are descriptive attributes, and there are control ones.
The build version is important for determining where the error was found. In this case, this is part of the defect description, slightly different from the description of the program section or type of error. It is also convenient to use the build number in which the defect has been fixed (a new feature has been added). And here it is most convenient to use a single singular, growing from assembly to assembly.
But for managing features and defects it is convenient to use the official release number. Let us recruit tasks for a four-week iteration. Now release 2.14 has been released, the next one will be 2.16. What we are putting into operation should have a label. Otherwise, it will be very difficult for the end user to communicate with us. Sometimes it is convenient to make the structure a big change / small change. For example, “version 2” was on php + MySQL, and version 3 will be on .Net + MSSQL. In the fourth version, we will switch from three-tier to four-tier architecture and finally make a fat client. And in version 5, we will finally make logistics in addition to warehouse accounting. Those. versions 2.x, 3.x, 4, x are big jumps, and the transition 3.12-3.14 is the release of patches, the addition of a little functionality, etc.
Sometimes they do three levels:
• the first level - big jumps, every 6-30 months
• the second level - small jumps, every 2-4 weeks
• the third level - urgent patches on demand at any time
There may well be a picture when part of the team is working on a version 4.0, another prepares 3.14, and a couple of guys with fast hands cook 3.12.1 and 3.12.2 (number 3.12.1 will be with the one who presses the commit earlier). Not that it was a complete nightmare of configuration management, but a bit of joy.
I would recommend focusing on two-level numbering of releases. If your team serves one client (support and development of the system), then it is convenient to make the number of the planned iteration the first number, and the patch number for the product version as the second. For boxes it will be different, but there you can get by with two numbers
There is still an interesting practice, when versions under development have an odd number, and those in operation are even.
So, for example, if version 14.0 is currently in operation (or the result of the seventh four-week iteration), 15.0 is under development, but patches 14.1 and 14.2 have already been released. The
full version number in this case will look like aa.b.ccc, where:
• aa - release number
• b - patch number
• ccc - build number
And you will have something like this:
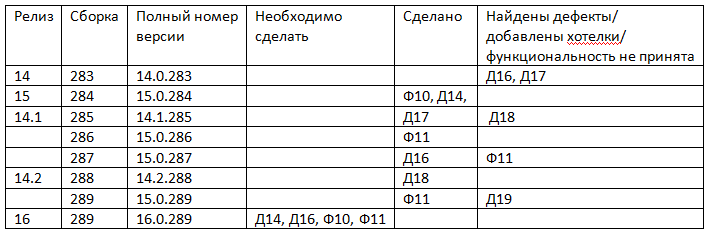
• Version 14.0.283 (release 14.0, build 283) is with the client. The next release 16.0 is scheduled to fix defects D14 and D16 and add features F10 and F11.
• The team gets to work, releases 15.0.284, with implemented F10, D14.
• But here users find in 14.0.283 a couple of defects. It was decided to make D17 a patch, and D16 to postpone until better times. The patch 14.1.285
• ...
• 15.0.289 and 16.0.289 are identical. The difference in the numbers is made in order to show that this is an official release.
This method of numbering is quite convenient for many cases. Perhaps it does not fit your project specifically. Most importantly, if you change something, remember that there are descriptive attributes and there are control ones. You can build control on other attributes that are not related to the version number. In this case, the number can be simplified. Or it may be that everyone is clear and the version number is simply not needed. It also happens. However, about this or in another article or at the training.
From the profanity of programmers.
In order for programmers, testers and users of the program to understand where and what happens, where an error occurred or when you can look at a new feature, use the program version. The easiest way is a single number increasing by one each assembly. Sometimes this method is the best. What about other products?
My IE has version number 8.0.6001.18828, and Paint has version 6.0, but the build number is 6002.
The following syntax is used to indicate version numbers of Microsoft Office products:
aa.bbbb.cccc
* aa: Office version.
* bbbb: Version of the executable file of the program, for example Excel.exe.
* cccc: Version of the Mso.dll file.
But the most original was Donald Knuth. Since version 3.0, TeX uses a characteristic version numbering system: each update adds an additional decimal digit to the version number, so that it asymptotically approaches π. This reflects the fact that the current version of TeX - 3.1415926 - is very stable and only minor updates are possible (see en.wikipedia.org/wiki/TeX ).
Forget about Knut's joke for now. How is it more convenient? In my seminar on setting up a backtracker, I talk about various attribute groups. There are descriptive attributes, and there are control ones.
The build version is important for determining where the error was found. In this case, this is part of the defect description, slightly different from the description of the program section or type of error. It is also convenient to use the build number in which the defect has been fixed (a new feature has been added). And here it is most convenient to use a single singular, growing from assembly to assembly.
But for managing features and defects it is convenient to use the official release number. Let us recruit tasks for a four-week iteration. Now release 2.14 has been released, the next one will be 2.16. What we are putting into operation should have a label. Otherwise, it will be very difficult for the end user to communicate with us. Sometimes it is convenient to make the structure a big change / small change. For example, “version 2” was on php + MySQL, and version 3 will be on .Net + MSSQL. In the fourth version, we will switch from three-tier to four-tier architecture and finally make a fat client. And in version 5, we will finally make logistics in addition to warehouse accounting. Those. versions 2.x, 3.x, 4, x are big jumps, and the transition 3.12-3.14 is the release of patches, the addition of a little functionality, etc.
Sometimes they do three levels:
• the first level - big jumps, every 6-30 months
• the second level - small jumps, every 2-4 weeks
• the third level - urgent patches on demand at any time
There may well be a picture when part of the team is working on a version 4.0, another prepares 3.14, and a couple of guys with fast hands cook 3.12.1 and 3.12.2 (number 3.12.1 will be with the one who presses the commit earlier). Not that it was a complete nightmare of configuration management, but a bit of joy.
I would recommend focusing on two-level numbering of releases. If your team serves one client (support and development of the system), then it is convenient to make the number of the planned iteration the first number, and the patch number for the product version as the second. For boxes it will be different, but there you can get by with two numbers
There is still an interesting practice, when versions under development have an odd number, and those in operation are even.
So, for example, if version 14.0 is currently in operation (or the result of the seventh four-week iteration), 15.0 is under development, but patches 14.1 and 14.2 have already been released. The
full version number in this case will look like aa.b.ccc, where:
• aa - release number
• b - patch number
• ccc - build number
And you will have something like this:
• Version 14.0.283 (release 14.0, build 283) is with the client. The next release 16.0 is scheduled to fix defects D14 and D16 and add features F10 and F11.
• The team gets to work, releases 15.0.284, with implemented F10, D14.
• But here users find in 14.0.283 a couple of defects. It was decided to make D17 a patch, and D16 to postpone until better times. The patch 14.1.285
• ...
• 15.0.289 and 16.0.289 are identical. The difference in the numbers is made in order to show that this is an official release.
This method of numbering is quite convenient for many cases. Perhaps it does not fit your project specifically. Most importantly, if you change something, remember that there are descriptive attributes and there are control ones. You can build control on other attributes that are not related to the version number. In this case, the number can be simplified. Or it may be that everyone is clear and the version number is simply not needed. It also happens. However, about this or in another article or at the training.