How computers play chess
The most interesting implementation of the chess program was shown yesterday at Habré.
After reading the comments, I came to the conclusion that the principle of operation of the most common algorithms for playing chess, checkers and the like is not known to everyone.
At the same time, the task of creating a program that plays something is rather trivial if there are methods for calculating certain quantities and ratings specific to this game.
I’ll tell you about the alpha-beta cut-offs and the minimax method in relation to chess (in the literature you can also find more general terms “face and bound method” and “branch and bound method”)
At any time during the game, for each player, there are a number of moves allowed by the rules. Let's say it is finite. In response, the second player can also make some finite number of moves. If we exclude the possibility of looping the game, then the total number of positions and transitions between them is large, but of course. Chess rules are just that.
It would seem that it is simpler: we have done a full search and we know everything about the game; the computer cannot lose.
However, the number of positions is so great that a full analysis of the game is practically impossible (with the exception of the classic 3x3 tic-tac-toe and similarly rich game strategies).
Therefore, in practice, the following is done :
1. Analytically, expertly or by the method of reasoning on precedents, the function of evaluating the position on the board is built. This rating is usually ranked on the axis: the larger it is, the more profitable for white, the less, the more profitable for black and accordingly unprofitable for white (the so-called zero-sum games).
2. An incomplete tree of moves is being constructed. At the same time, the number of calculated half-moves is really determined by the available computational resources (the attached program calculates 7 half-moves, which is rather modest for modern programs)
3. A moderately intelligent analysis of the tree of possible moves is performed, during which deliberately non-optimal branches are cut off and more promising ones are deeply calculated. This is where the famous alpha beta procedure is performed.
And now the same thing, but more formally and strictly(the presentation is mainly based on an article by D. Knut and R. Moore translated by Pavel Dubner ):
Designations :
p - position
f (p) - a numerical function that estimates the gain of “our” player at the end of the game (these positions p are also called terminal)
F (p) is a numerical function that estimates the gain of “our” player in a nonterminal position.
We will proceed from the fact that the second player also acts in the best way for himself.
Then:
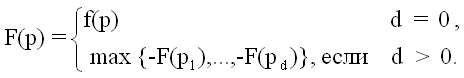
There is a subtle consideration, Knut and Moore have perfectly formulated it, so I’ll just quote:
Full depth search :
This search is recursive and will work for a very long time, but it is guaranteed to find the optimal strategy.
You can optimize the algorithm without considering those branches of the move tree that are obviously worse than the solution already found (this is called the branch and bound method).
The idea of the branch and bound method is implemented by the following algorithm :
This modification also finds the optimal solution.
In the case of analysis of a deliberately finite game tree, where all terminal vertices have estimates, you can enter not only the upper boundary for the search, but also the lower one, while still reducing the search space and saving resources.
Alpha beta clipping is implemented with the following code :
Such optimization still finds a notoriously better solution .
In practice, even in the simplest games, not to mention chess, a complete enumeration of terminal positions cannot be organized. Therefore, the non-trivial task of an approximate assessment of the position arises. It is clear that the correct mat gives many advantages to the position, but everything is also taken into account: the position of the figures, the king’s security, numerical superiority, and the possibility of castling. Depending on the implementation details, the robot may be too cautious or, conversely, recklessly throwing themselves at exchanges.
Using any evaluation functions deprives the algorithm of mathematical rigor. It will be as good as the rating function.
It is clear that the first call to the function F2 contains infinity of different signs as alpha and beta.
Example tree of moves:

Additional explanations for the last picture here: Source
Another problem is the beginning of the game. It’s far to the end, the prospects are foggy, no one gives children mats. Therefore, as a rule, libraries of investigated openings are used. If the opponent does something unintelligible from the standpoint of chess tactics, the analyzer described above turns on.
In principle, all of the above is relatively simple. After two years of study, my three of us three students piled these chess pieces . Everything has been done there quite qualitatively and there is room to grow.
After reading the comments, I came to the conclusion that the principle of operation of the most common algorithms for playing chess, checkers and the like is not known to everyone.
At the same time, the task of creating a program that plays something is rather trivial if there are methods for calculating certain quantities and ratings specific to this game.
I’ll tell you about the alpha-beta cut-offs and the minimax method in relation to chess (in the literature you can also find more general terms “face and bound method” and “branch and bound method”)
At any time during the game, for each player, there are a number of moves allowed by the rules. Let's say it is finite. In response, the second player can also make some finite number of moves. If we exclude the possibility of looping the game, then the total number of positions and transitions between them is large, but of course. Chess rules are just that.
It would seem that it is simpler: we have done a full search and we know everything about the game; the computer cannot lose.
However, the number of positions is so great that a full analysis of the game is practically impossible (with the exception of the classic 3x3 tic-tac-toe and similarly rich game strategies).
Therefore, in practice, the following is done :
1. Analytically, expertly or by the method of reasoning on precedents, the function of evaluating the position on the board is built. This rating is usually ranked on the axis: the larger it is, the more profitable for white, the less, the more profitable for black and accordingly unprofitable for white (the so-called zero-sum games).
2. An incomplete tree of moves is being constructed. At the same time, the number of calculated half-moves is really determined by the available computational resources (the attached program calculates 7 half-moves, which is rather modest for modern programs)
3. A moderately intelligent analysis of the tree of possible moves is performed, during which deliberately non-optimal branches are cut off and more promising ones are deeply calculated. This is where the famous alpha beta procedure is performed.
And now the same thing, but more formally and strictly(the presentation is mainly based on an article by D. Knut and R. Moore translated by Pavel Dubner ):
Designations :
p - position
f (p) - a numerical function that estimates the gain of “our” player at the end of the game (these positions p are also called terminal)
F (p) is a numerical function that estimates the gain of “our” player in a nonterminal position.
We will proceed from the fact that the second player also acts in the best way for himself.
Then:
There is a subtle consideration, Knut and Moore have perfectly formulated it, so I’ll just quote:
However, it should be noted that it reflects the results of a very cautious strategy that is not necessarily good against bad players or players acting according to a different optimality principle. Suppose, for example, that there are two moves in positions p1 and p2, where p1 guarantees a draw (win 0) and does not give an opportunity to win, while p2 gives an opportunity to win if the opponent views a very thin winning move. In such a situation, we may prefer a risky move in p2, unless we are sure that our opponent is omnipotent and omniscient. It is very possible that people win chess programs in this way.
Full depth search :
int F(void *p)
{
int res,i,t,d,m;
// получаем список возможных ходов ps (их число равно d)
possibles(p, ps, &d);
if (!d) res=f(p) else
{
m = -infinity;
for (i=1;i<=d;i++)
{
t = -F(ps[i]);
if (t > m) m=t;
}
res = m;
}
return res
* This source code was highlighted with Source Code Highlighter.This search is recursive and will work for a very long time, but it is guaranteed to find the optimal strategy.
You can optimize the algorithm without considering those branches of the move tree that are obviously worse than the solution already found (this is called the branch and bound method).
The idea of the branch and bound method is implemented by the following algorithm :
int F1(void *p, int bound)
{
int res,i,t,d,m;
// получаем список возможных ходов ps (их число равно d)
possibles(p, ps, &d);
if (!d) res=f(p) else
{
m = -infinity;
for (i=1;(i<=d) && (m
{
t = -F1(ps[i],-m);
if (t > m) m=t;
}
res = m;
}
return res;
}
* This source code was highlighted with Source Code Highlighter. This modification also finds the optimal solution.
In the case of analysis of a deliberately finite game tree, where all terminal vertices have estimates, you can enter not only the upper boundary for the search, but also the lower one, while still reducing the search space and saving resources.
Alpha beta clipping is implemented with the following code :
int F1(void *p, int alpha, int beta)
{
int res,i,t,d,m;
// получаем список возможных ходов ps (их число равно d)
possibles(p, ps, &d);
if (!d) res=f(p) else
{
m = alpha;
for (i=1;(i<=d) && (m
{
t = -F2(ps[i],-beta,-m);
if (t > m) m=t;
}
res = m;
}
return res;
}
* This source code was highlighted with Source Code Highlighter. Such optimization still finds a notoriously better solution .
In practice, even in the simplest games, not to mention chess, a complete enumeration of terminal positions cannot be organized. Therefore, the non-trivial task of an approximate assessment of the position arises. It is clear that the correct mat gives many advantages to the position, but everything is also taken into account: the position of the figures, the king’s security, numerical superiority, and the possibility of castling. Depending on the implementation details, the robot may be too cautious or, conversely, recklessly throwing themselves at exchanges.
Using any evaluation functions deprives the algorithm of mathematical rigor. It will be as good as the rating function.
It is clear that the first call to the function F2 contains infinity of different signs as alpha and beta.
Example tree of moves:
Additional explanations for the last picture here: Source
Another problem is the beginning of the game. It’s far to the end, the prospects are foggy, no one gives children mats. Therefore, as a rule, libraries of investigated openings are used. If the opponent does something unintelligible from the standpoint of chess tactics, the analyzer described above turns on.
In principle, all of the above is relatively simple. After two years of study, my three of us three students piled these chess pieces . Everything has been done there quite qualitatively and there is room to grow.