Differences between LabelEncoder and OneHotEncoder in SciKit Learn
- Transfer
If you recently started your journey in machine learning, you might get confused between LabelEncoder and OneHotEncoder . Both encoders are part of the SciKit Learn library in Python and both are used to convert categorical or textual data into numbers that our predictive models understand best. Let's find out the differences between the encoders on a simple example.
Character Encoding
First of all, the SciKit Learn documentation for LabelEncoder can be found here . Now consider the following data:
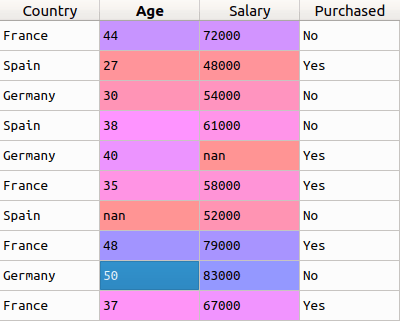
In this example, the first column (country) is fully text. As you may already know, we cannot use text in data to train the model. Therefore, before we can begin the process, we need to prepare this data.
And to convert such categories into understandable models of numerical data, we use the LabelEncoder class . Thus, all we need to do to get the attribute for the first column is import the class from the sklearn library , process the column with the fit_transform function , and replace the existing text data with the new encoded one. Let's see the code.
from sklearn.preprocessing import LabelEncoder
labelencoder = LabelEncoder()
x[:, 0] = labelencoder.fit_transform(x[:, 0])
It is assumed that the data is in the variable x . After running the code above, if you check the x value , you will see that the three countries in the first column have been replaced by the numbers 0, 1 and 2.
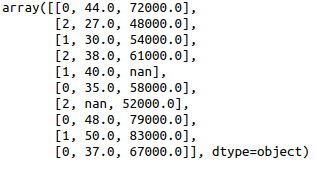
In general, this is the coding of signs. But depending on the data, this conversion creates a new problem. We have converted a set of countries into a set of numbers. But this is just categorical data, and in fact there is no connection between the numbers.
The problem here is that, since there are different numbers in the same column, the model will incorrectly think that the data is in some special order - 0 <1 <2 Although this, of course, is not so at all. To solve the problem, we use OneHotEncoder .
OneHotEncoder
If you are interested in reading the documentation, you can find it here . Now, as we have already discussed, depending on the data we have, we may encounter a situation where, after encoding the attributes, our model gets confused, falsely assuming that the data is connected by an order or hierarchy that is not really there. To avoid this, we will use OneHotEncoder .
This encoder takes a column with categorical data that has been previously encoded into a characteristic and creates several new columns for it. Numbers are replaced with ones and zeros, depending on which column which value is inherent. In our example, we get three new columns, one for each country — France, Germany, and Spain.
For rows whose first column is France, the column “France” will be set to “1” and the other two columns to “0”. Similarly, for rows whose first column is Germany, the Germany column will have a “1” and the other two columns will have a “0”.
This is done very simply:
from sklearn.preprocessing import OneHotEncoder
onehotencoder = OneHotEncoder(categorical_features = [0])
x = onehotencoder.fit_transform(x).toarray()
In the constructor, we indicate which column should be processed by OneHotEncoder , in our case - [0] . Then transform the x array using the fit_transform function of the encoder object you just created. That's it, now we have three new columns in the dataset:
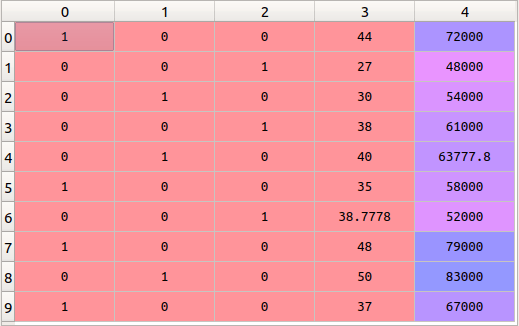
As you can see, instead of one column with a country, we got three new ones encoding this country.
This is the difference from LabelEncoder and OneHotEncoder .