Understanding the FFT Algorithm
- Transfer
Hello, friends. The Algorithms for Developers course starts tomorrow , and we still have one unpublished translation. Actually we correct and share material with you. Go.
Fast Fourier Transform (FFT) is one of the most important signal processing and data analysis algorithms. I used it for years without formal knowledge in computer science. But this week it occurred to me that I never wondered how the FFT calculates the discrete Fourier transform so quickly. I shook off the dust from the old books on algorithms, opened it, and read with pleasure on a deceptively simple computer tricks that George. W. Cooley and John Tukey described in his classic work of 1965 on this topic.

The goal of this post is to plunge into the Cooley-Tukey FFT algorithm, explaining the symmetries that lead to it, and show some simple Python implementations that apply theory in practice. I hope that this study will give data analysis specialists, such as myself, a more complete picture of what is happening under the hood of the algorithms we use.
Discrete Fourier Transform The
FFT is a fast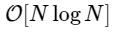 algorithm for calculating the discrete Fourier transform (DFT), which is directly calculated for
algorithm for calculating the discrete Fourier transform (DFT), which is directly calculated for 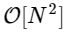 . The DFT, like the more familiar continuous version of the Fourier transform, has a direct and inverse form, which are defined as follows:
. The DFT, like the more familiar continuous version of the Fourier transform, has a direct and inverse form, which are defined as follows:
Forward discrete Fourier transform (DFT):
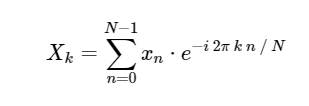
Inverse discrete Fourier transform (DFT):
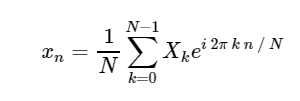
Transformation from
Due to the importance of FFT (hereinafter, the equivalent FFT - Fast Fourier Transform can be used) in many areas of Python contains many standard tools and shells for calculating it. Both NumPy and SciPy have shells from the extremely well-tested FFTPACK library, which are located in submodules
For the moment, however, let's leave these implementations aside and wonder how we can calculate FFT in Python from scratch.
Discrete Fourier Transform Calculation
For simplicity, we will only deal with direct conversion, since the inverse transformation can be implemented in a very similar way. Looking at the above DFT expression, we see that this is nothing more than a linear linear operation: multiplying the matrix by a vector
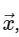
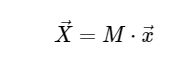
with the matrix M given.
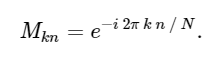
With this in mind, we can calculate the DFT using a simple matrix multiplication as follows:
In [ 1]:
We can double-check the result by comparing it with the FFT function built into numpy:
In [2]:
0ut [2]:
Just to confirm the slowness of our algorithm, we can compare the execution time of these two approaches:
In [3]:
We are more than 1000 times slower, which is to be expected for such a simplified implementation. But this is not the worst. For an input vector of length N, the FFT algorithm scales as , while our slow algorithm scales as
, while our slow algorithm scales as 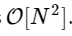 . This means that for
. This means that for 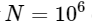 elements, we expect the FFT to complete in about 50 ms, while our slow algorithm will take about 20 hours!
elements, we expect the FFT to complete in about 50 ms, while our slow algorithm will take about 20 hours!
So how does the FFT achieve such an acceleration? The answer is to use symmetry.
Symmetries in the discrete Fourier transform
One of the most important tools in building algorithms is the use of task symmetries. If you can analytically show that one part of the problem is simply related to the other, you can calculate the sub-result only once and save this computational cost. Cooley and Tukey used exactly this approach to obtain FFT.
We'll start with a question about the meaning . From our expression above:
. From our expression above:

where we used the identity exp [2π in] = 1, which holds for any integer n.
The last line shows well the symmetry property of the DFT:
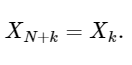
A simple extension,
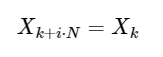
for any integer i. As we will see below, this symmetry can be used to calculate the DFT much faster.
DFT in FFT: using symmetry
Cooley and Tukey showed that FFT calculations can be divided into two smaller parts. From the definition of the DFT we have:
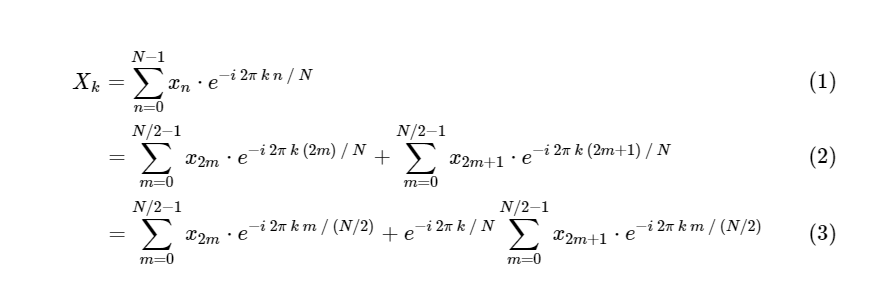
We divided one discrete Fourier transform into two terms, which in themselves are very similar to smaller discrete Fourier transforms, one to values with an odd number and one to values with an even number. However, so far we have not saved any computational cycles. Each term consists of (N / 2) ∗ N calculations, in total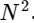 .
.
The trick is to use symmetry in each of these conditions. Since the range of k is 0≤kit became 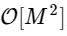 , where M is two times smaller than N.
, where M is two times smaller than N.
But there is no reason to dwell on this: as long as our smaller Fourier transforms have an even M, we can re-apply this “divide and conquer” approach, each time halving the computational cost, until our arrays become small enough so that the strategy no longer promises benefits. In the asymptotic limit, this recursive approach scales as O [NlogN].
This recursive algorithm can be implemented very quickly in Python, starting from our slow DFT code, when the size of the subtask becomes quite small:
In [4]:
Here we will make a quick check that our algorithm gives the correct result:
In [5]:
Out [5]:
Compare this algorithm with our slow version:
-In [6]:
Our calculation is faster than the direct version! Moreover, our recursive algorithm asymptoticallywe have implemented the fast Fourier transform.
Note that we are still not close to the speed of the numpy built-in FFT algorithm, and this should be expected. The FFTPACK algorithm behind
A good strategy for speeding up code when working with Python / NumPy is to vectorize repeating calculations whenever possible. We can do this - in the process, delete our recursive function calls, which will make our Python FFT even more efficient.
Vectorized Numpy-version
Note that in the above-mentioned FFT recursive implementation at the lowest level of recursion we perform N / 32 identical matrix-vector products. The effectiveness of our algorithm will win if we simultaneously calculate these matrix-vector products as a single matrix-matrix product. At each subsequent recursion level, we also perform repetitive operations that can be vectorized. NumPy does an excellent job of such an operation, and we can use this fact to create this vectorized version of the fast Fourier transform:
In [7]:
Although the algorithm is slightly more opaque, it is simply a rearrangement of the operations used in the recursive version, with one exception: we use symmetry in the calculation of the coefficients and build only half of the array. Again, we confirm that our function gives the correct result:
In [8]:
Out [8]:
As our algorithms become much more efficient, we can use a larger array to compare time, leaving
In [9]:
We have improved our implementation by an order of magnitude! Now we are about 10 times away from the FFTPACK benchmark, using just a couple dozen lines of pure Python + NumPy. Although this is still not computationally consistent, in terms of readability, the Python version is far superior to the FFTPACK source code, which you can view here .
So how does FFTPACK achieve this last acceleration? Well, basically, it's just a matter of detailed bookkeeping. FFTPACK spends a lot of time reusing any intermediate calculations that can be reused. Our ragged version still includes excess memory allocation and copying; in a low-level language such as Fortran, it is easier to control and minimize memory usage. In addition, the Cooley-Tukey algorithm can be extended to use partitions with a size other than 2 (what we have implemented here is known as the Cooley-Tukey Radix FFT from base 2). Other more complex FFT algorithms can also be used, including fundamentally different approaches based on convolution data (see, for example, the Blueshtein algorithm and the Raider algorithm).
Although functions in pure Python are probably useless in practice, I hope that they provide some insight into what is happening in the background of FFT-based data analysis. As data specialists, we can cope with the implementation of the “black box” of fundamental tools created by our more algorithmically-minded colleagues, but I strongly believe that the more understanding we have about the low-level algorithms that we apply to our data, the better practices we will.
This post was written entirely in IPython Notepad. The full notebook can be downloaded here or viewed statically here .
Many may notice that the material is far from new, but, as it seems to us, is quite relevant. In general, write whether the article was useful. Waiting for your comments.
Fast Fourier Transform (FFT) is one of the most important signal processing and data analysis algorithms. I used it for years without formal knowledge in computer science. But this week it occurred to me that I never wondered how the FFT calculates the discrete Fourier transform so quickly. I shook off the dust from the old books on algorithms, opened it, and read with pleasure on a deceptively simple computer tricks that George. W. Cooley and John Tukey described in his classic work of 1965 on this topic.
The goal of this post is to plunge into the Cooley-Tukey FFT algorithm, explaining the symmetries that lead to it, and show some simple Python implementations that apply theory in practice. I hope that this study will give data analysis specialists, such as myself, a more complete picture of what is happening under the hood of the algorithms we use.
Discrete Fourier Transform The
FFT is a fast
algorithm for calculating the discrete Fourier transform (DFT), which is directly calculated for . The DFT, like the more familiar continuous version of the Fourier transform, has a direct and inverse form, which are defined as follows: Forward discrete Fourier transform (DFT):
Inverse discrete Fourier transform (DFT):
Transformation from
xn → XkIt is a translation from the configuration space into the frequency space and can be very useful both for studying the signal power spectrum and for converting certain tasks for more efficient calculation. You can find some examples of this in action in chapter 10 of our future book on astronomy and statistics, where you can also find images and Python source code. For an example of using FFT to simplify the integration of otherwise complicated differential equations, see my post “Solving the Schrödinger equation in Python” .Due to the importance of FFT (hereinafter, the equivalent FFT - Fast Fourier Transform can be used) in many areas of Python contains many standard tools and shells for calculating it. Both NumPy and SciPy have shells from the extremely well-tested FFTPACK library, which are located in submodules
numpy.fftand scipy.fftpackrespectively. The fastest FFT that I know of is in the FFTW package , which is also available in Python through the PyFFTW package . For the moment, however, let's leave these implementations aside and wonder how we can calculate FFT in Python from scratch.
Discrete Fourier Transform Calculation
For simplicity, we will only deal with direct conversion, since the inverse transformation can be implemented in a very similar way. Looking at the above DFT expression, we see that this is nothing more than a linear linear operation: multiplying the matrix by a vector
with the matrix M given.
With this in mind, we can calculate the DFT using a simple matrix multiplication as follows:
In [ 1]:
import numpy as np
def DFT_slow(x):
"""Compute the discrete Fourier Transform of the 1D array x"""
x = np.asarray(x, dtype=float)
N = x.shape[0]
n = np.arange(N)
k = n.reshape((N, 1))
M = np.exp(-2j * np.pi * k * n / N)
return np.dot(M, x)We can double-check the result by comparing it with the FFT function built into numpy:
In [2]:
x = np.random.random(1024)
np.allclose(DFT_slow(x), np.fft.fft(x))0ut [2]:
TrueJust to confirm the slowness of our algorithm, we can compare the execution time of these two approaches:
In [3]:
%timeit DFT_slow(x)
%timeit np.fft.fft(x)10 loops, best of 3: 75.4 ms per loop
10000 loops, best of 3: 25.5 µs per loopWe are more than 1000 times slower, which is to be expected for such a simplified implementation. But this is not the worst. For an input vector of length N, the FFT algorithm scales as
, while our slow algorithm scales as . This means that for elements, we expect the FFT to complete in about 50 ms, while our slow algorithm will take about 20 hours! So how does the FFT achieve such an acceleration? The answer is to use symmetry.
Symmetries in the discrete Fourier transform
One of the most important tools in building algorithms is the use of task symmetries. If you can analytically show that one part of the problem is simply related to the other, you can calculate the sub-result only once and save this computational cost. Cooley and Tukey used exactly this approach to obtain FFT.
We'll start with a question about the meaning
. From our expression above: where we used the identity exp [2π in] = 1, which holds for any integer n.
The last line shows well the symmetry property of the DFT:
A simple extension,
for any integer i. As we will see below, this symmetry can be used to calculate the DFT much faster.
DFT in FFT: using symmetry
Cooley and Tukey showed that FFT calculations can be divided into two smaller parts. From the definition of the DFT we have:
We divided one discrete Fourier transform into two terms, which in themselves are very similar to smaller discrete Fourier transforms, one to values with an odd number and one to values with an even number. However, so far we have not saved any computational cycles. Each term consists of (N / 2) ∗ N calculations, in total
. The trick is to use symmetry in each of these conditions. Since the range of k is 0≤k
, where M is two times smaller than N. But there is no reason to dwell on this: as long as our smaller Fourier transforms have an even M, we can re-apply this “divide and conquer” approach, each time halving the computational cost, until our arrays become small enough so that the strategy no longer promises benefits. In the asymptotic limit, this recursive approach scales as O [NlogN].
This recursive algorithm can be implemented very quickly in Python, starting from our slow DFT code, when the size of the subtask becomes quite small:
In [4]:
def FFT(x):
"""A recursive implementation of the 1D Cooley-Tukey FFT"""
x = np.asarray(x, dtype=float)
N = x.shape[0]
if N % 2 > 0:
raise ValueError("size of x must be a power of 2")
elif N <= 32: # this cutoff should be optimized
return DFT_slow(x)
else:
X_even = FFT(x[::2])
X_odd = FFT(x[1::2])
factor = np.exp(-2j * np.pi * np.arange(N) / N)
return np.concatenate([X_even + factor[:N / 2] * X_odd,
X_even + factor[N / 2:] * X_odd])Here we will make a quick check that our algorithm gives the correct result:
In [5]:
x = np.random.random(1024)
np.allclose(FFT(x), np.fft.fft(x))Out [5]:
TrueCompare this algorithm with our slow version:
-In [6]:
%timeit DFT_slow(x)
%timeit FFT(x)
%timeit np.fft.fft(x)10 loops, best of 3: 77.6 ms per loop
100 loops, best of 3: 4.07 ms per loop
10000 loops, best of 3: 24.7 µs per loopOur calculation is faster than the direct version! Moreover, our recursive algorithm asymptotically
we have implemented the fast Fourier transform. Note that we are still not close to the speed of the numpy built-in FFT algorithm, and this should be expected. The FFTPACK algorithm behind
fftnumpy is a Fortran implementation that has received years of refinement and optimization. In addition, our NumPy solution includes both recursion of the Python stack and allocation of many temporary arrays, which increases the computational time. A good strategy for speeding up code when working with Python / NumPy is to vectorize repeating calculations whenever possible. We can do this - in the process, delete our recursive function calls, which will make our Python FFT even more efficient.
Vectorized Numpy-version
Note that in the above-mentioned FFT recursive implementation at the lowest level of recursion we perform N / 32 identical matrix-vector products. The effectiveness of our algorithm will win if we simultaneously calculate these matrix-vector products as a single matrix-matrix product. At each subsequent recursion level, we also perform repetitive operations that can be vectorized. NumPy does an excellent job of such an operation, and we can use this fact to create this vectorized version of the fast Fourier transform:
In [7]:
def FFT_vectorized(x):
"""A vectorized, non-recursive version of the Cooley-Tukey FFT"""
x = np.asarray(x, dtype=float)
N = x.shape[0]
if np.log2(N) % 1 > 0:
raise ValueError("size of x must be a power of 2")
# N_min here is equivalent to the stopping condition above,
# and should be a power of 2
N_min = min(N, 32)
# Perform an O[N^2] DFT on all length-N_min sub-problems at once
n = np.arange(N_min)
k = n[:, None]
M = np.exp(-2j * np.pi * n * k / N_min)
X = np.dot(M, x.reshape((N_min, -1)))
# build-up each level of the recursive calculation all at once
while X.shape[0] < N:
X_even = X[:, :X.shape[1] / 2]
X_odd = X[:, X.shape[1] / 2:]
factor = np.exp(-1j * np.pi * np.arange(X.shape[0])
/ X.shape[0])[:, None]
X = np.vstack([X_even + factor * X_odd,
X_even - factor * X_odd])
return X.ravel()Although the algorithm is slightly more opaque, it is simply a rearrangement of the operations used in the recursive version, with one exception: we use symmetry in the calculation of the coefficients and build only half of the array. Again, we confirm that our function gives the correct result:
In [8]:
x = np.random.random(1024)
np.allclose(FFT_vectorized(x), np.fft.fft(x))Out [8]:
TrueAs our algorithms become much more efficient, we can use a larger array to compare time, leaving
DFT_slow: In [9]:
x = np.random.random(1024 * 16)
%timeit FFT(x)
%timeit FFT_vectorized(x)
%timeit np.fft.fft(x)10 loops, best of 3: 72.8 ms per loop
100 loops, best of 3: 4.11 ms per loop
1000 loops, best of 3: 505 µs per loopWe have improved our implementation by an order of magnitude! Now we are about 10 times away from the FFTPACK benchmark, using just a couple dozen lines of pure Python + NumPy. Although this is still not computationally consistent, in terms of readability, the Python version is far superior to the FFTPACK source code, which you can view here .
So how does FFTPACK achieve this last acceleration? Well, basically, it's just a matter of detailed bookkeeping. FFTPACK spends a lot of time reusing any intermediate calculations that can be reused. Our ragged version still includes excess memory allocation and copying; in a low-level language such as Fortran, it is easier to control and minimize memory usage. In addition, the Cooley-Tukey algorithm can be extended to use partitions with a size other than 2 (what we have implemented here is known as the Cooley-Tukey Radix FFT from base 2). Other more complex FFT algorithms can also be used, including fundamentally different approaches based on convolution data (see, for example, the Blueshtein algorithm and the Raider algorithm).
Although functions in pure Python are probably useless in practice, I hope that they provide some insight into what is happening in the background of FFT-based data analysis. As data specialists, we can cope with the implementation of the “black box” of fundamental tools created by our more algorithmically-minded colleagues, but I strongly believe that the more understanding we have about the low-level algorithms that we apply to our data, the better practices we will.
This post was written entirely in IPython Notepad. The full notebook can be downloaded here or viewed statically here .
Many may notice that the material is far from new, but, as it seems to us, is quite relevant. In general, write whether the article was useful. Waiting for your comments.