Ok Google: How do I get through the captcha?
Hello. My name is Ibadov Ilkin, I am a student of the Ural Federal University.
In this article I want to talk about my experience with the automated solution for Google’s captcha - “reCAPTCHA”. I would like to warn the reader in advance that at the time of writing the article, the prototype does not work as efficiently as it might seem from the title, however, the result demonstrates that the approach being implemented is able to solve the problem.
Probably, everyone in his life came across a captcha: enter text from a picture, solve a simple expression or a complicated equation, choose cars, fire hydrants, pedestrian crossings ... Protecting resources from automated systems is necessary and plays a significant role in security: captcha protects against DDoS attacks , automatic registrations and postings, parsing, prevents spam and password selection for accounts.
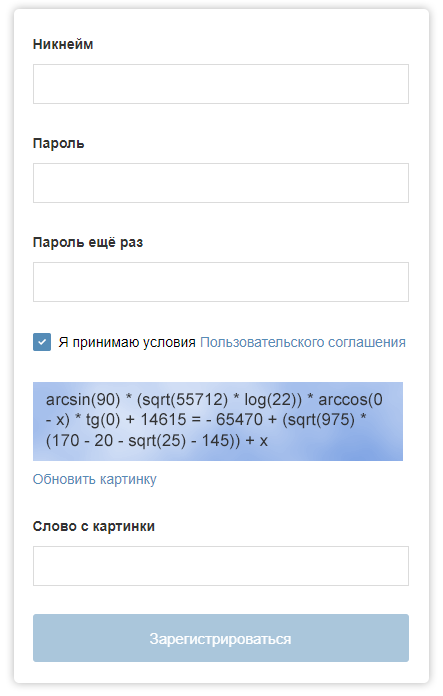
The registration form on "Habré" could be with such a captcha.
With the development of machine learning technologies, the performance of captcha may be at risk. In this article, I describe the key points of a program that can solve the problem of manually selecting images in Google reCAPTCHA (fortunately, not always so far).
To get through captcha, it is necessary to solve such problems as: determining the required captcha class, detecting and classifying objects, detecting captcha cells, imitating human activities in solving captcha (cursor movement, click).
To search for objects in an image, trained neural networks are used that can be downloaded to a computer and recognize objects in images or videos. But to solve the captcha, just detecting objects is not enough: you need to determine the position of the cells and find out which cells you want to select (or not to select cells at all). For this, computer vision tools are used: in this work, this is the famous OpenCV library .
In order to find objects in the image, firstly, the image itself is required. I get a screenshot of a part of the screen using the PyAutoGUI module with dimensions sufficient for detecting objects. In the rest of the screen, I display windows for debugging and monitoring program processes.
Detection and classification of objects is what the neural network does. The library that allows us to work with neural networks is called " Tensorflow " (developed by Google). Today, there are many different trained models for your choice on different data , which means that all of them can return a different detection result: some models will better detect objects, and some worse.
In this paper, I am using the ssd_mobilenet_v1_coco model. The selected model is trained on the COCO dataset”, Which distinguishes 90 different classes (from people and cars to toothbrushes and combs). Now there are other models that are trained on the same data, but with different parameters. In addition, this model has optimal performance and accuracy parameters, which is important for a desktop computer. The source says that the processing time for one frame of 300 x 300 pixels is 30 milliseconds. On the "Nvidia GeForce GTX TITAN X".
The result of the neural network is a set of arrays:
The indices of the elements in these arrays correspond to each other, that is: the third element in the array of object classes corresponds to the third element in the array of "boxes" of the detected objects and the third element in the array of object ratings.

The selected model allows you to detect objects from 90 classes in real time.
“OpenCV” provides us with the ability to operate with entities called “ circuits ”: They can be detected only by the “findContours ()” function from the “OpenCV” library. It is necessary to submit a binary image to the input of such a function, which can be obtained by the threshold transformation function :
Having set the extreme values of the parameters of the threshold transformation function, we also get rid of various kinds of noise. Also, to minimize the amount of unnecessary small elements and noise, morphological transformations can be applied : erosion (compression) and build-up (expansion) functions. These functions are also part of OpenCV. After the transformations, the contours are selected whose number of vertices is four (having previously performed the approximation function on the contours ).

In the first window, the result of the threshold transformation. The second is an example of morphological transformation. In the third window, the cells and captcha cap are already selected: highlighted in color programmatically.
After all the transformations, the contours that are not cells still fall into the final array with cells. In order to filter out unnecessary noises, I select according to the values of the length (perimeter) and the area of the contours.
It was experimentally revealed that the values of the circuits of interest lie in the range from 360 to 900 units. This value is selected on the screen with a diagonal of 15.6 inches and a resolution of 1366 x 768 pixels. Further, the indicated values of the contours can be calculated depending on the size of the user's screen, but there is no such link in the prototype being created.
The main advantage of the chosen approach to detecting cells is that we don’t care what the grid will look like and how many cells will be displayed on the captcha page: 8, 9 or 16.
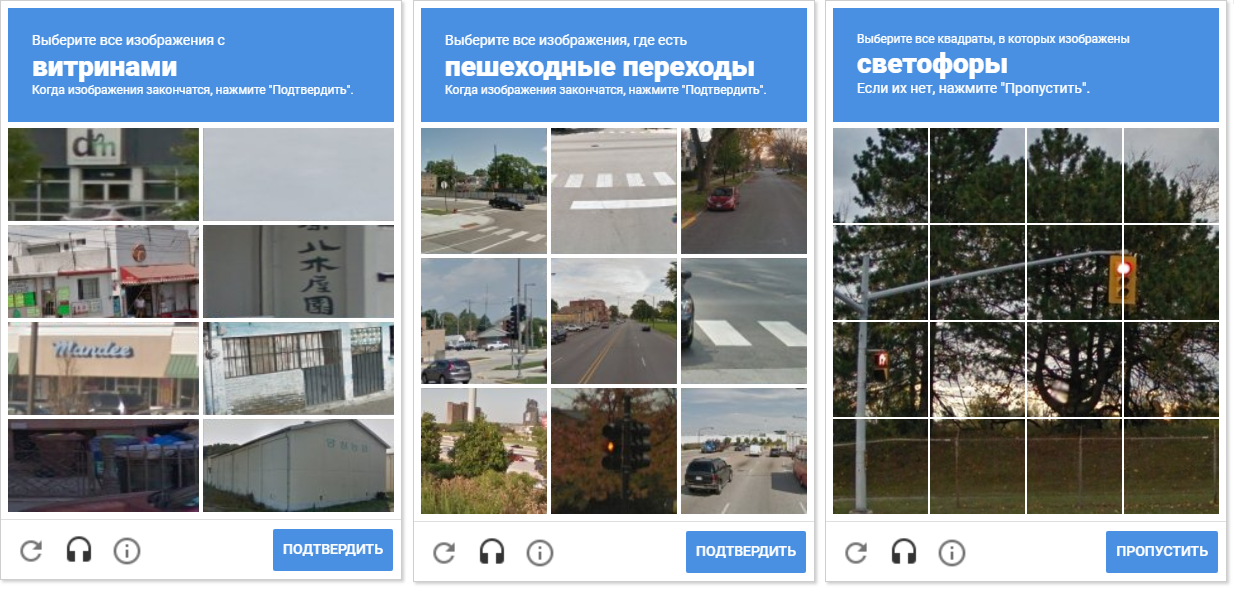
The image shows a variety of captcha nets. Please note that the distance between the cells is different. To separate cells from each other allows morphological compression.
An additional advantage of detecting contours is that OpenCV allows us to detect their centers (we need them to determine the coordinates of movement and mouse click).
Having an array with clean contours of CAPTCHA cells without unnecessary noise circuits, we can cycle through each CAPTCHA cell (“circuit” in the terminology “OpenCV”) and check for the fact that it intersects with the detected “box” of the object received from the neural network.
To establish this fact, the transfer of the detected “box” to a circuit similar to the cells was used. But this approach turned out to be wrong, because the case when the object is located inside the cell is not considered an intersection. Naturally, such cells did not stand out in the captcha.
The problem was solved by redrawing the outline of each cell (with white fill) onto a black sheet. In a similar way, a binary image of a frame with an object was obtained. The question arises - how now to establish the fact of the intersection of the cell with the shaded frame of the object? In each iteration of an array with cells, a disjunction operation (logical or) is performed on two binary images. As a result, we get a new binary image in which intersected areas will be highlighted. That is, if there are such areas, then the cell and the frame of the object intersect. Programmatically, such a check can be done using the “ .any () ” method : it will return “True” if the array has at least one element equal to one or “False” if there are no units.
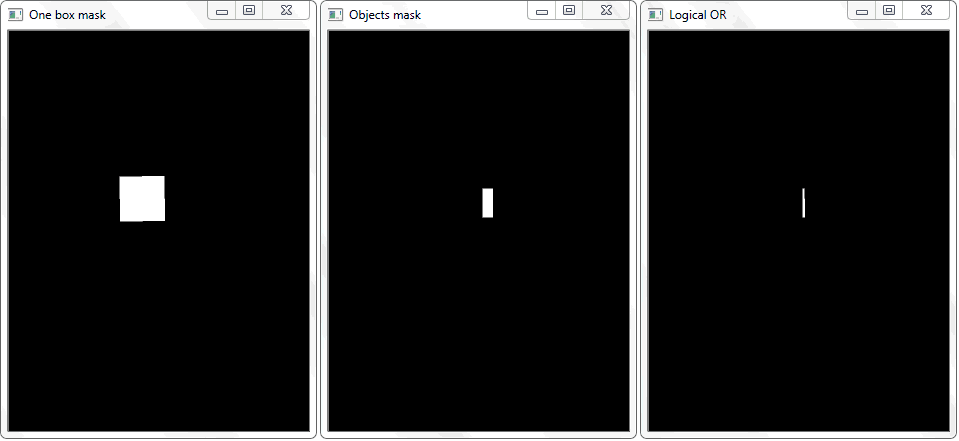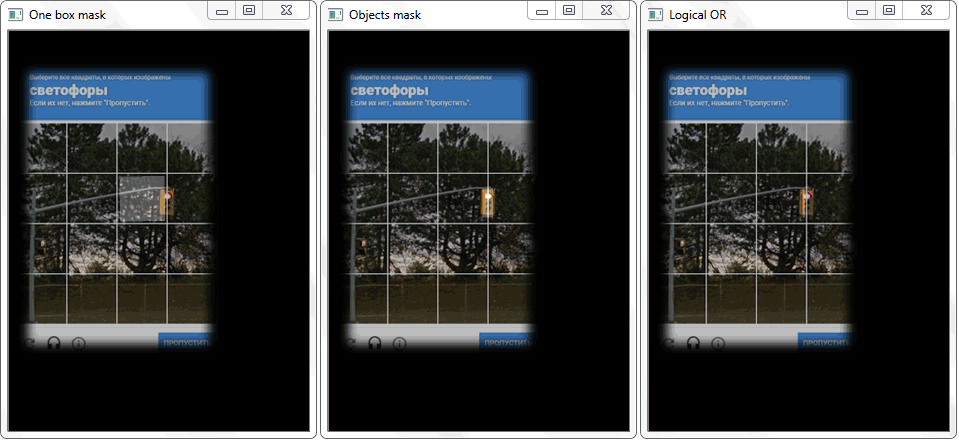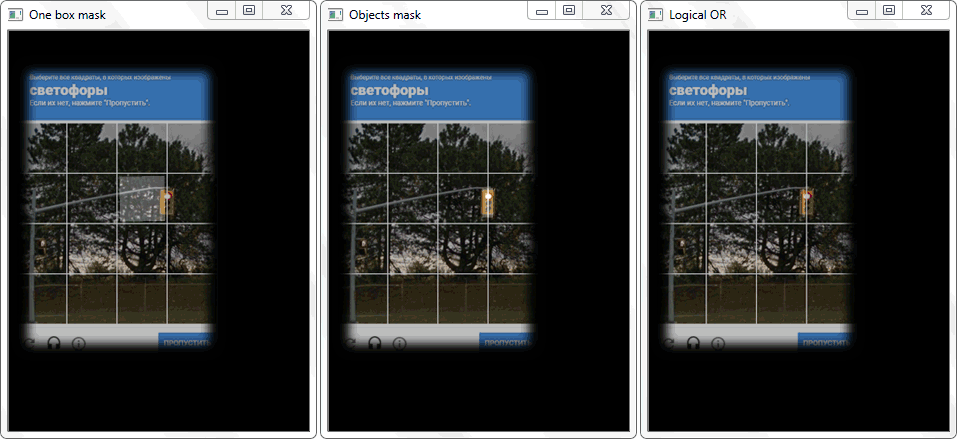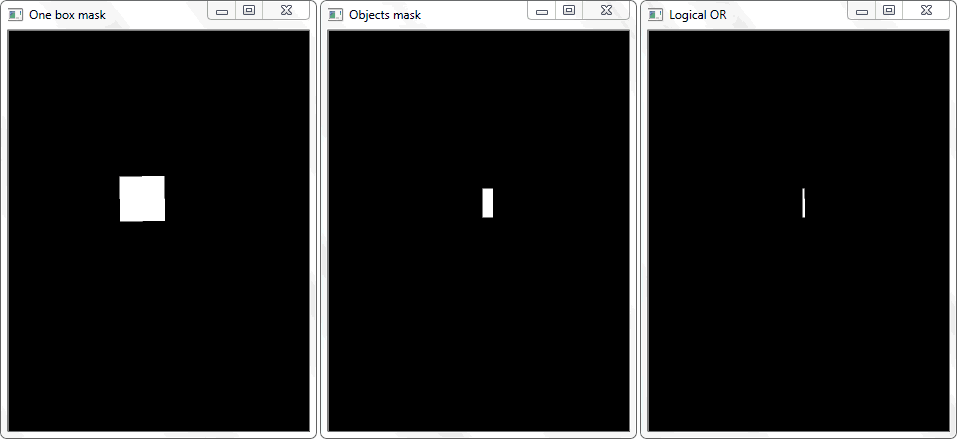
The function “any ()” for the image “Logical OR” in this case will return true and thereby establish the fact of the intersection of the cell with the frame area of the detected object.
Cursor control in “Python” is made available thanks to the “win32api” module (however, it later turned out that the “PyAutoGUI” already imported into the project also knows how to do this). Pressing and releasing the left mouse button, as well as moving the cursor to the desired coordinates, is performed by the corresponding functions of the win32api module. But in the prototype, they were wrapped in user-defined functions in order to provide visual observation of the cursor movement. This negatively affects performance and was implemented solely for demonstration.
During the development process, the idea arose of choosing cells in a random order. It’s possible that this doesn’t make sense (for obvious reasons, Google doesn’t give us comments and descriptions of the mechanisms of captcha operation), but moving the cursor through the cells in a chaotic manner looks more fun.
On the animation, the result is "random.shuffle (boxesForSelect)".
In order to combine all the available developments into a single whole, one more link is required: a recognition unit for the class required from the captcha. We already know how to recognize and distinguish different objects in the image, we can click on arbitrary captcha cells, but we don’t know which cells to click on. One of the ways to solve this problem is to recognize text from the captcha heading. First of all, I tried to implement text recognition using the optical character recognition tool " Tesseract-OCR ".
In the latest versions, it is possible to install language packs directly in the installer window (previously this was done manually). After installing and importing Tesseract-OCR into my project, I tried to recognize the text from the captcha header.
The result, unfortunately, did not impress me at all. I decided that the text in the header was highlighted in bold and merged for a reason, so I tried to apply various transformations to the image: binarization, narrowing, expansion, blurring, distortion and resizing operations. Unfortunately, this did not give a good result: in the best cases, only a part of the class letters was determined, and when the result was satisfactory, I applied the same transformations, but for other caps (with different text), and the result turned out to be bad again.

Recognition of the Tesseract-OCR caps usually led to unsatisfactory results.
It is impossible to say unequivocally that “Tesseract-OCR” does not recognize text well, this is not so: the tool copes with other images (not captcha caps) much better.
I decided to use a third-party service that offered an API for working with it for free (registration and receipt of a key to an email address is required). The service has a limit of 500 recognitions per day, but for the entire development period I have not encountered any problems with limitations. On the contrary: I submitted the original image of the header to the service (without applying absolutely any transformations) and the result impressed me pleasantly.
Words from the service were returned practically without errors (usually even those written in small print). Moreover, they returned in a very convenient format - broken by line with line break characters. In all the images, I was only interested in the second line, so I directly accessed it. This could not but rejoice, since such a format freed me from the need to prepare a line: I did not have to cut the beginning or end of the whole text, do “trims”, replacements, work with regular expressions and perform other operations on the line, aimed at highlighting one word (and sometimes two!) - a nice bonus!
A service that recognized text almost never made a mistake with the class name, but I still decided to leave part of the class name for a possible error. This is optional, but I noticed that “Tesseract-OCR” in some cases incorrectly recognized the end of a word starting from the middle. In addition, this approach eliminates the application error in the case of a long class name or a two-word name (in this case, the service will return not 3, but 4 lines, and I cannot find the full name of the class in the second line).
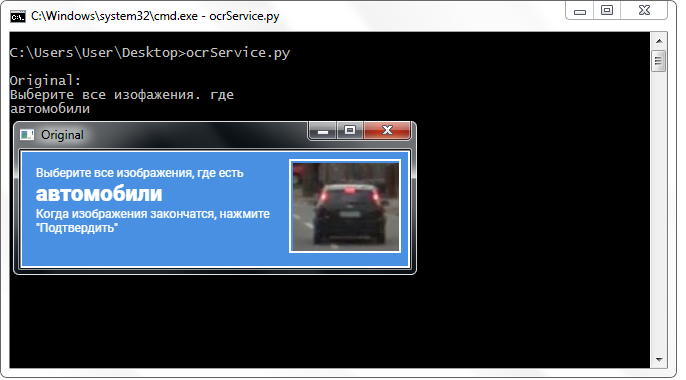
A third-party service recognizes the class name well without any transformations over the image.
Getting text from the header is not enough. It needs to be compared with the identifiers of the available model classes, because in the class array the neural network returns exactly the class identifier, and not its name, as it may seem. When training the model, as a rule, a file is created in which class names and their identifiers are compared (aka “label map”). I decided to do it easier and specify the class identifiers manually, since captcha still requires classes in Russian (by the way, this can be changed):
Everything described above is reproduced in the main cycle of the program: the frames of the object, the cell, their intersections are determined, the cursor moves and clicks. When a header is detected, text recognition is performed. If the neural network cannot detect the required class, then an arbitrary shift of the image is performed up to 5 times (that is, the input to the neural network is changed), and if the detection still does not happen, then the “Skip / Confirm” button is clicked (its position is detected similarly detect cells and caps).
If you often solve the captcha, you could observe the picture when the selected cell disappears, and a new one slowly and slowly appears in its place. Since the prototype is programmed to instantly go to the next page after selecting all the cells, I decided to make 3 second pauses to exclude clicking on the “Next” button without detecting objects on the slowly appearing cell.
The article would not be complete if it did not contain a description of the most important thing - a checkmark for successfully passing captcha. I decided that a simple template comparison could do this.. It is worth noting that pattern matching is far from the best way to detect objects. For example, I had to set the detection sensitivity to “0.01” so that the function stopped seeing ticks in everything, but saw it when there really is a tick. Similarly, I acted with an empty checkbox that meets the user and from which the captcha starts (there were no problems with sensitivity).
The result of all the described actions was an application, the performance of which I tested on the " Toaster ":
It is worth recognizing that the video was not shot on the first try, as I often faced with the need to choose classes that are not in the model (for example, pedestrian crossings, stairs or shop windows).
“Google reCAPTCHA” returns a certain value to the site, showing how “You are a robot”, and site administrators, in turn, can set a threshold for passing this value. It is possible that a relatively low captcha threshold was set on the Toaster. This explains the rather easy passage of the captcha by the program, despite the fact that it was mistaken twice, not seeing the traffic light from the first page and the fire hydrant from the fourth page of the captcha.
In addition to the Toaster, experiments were conducted on the official demo page of reCAPTCHA. As a result, it was noticed that after multiple erroneous detections (and non-detections), getting a captcha becomes extremely difficult even for a person: new classes are required (like tractors and palm trees), cells without objects appear in the samples (almost monotonous colors) and the number of pages increases dramatically, to go through.
This was especially noticeable when I decided to try clicking on random cells in case of non-detection of objects (due to their absence in the model). Therefore, we can say for sure that random clicks will not lead to a solution to the problem. To get rid of such a “blockage” by the examiner, we reconnected the Internet connection and cleared the browser data, because it became impossible to pass such a test - it was almost endless!

If you doubt your humanity, such an outcome is possible.
If the article and the application arouse interest of the reader, I will gladly continue its implementation, tests and the further description in a more detailed form.
It is about finding classes that are not part of the current network, this will greatly improve the efficiency of the application. At the moment, there is an urgent need to recognize at least such classes as: pedestrian crossings, shop windows and chimneys - I will tell you how to retrain the model. During development, I made a short list of the most common classes:
Improving the quality of object detection can be achieved by using several models at the same time: this can degrade performance, but increase accuracy.
Another way to improve the quality of detection of objects is to change the image input to the neural network: on the video you can see that when objects are not detected, I do an arbitrary image shift several times (within 10 pixels horizontally and vertically), and often this operation allows you to see objects that were previously were not detected.
An increase in the image from a small square to a large one (up to 300 x 300 pixels) also leads to the detection of undetected objects.

No objects were found on the left: original square with 100 pixels side. On the right, a bus is detected: an enlarged square up to 300 x 300 pixels.
Another interesting transformation is the removal of the white grid over the image using OpenCV tools: it is possible that the fire hydrant was not detected in the video for this reason (this class is present in the neural network).
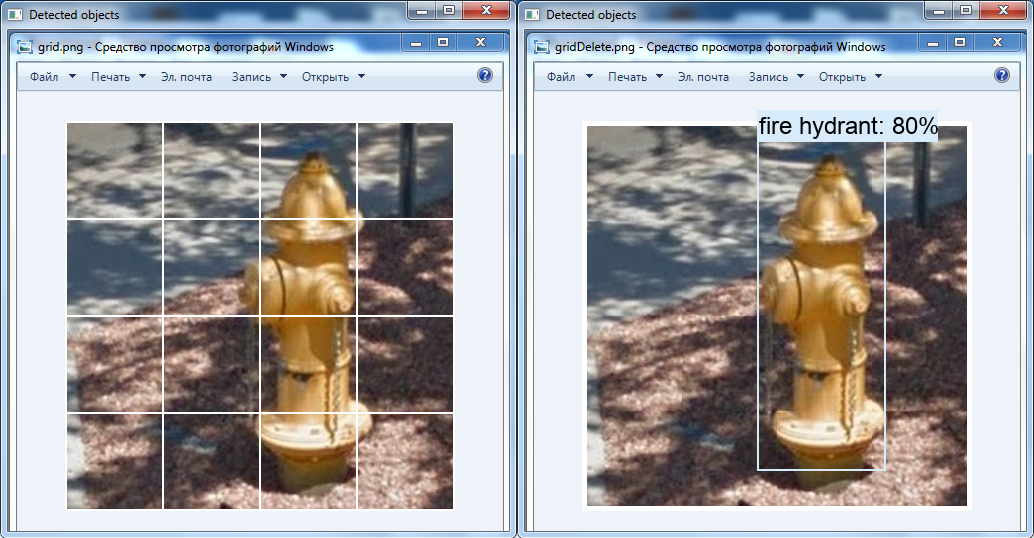
On the left is the original image, and on the right is the image that was changed in the graphics editor: the grid is deleted, the cells are moved to each other.
With this article, I wanted to tell you that captcha is probably not the best protection against bots, and it is quite possible that in the near future there will be a need for new means of protection against automated systems.
The developed prototype, even being in an incomplete state, demonstrates that with the required classes in the neural network model and applying transformations over images, it is possible to achieve automation of a process that should not be automated.
Also, I would like to draw the attention of Google to the fact that in addition to the way to bypass captcha described in this article, there is also another way in which transcription is performedaudio sample. In my opinion, it is now necessary to take measures related to improving the quality of software products and algorithms against robots.
From the content and essence of the material, it may seem that I do not like Google and, in particular, reCAPTCHA, but this is far from the case, and if there is a next implementation, I will tell you why.
Developed and demonstrated in order to improve education and improve methods aimed at ensuring information security.
Thanks for attention.
In this article I want to talk about my experience with the automated solution for Google’s captcha - “reCAPTCHA”. I would like to warn the reader in advance that at the time of writing the article, the prototype does not work as efficiently as it might seem from the title, however, the result demonstrates that the approach being implemented is able to solve the problem.
Probably, everyone in his life came across a captcha: enter text from a picture, solve a simple expression or a complicated equation, choose cars, fire hydrants, pedestrian crossings ... Protecting resources from automated systems is necessary and plays a significant role in security: captcha protects against DDoS attacks , automatic registrations and postings, parsing, prevents spam and password selection for accounts.
The registration form on "Habré" could be with such a captcha.
With the development of machine learning technologies, the performance of captcha may be at risk. In this article, I describe the key points of a program that can solve the problem of manually selecting images in Google reCAPTCHA (fortunately, not always so far).
To get through captcha, it is necessary to solve such problems as: determining the required captcha class, detecting and classifying objects, detecting captcha cells, imitating human activities in solving captcha (cursor movement, click).
To search for objects in an image, trained neural networks are used that can be downloaded to a computer and recognize objects in images or videos. But to solve the captcha, just detecting objects is not enough: you need to determine the position of the cells and find out which cells you want to select (or not to select cells at all). For this, computer vision tools are used: in this work, this is the famous OpenCV library .
In order to find objects in the image, firstly, the image itself is required. I get a screenshot of a part of the screen using the PyAutoGUI module with dimensions sufficient for detecting objects. In the rest of the screen, I display windows for debugging and monitoring program processes.
Object Detection
Detection and classification of objects is what the neural network does. The library that allows us to work with neural networks is called " Tensorflow " (developed by Google). Today, there are many different trained models for your choice on different data , which means that all of them can return a different detection result: some models will better detect objects, and some worse.
In this paper, I am using the ssd_mobilenet_v1_coco model. The selected model is trained on the COCO dataset”, Which distinguishes 90 different classes (from people and cars to toothbrushes and combs). Now there are other models that are trained on the same data, but with different parameters. In addition, this model has optimal performance and accuracy parameters, which is important for a desktop computer. The source says that the processing time for one frame of 300 x 300 pixels is 30 milliseconds. On the "Nvidia GeForce GTX TITAN X".
The result of the neural network is a set of arrays:
- with a list of classes of detected objects (their identifiers);
- with a list of ratings of detected objects (in percent);
- with a list of coordinates of detected objects ("boxes").
The indices of the elements in these arrays correspond to each other, that is: the third element in the array of object classes corresponds to the third element in the array of "boxes" of the detected objects and the third element in the array of object ratings.
The selected model allows you to detect objects from 90 classes in real time.
Cell detection
“OpenCV” provides us with the ability to operate with entities called “ circuits ”: They can be detected only by the “findContours ()” function from the “OpenCV” library. It is necessary to submit a binary image to the input of such a function, which can be obtained by the threshold transformation function :
_retval, binImage = cv2.threshold(image,254,255,cv2.THRESH_BINARY)
contours = cv2.findContours(binImage, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)[0]Having set the extreme values of the parameters of the threshold transformation function, we also get rid of various kinds of noise. Also, to minimize the amount of unnecessary small elements and noise, morphological transformations can be applied : erosion (compression) and build-up (expansion) functions. These functions are also part of OpenCV. After the transformations, the contours are selected whose number of vertices is four (having previously performed the approximation function on the contours ).
In the first window, the result of the threshold transformation. The second is an example of morphological transformation. In the third window, the cells and captcha cap are already selected: highlighted in color programmatically.
After all the transformations, the contours that are not cells still fall into the final array with cells. In order to filter out unnecessary noises, I select according to the values of the length (perimeter) and the area of the contours.
It was experimentally revealed that the values of the circuits of interest lie in the range from 360 to 900 units. This value is selected on the screen with a diagonal of 15.6 inches and a resolution of 1366 x 768 pixels. Further, the indicated values of the contours can be calculated depending on the size of the user's screen, but there is no such link in the prototype being created.
The main advantage of the chosen approach to detecting cells is that we don’t care what the grid will look like and how many cells will be displayed on the captcha page: 8, 9 or 16.
The image shows a variety of captcha nets. Please note that the distance between the cells is different. To separate cells from each other allows morphological compression.
An additional advantage of detecting contours is that OpenCV allows us to detect their centers (we need them to determine the coordinates of movement and mouse click).
Selecting cells to select
Having an array with clean contours of CAPTCHA cells without unnecessary noise circuits, we can cycle through each CAPTCHA cell (“circuit” in the terminology “OpenCV”) and check for the fact that it intersects with the detected “box” of the object received from the neural network.
To establish this fact, the transfer of the detected “box” to a circuit similar to the cells was used. But this approach turned out to be wrong, because the case when the object is located inside the cell is not considered an intersection. Naturally, such cells did not stand out in the captcha.
The problem was solved by redrawing the outline of each cell (with white fill) onto a black sheet. In a similar way, a binary image of a frame with an object was obtained. The question arises - how now to establish the fact of the intersection of the cell with the shaded frame of the object? In each iteration of an array with cells, a disjunction operation (logical or) is performed on two binary images. As a result, we get a new binary image in which intersected areas will be highlighted. That is, if there are such areas, then the cell and the frame of the object intersect. Programmatically, such a check can be done using the “ .any () ” method : it will return “True” if the array has at least one element equal to one or “False” if there are no units.
The function “any ()” for the image “Logical OR” in this case will return true and thereby establish the fact of the intersection of the cell with the frame area of the detected object.
Control
Cursor control in “Python” is made available thanks to the “win32api” module (however, it later turned out that the “PyAutoGUI” already imported into the project also knows how to do this). Pressing and releasing the left mouse button, as well as moving the cursor to the desired coordinates, is performed by the corresponding functions of the win32api module. But in the prototype, they were wrapped in user-defined functions in order to provide visual observation of the cursor movement. This negatively affects performance and was implemented solely for demonstration.
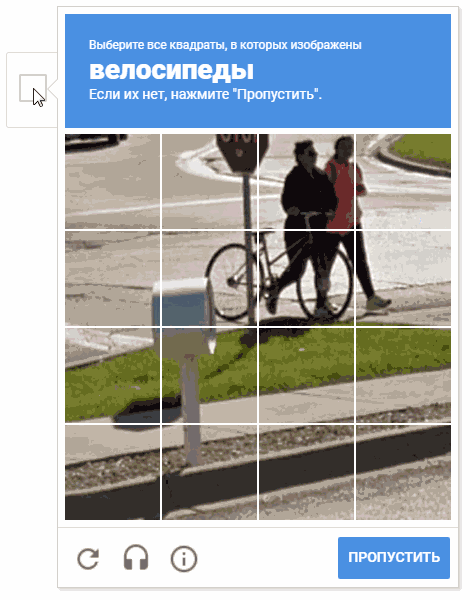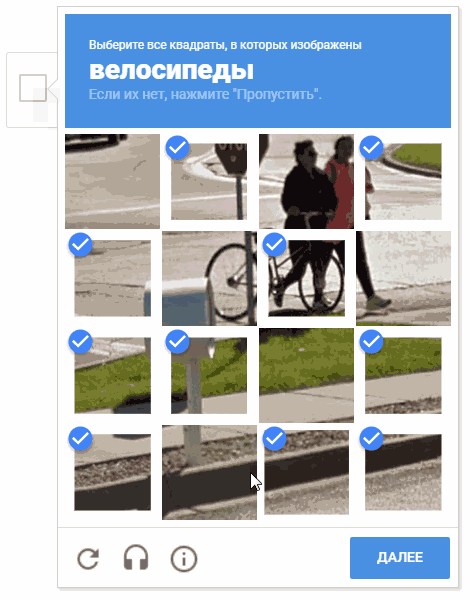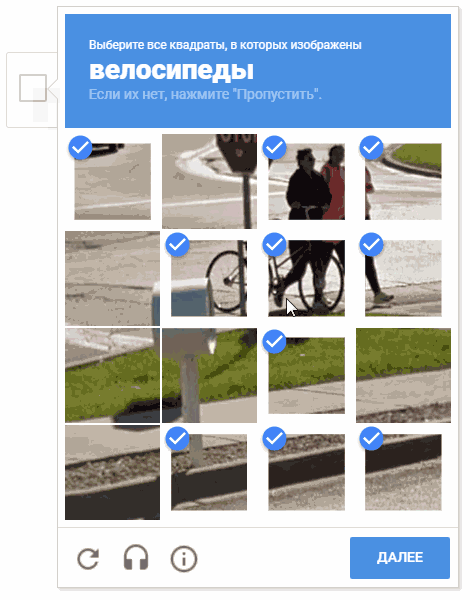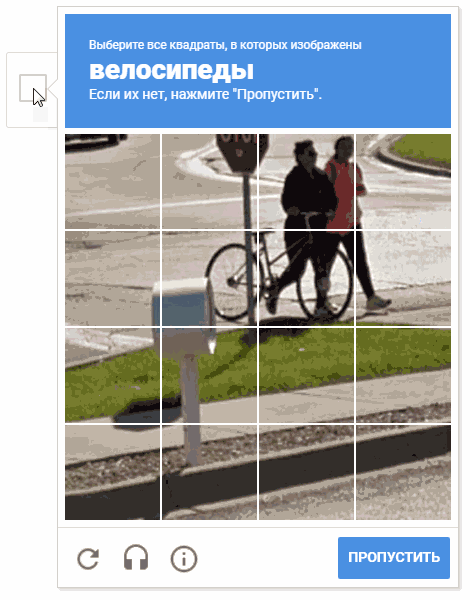
During the development process, the idea arose of choosing cells in a random order. It’s possible that this doesn’t make sense (for obvious reasons, Google doesn’t give us comments and descriptions of the mechanisms of captcha operation), but moving the cursor through the cells in a chaotic manner looks more fun.
On the animation, the result is "random.shuffle (boxesForSelect)".
Text recognising
In order to combine all the available developments into a single whole, one more link is required: a recognition unit for the class required from the captcha. We already know how to recognize and distinguish different objects in the image, we can click on arbitrary captcha cells, but we don’t know which cells to click on. One of the ways to solve this problem is to recognize text from the captcha heading. First of all, I tried to implement text recognition using the optical character recognition tool " Tesseract-OCR ".
In the latest versions, it is possible to install language packs directly in the installer window (previously this was done manually). After installing and importing Tesseract-OCR into my project, I tried to recognize the text from the captcha header.
The result, unfortunately, did not impress me at all. I decided that the text in the header was highlighted in bold and merged for a reason, so I tried to apply various transformations to the image: binarization, narrowing, expansion, blurring, distortion and resizing operations. Unfortunately, this did not give a good result: in the best cases, only a part of the class letters was determined, and when the result was satisfactory, I applied the same transformations, but for other caps (with different text), and the result turned out to be bad again.
Recognition of the Tesseract-OCR caps usually led to unsatisfactory results.
It is impossible to say unequivocally that “Tesseract-OCR” does not recognize text well, this is not so: the tool copes with other images (not captcha caps) much better.
I decided to use a third-party service that offered an API for working with it for free (registration and receipt of a key to an email address is required). The service has a limit of 500 recognitions per day, but for the entire development period I have not encountered any problems with limitations. On the contrary: I submitted the original image of the header to the service (without applying absolutely any transformations) and the result impressed me pleasantly.
Words from the service were returned practically without errors (usually even those written in small print). Moreover, they returned in a very convenient format - broken by line with line break characters. In all the images, I was only interested in the second line, so I directly accessed it. This could not but rejoice, since such a format freed me from the need to prepare a line: I did not have to cut the beginning or end of the whole text, do “trims”, replacements, work with regular expressions and perform other operations on the line, aimed at highlighting one word (and sometimes two!) - a nice bonus!
text = serviceResponse['ParsedResults'][0]['ParsedText'] #получил текст из JSON
lines = text.splitlines() #Разбил на элементы
print("Recognized " + lines[1]) #Готово к использованию!A service that recognized text almost never made a mistake with the class name, but I still decided to leave part of the class name for a possible error. This is optional, but I noticed that “Tesseract-OCR” in some cases incorrectly recognized the end of a word starting from the middle. In addition, this approach eliminates the application error in the case of a long class name or a two-word name (in this case, the service will return not 3, but 4 lines, and I cannot find the full name of the class in the second line).
A third-party service recognizes the class name well without any transformations over the image.
Merger
Getting text from the header is not enough. It needs to be compared with the identifiers of the available model classes, because in the class array the neural network returns exactly the class identifier, and not its name, as it may seem. When training the model, as a rule, a file is created in which class names and their identifiers are compared (aka “label map”). I decided to do it easier and specify the class identifiers manually, since captcha still requires classes in Russian (by the way, this can be changed):
if "автом" in query: # ищем вхождение класса в запросе капчи
classNum = 3 # присваиваем соответствующий "label map" идентификатор
elif "свето" in query:
classNum = 10
elif "пожар" in query:
classNum = 11
...Everything described above is reproduced in the main cycle of the program: the frames of the object, the cell, their intersections are determined, the cursor moves and clicks. When a header is detected, text recognition is performed. If the neural network cannot detect the required class, then an arbitrary shift of the image is performed up to 5 times (that is, the input to the neural network is changed), and if the detection still does not happen, then the “Skip / Confirm” button is clicked (its position is detected similarly detect cells and caps).
If you often solve the captcha, you could observe the picture when the selected cell disappears, and a new one slowly and slowly appears in its place. Since the prototype is programmed to instantly go to the next page after selecting all the cells, I decided to make 3 second pauses to exclude clicking on the “Next” button without detecting objects on the slowly appearing cell.
The article would not be complete if it did not contain a description of the most important thing - a checkmark for successfully passing captcha. I decided that a simple template comparison could do this.. It is worth noting that pattern matching is far from the best way to detect objects. For example, I had to set the detection sensitivity to “0.01” so that the function stopped seeing ticks in everything, but saw it when there really is a tick. Similarly, I acted with an empty checkbox that meets the user and from which the captcha starts (there were no problems with sensitivity).
Result
The result of all the described actions was an application, the performance of which I tested on the " Toaster ":
It is worth recognizing that the video was not shot on the first try, as I often faced with the need to choose classes that are not in the model (for example, pedestrian crossings, stairs or shop windows).
“Google reCAPTCHA” returns a certain value to the site, showing how “You are a robot”, and site administrators, in turn, can set a threshold for passing this value. It is possible that a relatively low captcha threshold was set on the Toaster. This explains the rather easy passage of the captcha by the program, despite the fact that it was mistaken twice, not seeing the traffic light from the first page and the fire hydrant from the fourth page of the captcha.
In addition to the Toaster, experiments were conducted on the official demo page of reCAPTCHA. As a result, it was noticed that after multiple erroneous detections (and non-detections), getting a captcha becomes extremely difficult even for a person: new classes are required (like tractors and palm trees), cells without objects appear in the samples (almost monotonous colors) and the number of pages increases dramatically, to go through.
This was especially noticeable when I decided to try clicking on random cells in case of non-detection of objects (due to their absence in the model). Therefore, we can say for sure that random clicks will not lead to a solution to the problem. To get rid of such a “blockage” by the examiner, we reconnected the Internet connection and cleared the browser data, because it became impossible to pass such a test - it was almost endless!
If you doubt your humanity, such an outcome is possible.
Development
If the article and the application arouse interest of the reader, I will gladly continue its implementation, tests and the further description in a more detailed form.
It is about finding classes that are not part of the current network, this will greatly improve the efficiency of the application. At the moment, there is an urgent need to recognize at least such classes as: pedestrian crossings, shop windows and chimneys - I will tell you how to retrain the model. During development, I made a short list of the most common classes:
- pedestrian crossings;
- fire hydrants;
- shop windows
- chimneys;
- cars;
- Buses
- traffic lights;
- bicycles
- means of transport;
- stairs
- signs.
Improving the quality of object detection can be achieved by using several models at the same time: this can degrade performance, but increase accuracy.
Another way to improve the quality of detection of objects is to change the image input to the neural network: on the video you can see that when objects are not detected, I do an arbitrary image shift several times (within 10 pixels horizontally and vertically), and often this operation allows you to see objects that were previously were not detected.
An increase in the image from a small square to a large one (up to 300 x 300 pixels) also leads to the detection of undetected objects.
No objects were found on the left: original square with 100 pixels side. On the right, a bus is detected: an enlarged square up to 300 x 300 pixels.
Another interesting transformation is the removal of the white grid over the image using OpenCV tools: it is possible that the fire hydrant was not detected in the video for this reason (this class is present in the neural network).
On the left is the original image, and on the right is the image that was changed in the graphics editor: the grid is deleted, the cells are moved to each other.
Summary
With this article, I wanted to tell you that captcha is probably not the best protection against bots, and it is quite possible that in the near future there will be a need for new means of protection against automated systems.
The developed prototype, even being in an incomplete state, demonstrates that with the required classes in the neural network model and applying transformations over images, it is possible to achieve automation of a process that should not be automated.
Also, I would like to draw the attention of Google to the fact that in addition to the way to bypass captcha described in this article, there is also another way in which transcription is performedaudio sample. In my opinion, it is now necessary to take measures related to improving the quality of software products and algorithms against robots.
From the content and essence of the material, it may seem that I do not like Google and, in particular, reCAPTCHA, but this is far from the case, and if there is a next implementation, I will tell you why.
Developed and demonstrated in order to improve education and improve methods aimed at ensuring information security.
Thanks for attention.