About removing a trend from experimental data
When analyzing experimentally obtained stationary time series, as a rule, during preliminary preparation (preprocessing) of data, it becomes necessary to suppress the trend existing in them.
Here a “new” trend highlighting method will be proposed - simple, obvious and suitable for very complex types of trend.
A trend is usually understood as an ultra-low-frequency non-harmonic component that sharply violates the stationarity of the process. The most common cause of a trend in experimentally obtained data is the “zero drift” of the recording equipment. Data integration and some other types of processing can also cause a trend. The presence of a trend greatly distorts the results of subsequent data processing (spectral estimation, etc.), therefore, the removal of the trend is necessary. In some cases, the trend itself is a valuable source of information (for example, when analyzing long-term trends in economic or meteorological processes).
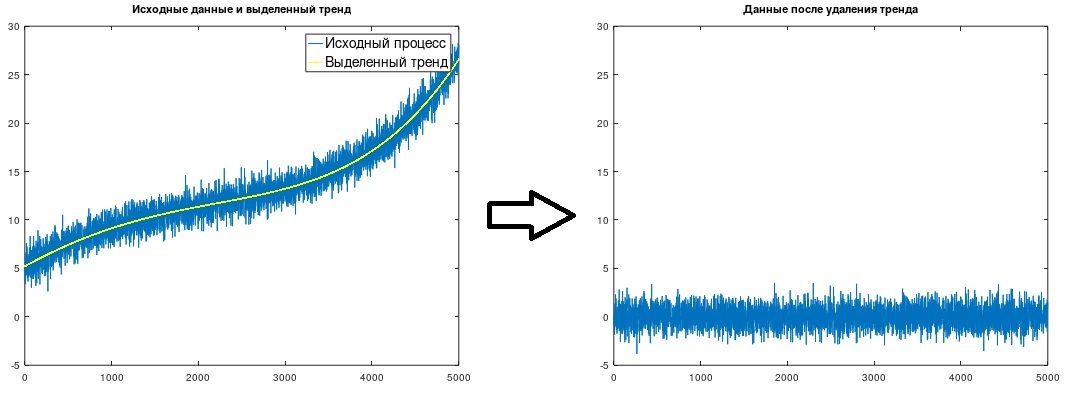
Fig. 1. Isolation and removal of a trend
Typically, a trend is modeled using linear or power (2nd or 3rd order) functions, the coefficients of which are calculated by multiplying the process by certain sequences and then applying fairly complex formulas derived using the least squares method. (see, for example, J. Bendat, A. Pirsol, “Applied Analysis of Random Data,” M., Mir, 1989.) The following is a slightly modified method, also based on the least squares method, which is very easy to understand and learn, and does not require either reference to directories, or independent complex symbolic calculations to obtain the necessary dependencies, while allowing you to model the trend with functions of any kind. This modified method is so simple and obvious (once mastered, the scripts can then be written from memory),
To identify a trend, an approximation of the initial process x [i], consisting of N + 1 samples, is performed using a small number k of trend functions u j [i]:
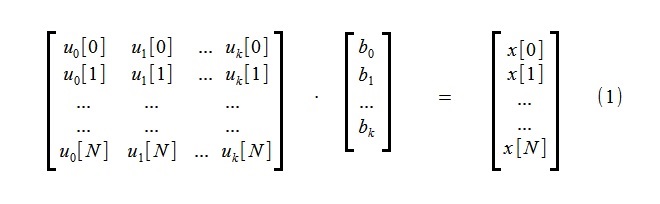
(Usually , power functions are chosen as functions u j [i],

but for this This method is absolutely unprincipled)
The system of linear algebraic equations (1) includes k unknown b j and N + 1 equations.
Accepting the notation: we

write more compactly

The application of the least squares method when searching for an approximate solution of an overdetermined system is written in matrix form as follows:

When writing a script: Naturally, there is no need to store the whole large matrix U, elements of the matrix UT U and vectors U T x can be "accumulated" step by step.
System (4) of k equations and k unknowns is solved by obvious methods — well, for example, we write it this way:

after which, using the found b j , we can construct the trend θ [i] in the form
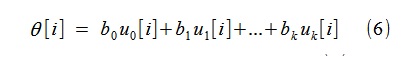
For example, we simulated a random process x [i] of the form
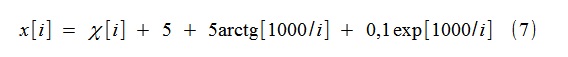
where χ [i] - Gaussian white noise with a single dispersion. The trend is modeled by functions of the type (2) (more precisely, (8)), up to and including 4th order (k = 4).
When using power functions for trend modeling, it should be noted that the matrix U TU (4) is theoretically always reversible due to the linear independence of these functions, however, for high orders of k (or very long realizations of N, which is less critical), certain of its elements can be very large in absolute value. At high orders of k, in case of computational difficulties, it is recommended to use lowering coefficients, for example, such (8):

(Δt = 1), which was done in the considered example. The trend shown in Fig. 1 is obtained.
After highlighting a trend, naturally, it should simply be subtracted from the source data.
Comment. Usually authoritative sources do not recommend working with trend models of the order above k = 2 (square parabola). Is this connected with the complexity of determining the "amplitude" coefficients b jby traditional methods, or with the exhaustion of the orders of machine variables mentioned above, or with the false attribution of the informative components of the process to the trend, it is not very clear. In the given example, the 4th order trend is highlighted as if it were quite plausible (though not much different from the 3rd order trend). For particularly difficult cases, sources recommend using a different method - low-pass filtering (not considered here).
Highlighting a trend, as shown above, the procedure is not so complicated, it allows you to either select and analyze “slow” trends, or, more often, helps to obtain high-quality data “output” - a centered stationary random process suitable for further analysis.
Here a “new” trend highlighting method will be proposed - simple, obvious and suitable for very complex types of trend.
A trend is usually understood as an ultra-low-frequency non-harmonic component that sharply violates the stationarity of the process. The most common cause of a trend in experimentally obtained data is the “zero drift” of the recording equipment. Data integration and some other types of processing can also cause a trend. The presence of a trend greatly distorts the results of subsequent data processing (spectral estimation, etc.), therefore, the removal of the trend is necessary. In some cases, the trend itself is a valuable source of information (for example, when analyzing long-term trends in economic or meteorological processes).
Fig. 1. Isolation and removal of a trend
Typically, a trend is modeled using linear or power (2nd or 3rd order) functions, the coefficients of which are calculated by multiplying the process by certain sequences and then applying fairly complex formulas derived using the least squares method. (see, for example, J. Bendat, A. Pirsol, “Applied Analysis of Random Data,” M., Mir, 1989.) The following is a slightly modified method, also based on the least squares method, which is very easy to understand and learn, and does not require either reference to directories, or independent complex symbolic calculations to obtain the necessary dependencies, while allowing you to model the trend with functions of any kind. This modified method is so simple and obvious (once mastered, the scripts can then be written from memory),
To identify a trend, an approximation of the initial process x [i], consisting of N + 1 samples, is performed using a small number k of trend functions u j [i]:
(Usually , power functions are chosen as functions u j [i],
but for this This method is absolutely unprincipled)
The system of linear algebraic equations (1) includes k unknown b j and N + 1 equations.
Accepting the notation: we
write more compactly
The application of the least squares method when searching for an approximate solution of an overdetermined system is written in matrix form as follows:
When writing a script: Naturally, there is no need to store the whole large matrix U, elements of the matrix UT U and vectors U T x can be "accumulated" step by step.
System (4) of k equations and k unknowns is solved by obvious methods — well, for example, we write it this way:
after which, using the found b j , we can construct the trend θ [i] in the form
For example, we simulated a random process x [i] of the form
where χ [i] - Gaussian white noise with a single dispersion. The trend is modeled by functions of the type (2) (more precisely, (8)), up to and including 4th order (k = 4).
When using power functions for trend modeling, it should be noted that the matrix U TU (4) is theoretically always reversible due to the linear independence of these functions, however, for high orders of k (or very long realizations of N, which is less critical), certain of its elements can be very large in absolute value. At high orders of k, in case of computational difficulties, it is recommended to use lowering coefficients, for example, such (8):
(Δt = 1), which was done in the considered example. The trend shown in Fig. 1 is obtained.
After highlighting a trend, naturally, it should simply be subtracted from the source data.
Comment. Usually authoritative sources do not recommend working with trend models of the order above k = 2 (square parabola). Is this connected with the complexity of determining the "amplitude" coefficients b jby traditional methods, or with the exhaustion of the orders of machine variables mentioned above, or with the false attribution of the informative components of the process to the trend, it is not very clear. In the given example, the 4th order trend is highlighted as if it were quite plausible (though not much different from the 3rd order trend). For particularly difficult cases, sources recommend using a different method - low-pass filtering (not considered here).
Highlighting a trend, as shown above, the procedure is not so complicated, it allows you to either select and analyze “slow” trends, or, more often, helps to obtain high-quality data “output” - a centered stationary random process suitable for further analysis.