Instant design
People learn architecture from old books that were written for Java. The books are good, but they provide a solution to the problems of that time with instruments of that time. Time has changed, C # is more similar to light Scala than Java, and there are few new good books.
In this article, we will examine the criteria for good code and bad code, how and what to measure. We will see an overview of typical tasks and approaches, we will analyze the pros and cons. At the end there will be recommendations and best practices for designing web applications.
This article is a transcript of my report from the DotNext 2018 Moscow conference. In addition to the text, there is a video and a link to the slides under the cut.

As you probably might have guessed, today I will talk about the development of enterprise software, namely, how to structure modern web applications:
We formulate the criteria. I really don't like it when talking about design is in the style of “my kung fu is stronger than your kung fu”. A business has, in principle, one specific criterion called money. Everyone knows that time is money, so these two components are most often the most important.

So, the criteria. In principle, the business most often asks us “as many features as possible per unit of time”, but with one caveat - these features should work. And the first step where it might break is code review. That is, it seems that the programmer said: "I will do it in three hours." Three hours passed, the review came into the code, and the team leader said: "Oh, no, redo it." There are three more - and how many iterations the code review has passed, so much you need to multiply three hours.
The next point is returns from the acceptance test stage. Same. If the feature does not work, then it is not done, these three hours stretch for a week, two - well, as usual. The last criterion is the number of regression and bugs, which nevertheless, despite testing and acceptance, went through production. This is also very bad. There is one problem with this criterion. It is difficult to track, because the connection between the fact that we push something into the repository and the fact that something broke after two weeks can be difficult to track. But, nevertheless, it is possible.
Once upon a time, when programmers were just starting to write programs, there was still no architecture, and everyone did everything they liked.

Therefore, we got such an architectural style. This is called “noodle code” here, they say “spaghetti code” abroad. Everything is connected with everything: we change something at point A - it breaks at point B, it is completely impossible to understand what is connected with what. Naturally, the programmers quickly realized that this would not work, and some structure had to be done, and decided that some layers would help us. Now, if you imagine that minced meat is code, and lasagna is such layers, here is an illustration of layered architecture. The minced meat remained minced, but now the minced meat from layer No. 1 can’t just go and talk to the minced meat from layer No. 2. We gave the code some form: even in the picture you can see that the climbing is more framed.
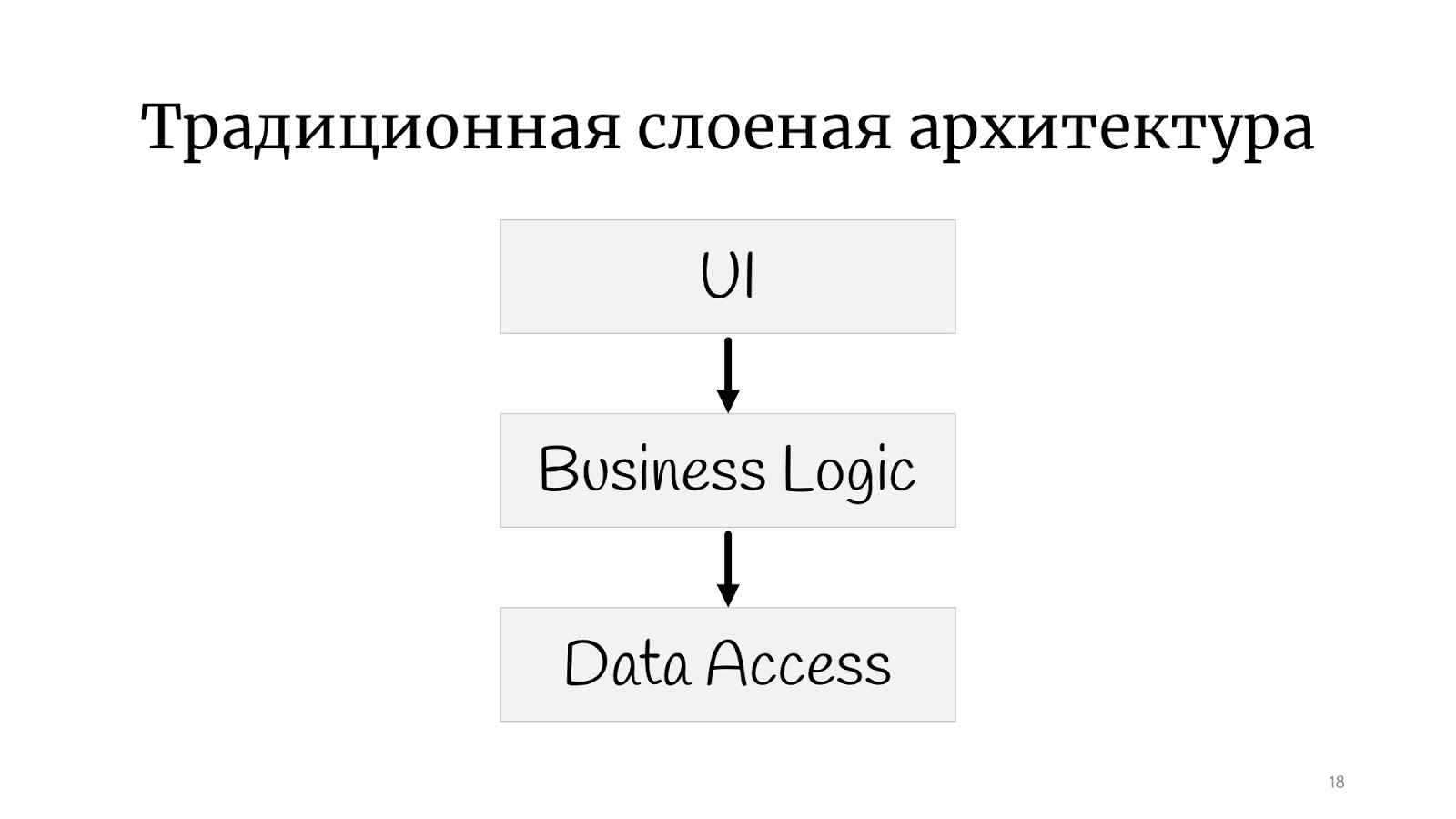
With classic layered architectureprobably everyone is familiar: there is a UI, there is a business logic and there is a Data Access layer. There are still all sorts of services, facades and layers, named for the architect who quit the company, there can be an unlimited number of them.

The next stage was the so-called onion architecture . It would seem that there is a huge difference: before that there was a small square, and here there were circles. It seems to be completely different.
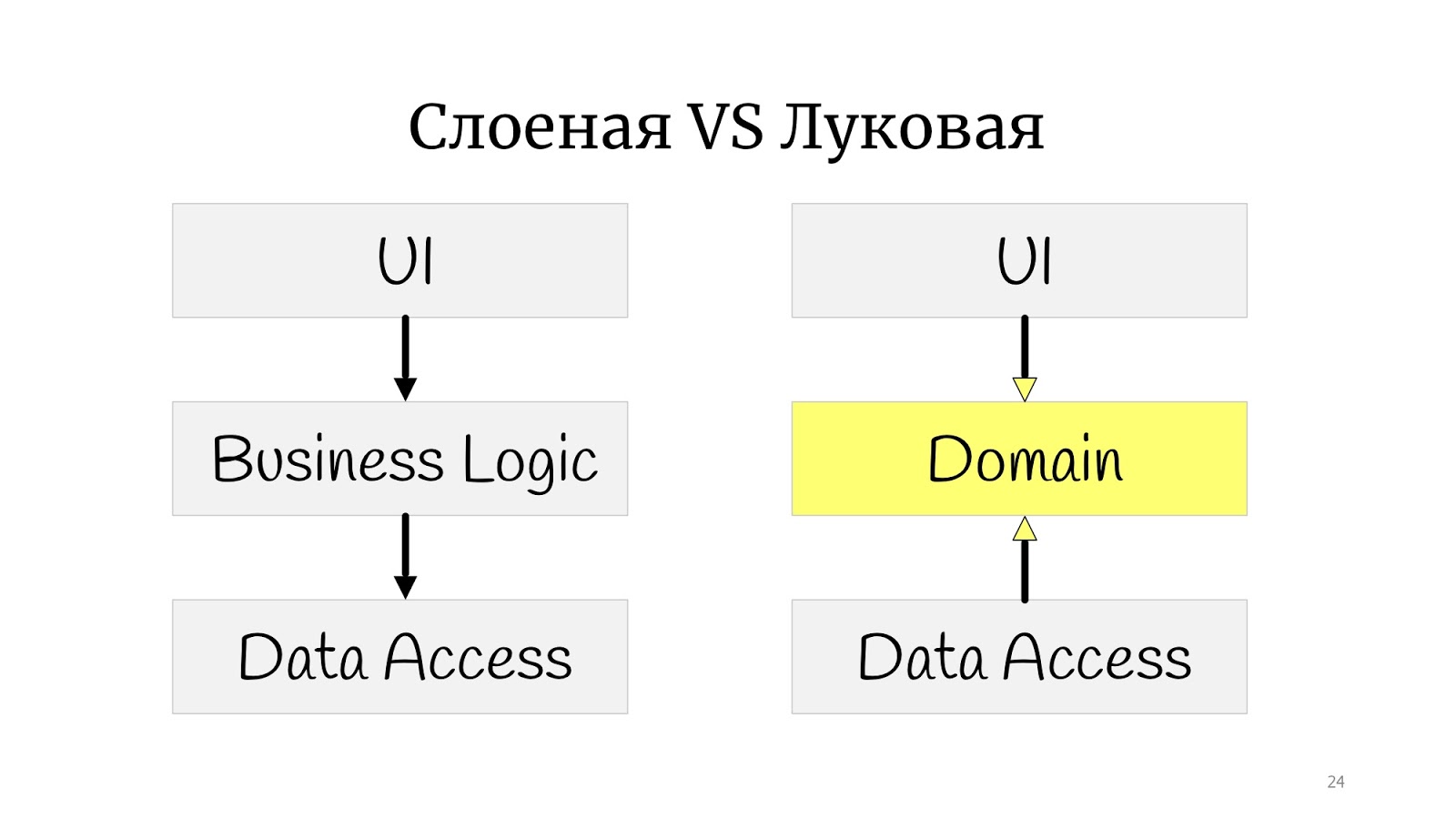
Not really. The whole difference is that somewhere at that time the principles of SOLID were formulated, and it turned out that in the classic onion there is a problem with dependency inversion, because the abstract domain code for some reason depends on the implementation, on Data Access, so we decided to deploy Data Access , and have Data Access depend on the domain.

Here I practiced drawing and drew the onion architecture, but not classically with the “rings”. I got something in between a polygon and circles. I did this to simply show that if you came across the words “onion”, “hexagonal” or “ports and adapters” - these are all one and the same. The point is that the domain is in the center, it is wrapped in services, they can be domain or application services, as you like. And the outside world in the form of UI, tests and infrastructure where DAL moved to - they communicate with the domain through this service layer.
Let's see how a simple use case would look like in such a paradigm - updating the user's email address.
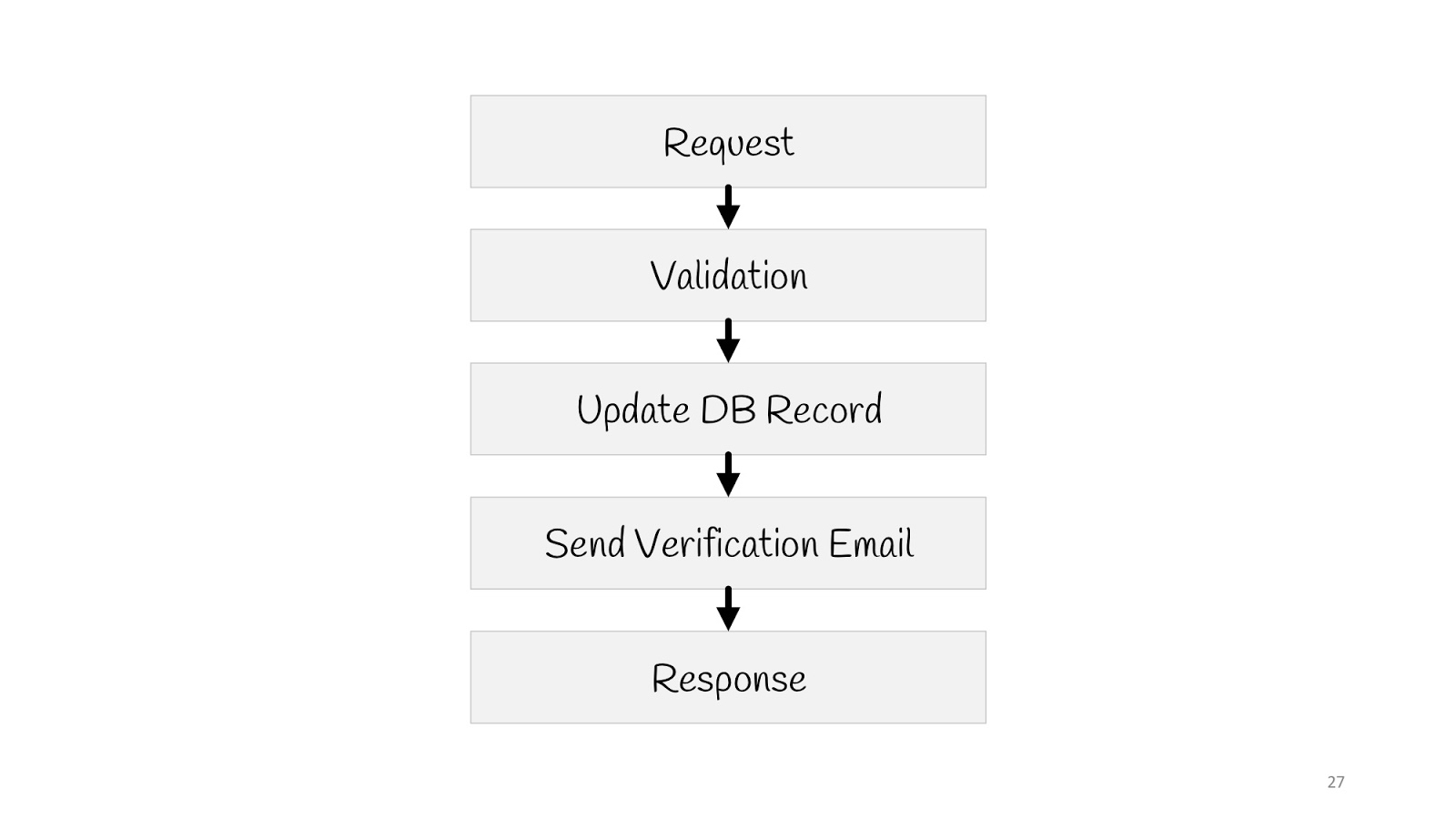
We need to send a request, validate, update the value in the database, send a notification to a new email: “Everything is in order, you changed your email, we know everything is fine”, and reply to the “200” browser - everything’s okay.
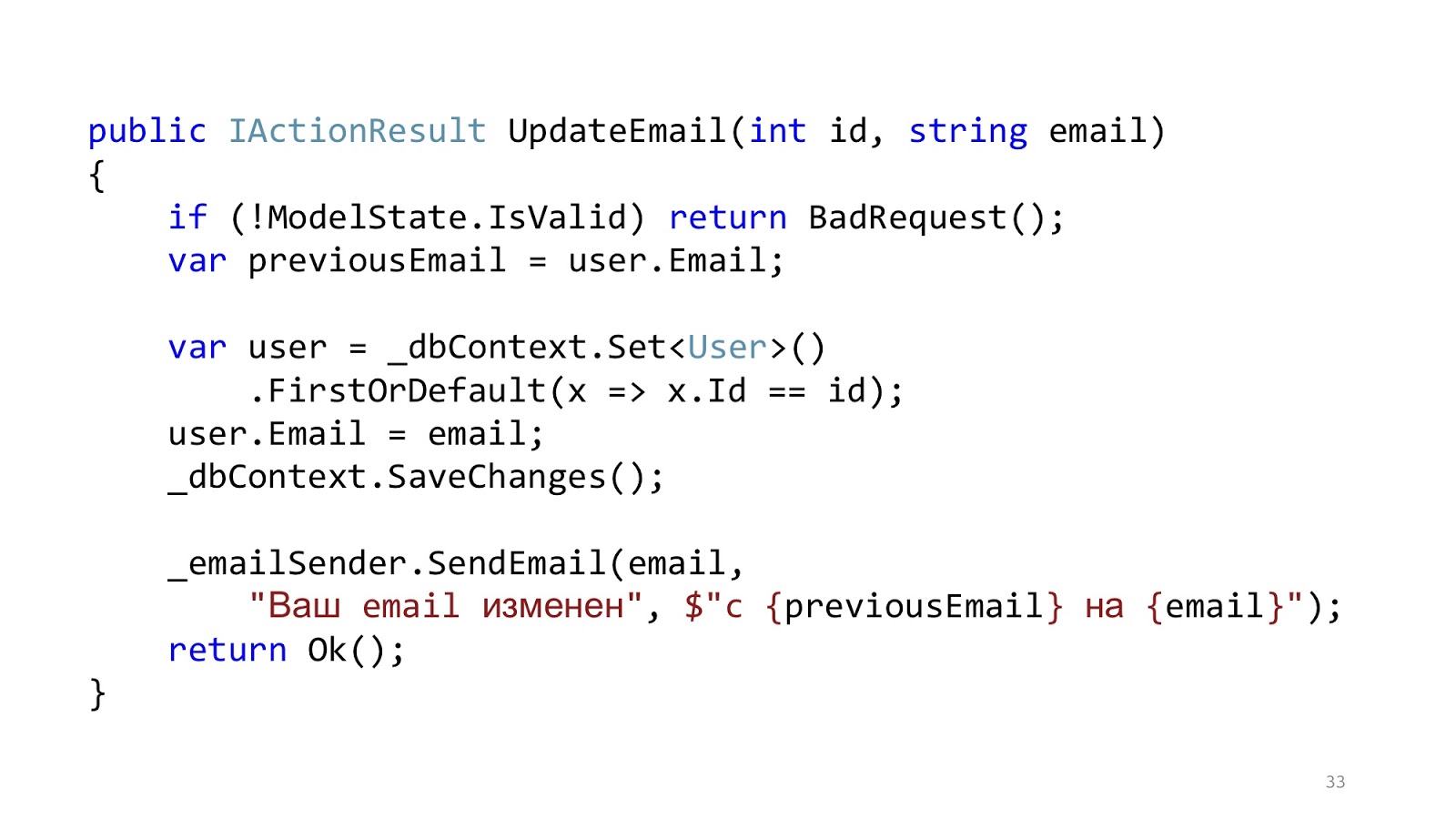
The code may look something like this. Here we have the standard ASP.NET MVC validation, there is ORM to read and update the data, and there is some kind of email-sender that sends a notification. It seems like everything is good, right? One caveat - in an ideal world.
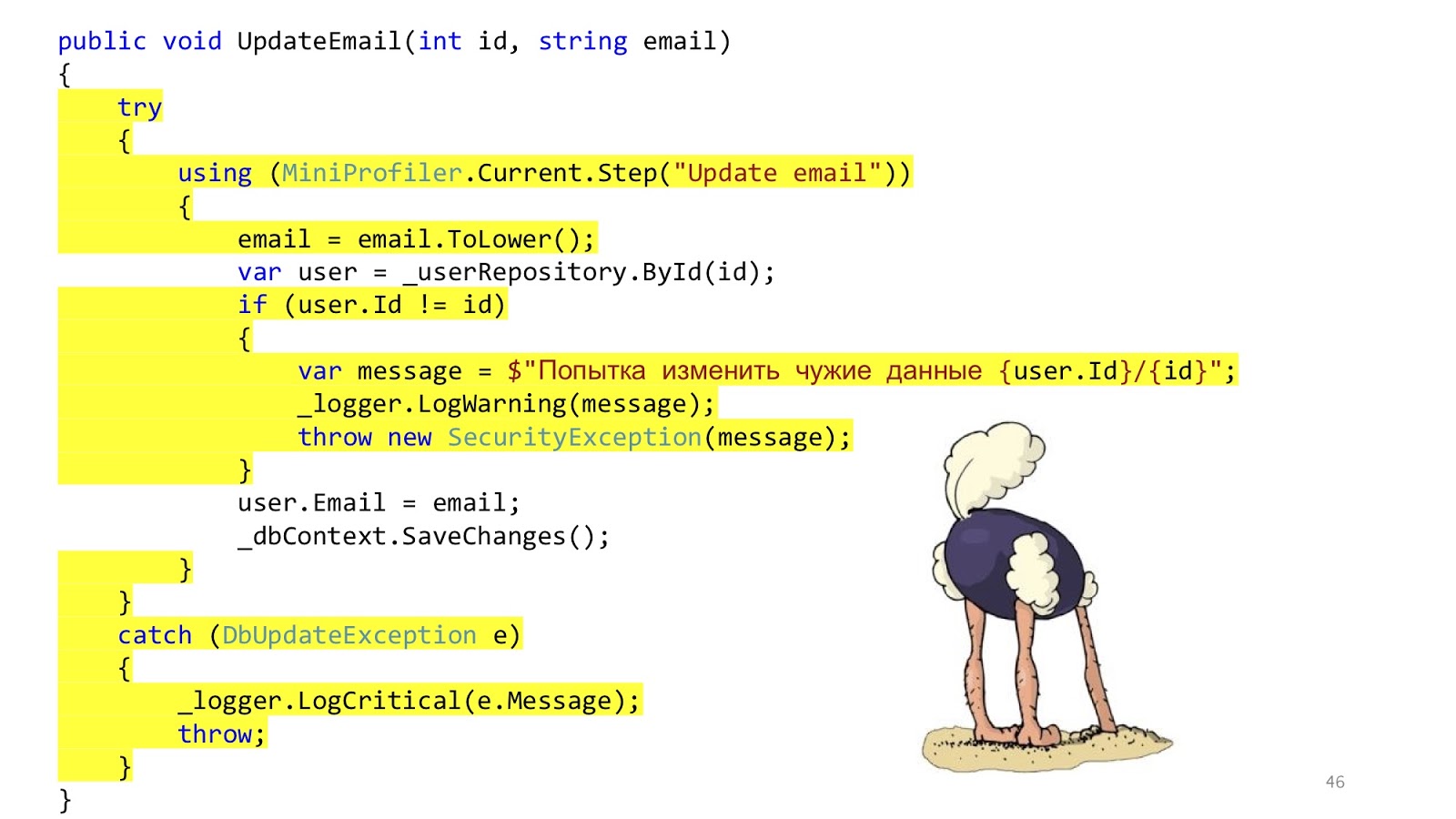
In the real world, the situation is slightly different. The point is to add authorization, error checking, formatting, logging and profiling. This all has nothing to do with our use case, but it should all be. And that little piece of code became big and scary: with a lot of nesting, with a lot of code, with the fact that it is hard to read, and most importantly, that there is more infrastructure code than domain code.

“Where are the services?” - you say. I wrote all the logic to the controllers. Of course, this is a problem, now I will add services, and everything will be fine.

We add services, and it really gets better, because instead of a big footcloth, we got one small beautiful line.
Got better? It has become! And now we can reuse this method in different controllers. The result is obvious. Let's look at the implementation of this method.
But here everything is not so good. This code is still here. We just transferred the same thing to the services. We decided not to solve the problem, but simply to disguise it and transfer it to another place. That's all.

In addition to this, some other questions arise. Should we do validation in the controller or here? Well, sort of like, in the controller. And if you need to go to the database and see that there is such an ID or that there is no other user with such an email? Hmm, well then in the service. But error handling here? This error handling is probably here, and the error handling that will respond to the browser in the controller. And the SaveChanges method, is it in the service or do you need to transfer it to the controller? It may be so and so, because if one service is called, it is more logical to call in the service, and if you have three methods of services in the controller that you need to call, then you need to call it outside of these services so that the transaction is one. These reflections suggest that perhaps the layers do not solve any problems.

And this idea occurred to more than one person. If you google, at least three of these respectable husbands write about the same thing. From top to bottom: Stephen .NET Junkie (unfortunately, I do not know his last name, because she does not appear anywhere on the Internet), the author of the Simple Injector IoC container . Next Jimmy Bogard is the author of AutoMapper . And down below is Scott Vlashin, author of F # for fun and profit .
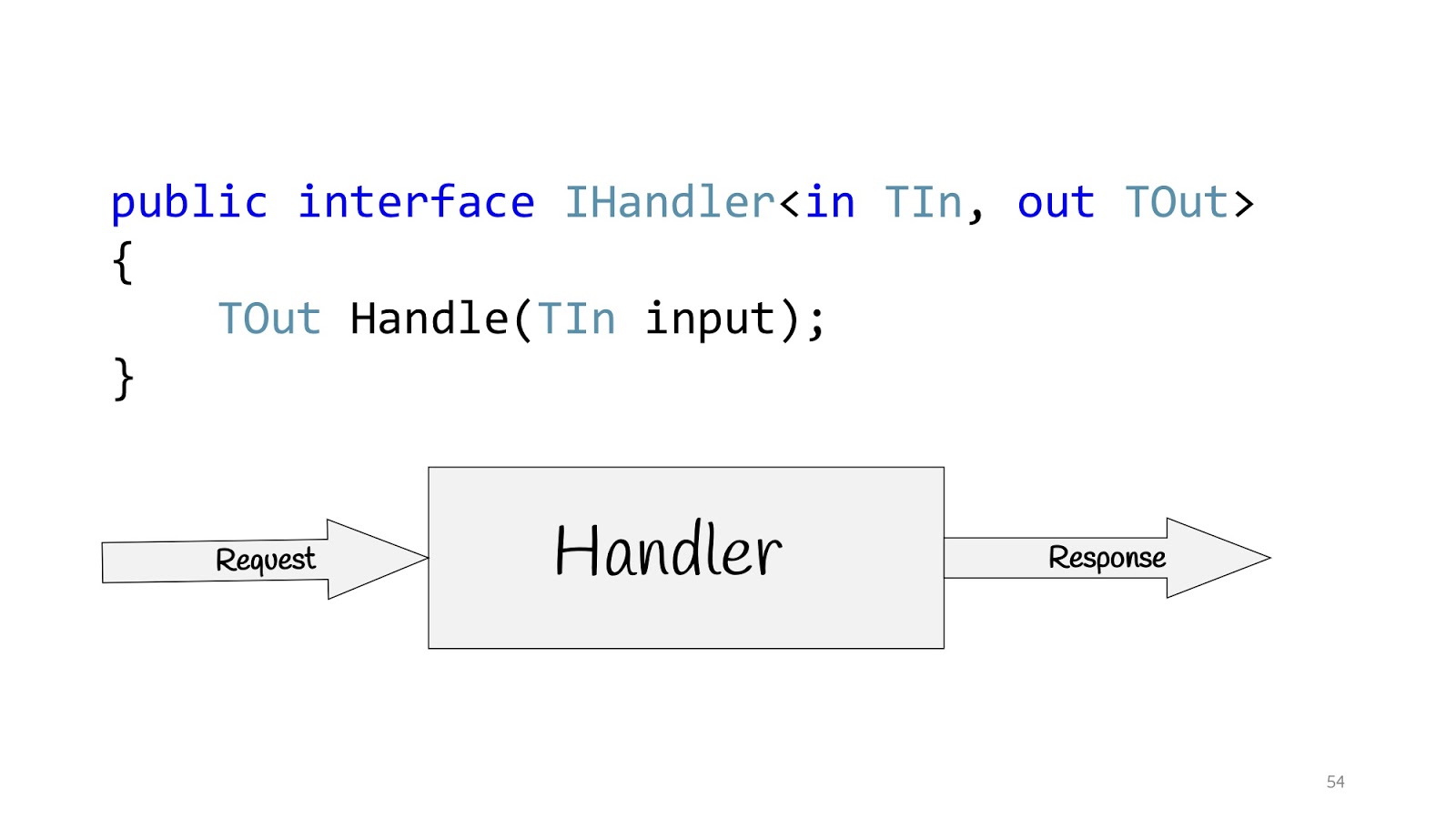
All these people are talking about the same thing and suggest building applications not on the basis of layers, but on the basis of use cases, that is, those requirements that the business is asking us for. Accordingly, the use case in C # can be determined using the IHandler interface. It has input values, there are output values and there is a method itself that actually executes this use case.

And inside this method there can be either a domain model, or some denormalized model for reading, maybe with Dapper or with Elastic Search, if you need to look for something, and maybe you have Legacy -system with stored procedures - no problem, as well as network requests - well, in general, anything you might need there. But if there are no layers, what to do?

To get started, let's get rid of UserService. We remove the method and create a class. And we’ll remove it, and we will remove it again. And then take and remove the class.

Let's think, are these classes equivalent or not? The GetUser class returns data and does not change anything on the server. This, for example, about the request "Give me the user ID." The UpdateEmail and BanUser classes return the result of the operation and change the state. For example, when we tell the server: “Please change the state, you need to change something.”
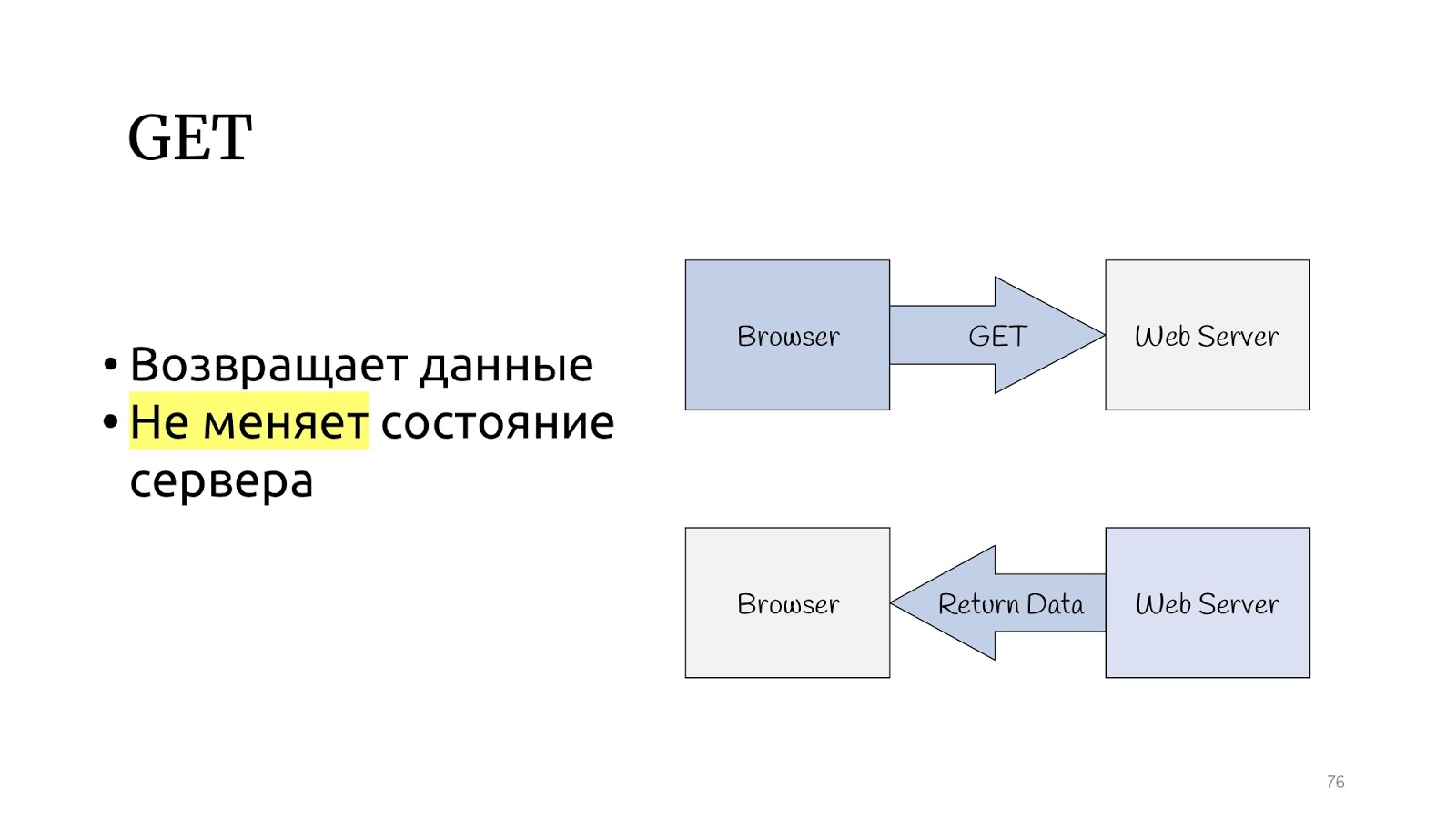
Let's look at the HTTP protocol. There is a GET method, which, according to the specification of the HTTP protocol, should return data and not change the state of the server.

And there are other methods that can change the status of the server and return the result of the operation.

The CQRS paradigm seems to be specifically designed for the HTTP protocol. Query are GET operations, and commands are PUT, POST, DELETE — no need to invent anything.
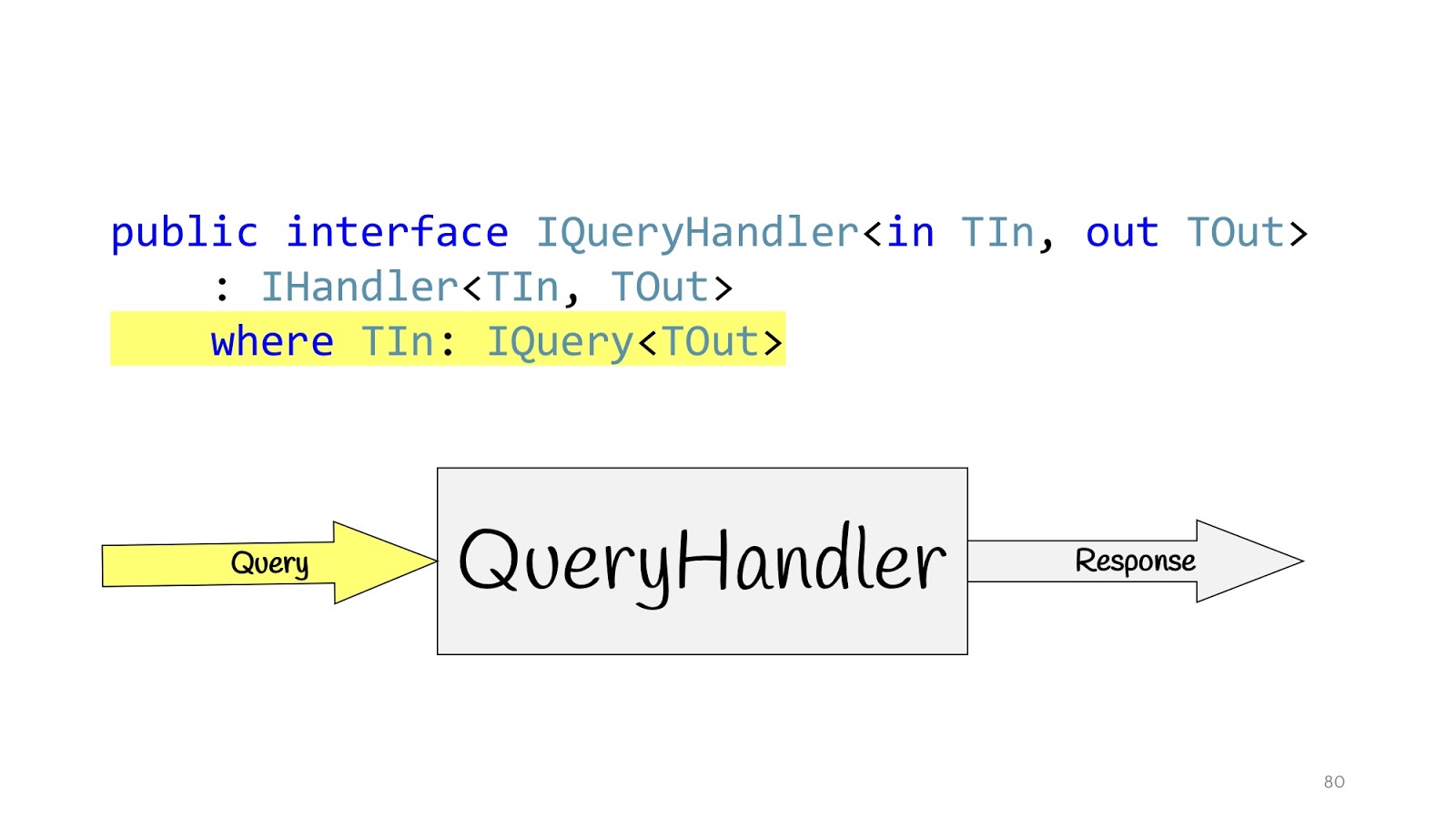
We redefine our Handler and define additional interfaces. IQueryHandler, which differs only in that we hung constraint that the type of input values is IQuery. IQuery is a marker interface, there is nothing in it except this generic. We need the generic in order to put constraint in QueryHandler, and now, declaring QueryHandler, we cannot pass there not Query, but passing the Query object there, we know its return value. This is convenient if you have only one interface, so you do not have to look for their implementation in the code, and again so as not to mess up. You write IQueryHandler, write an implementation there, and in TOut you cannot substitute another type of return value. It just does not compile. Thus, you can immediately see which input values correspond to which input data.

The situation is completely similar for CommandHandler with one exception: this generic is needed for one more trick, which we will see a little further.
Handlers, we announced, what is their implementation?
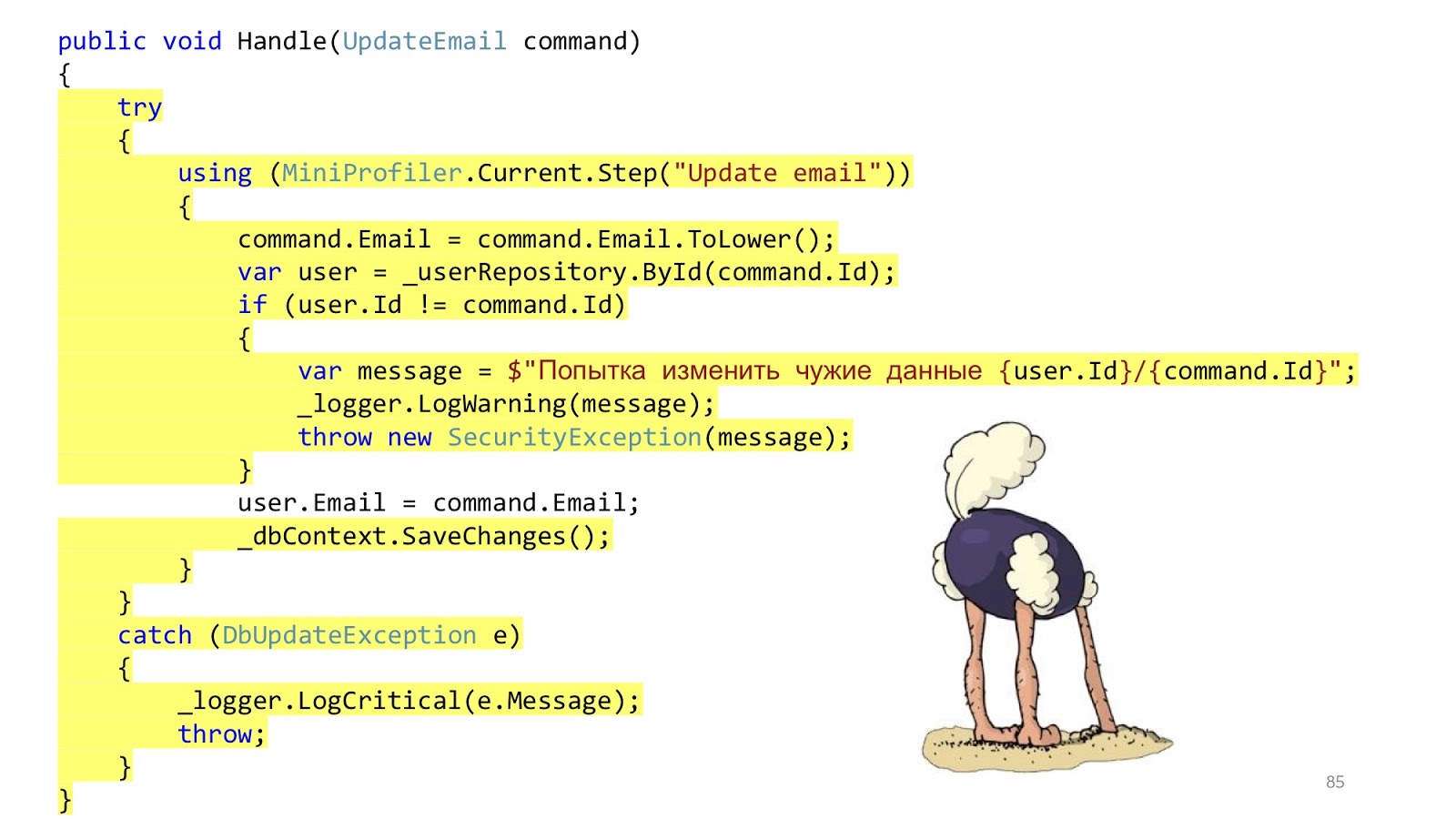
Is there any problem, yes? Something seems to have failed.
But it didn’t help, because we are still in the middle of the road, we need to finalize a little more, and this time we need to use the decorator pattern , namely its wonderful layout feature. The decorator can be wrapped in a decorator, wrapped in a decorator, wrapped in a decorator - continue until you get bored.
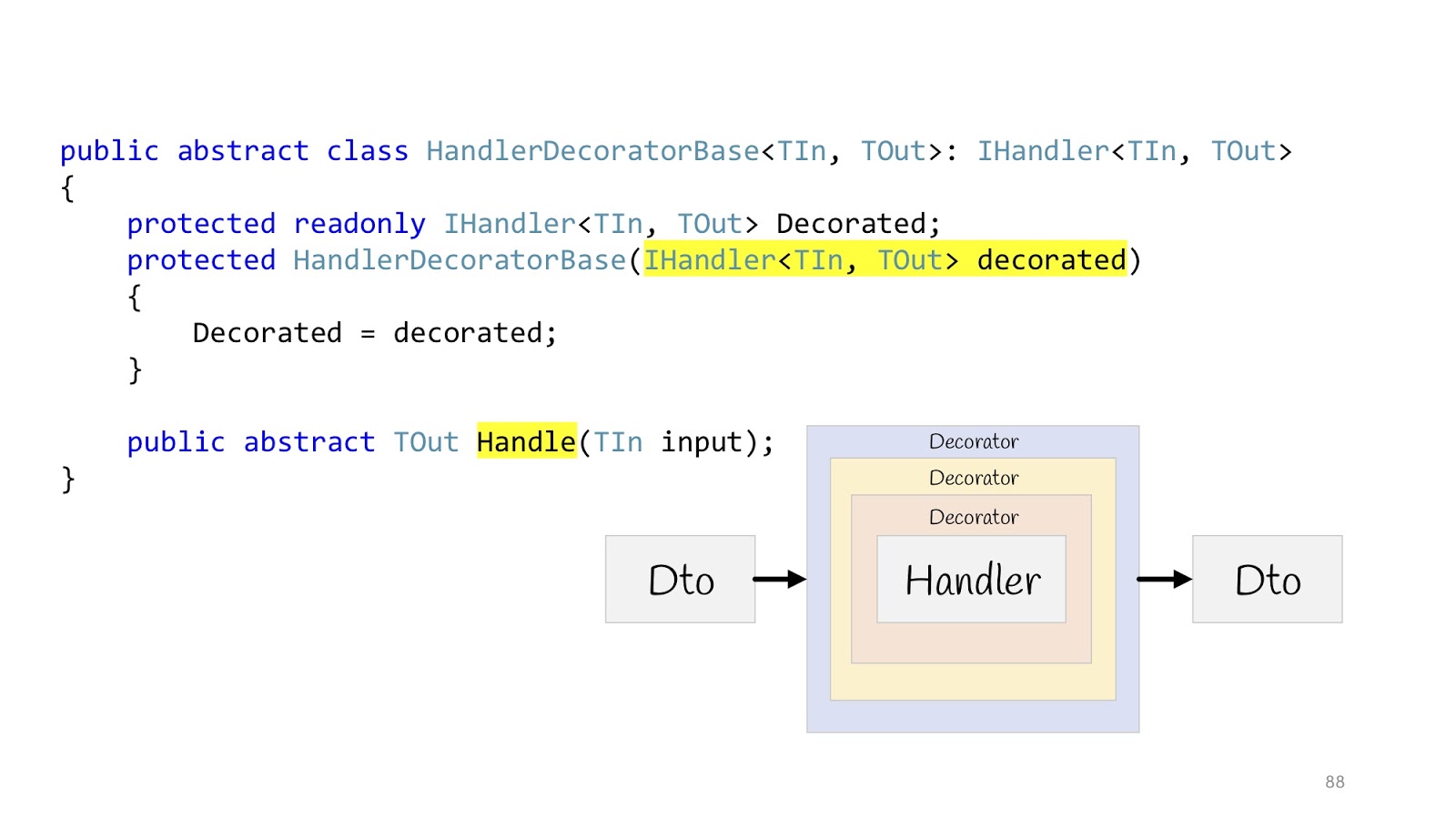
Then everything will look like this: there is an input Dto, it enters the first decorator, the second, third, then we go into the Handler and also exit it, go through all the decorators and return Dto in the browser. We declare an abstract base class in order to later inherit, the body of Handler is passed to the constructor, and we declare the abstract Handle method, in which additional decorator logic will be hung.
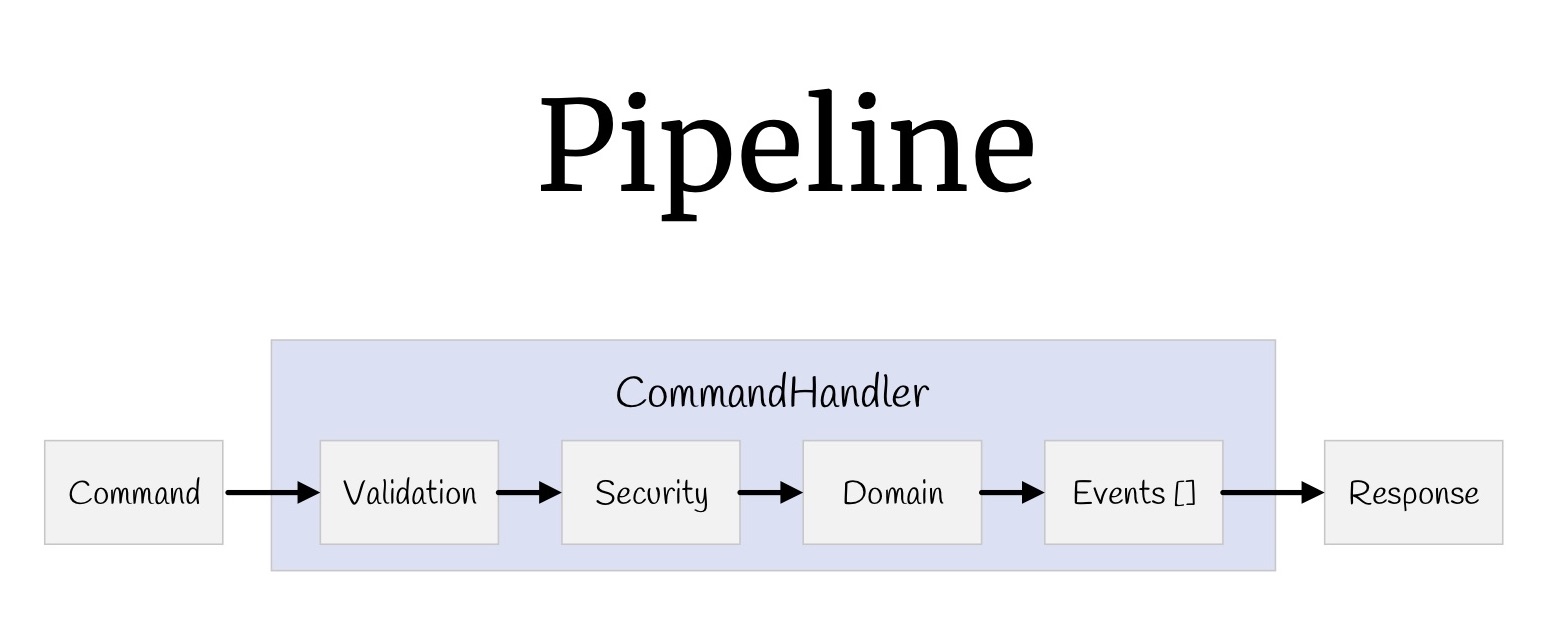
Now with the help of decorators you can build a whole pipeline. Let's start with the teams. What did we have? Input values, validation, verification of access rights, the logic itself, some events that occur as a result of this logic, and return values.

Let's start with validation. We declare a decorator. IEnumerable from type T validators comes into the constructor of this decorator. We execute them all, check if the validation fails and the type of the return value is this , then we can return it, because the types match. And if it's some other Hander, well then you have to throw an Exception, because there is no result here, the type of another return value.
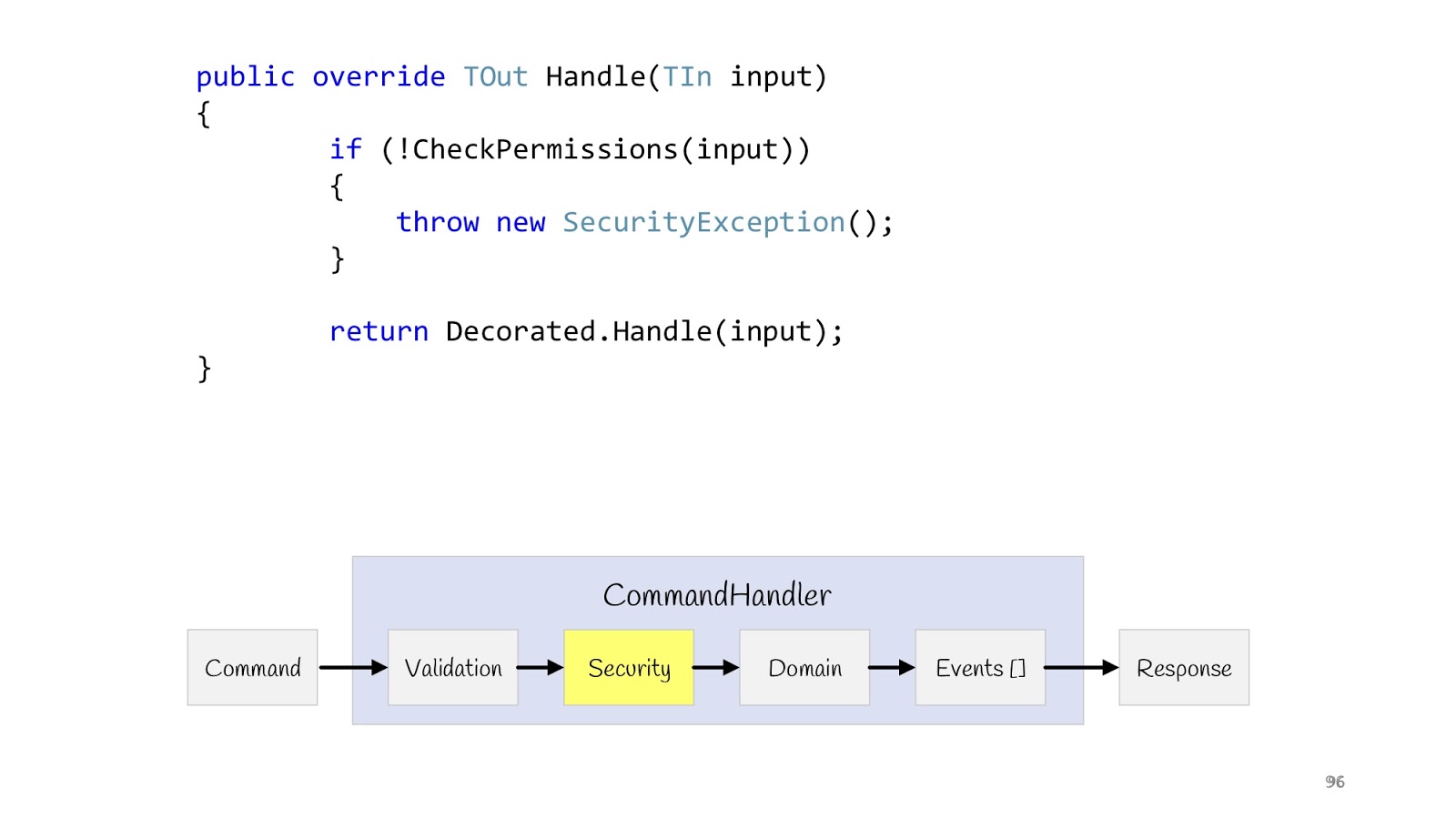
The next step is Security. We also declare the decorator, make the CheckPermission method, and verify. If suddenly something went wrong, everything, we don’t continue. Now, after we have completed all the checks and are sure that everything is fine, we can fulfill our logic.
Before showing the implementation of the logic, I want to start a little bit earlier, namely with the input values that come there.
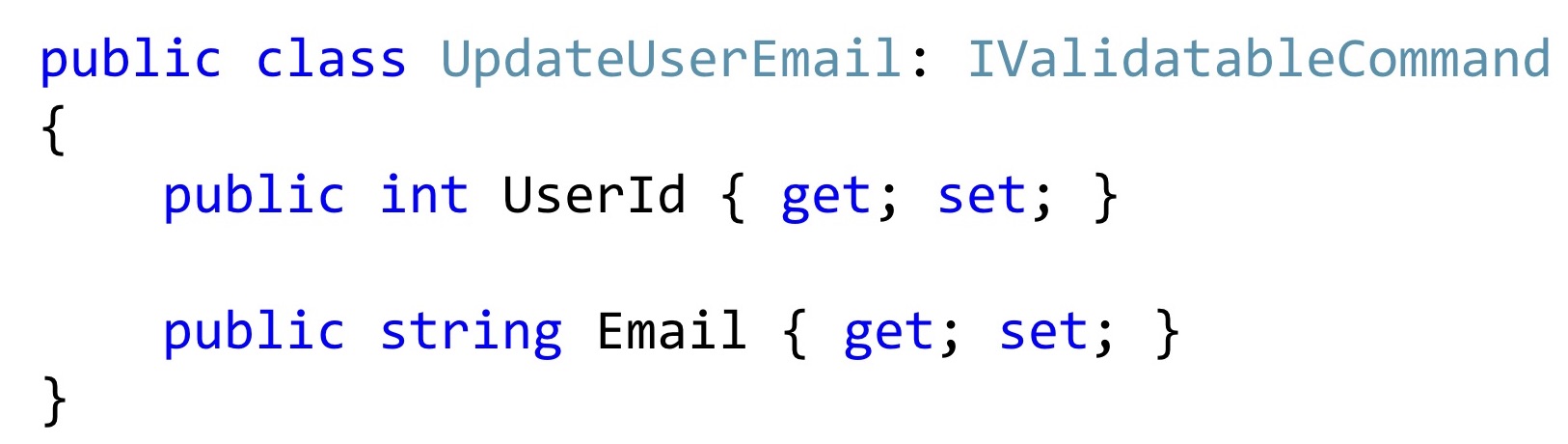
Now, if we single out such a class, then most often it may look something like this. At least the code that I see in everyday work.
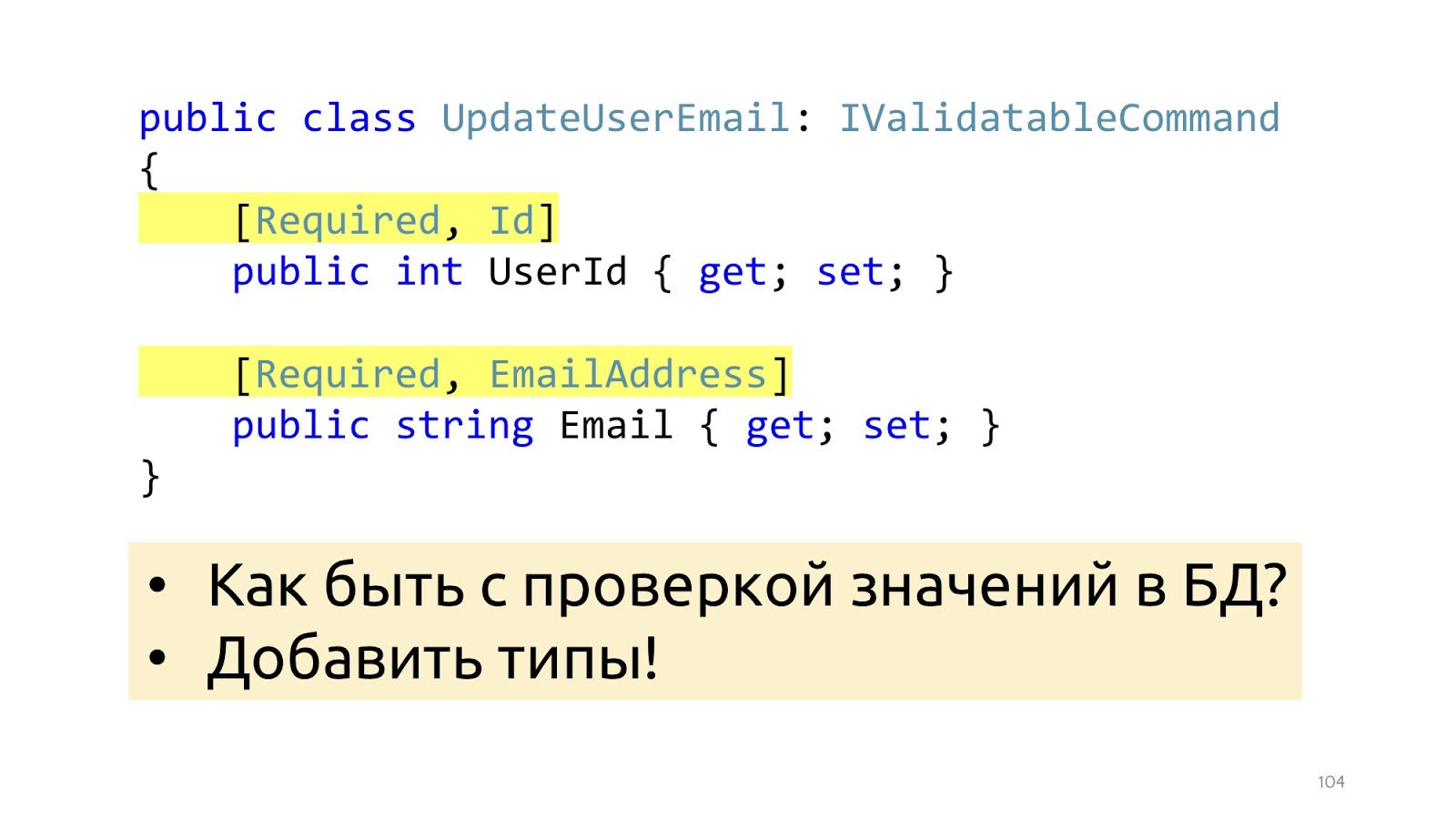
In order for validation to work, we add some attributes here that tell you what kind of validation it is. This will help from the point of view of the data structure, but will not help with such validation as checking values in the database. It’s just EmailAddress, it’s not clear how, where to check how to use these attributes in order to go to the database. Instead of attributes, you can go to special types, then this problem will be solved.

Instead of primitive
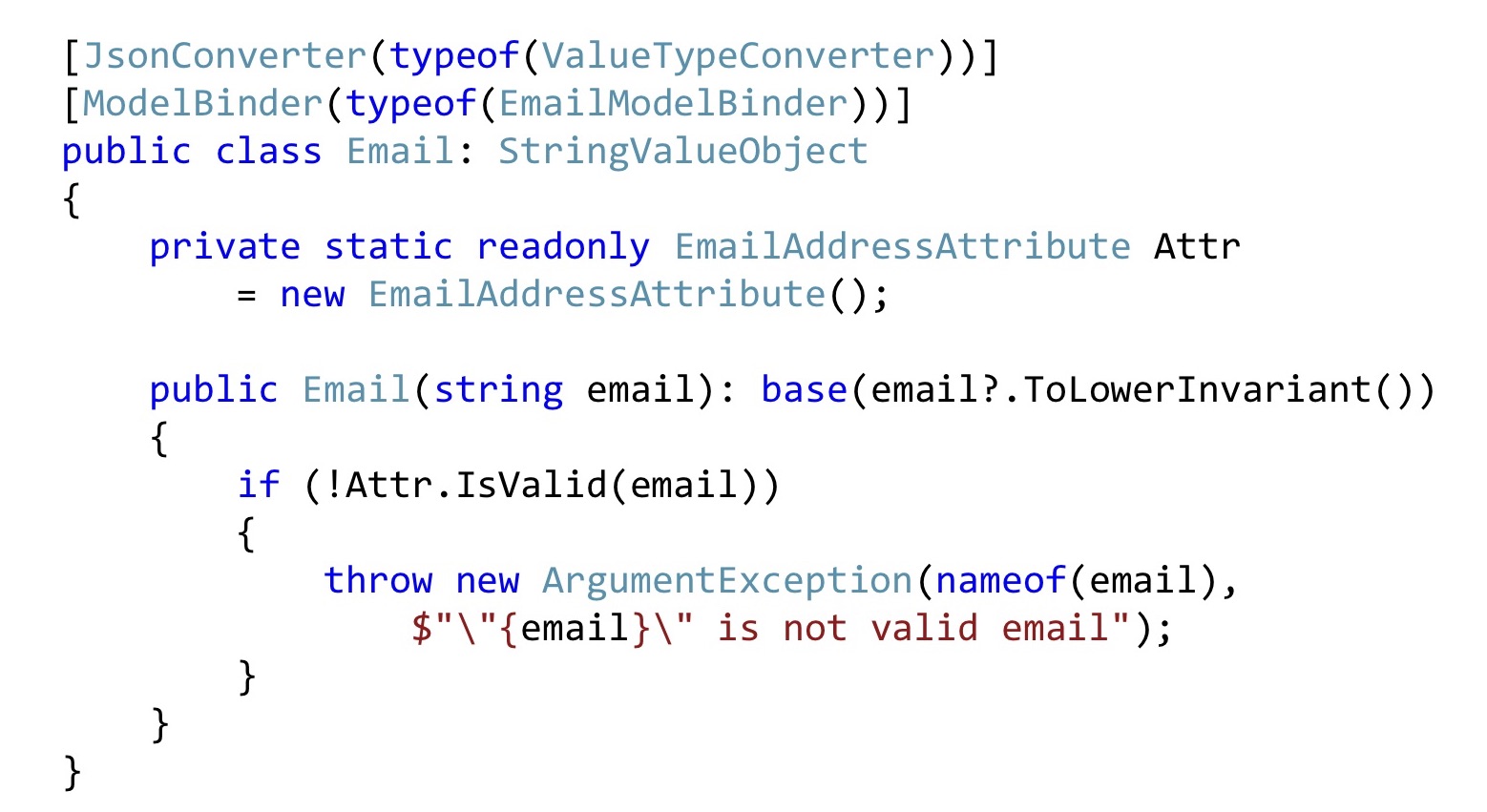
We do the same with Email. Convert all emails to the bottom line so that everything looks the same for us. Next, we take the Email attribute, declare it as static for compatibility with ASP.NET validation, and here we simply call it. That is, this can also be done. In order for the ASP.NET infrastructure to catch all this, you will have to slightly modify the serialization and / or ModelBinding. There is not much code there, it is relatively simple, so I won’t stop there.
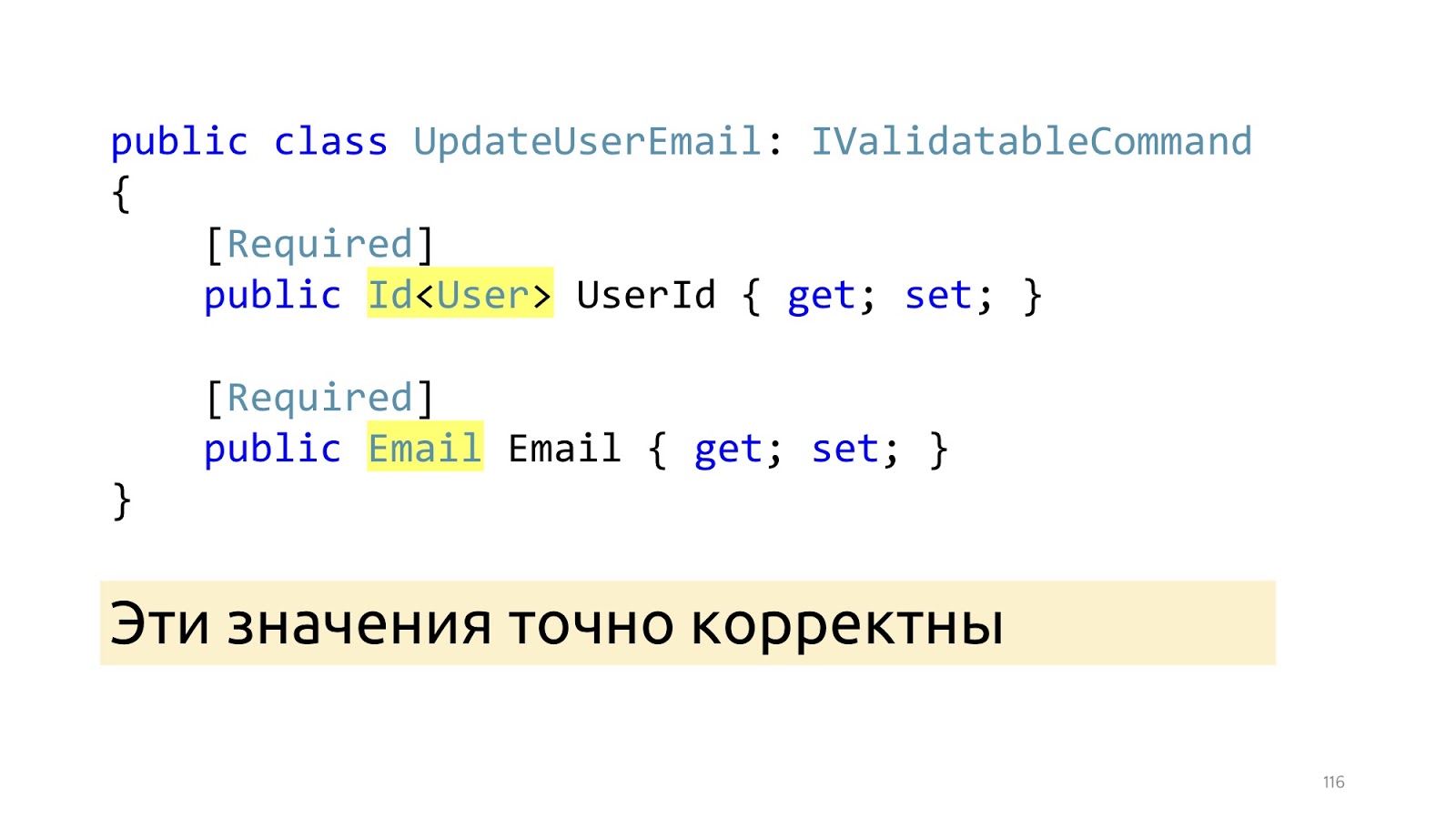
After these changes, instead of primitive types, specialized types appear here: Id and Email. And after these ModelBinder and the updated deserializer worked out, we know for sure that these values are correct, including that such values are in the database. “Invariants”

The next point I would like to dwell on is the state of invariants in the class, because the anemic model is often used, in which there is simply a class, many setter getters, it is completely unclear how they should work together. We work with complex business logic, so it is important for us that the code is self-documenting. Instead, it is better to declare the real constructor along with empty for ORM, it can be declared protected so that programmers in their application code could not call it, and ORM could. Here we pass not the primitive type, but the Email type, it is already correctly correct, if it is null, we still throw an Exception. You can use some Fody, PostSharp, but C # 8 is coming soon. Accordingly, there will be a Non-nullable reference type, and it is better to wait for its support in the language. The next moment, if we want to change the name and surname, most likely we want to change them together, so there must be an appropriate public method that changes them together.

In this public method, we also verify that the length of these lines matches what we use in the database. And if something is wrong, then stop execution. Here I use the same trick. I declare a special attribute and just call it in the application code.
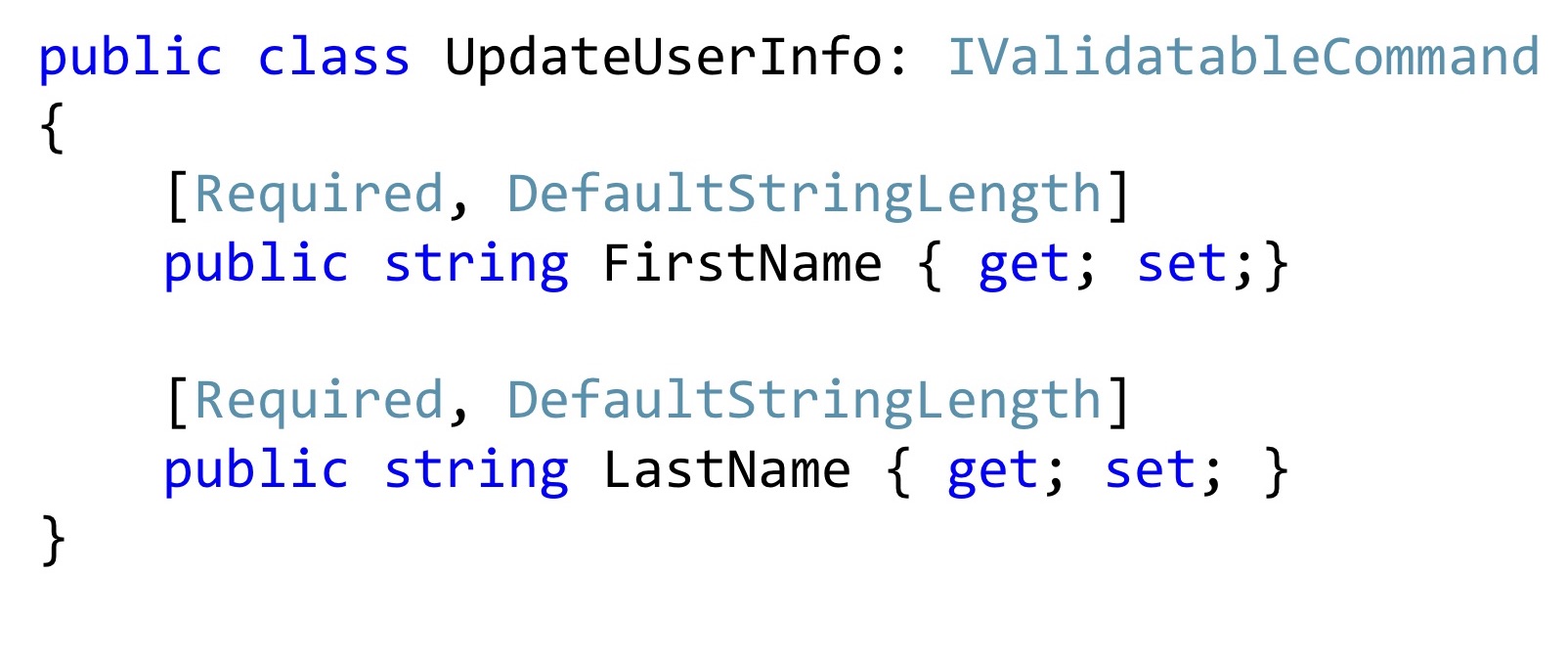
Moreover, such attributes can be reused in Dto. Now, if I want to change the name and surname, I may have such a change command. Is it worth adding a special constructor here? It seems to be worth it. It will become better, no one will change these values, will not break them, they will be exactly right.

Actually not really. The fact is that Dto are not really objects at all. This is such a dictionary into which we put deserialized data. That is, they pretend to be objects, of course, but they have only one responsibility - it is to be serialized and deserialized. If we try to fight this structure, we’ll start to announce some ModelBinders with designers, to do something like that is incredibly tiring, and, most importantly, it will break with new releases of new frameworks. All this was well described by Mark Simon in the article “On the borders of the program are not object-oriented” , if it’s interesting, it’s better to read his post, there it is described in detail.

In short, we have a dirty external world, we put checks at the input, convert it to our clean model, and then transfer it all back to serialization, to the browser, again to the dirty external world.
After all these changes have been made, how will the Hander look like here?

I wrote two lines here in order to make it more convenient to read, but in general it can be written in one. The data is exactly correct, because we have a type system, there is validation, that is, the data are reinforced concrete, you do not need to check them again. Such a user also exists, there is no other user with such a busy email, everything can be done. However, there is still no call to the SaveChanges method, there is no notification and there are no logs and profilers, right? We move on.
Domain events.

Probably the first time this concept was popularized by Udi Dahan in his post “Domain Events - Salvation” . There, he suggests simply declaring a static class with the Raise method and throwing such events. A little later, Jimmy Bogard proposed a better implementation, it is called "A better domain events pattern" .
I will be showing the serialization of Bogard with one small change, but an important one. Instead of throwing events, we can declare some list, and in those places where some kind of reaction should take place, directly inside the entity to save these events. In this case, this getter

Further, at the moment when we will call the SaveChanges method, we take ChangeTracker, see if there are any entities that implement the interface, whether they have domain events. And if there is, let's take all these domain events and send them to some dispatcher who knows what to do with them.
The implementation of this dispatcher is a topic for another discussion, there are some difficulties with multiple dispatch in C #, but this is also done. With this approach, there is another non-obvious advantage. Now, if we have two developers, one can write code that changes this email, and the other can do a notification module. They are absolutely not connected with each other, they write different code, they are connected only at the level of this domain event of one Dto class. The first developer simply throws this class away at some point, the second one responds to it and knows that it needs to be sent by email, SMS, push notifications to the phone and all the other million notifications, taking into account any user preferences that usually happen.
Here is the smallest, but important point. Jimmy's article uses an overload of the SaveChanges method, and it's best not to. And it’s better to do it in the decorator, because if we overload the SaveChanges method and we needed dbContext in Handler, we will get circular dependencies. You can work with this, but the solutions are a little less convenient and a little less beautiful. Therefore, if the pipeline is built on decorators, then I see no reason to do it differently.

The nesting of the code remained, but in the initial example we had first using MiniProfiler, then try catch, then if. Total there were three levels of nesting, now each this level of nesting is in its own decorator. And inside the decorator, which is responsible for profiling, we have only one level of nesting, the code is read perfectly. In addition, it is clear that in these decorators there is only one responsibility. If the decorator is responsible for logging, then he will only log, if for profiling, respectively, only profile, everything else is in other places.
After the entire pipeline has worked, we can only take Dto and send it to the browser further, serialize JSON.
But one more small thing, such a thing that is sometimes forgotten: at every stage, an Exception can happen here, and actually you need to somehow handle them.

I cannot but mention Scott Vlashin and his report “Railway oriented programming” here again . Why? The original report is entirely devoted to working with errors in the F # language, how to organize flow a little differently and why such an approach may be preferable to using Exception'ov. In F #, this really works very well, because F # is a functional language, and Scott uses the functionality of a functional language.

Since, probably, most of you still write in C #, if you write an analogue in C # , then this approach will look something like this. Instead of throwing exceptions, we declare a Result class that has a successful branch and an unsuccessful branch. Accordingly, two designers. A class can be in only one state. This class is a special case of union type, discriminated union from F #, but rewritten in C #, because there is no built-in support in C #.

Instead of declaring public getters that someone might not check for null in the code, Pattern Matching is used. Again, in F # it would be a built-in Pattern Matching language, in C # we have to write a separate method into which we will pass one function that knows what to do with the successful result of the operation, how to convert it further down the chain, and that with an error. That is, no matter which branch worked for us, we must cast this to a single returned result. In F #, this all works very well, because there is a functional composition, well, and everything else that I have already listed. In .NET, this works a little worse, because as soon as you have more than one Result,

The easiest way to combine them is to use LINQ , because in fact LINQ works not only with IEnumerable, if you redefine the SelectMany and Select methods in the right way, then the C # compiler will see that you can use LINQ syntax for these types. In general, it turns out tracing paper with Haskell do-notation or with the same Computation Expressions in F #. How should this be read? Here we have three results of the operation, and if everything is fine there in all three cases, then take these results r1 + r2 + r3 and add it. The type of the resulting value will also be Result, but the new Result, which we declare in Select. In general, this is even a working approach, if not one but.

For all other developers, as soon as you start writing such code in C #, you start to look something like this. “These are bad scary Exceptions, don't write them! They are evil! Better write code that no one understands and cannot debug! ”

C # is not F #, it is somewhat different, there are no different concepts on the basis of which this is done, and when we try to pull an owl on the globe, it turns out, to put it mildly, unusual.

Instead, you can use the built-in normal tools that are documented, that everyone knows and that will not cause cognitive dissonance among developers. ASP.NET has a global Handler Exception.

We know that if there are any problems with validation, you need to return the code 400 or 422 (Unprocessable Entity). If there is a problem with authentication and authorization, there are 401 and 403. If something went wrong, then something went wrong. And if something went wrong and you want to tell the user exactly what, define your Exception type, say that it is IHasUserMessage, declare a Message getter in this interface and just check: if this interface is implemented, then you can take a message from Exception and pass it in JSON to the user. If this interface is not implemented, it means that there is some kind of system error, and we simply tell users that something went wrong, we are already doing it, we all know - well, as usual.
We conclude this with the teams and look at what we have in the Read-stack. As for the request, validation, response directly - this is about the same thing, we will not stop separately. There may still be an additional cache, but in general there are no big problems with the cache either.
Let's look better at a security check. There may also be the same Security decorator, which checks whether this request can be made or not:

But there is another case when we display more than one record, and list, and for some users we need to display a complete list (for example, some super administrators), and for other users we have to display limited lists, for third ones - limited in a different way, well, and as is often the case in corporate applications, access rights can be extremely sophisticated, so you need to be sure that these lists are not crawl through ie that these users are not intended.
The problem is solved quite simply. We can redefine the interface (IPermissionFilter) into which the original queryable arrives and queryable returns. The difference is that to the queryable that returns, we have already imposed additional conditions where, checked the current user and said: “Here, return only that data to that user ...” - and then all your logic related to permissions . Again, if you have two programmers, one programmer goes to write permissions, he knows that he needs to write just a lot of permissionFilters and check that they work correctly for all entities. And other programmers do not know anything about permission, in their list the correct data simply always passes, that's all. Because they receive at the input no longer the original queryable from dbContext, but limited to filters. Such permissionFilter also has a layout property, we can add and apply all permissionFilters. As a result, we get the resulting permissionFilter, which will narrow the data selection to the maximum, taking into account all the conditions that are suitable for this entity.

Why not do it with ORM built-in tools, for example, Global Filters in an entity framework? Again, in order not to make any cyclic dependencies for yourself and not drag any additional story about your business layer into context.
It remains to look at the reading model. The CQRS paradigm does not use the domain model in the reading stack, instead, we just immediately create the Dto that the browser needs at the moment.

If we write in C #, then most likely we are using LINQ, if there aren’t just any monstrous performance requirements, and if there are any, then you may not have a corporate application. In general, this problem can be solved once and for all with such a LinqQueryHandler. Here's a pretty scary constraint on the generic: this is Query, which returns a list of projections, and it can still filter these projections and sort these projections. She also works only with some types of entities and knows how to convert these entities to projections and return the list of such projections in the form of Dto to the browser.

The implementation of the Handle method can be quite simple. Just in case, check if this TQuery filter implements for the original entity. Further we do a projection, it is queryable extension AutoMapper'a. If someone still does not know, AutoMapper can build projections in LINQ, that is, those that will build the Select method, and not map it in memory.
Then we apply filtering, sorting and display it all in the browser. How exactly all this is done, I told in St. Petersburg on DotNext, this is another whole report, it is already available for free and decrypted in the Habré , you can listen, see, read how to write filtering, sorting and projection using expression'ov for anything once and then reused.
Not all expressions are equally
We move on. One topic that I did not cover in the last DotNext is problems with translation in SQL. Because in Select, of course, we can write everything we want, but the queryable providers will not understand everything.
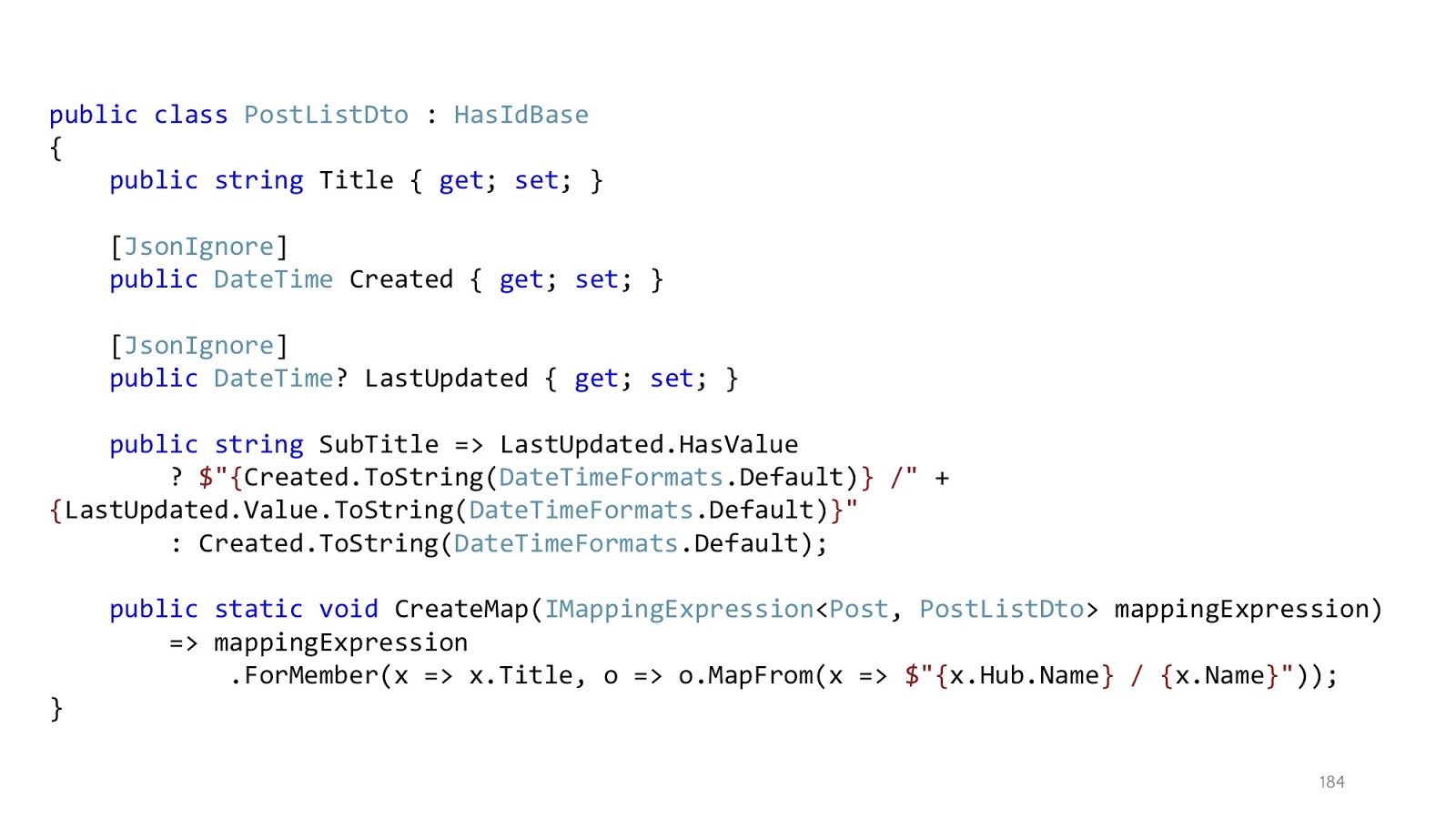
Since we are talking about Habr, let's use Habr as an example. We have a list of posts, they have a Title, and we want to enter Title as the name of the hub, and then the name of the post itself. There are no problems with this projection, everything is being transformed. But if we want to bring out such a SubTitle when we last updated the article, when we created it, and we also want to use some custom format for these dates, the queryable provider will not be able to cope with this. He does not know what kind of custom format is declared in our code.
And there is one pretty simple trick that solves this problem. Instead of trying to project, we project to primitives. That is, we pull out everything we need, first. Next, we mark this all with “JsonIgnore” so that the serializer ignores these fields. And declare the method we need in Dto. That is, instead of doing this in the projection, we do it already in memory. When the serializer starts converting the class to JSON, it will see that it should skip Created and LastUpdated, and SubTitle is a public property, you need to take it. Then he will take it, call this method, and then in memory we will appap what we need, that which we could not transform into projections. In most cases, such a simple trick solves the problem that some expressions cannot be converted.

Let's look at both stacks together. They, in general, are quite similar and differ only in what steps we have taken. Depending on which pipeline, we can use different decorators. We’ll cache the requests — and in teams, for example, we don’t need it. Similarly, we want to invoke commands in SaveChanges, but in Query we do not need to call SaveChanges. When the pipelines are assembled and we understand that there are a limited number of them, such decorators can be taken and designed as separate libraries, put on NuGet, and then simply connected as reusable modules.
Because in the code of decorators there is nothing about the domain. You can write the domain separately, and transfer the infrastructure to some other developer, who will issue these modules to you, and you will use them. If you are familiar with Brooks, for example, you probably know that the easiest way to write code is to buy it. Accordingly, a great option, if you can take and say: “We need these decorators,” and buy them. No liability.
If decorators are so great, how do you register them?

It’s necessary to register them somehow like this. Not quite pretty.

Although no one does it with his hands, of course, it all happens through containers. You can take Jimmy Bogard's MediatR, in which all this already exists and there is documentation. All I talked about is the same decorators - the truth is, he has it called pipeline behavior in MediatR. But the meaning is the same, Request / Response methods, RequestHandlers and methods for registering these decorators are also defined there. Or you can take Simple Injector, whose decorator is just a piece of the framework.

And now back to this slide, remember, I said that we will need this generic again, where is TIn: ICommand.

Here in Simple Injector, registration of decorators based on constraints is additionally supported. That is, you can, where you register the decorator, indicate that if the decorator is with constraint, then it will be applied only to those Handlers that have such constraint. Accordingly, if we have ICommand constraint, we can create a SaveChanges decorator with ICommand constraint as well, and Simple Injector will automatically understand that these two constraints are the same and will only apply this decorator to the corresponding Handler. Well, it turns out another little beautiful feature that allows you to build just such application logic on the type system, which should be applied to what.
What to use? Simple Injector or MeriatR - in principle, all felt-tip pens are different in taste and color, in addition, in Autofac, in my opinion, there are also decorators and in other containers it can also be, I just don’t follow, I don’t know. If interested, take a look.
Throughout my current report, another word is missing to shout “bingo”.
Even two words, namely “Clean architecture”. It was impossible to mention a lot of smart people and forget about Uncle Bob Martin.

For some reason, modern web applications love to talk about the fact that they are MVC, how wonderful they are, what their structure is.

Instead, Bob Martin, and many others, including Angular, by the way, already offers to structure the application based on what modules there are in the system, that is, what functionality. Instead of saying: “I am an MVC application”, we can say: “I have the following Features, that is, such functionality: I have account management, I have Blog and I have some Import, that is some three big modules. ”
Perhaps, of course, it is more convenient for programmers to know that this is an MVC application, we like that there are some technical details, details. But for management MVC is absolutely unimportant. But such a structure, when a person understands how many features he has, is much more important for business. That is, this structure corresponds to the functionality of the system.


I promised, after all, not to crush the authorities and the fact that kung fu is stronger than another kung fu, so I will give other advantages of this design.
Firstly, the code in this case is added, not edited. If we have different modules and we want to add a new module, this is a new folder. It doesn’t work out that there is some work with users in module A and module B, so the programmers Vasya and Petya both went to fix the User Service, then they sent pull requests, and then suddenly there was a conflict because they both changed this User Service as deemed necessary. And even without the fact that they changed signatures or something like that, they just simply changed lines and types somewhere. Some commonplace technical things can lead to the fact that at the stage of the review code, a conflict may occur and this will delay the release cycle.
The next moment. This organization of the code encourages us to think better about what contexts there are in the application and how to divide it correctly. That is, if we divide correctly, then ideally we should not create any unnecessary dependencies between modules where they do not exist. Accordingly, where we are, we will find out what they are at the stage of separation by modules, because we will see that for some reason this module depends on another. And if it so happened that our modules are completely independent (and this can also be done, but with some reservations), then the feature can be deleted simply by clicking on the “Delete” button: we delete the folder and it is no longer in the program, and that’s it. Pretty comfortable.
In practice, we had to carry out such actions two or two times - the word "refactoring" is probably not quite right when you throw out all the code and rewrite it again, it's more like a rewrite. And if the code was written in the usual puff style, this would not have happened: all these services related to different modules, we could not have thrown out, because there would have been unnecessary dependencies. And so we just threw out some jammed modules and then rewrote when our hands reached. I will not go into details about why I had to do this, but sometimes it happens. That is, this happened not because there were bad and stupid programmers, but because of the circumstances.
And the last point: this separation simplifies the work of numerical methods and communication. When I say “numerical methods”, I again curtsey toward management: we begin to count the number of features, the number of returns with a review code, the number of returns from testing, and that’s all. Remember, when I formulated the criteria, I noticed that it is rather difficult to track the connection between regression, bugs that reached production, and why it happened. And when we begin to put the code in this way, it becomes a little easier. Because if some kind of pull request comes up to edit existing modules, option number one - requirements have changed, option number two - something went wrong, a bug crawled into production. And hereafter, we already look at the history of changes in VCS precisely for this module: why did he crawl into production, what commits were there? If these commits are in this module, they can still be sorted out somehow, and if they are simply spread across all our layers, it becomes much more difficult to sort out.

Despite this, everything I talked about is not without flaws. Namely: it does not work out of the box. That is, if you just take the project template, you have to add infrastructure code. Ideally, write your own project template, in which everything you need is already connected, there will be a project structure. But it probably takes no less than a working day if you do it from scratch. Well, once, for example. When I say “working day”, in the sense that everything is ready for us, you only need to collect the dependencies. It took me several years to build the dependencies - with how my idea of how to write code changed.
This illustrates the second point of this slide: write this infrastructure code, redefine something, add something. That is, more serious requirements are placed on him in terms of quality. In some application code, you can write as it is customary for you, because if a bug comes, you will correct it. But if you start to publish some libraries for free access and they have jambs, and someone connected them, and this is not one project, but this is tied to you, for example, the work of the entire company or the clients project, it becomes very more difficult. The risks of this case are higher.

We summarize. If you want to organize the work with the code as follows, you will need to declare here such IHandler as the main building block. He will perform operations.
Further we extend this IHandler with two interfaces ICommandHandler and IQueryHandler and we say that these are holistic abstractions. A very cool-sounding phrase means simply that it is performed in a single transaction. That is, if there is a CommandHandler, there will be no other CommandHandler inside it, it acts throughout this request.
Why is that? This eliminates the flame of what Query can use there in commands, commands in Query - that’s all. If you need reusable code that you have to use both there and there, then you declare Hander, if you declare CommandHandler or QueryHandler, it means some specific use case, this should not be reused.
Decorators are an excellent tool for sharing this whole logic, sharing responsibilities, responsibilities between different classes, in order to register them, you will need infrastructure: either a container or a framework.
The type system and invariants are much better than validation. Because it allows you to learn about errors at the compilation stage, and not in runtime. But not at the borders, because at the borders the programs are not object-oriented.
And we are still waiting for C # 8 to have a nullable reference type appear and our type system to become better. Not as cool, of course, as in functional programming languages, but better.
Events can be tracked as part of a transaction using ChangeTracker’s ORM.
And Exceptions are a normal option for errors if you don't write in F #, if we write in C #. There is an option in which you still need to abandon these exceptions, there may be some kind of performance limitation, for example. But if you have performance limitations due to the fact that you have too many Exceptions, you probably do not need LINQ there, and everything else, and everything that I told you is not quite for you, you we need stored procedures, Dapper, and something else, and maybe not even .NET.
And if we don’t have such terrible performance requirements, then LINQ, automatic projections, permissions are all excellent. Yes, it really slows down, but it slows down for a few milliseconds, that is, it is less than network delays to your database. Well, structuring the application by feature rather than by layer is a more preferable method.
I mentioned many people and ideas in the report. Here are the links:

The last slide is a bit of recommended literature. On the left, we have Eric Evans’s incorruptible. The second book is Scott Vlashin’s book “Domain Modeling Made Functional”, it is about F #, but even if you never want to write in F #, I still recommend reading it because it is very well structured, the thoughts are very clearly stated, just with the point of view of common sense and the fact that two plus two equals four. That is, ideas can also be transferred to C #, but with one exception, so as not to look like on that slide about Exception.
And the last, perhaps unobvious book, is Entity Framework Core In Action. I didn’t post it here because it is about the Entity Framework, but because there is a whole section on how to use all kinds of DDD options with ORM, that is, where ORM starts to interfere with us in terms of implementing DDD and how to get around it.
In this article, we will examine the criteria for good code and bad code, how and what to measure. We will see an overview of typical tasks and approaches, we will analyze the pros and cons. At the end there will be recommendations and best practices for designing web applications.
This article is a transcript of my report from the DotNext 2018 Moscow conference. In addition to the text, there is a video and a link to the slides under the cut.
Slides and report page on the site .Briefly about me: I am from Kazan, I work for High Tech Group. We are developing software for business. Recently, I have been teaching a course at the Kazan Federal University called Corporate Software Development. From time to time I still write articles on Habr about engineering practices, about the development of enterprise software.
As you probably might have guessed, today I will talk about the development of enterprise software, namely, how to structure modern web applications:
- the criteria
- a brief history of the development of architectural thought (what was, what has become, what problems are);
- overview of the flaws of classic puff architecture
- decision
- step-by-step analysis of implementation without diving into details
- results.
Criteria
We formulate the criteria. I really don't like it when talking about design is in the style of “my kung fu is stronger than your kung fu”. A business has, in principle, one specific criterion called money. Everyone knows that time is money, so these two components are most often the most important.
So, the criteria. In principle, the business most often asks us “as many features as possible per unit of time”, but with one caveat - these features should work. And the first step where it might break is code review. That is, it seems that the programmer said: "I will do it in three hours." Three hours passed, the review came into the code, and the team leader said: "Oh, no, redo it." There are three more - and how many iterations the code review has passed, so much you need to multiply three hours.
The next point is returns from the acceptance test stage. Same. If the feature does not work, then it is not done, these three hours stretch for a week, two - well, as usual. The last criterion is the number of regression and bugs, which nevertheless, despite testing and acceptance, went through production. This is also very bad. There is one problem with this criterion. It is difficult to track, because the connection between the fact that we push something into the repository and the fact that something broke after two weeks can be difficult to track. But, nevertheless, it is possible.
Architecture development
Once upon a time, when programmers were just starting to write programs, there was still no architecture, and everyone did everything they liked.
Therefore, we got such an architectural style. This is called “noodle code” here, they say “spaghetti code” abroad. Everything is connected with everything: we change something at point A - it breaks at point B, it is completely impossible to understand what is connected with what. Naturally, the programmers quickly realized that this would not work, and some structure had to be done, and decided that some layers would help us. Now, if you imagine that minced meat is code, and lasagna is such layers, here is an illustration of layered architecture. The minced meat remained minced, but now the minced meat from layer No. 1 can’t just go and talk to the minced meat from layer No. 2. We gave the code some form: even in the picture you can see that the climbing is more framed.
With classic layered architectureprobably everyone is familiar: there is a UI, there is a business logic and there is a Data Access layer. There are still all sorts of services, facades and layers, named for the architect who quit the company, there can be an unlimited number of them.
The next stage was the so-called onion architecture . It would seem that there is a huge difference: before that there was a small square, and here there were circles. It seems to be completely different.
Not really. The whole difference is that somewhere at that time the principles of SOLID were formulated, and it turned out that in the classic onion there is a problem with dependency inversion, because the abstract domain code for some reason depends on the implementation, on Data Access, so we decided to deploy Data Access , and have Data Access depend on the domain.
Here I practiced drawing and drew the onion architecture, but not classically with the “rings”. I got something in between a polygon and circles. I did this to simply show that if you came across the words “onion”, “hexagonal” or “ports and adapters” - these are all one and the same. The point is that the domain is in the center, it is wrapped in services, they can be domain or application services, as you like. And the outside world in the form of UI, tests and infrastructure where DAL moved to - they communicate with the domain through this service layer.
A simple example. Email update
Let's see how a simple use case would look like in such a paradigm - updating the user's email address.
We need to send a request, validate, update the value in the database, send a notification to a new email: “Everything is in order, you changed your email, we know everything is fine”, and reply to the “200” browser - everything’s okay.
The code may look something like this. Here we have the standard ASP.NET MVC validation, there is ORM to read and update the data, and there is some kind of email-sender that sends a notification. It seems like everything is good, right? One caveat - in an ideal world.
In the real world, the situation is slightly different. The point is to add authorization, error checking, formatting, logging and profiling. This all has nothing to do with our use case, but it should all be. And that little piece of code became big and scary: with a lot of nesting, with a lot of code, with the fact that it is hard to read, and most importantly, that there is more infrastructure code than domain code.
“Where are the services?” - you say. I wrote all the logic to the controllers. Of course, this is a problem, now I will add services, and everything will be fine.
We add services, and it really gets better, because instead of a big footcloth, we got one small beautiful line.
Got better? It has become! And now we can reuse this method in different controllers. The result is obvious. Let's look at the implementation of this method.
But here everything is not so good. This code is still here. We just transferred the same thing to the services. We decided not to solve the problem, but simply to disguise it and transfer it to another place. That's all.
In addition to this, some other questions arise. Should we do validation in the controller or here? Well, sort of like, in the controller. And if you need to go to the database and see that there is such an ID or that there is no other user with such an email? Hmm, well then in the service. But error handling here? This error handling is probably here, and the error handling that will respond to the browser in the controller. And the SaveChanges method, is it in the service or do you need to transfer it to the controller? It may be so and so, because if one service is called, it is more logical to call in the service, and if you have three methods of services in the controller that you need to call, then you need to call it outside of these services so that the transaction is one. These reflections suggest that perhaps the layers do not solve any problems.
And this idea occurred to more than one person. If you google, at least three of these respectable husbands write about the same thing. From top to bottom: Stephen .NET Junkie (unfortunately, I do not know his last name, because she does not appear anywhere on the Internet), the author of the Simple Injector IoC container . Next Jimmy Bogard is the author of AutoMapper . And down below is Scott Vlashin, author of F # for fun and profit .
All these people are talking about the same thing and suggest building applications not on the basis of layers, but on the basis of use cases, that is, those requirements that the business is asking us for. Accordingly, the use case in C # can be determined using the IHandler interface. It has input values, there are output values and there is a method itself that actually executes this use case.
And inside this method there can be either a domain model, or some denormalized model for reading, maybe with Dapper or with Elastic Search, if you need to look for something, and maybe you have Legacy -system with stored procedures - no problem, as well as network requests - well, in general, anything you might need there. But if there are no layers, what to do?
To get started, let's get rid of UserService. We remove the method and create a class. And we’ll remove it, and we will remove it again. And then take and remove the class.
Let's think, are these classes equivalent or not? The GetUser class returns data and does not change anything on the server. This, for example, about the request "Give me the user ID." The UpdateEmail and BanUser classes return the result of the operation and change the state. For example, when we tell the server: “Please change the state, you need to change something.”
Let's look at the HTTP protocol. There is a GET method, which, according to the specification of the HTTP protocol, should return data and not change the state of the server.
And there are other methods that can change the status of the server and return the result of the operation.
The CQRS paradigm seems to be specifically designed for the HTTP protocol. Query are GET operations, and commands are PUT, POST, DELETE — no need to invent anything.
We redefine our Handler and define additional interfaces. IQueryHandler, which differs only in that we hung constraint that the type of input values is IQuery. IQuery is a marker interface, there is nothing in it except this generic. We need the generic in order to put constraint in QueryHandler, and now, declaring QueryHandler, we cannot pass there not Query, but passing the Query object there, we know its return value. This is convenient if you have only one interface, so you do not have to look for their implementation in the code, and again so as not to mess up. You write IQueryHandler, write an implementation there, and in TOut you cannot substitute another type of return value. It just does not compile. Thus, you can immediately see which input values correspond to which input data.
The situation is completely similar for CommandHandler with one exception: this generic is needed for one more trick, which we will see a little further.
Handler Implementation
Handlers, we announced, what is their implementation?
Is there any problem, yes? Something seems to have failed.
Decorators rush to the rescue
But it didn’t help, because we are still in the middle of the road, we need to finalize a little more, and this time we need to use the decorator pattern , namely its wonderful layout feature. The decorator can be wrapped in a decorator, wrapped in a decorator, wrapped in a decorator - continue until you get bored.
Then everything will look like this: there is an input Dto, it enters the first decorator, the second, third, then we go into the Handler and also exit it, go through all the decorators and return Dto in the browser. We declare an abstract base class in order to later inherit, the body of Handler is passed to the constructor, and we declare the abstract Handle method, in which additional decorator logic will be hung.
Now with the help of decorators you can build a whole pipeline. Let's start with the teams. What did we have? Input values, validation, verification of access rights, the logic itself, some events that occur as a result of this logic, and return values.
Let's start with validation. We declare a decorator. IEnumerable from type T validators comes into the constructor of this decorator. We execute them all, check if the validation fails and the type of the return value is this , then we can return it, because the types match. And if it's some other Hander, well then you have to throw an Exception, because there is no result here, the type of another return value.
IEnumerableThe next step is Security. We also declare the decorator, make the CheckPermission method, and verify. If suddenly something went wrong, everything, we don’t continue. Now, after we have completed all the checks and are sure that everything is fine, we can fulfill our logic.
Obsession with primitives
Before showing the implementation of the logic, I want to start a little bit earlier, namely with the input values that come there.
Now, if we single out such a class, then most often it may look something like this. At least the code that I see in everyday work.
In order for validation to work, we add some attributes here that tell you what kind of validation it is. This will help from the point of view of the data structure, but will not help with such validation as checking values in the database. It’s just EmailAddress, it’s not clear how, where to check how to use these attributes in order to go to the database. Instead of attributes, you can go to special types, then this problem will be solved.
Instead of primitive
intlet's declare an Id type that has a generic that it is a certain entity with an int key. And we either pass this entity to the constructor, or pass its Id, but at the same time we must pass a function that by Id can take and return, check whether it is null there or not null. We do the same with Email. Convert all emails to the bottom line so that everything looks the same for us. Next, we take the Email attribute, declare it as static for compatibility with ASP.NET validation, and here we simply call it. That is, this can also be done. In order for the ASP.NET infrastructure to catch all this, you will have to slightly modify the serialization and / or ModelBinding. There is not much code there, it is relatively simple, so I won’t stop there.
After these changes, instead of primitive types, specialized types appear here: Id and Email. And after these ModelBinder and the updated deserializer worked out, we know for sure that these values are correct, including that such values are in the database. “Invariants”
The next point I would like to dwell on is the state of invariants in the class, because the anemic model is often used, in which there is simply a class, many setter getters, it is completely unclear how they should work together. We work with complex business logic, so it is important for us that the code is self-documenting. Instead, it is better to declare the real constructor along with empty for ORM, it can be declared protected so that programmers in their application code could not call it, and ORM could. Here we pass not the primitive type, but the Email type, it is already correctly correct, if it is null, we still throw an Exception. You can use some Fody, PostSharp, but C # 8 is coming soon. Accordingly, there will be a Non-nullable reference type, and it is better to wait for its support in the language. The next moment, if we want to change the name and surname, most likely we want to change them together, so there must be an appropriate public method that changes them together.
In this public method, we also verify that the length of these lines matches what we use in the database. And if something is wrong, then stop execution. Here I use the same trick. I declare a special attribute and just call it in the application code.
Moreover, such attributes can be reused in Dto. Now, if I want to change the name and surname, I may have such a change command. Is it worth adding a special constructor here? It seems to be worth it. It will become better, no one will change these values, will not break them, they will be exactly right.
Actually not really. The fact is that Dto are not really objects at all. This is such a dictionary into which we put deserialized data. That is, they pretend to be objects, of course, but they have only one responsibility - it is to be serialized and deserialized. If we try to fight this structure, we’ll start to announce some ModelBinders with designers, to do something like that is incredibly tiring, and, most importantly, it will break with new releases of new frameworks. All this was well described by Mark Simon in the article “On the borders of the program are not object-oriented” , if it’s interesting, it’s better to read his post, there it is described in detail.
In short, we have a dirty external world, we put checks at the input, convert it to our clean model, and then transfer it all back to serialization, to the browser, again to the dirty external world.
Handler
After all these changes have been made, how will the Hander look like here?
I wrote two lines here in order to make it more convenient to read, but in general it can be written in one. The data is exactly correct, because we have a type system, there is validation, that is, the data are reinforced concrete, you do not need to check them again. Such a user also exists, there is no other user with such a busy email, everything can be done. However, there is still no call to the SaveChanges method, there is no notification and there are no logs and profilers, right? We move on.
Events
Domain events.
Probably the first time this concept was popularized by Udi Dahan in his post “Domain Events - Salvation” . There, he suggests simply declaring a static class with the Raise method and throwing such events. A little later, Jimmy Bogard proposed a better implementation, it is called "A better domain events pattern" .
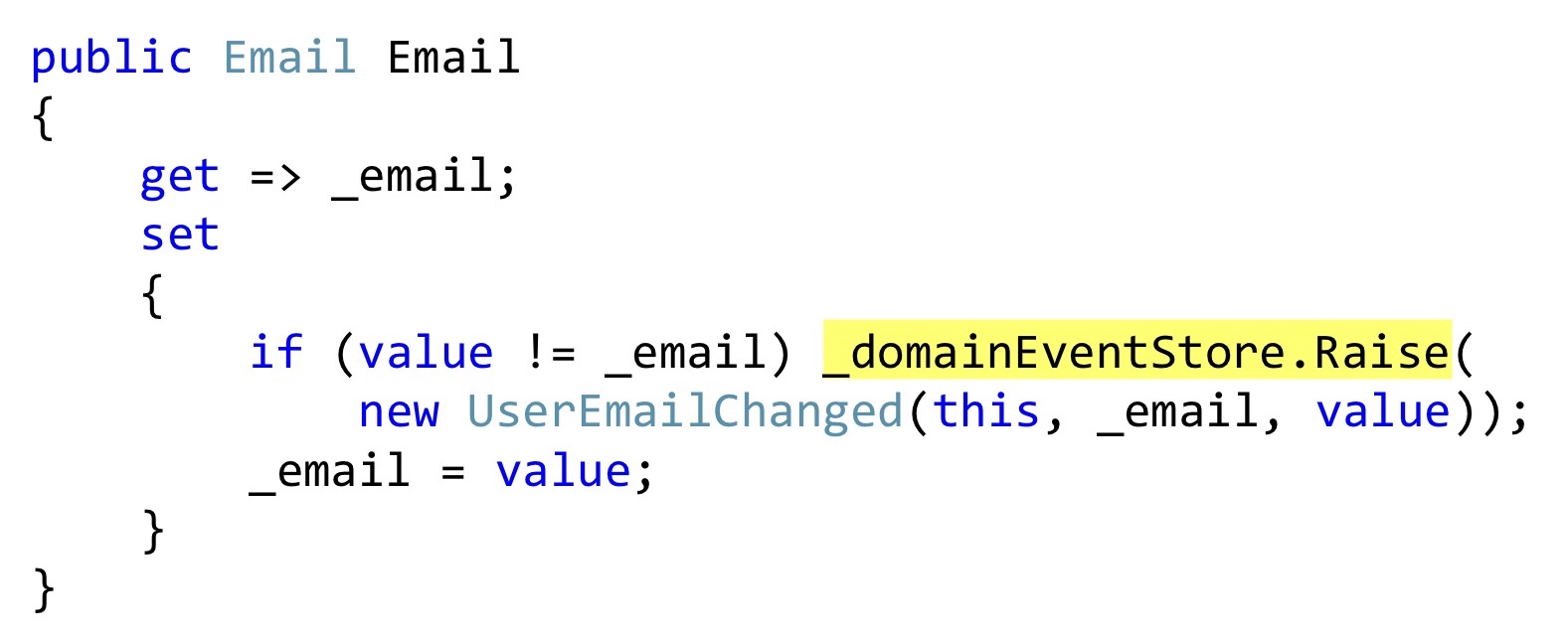
I will be showing the serialization of Bogard with one small change, but an important one. Instead of throwing events, we can declare some list, and in those places where some kind of reaction should take place, directly inside the entity to save these events. In this case, this getter
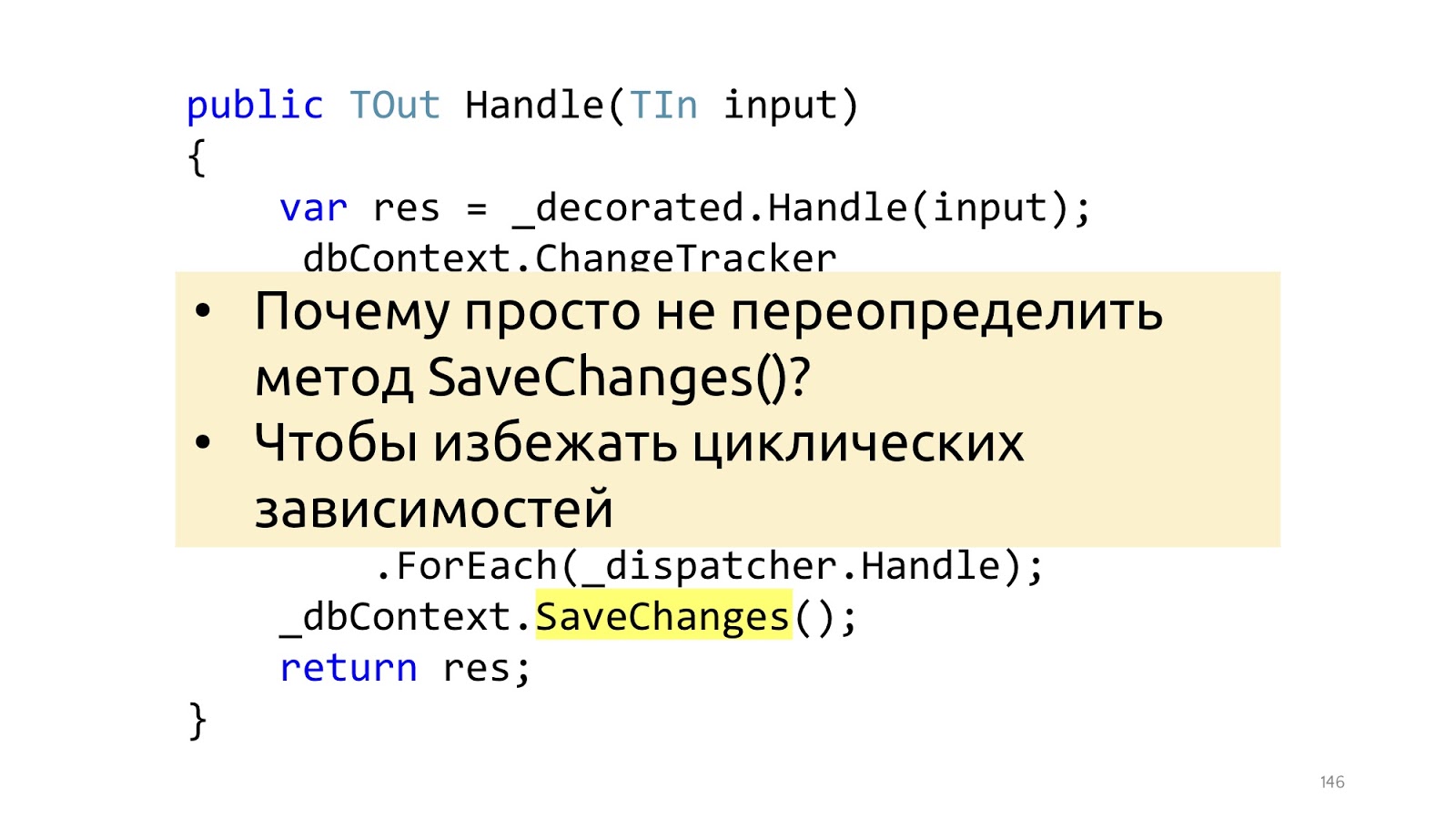
email- it is also a User class, and this class, this property does not pretend to be a property with getters and setters, but really adds something to this. That is, this is real encapsulation, not profanity. When changing, we check that the email is different and throw an event. This event has not yet reached anywhere; we only have it in the internal list of entities. Further, at the moment when we will call the SaveChanges method, we take ChangeTracker, see if there are any entities that implement the interface, whether they have domain events. And if there is, let's take all these domain events and send them to some dispatcher who knows what to do with them.
The implementation of this dispatcher is a topic for another discussion, there are some difficulties with multiple dispatch in C #, but this is also done. With this approach, there is another non-obvious advantage. Now, if we have two developers, one can write code that changes this email, and the other can do a notification module. They are absolutely not connected with each other, they write different code, they are connected only at the level of this domain event of one Dto class. The first developer simply throws this class away at some point, the second one responds to it and knows that it needs to be sent by email, SMS, push notifications to the phone and all the other million notifications, taking into account any user preferences that usually happen.
Here is the smallest, but important point. Jimmy's article uses an overload of the SaveChanges method, and it's best not to. And it’s better to do it in the decorator, because if we overload the SaveChanges method and we needed dbContext in Handler, we will get circular dependencies. You can work with this, but the solutions are a little less convenient and a little less beautiful. Therefore, if the pipeline is built on decorators, then I see no reason to do it differently.
Logging and Profiling
The nesting of the code remained, but in the initial example we had first using MiniProfiler, then try catch, then if. Total there were three levels of nesting, now each this level of nesting is in its own decorator. And inside the decorator, which is responsible for profiling, we have only one level of nesting, the code is read perfectly. In addition, it is clear that in these decorators there is only one responsibility. If the decorator is responsible for logging, then he will only log, if for profiling, respectively, only profile, everything else is in other places.
Response
After the entire pipeline has worked, we can only take Dto and send it to the browser further, serialize JSON.
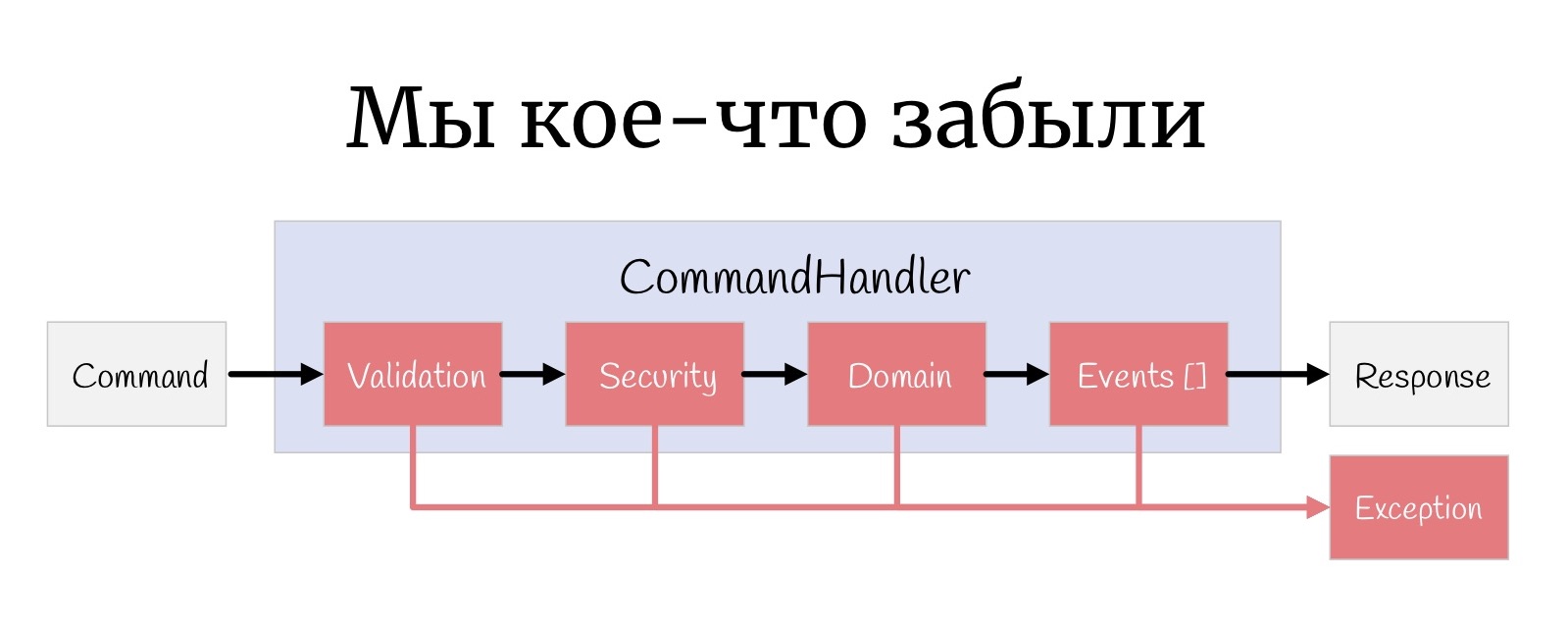
But one more small thing, such a thing that is sometimes forgotten: at every stage, an Exception can happen here, and actually you need to somehow handle them.
I cannot but mention Scott Vlashin and his report “Railway oriented programming” here again . Why? The original report is entirely devoted to working with errors in the F # language, how to organize flow a little differently and why such an approach may be preferable to using Exception'ov. In F #, this really works very well, because F # is a functional language, and Scott uses the functionality of a functional language.
Since, probably, most of you still write in C #, if you write an analogue in C # , then this approach will look something like this. Instead of throwing exceptions, we declare a Result class that has a successful branch and an unsuccessful branch. Accordingly, two designers. A class can be in only one state. This class is a special case of union type, discriminated union from F #, but rewritten in C #, because there is no built-in support in C #.
Instead of declaring public getters that someone might not check for null in the code, Pattern Matching is used. Again, in F # it would be a built-in Pattern Matching language, in C # we have to write a separate method into which we will pass one function that knows what to do with the successful result of the operation, how to convert it further down the chain, and that with an error. That is, no matter which branch worked for us, we must cast this to a single returned result. In F #, this all works very well, because there is a functional composition, well, and everything else that I have already listed. In .NET, this works a little worse, because as soon as you have more than one Result,
The easiest way to combine them is to use LINQ , because in fact LINQ works not only with IEnumerable, if you redefine the SelectMany and Select methods in the right way, then the C # compiler will see that you can use LINQ syntax for these types. In general, it turns out tracing paper with Haskell do-notation or with the same Computation Expressions in F #. How should this be read? Here we have three results of the operation, and if everything is fine there in all three cases, then take these results r1 + r2 + r3 and add it. The type of the resulting value will also be Result, but the new Result, which we declare in Select. In general, this is even a working approach, if not one but.
For all other developers, as soon as you start writing such code in C #, you start to look something like this. “These are bad scary Exceptions, don't write them! They are evil! Better write code that no one understands and cannot debug! ”
C # is not F #, it is somewhat different, there are no different concepts on the basis of which this is done, and when we try to pull an owl on the globe, it turns out, to put it mildly, unusual.
Instead, you can use the built-in normal tools that are documented, that everyone knows and that will not cause cognitive dissonance among developers. ASP.NET has a global Handler Exception.
We know that if there are any problems with validation, you need to return the code 400 or 422 (Unprocessable Entity). If there is a problem with authentication and authorization, there are 401 and 403. If something went wrong, then something went wrong. And if something went wrong and you want to tell the user exactly what, define your Exception type, say that it is IHasUserMessage, declare a Message getter in this interface and just check: if this interface is implemented, then you can take a message from Exception and pass it in JSON to the user. If this interface is not implemented, it means that there is some kind of system error, and we simply tell users that something went wrong, we are already doing it, we all know - well, as usual.
Query pipeline
We conclude this with the teams and look at what we have in the Read-stack. As for the request, validation, response directly - this is about the same thing, we will not stop separately. There may still be an additional cache, but in general there are no big problems with the cache either.
Security
Let's look better at a security check. There may also be the same Security decorator, which checks whether this request can be made or not:
But there is another case when we display more than one record, and list, and for some users we need to display a complete list (for example, some super administrators), and for other users we have to display limited lists, for third ones - limited in a different way, well, and as is often the case in corporate applications, access rights can be extremely sophisticated, so you need to be sure that these lists are not crawl through ie that these users are not intended.
The problem is solved quite simply. We can redefine the interface (IPermissionFilter) into which the original queryable arrives and queryable returns. The difference is that to the queryable that returns, we have already imposed additional conditions where, checked the current user and said: “Here, return only that data to that user ...” - and then all your logic related to permissions . Again, if you have two programmers, one programmer goes to write permissions, he knows that he needs to write just a lot of permissionFilters and check that they work correctly for all entities. And other programmers do not know anything about permission, in their list the correct data simply always passes, that's all. Because they receive at the input no longer the original queryable from dbContext, but limited to filters. Such permissionFilter also has a layout property, we can add and apply all permissionFilters. As a result, we get the resulting permissionFilter, which will narrow the data selection to the maximum, taking into account all the conditions that are suitable for this entity.
Why not do it with ORM built-in tools, for example, Global Filters in an entity framework? Again, in order not to make any cyclic dependencies for yourself and not drag any additional story about your business layer into context.
Query Pipeline. Read model
It remains to look at the reading model. The CQRS paradigm does not use the domain model in the reading stack, instead, we just immediately create the Dto that the browser needs at the moment.
If we write in C #, then most likely we are using LINQ, if there aren’t just any monstrous performance requirements, and if there are any, then you may not have a corporate application. In general, this problem can be solved once and for all with such a LinqQueryHandler. Here's a pretty scary constraint on the generic: this is Query, which returns a list of projections, and it can still filter these projections and sort these projections. She also works only with some types of entities and knows how to convert these entities to projections and return the list of such projections in the form of Dto to the browser.
The implementation of the Handle method can be quite simple. Just in case, check if this TQuery filter implements for the original entity. Further we do a projection, it is queryable extension AutoMapper'a. If someone still does not know, AutoMapper can build projections in LINQ, that is, those that will build the Select method, and not map it in memory.
Then we apply filtering, sorting and display it all in the browser. How exactly all this is done, I told in St. Petersburg on DotNext, this is another whole report, it is already available for free and decrypted in the Habré , you can listen, see, read how to write filtering, sorting and projection using expression'ov for anything once and then reused.
Not all expressions are equally useful translated into SQL
We move on. One topic that I did not cover in the last DotNext is problems with translation in SQL. Because in Select, of course, we can write everything we want, but the queryable providers will not understand everything.
Since we are talking about Habr, let's use Habr as an example. We have a list of posts, they have a Title, and we want to enter Title as the name of the hub, and then the name of the post itself. There are no problems with this projection, everything is being transformed. But if we want to bring out such a SubTitle when we last updated the article, when we created it, and we also want to use some custom format for these dates, the queryable provider will not be able to cope with this. He does not know what kind of custom format is declared in our code.
And there is one pretty simple trick that solves this problem. Instead of trying to project, we project to primitives. That is, we pull out everything we need, first. Next, we mark this all with “JsonIgnore” so that the serializer ignores these fields. And declare the method we need in Dto. That is, instead of doing this in the projection, we do it already in memory. When the serializer starts converting the class to JSON, it will see that it should skip Created and LastUpdated, and SubTitle is a public property, you need to take it. Then he will take it, call this method, and then in memory we will appap what we need, that which we could not transform into projections. In most cases, such a simple trick solves the problem that some expressions cannot be converted.
Let's look at both stacks together. They, in general, are quite similar and differ only in what steps we have taken. Depending on which pipeline, we can use different decorators. We’ll cache the requests — and in teams, for example, we don’t need it. Similarly, we want to invoke commands in SaveChanges, but in Query we do not need to call SaveChanges. When the pipelines are assembled and we understand that there are a limited number of them, such decorators can be taken and designed as separate libraries, put on NuGet, and then simply connected as reusable modules.
Because in the code of decorators there is nothing about the domain. You can write the domain separately, and transfer the infrastructure to some other developer, who will issue these modules to you, and you will use them. If you are familiar with Brooks, for example, you probably know that the easiest way to write code is to buy it. Accordingly, a great option, if you can take and say: “We need these decorators,” and buy them. No liability.
Registration of decorators
If decorators are so great, how do you register them?
It’s necessary to register them somehow like this. Not quite pretty.
Although no one does it with his hands, of course, it all happens through containers. You can take Jimmy Bogard's MediatR, in which all this already exists and there is documentation. All I talked about is the same decorators - the truth is, he has it called pipeline behavior in MediatR. But the meaning is the same, Request / Response methods, RequestHandlers and methods for registering these decorators are also defined there. Or you can take Simple Injector, whose decorator is just a piece of the framework.
And now back to this slide, remember, I said that we will need this generic again, where is TIn: ICommand.
Here in Simple Injector, registration of decorators based on constraints is additionally supported. That is, you can, where you register the decorator, indicate that if the decorator is with constraint, then it will be applied only to those Handlers that have such constraint. Accordingly, if we have ICommand constraint, we can create a SaveChanges decorator with ICommand constraint as well, and Simple Injector will automatically understand that these two constraints are the same and will only apply this decorator to the corresponding Handler. Well, it turns out another little beautiful feature that allows you to build just such application logic on the type system, which should be applied to what.
What to use? Simple Injector or MeriatR - in principle, all felt-tip pens are different in taste and color, in addition, in Autofac, in my opinion, there are also decorators and in other containers it can also be, I just don’t follow, I don’t know. If interested, take a look.
Organization by Modules, Not Layers
Throughout my current report, another word is missing to shout “bingo”.
Even two words, namely “Clean architecture”. It was impossible to mention a lot of smart people and forget about Uncle Bob Martin.
For some reason, modern web applications love to talk about the fact that they are MVC, how wonderful they are, what their structure is.
Instead, Bob Martin, and many others, including Angular, by the way, already offers to structure the application based on what modules there are in the system, that is, what functionality. Instead of saying: “I am an MVC application”, we can say: “I have the following Features, that is, such functionality: I have account management, I have Blog and I have some Import, that is some three big modules. ”
Perhaps, of course, it is more convenient for programmers to know that this is an MVC application, we like that there are some technical details, details. But for management MVC is absolutely unimportant. But such a structure, when a person understands how many features he has, is much more important for business. That is, this structure corresponds to the functionality of the system.
I promised, after all, not to crush the authorities and the fact that kung fu is stronger than another kung fu, so I will give other advantages of this design.
Firstly, the code in this case is added, not edited. If we have different modules and we want to add a new module, this is a new folder. It doesn’t work out that there is some work with users in module A and module B, so the programmers Vasya and Petya both went to fix the User Service, then they sent pull requests, and then suddenly there was a conflict because they both changed this User Service as deemed necessary. And even without the fact that they changed signatures or something like that, they just simply changed lines and types somewhere. Some commonplace technical things can lead to the fact that at the stage of the review code, a conflict may occur and this will delay the release cycle.
The next moment. This organization of the code encourages us to think better about what contexts there are in the application and how to divide it correctly. That is, if we divide correctly, then ideally we should not create any unnecessary dependencies between modules where they do not exist. Accordingly, where we are, we will find out what they are at the stage of separation by modules, because we will see that for some reason this module depends on another. And if it so happened that our modules are completely independent (and this can also be done, but with some reservations), then the feature can be deleted simply by clicking on the “Delete” button: we delete the folder and it is no longer in the program, and that’s it. Pretty comfortable.
In practice, we had to carry out such actions two or two times - the word "refactoring" is probably not quite right when you throw out all the code and rewrite it again, it's more like a rewrite. And if the code was written in the usual puff style, this would not have happened: all these services related to different modules, we could not have thrown out, because there would have been unnecessary dependencies. And so we just threw out some jammed modules and then rewrote when our hands reached. I will not go into details about why I had to do this, but sometimes it happens. That is, this happened not because there were bad and stupid programmers, but because of the circumstances.
And the last point: this separation simplifies the work of numerical methods and communication. When I say “numerical methods”, I again curtsey toward management: we begin to count the number of features, the number of returns with a review code, the number of returns from testing, and that’s all. Remember, when I formulated the criteria, I noticed that it is rather difficult to track the connection between regression, bugs that reached production, and why it happened. And when we begin to put the code in this way, it becomes a little easier. Because if some kind of pull request comes up to edit existing modules, option number one - requirements have changed, option number two - something went wrong, a bug crawled into production. And hereafter, we already look at the history of changes in VCS precisely for this module: why did he crawl into production, what commits were there? If these commits are in this module, they can still be sorted out somehow, and if they are simply spread across all our layers, it becomes much more difficult to sort out.
Despite this, everything I talked about is not without flaws. Namely: it does not work out of the box. That is, if you just take the project template, you have to add infrastructure code. Ideally, write your own project template, in which everything you need is already connected, there will be a project structure. But it probably takes no less than a working day if you do it from scratch. Well, once, for example. When I say “working day”, in the sense that everything is ready for us, you only need to collect the dependencies. It took me several years to build the dependencies - with how my idea of how to write code changed.
This illustrates the second point of this slide: write this infrastructure code, redefine something, add something. That is, more serious requirements are placed on him in terms of quality. In some application code, you can write as it is customary for you, because if a bug comes, you will correct it. But if you start to publish some libraries for free access and they have jambs, and someone connected them, and this is not one project, but this is tied to you, for example, the work of the entire company or the clients project, it becomes very more difficult. The risks of this case are higher.
We summarize. If you want to organize the work with the code as follows, you will need to declare here such IHandler as the main building block. He will perform operations.
Further we extend this IHandler with two interfaces ICommandHandler and IQueryHandler and we say that these are holistic abstractions. A very cool-sounding phrase means simply that it is performed in a single transaction. That is, if there is a CommandHandler, there will be no other CommandHandler inside it, it acts throughout this request.
Why is that? This eliminates the flame of what Query can use there in commands, commands in Query - that’s all. If you need reusable code that you have to use both there and there, then you declare Hander, if you declare CommandHandler or QueryHandler, it means some specific use case, this should not be reused.
Decorators are an excellent tool for sharing this whole logic, sharing responsibilities, responsibilities between different classes, in order to register them, you will need infrastructure: either a container or a framework.
The type system and invariants are much better than validation. Because it allows you to learn about errors at the compilation stage, and not in runtime. But not at the borders, because at the borders the programs are not object-oriented.
And we are still waiting for C # 8 to have a nullable reference type appear and our type system to become better. Not as cool, of course, as in functional programming languages, but better.
Events can be tracked as part of a transaction using ChangeTracker’s ORM.
And Exceptions are a normal option for errors if you don't write in F #, if we write in C #. There is an option in which you still need to abandon these exceptions, there may be some kind of performance limitation, for example. But if you have performance limitations due to the fact that you have too many Exceptions, you probably do not need LINQ there, and everything else, and everything that I told you is not quite for you, you we need stored procedures, Dapper, and something else, and maybe not even .NET.
And if we don’t have such terrible performance requirements, then LINQ, automatic projections, permissions are all excellent. Yes, it really slows down, but it slows down for a few milliseconds, that is, it is less than network delays to your database. Well, structuring the application by feature rather than by layer is a more preferable method.
I mentioned many people and ideas in the report. Here are the links:
- Vertical slices
- Obsession with primitives
- Domain events
- DDD
- Rop
- LINQ and Expressions:
- Clean architecture
The last slide is a bit of recommended literature. On the left, we have Eric Evans’s incorruptible. The second book is Scott Vlashin’s book “Domain Modeling Made Functional”, it is about F #, but even if you never want to write in F #, I still recommend reading it because it is very well structured, the thoughts are very clearly stated, just with the point of view of common sense and the fact that two plus two equals four. That is, ideas can also be transferred to C #, but with one exception, so as not to look like on that slide about Exception.
And the last, perhaps unobvious book, is Entity Framework Core In Action. I didn’t post it here because it is about the Entity Framework, but because there is a whole section on how to use all kinds of DDD options with ORM, that is, where ORM starts to interfere with us in terms of implementing DDD and how to get around it.
Minute of advertising. On May 15-16, 2019, the DotNext Piter .NET conference will be held, where I am a member of the program committee. The program can be viewed here , tickets can also be purchased on the website .