Errors built into the system: their role in statistics
In a previous article, I pointed out how widespread the problem of the misuse of the t-criterion is in scientific publications (and this can only be done thanks to their openness, and what trash is created when it is used in any course, reports, training tasks, etc. - is unknown) . To discuss this, I talked about the basics of analysis of variance and the significance level α set by the researcher himself. But for a full understanding of the whole picture of statistical analysis, it is necessary to emphasize a number of important things. And the most basic of them is the concept of error.
Any physical system contains some kind of error, inaccuracy. In the most diverse form: the so-called tolerance - the difference in size of different products of the same type; non-linear characteristic - when a device or method measures something according to a well-known law within certain limits, and then becomes inapplicable; discreteness - when we are technically unable to ensure a smooth output characteristic.
And at the same time, there is a purely human error - incorrect use of devices, instruments, mathematical laws. There is a fundamental difference between the error inherent in the system and the error in applying this system. It is important to distinguish and not confuse among themselves these two concepts, called the same word “error”. In this article, I prefer to use the word "error" to denote the properties of the system, and "incorrect use" - for its erroneous use.
That is, the error of the ruler is equal to the tolerance of the equipment, putting strokes on its canvas. A mistake in the sense of incorrect use would be to use it when measuring the details of a watch. The mistake of the steelyard is written on it and amounts to about 50 grams, and the misuse of the steelyard would be to weigh a 25 kg bag on it, which stretches the spring from the region of Hooke's law to the region of plastic deformations. The error of an atomic force microscope stems from its discreteness - you cannot "touch" objects with a probe smaller than with a diameter of one atom. But there are many ways to misuse it or misinterpret data. Etc.
So, what kind of error does this have in statistical methods? And this error is precisely the notorious level of significance α.
A mistake in the mathematical apparatus of statistics is its Bayesian probabilistic essence itself. In the last article, I already mentioned what statistical methods are based on: determining the significance level α as the greatest allowable probability to illegally reject the null hypothesis, and the researcher to independently assign this value to the researcher.
Do you already see this convention? In fact, in the criteria methods there is no familiar mathematical rigor. Mathematics operates on probabilistic characteristics.
And here comes another point where a misinterpretation of one word in a different context is possible. It is necessary to distinguish between the concept of probability and the actual implementation of an event, expressed in the distribution of probability. For example, before starting any of our experiments, we don’t know what kind of value we will get as a result. There are two possible outcomes: having made a certain value of the result, we will either really get it or not. It is logical that the probability of both events is 1/2. But the Gaussian curve shown in the previous article shows the probability distribution that we correctly guess the coincidence.
You can clearly illustrate this with an example. Let us roll two dice 600 times - regular and cheating. We get the following results:

Before the experiment, for both cubes the loss of any face will be equally probable - 1/6. However, after the experiment, the essence of the cheating cube appears, and we can say that the probability density of the six falling on it is 90%.
Another example that chemists, physicists, and anyone interested in quantum effects know about is atomic orbitals. Theoretically, an electron can be “smeared” in space and located almost anywhere. But in practice there are areas where it will be in 90 percent or more of cases. These regions of space formed by a surface with a probability density of the electron there being 90% are classical atomic orbitals in the form of spheres, dumbbells, etc.
So, by independently setting the significance level, we deliberately agree to the error described in its name. Because of this, not a single result can be considered “completely reliable” - always our statistical conclusions will contain some probability of failure.
An error formulated by determining the significance level α is called an error of the first kind . It can be defined as a “false alarm”, or, more correctly, a false positive result. In fact, what do the words “erroneously reject the null hypothesis” mean? This means mistakenly taking the observed data for significant differences between the two groups. To make a false diagnosis about the presence of the disease, to rush to reveal to the world a new discovery, which actually does not exist - these are examples of errors of the first kind.
But then, should there be false negative results? Quite right, and they are called errors of the second kind . Examples are an untimely diagnosis or disappointment as a result of the study, although in fact it contains important data. Errors of the second kind are indicated by the letter, oddly enough, β. But this concept itself is not so important for statistics as the number 1-β. The number 1-β is called the power of the criterion , and as you might guess, it characterizes the ability of the criterion not to miss a significant event.
However, the content in statistical methods of errors of the first and second kind is not only their limitation. The very concept of these errors can be used directly in statistical analysis. How?
ROC analysis (from receiver operating characteristic) is a method for quantifying the applicability of a certain attribute to a binary classification of objects. Simply put, we can come up with some way to distinguish sick people from healthy people, cats from dogs, black from white, and then check the validity of this method. Let's look at an example again.
Let you be a budding forensic scientist, and develop a new way to discreetly and unequivocally determine whether a person is a criminal. You came up with a quantitative sign: to evaluate the criminal inclinations of people by the frequency of their listening to Mikhail Krug. But will your symptom give adequate results? Let's get it right.
You will need two groups of people to validate your criteria: ordinary citizens and criminals. Indeed, let us assume that the average annual time they listen to Mikhail Krug differs (see the figure):
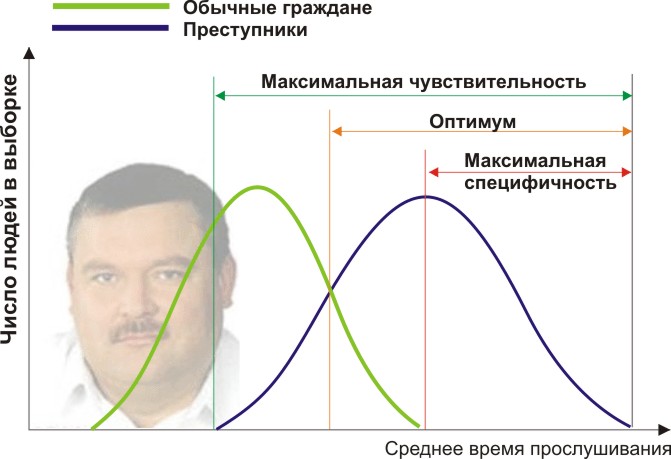
Here we see that by the quantitative sign of listening time, our samples intersect. Someone listens to the Circle spontaneously on the radio without committing crimes, and someone breaks the law by listening to other music or even being deaf. What boundary conditions do we have? ROC analysis introduces the concepts of selectivity (sensitivity) and specificity. Sensitivity is defined as the ability to identify all the points of interest to us (in this example, criminals), and specificity - not to capture anything false positive (not to put ordinary inhabitants under suspicion). We can set some critical quantitative trait that separates some from the others (orange), ranging from maximum sensitivity (green) to maximum specificity (red).
Let's look at the following diagram:

By shifting the value of our attribute, we change the ratio of false-positive and false-negative results (the area under the curves). In the same way, we can define Sensitivity = Position. Res-t / (Positive Res-t + false-negative. Res-t) and Specificity = Neg. Res-t / (Negative Res-t + false-positive. Res-t).
But most importantly, we can evaluate the ratio of positive to false positives over the entire range of values of our quantitative attribute, which is our desired ROC-curve (see figure):

And how do we understand from this graph how good our attribute is? Very simple, calculate the area under the curve (AUC, area under curve). The dashed line (0,0; 1,1) means the complete coincidence of the two samples and a completely meaningless criterion (the area under the curve is 0.5 of the entire square). But the convexity of the ROC curve just indicates the perfection of the criterion. If we manage to find such a criterion that the samples will not intersect at all, then the area under the curve will occupy the entire graph. In general, the trait is considered good, allowing one to reliably separate one sample from another if AUC> 0.75-0.8.
With this analysis, you can solve a variety of problems. Having decided that too many housewives are under suspicion because of Michael Krug, and in addition, dangerous repeat offenders listening to Noggano are missed, you can reject this criterion and develop another one.
Having emerged as a way of processing radio signals and identifying “friend or foe” after an attack on Pearl Harbor (hence the strange name for the characteristics of the receiver), ROC analysis has been widely used in biomedical statistics for analysis, validation, creation and characterization of biomarker panels etc. It is flexible to use if it is based on sound logic. For example, you can develop indications for medical examination of retired core patients by applying a highly specific criterion, increasing the efficiency of detecting heart diseases and not overloading doctors with unnecessary patients. And during a dangerous epidemic of a previously unknown virus, on the contrary, you can come up with a highly selective criterion so that no one else literally escapes vaccination.
We met with errors of both kinds and their visibility in the description of validated criteria. Now, moving from these logical foundations, we can destroy a series of false stereotypical descriptions of the results. Some incorrect formulations capture our minds, often confused by their similar words and concepts, and also because of the very little attention paid to incorrect interpretation. This, perhaps, will need to be written separately.
Error and incorrect application: what is the difference?
Any physical system contains some kind of error, inaccuracy. In the most diverse form: the so-called tolerance - the difference in size of different products of the same type; non-linear characteristic - when a device or method measures something according to a well-known law within certain limits, and then becomes inapplicable; discreteness - when we are technically unable to ensure a smooth output characteristic.
And at the same time, there is a purely human error - incorrect use of devices, instruments, mathematical laws. There is a fundamental difference between the error inherent in the system and the error in applying this system. It is important to distinguish and not confuse among themselves these two concepts, called the same word “error”. In this article, I prefer to use the word "error" to denote the properties of the system, and "incorrect use" - for its erroneous use.
That is, the error of the ruler is equal to the tolerance of the equipment, putting strokes on its canvas. A mistake in the sense of incorrect use would be to use it when measuring the details of a watch. The mistake of the steelyard is written on it and amounts to about 50 grams, and the misuse of the steelyard would be to weigh a 25 kg bag on it, which stretches the spring from the region of Hooke's law to the region of plastic deformations. The error of an atomic force microscope stems from its discreteness - you cannot "touch" objects with a probe smaller than with a diameter of one atom. But there are many ways to misuse it or misinterpret data. Etc.
So, what kind of error does this have in statistical methods? And this error is precisely the notorious level of significance α.
Errors of the first and second kind
A mistake in the mathematical apparatus of statistics is its Bayesian probabilistic essence itself. In the last article, I already mentioned what statistical methods are based on: determining the significance level α as the greatest allowable probability to illegally reject the null hypothesis, and the researcher to independently assign this value to the researcher.
Do you already see this convention? In fact, in the criteria methods there is no familiar mathematical rigor. Mathematics operates on probabilistic characteristics.
And here comes another point where a misinterpretation of one word in a different context is possible. It is necessary to distinguish between the concept of probability and the actual implementation of an event, expressed in the distribution of probability. For example, before starting any of our experiments, we don’t know what kind of value we will get as a result. There are two possible outcomes: having made a certain value of the result, we will either really get it or not. It is logical that the probability of both events is 1/2. But the Gaussian curve shown in the previous article shows the probability distribution that we correctly guess the coincidence.
You can clearly illustrate this with an example. Let us roll two dice 600 times - regular and cheating. We get the following results:
Before the experiment, for both cubes the loss of any face will be equally probable - 1/6. However, after the experiment, the essence of the cheating cube appears, and we can say that the probability density of the six falling on it is 90%.
Another example that chemists, physicists, and anyone interested in quantum effects know about is atomic orbitals. Theoretically, an electron can be “smeared” in space and located almost anywhere. But in practice there are areas where it will be in 90 percent or more of cases. These regions of space formed by a surface with a probability density of the electron there being 90% are classical atomic orbitals in the form of spheres, dumbbells, etc.
So, by independently setting the significance level, we deliberately agree to the error described in its name. Because of this, not a single result can be considered “completely reliable” - always our statistical conclusions will contain some probability of failure.
An error formulated by determining the significance level α is called an error of the first kind . It can be defined as a “false alarm”, or, more correctly, a false positive result. In fact, what do the words “erroneously reject the null hypothesis” mean? This means mistakenly taking the observed data for significant differences between the two groups. To make a false diagnosis about the presence of the disease, to rush to reveal to the world a new discovery, which actually does not exist - these are examples of errors of the first kind.
But then, should there be false negative results? Quite right, and they are called errors of the second kind . Examples are an untimely diagnosis or disappointment as a result of the study, although in fact it contains important data. Errors of the second kind are indicated by the letter, oddly enough, β. But this concept itself is not so important for statistics as the number 1-β. The number 1-β is called the power of the criterion , and as you might guess, it characterizes the ability of the criterion not to miss a significant event.
However, the content in statistical methods of errors of the first and second kind is not only their limitation. The very concept of these errors can be used directly in statistical analysis. How?
ROC analysis
ROC analysis (from receiver operating characteristic) is a method for quantifying the applicability of a certain attribute to a binary classification of objects. Simply put, we can come up with some way to distinguish sick people from healthy people, cats from dogs, black from white, and then check the validity of this method. Let's look at an example again.
Let you be a budding forensic scientist, and develop a new way to discreetly and unequivocally determine whether a person is a criminal. You came up with a quantitative sign: to evaluate the criminal inclinations of people by the frequency of their listening to Mikhail Krug. But will your symptom give adequate results? Let's get it right.
You will need two groups of people to validate your criteria: ordinary citizens and criminals. Indeed, let us assume that the average annual time they listen to Mikhail Krug differs (see the figure):
Here we see that by the quantitative sign of listening time, our samples intersect. Someone listens to the Circle spontaneously on the radio without committing crimes, and someone breaks the law by listening to other music or even being deaf. What boundary conditions do we have? ROC analysis introduces the concepts of selectivity (sensitivity) and specificity. Sensitivity is defined as the ability to identify all the points of interest to us (in this example, criminals), and specificity - not to capture anything false positive (not to put ordinary inhabitants under suspicion). We can set some critical quantitative trait that separates some from the others (orange), ranging from maximum sensitivity (green) to maximum specificity (red).
Let's look at the following diagram:
By shifting the value of our attribute, we change the ratio of false-positive and false-negative results (the area under the curves). In the same way, we can define Sensitivity = Position. Res-t / (Positive Res-t + false-negative. Res-t) and Specificity = Neg. Res-t / (Negative Res-t + false-positive. Res-t).
But most importantly, we can evaluate the ratio of positive to false positives over the entire range of values of our quantitative attribute, which is our desired ROC-curve (see figure):
And how do we understand from this graph how good our attribute is? Very simple, calculate the area under the curve (AUC, area under curve). The dashed line (0,0; 1,1) means the complete coincidence of the two samples and a completely meaningless criterion (the area under the curve is 0.5 of the entire square). But the convexity of the ROC curve just indicates the perfection of the criterion. If we manage to find such a criterion that the samples will not intersect at all, then the area under the curve will occupy the entire graph. In general, the trait is considered good, allowing one to reliably separate one sample from another if AUC> 0.75-0.8.
With this analysis, you can solve a variety of problems. Having decided that too many housewives are under suspicion because of Michael Krug, and in addition, dangerous repeat offenders listening to Noggano are missed, you can reject this criterion and develop another one.
Having emerged as a way of processing radio signals and identifying “friend or foe” after an attack on Pearl Harbor (hence the strange name for the characteristics of the receiver), ROC analysis has been widely used in biomedical statistics for analysis, validation, creation and characterization of biomarker panels etc. It is flexible to use if it is based on sound logic. For example, you can develop indications for medical examination of retired core patients by applying a highly specific criterion, increasing the efficiency of detecting heart diseases and not overloading doctors with unnecessary patients. And during a dangerous epidemic of a previously unknown virus, on the contrary, you can come up with a highly selective criterion so that no one else literally escapes vaccination.
We met with errors of both kinds and their visibility in the description of validated criteria. Now, moving from these logical foundations, we can destroy a series of false stereotypical descriptions of the results. Some incorrect formulations capture our minds, often confused by their similar words and concepts, and also because of the very little attention paid to incorrect interpretation. This, perhaps, will need to be written separately.