Book "Applied Text Data Analysis in Python"
 Text analysis technology is rapidly changing under the influence of machine learning. Neural networks from theoretical scientific research have passed into real life, and text analysis is actively integrated into software solutions. Neural networks are able to solve the most complex tasks of natural language processing, no one is surprised by machine translation, “conversation” with a robot in an online store, rephrasing, answering questions and maintaining a dialogue. Why does Siri, Alexa and Alice not want to understand us, Google does not find what we are looking for, and machine translators amuse us with examples of “translation difficulties” from Chinese to Albanian? The answer lies in the details - in algorithms that work correctly in theory, but are difficult to implement in practice. Learn how to use machine learning techniques to analyze text in real-world tasks, using the features and libraries of Python. From model search and data preprocessing, you will move on to the methods of classifying and clustering texts, then proceed to visual interpretation, graph analysis, and after familiarizing yourself with scaling techniques, learn to use deep learning to analyze text.
Text analysis technology is rapidly changing under the influence of machine learning. Neural networks from theoretical scientific research have passed into real life, and text analysis is actively integrated into software solutions. Neural networks are able to solve the most complex tasks of natural language processing, no one is surprised by machine translation, “conversation” with a robot in an online store, rephrasing, answering questions and maintaining a dialogue. Why does Siri, Alexa and Alice not want to understand us, Google does not find what we are looking for, and machine translators amuse us with examples of “translation difficulties” from Chinese to Albanian? The answer lies in the details - in algorithms that work correctly in theory, but are difficult to implement in practice. Learn how to use machine learning techniques to analyze text in real-world tasks, using the features and libraries of Python. From model search and data preprocessing, you will move on to the methods of classifying and clustering texts, then proceed to visual interpretation, graph analysis, and after familiarizing yourself with scaling techniques, learn to use deep learning to analyze text.What is described in this book?
This book talks about using machine learning methods to analyze text using the Python libraries just listed. The applied nature of the book suggests that we focus not on academic linguistics or statistical models, but on the effective deployment of text-trained models within the application.
Our proposed model of text analysis is directly related to the process of machine learning - the search for a model consisting of features, an algorithm, and hyperparameters that would give the best results on training data in order to evaluate unknown data. This process begins with the creation of a training data set, which in the field of text analysis is called the corpus. Then we examine the methods for extracting attributes and preprocessing to represent the text in the form of numerical data understandable to machine learning methods. Further, having got acquainted with some basics, we will move on to studying the methods of classification and clustering of text, the story of which completes the first chapters of the book.
In subsequent chapters, the focus is on expanding models with richer sets of attributes and creating text analysis applications. First, we will look at how it is possible to present and implement a context in the form of signs, then we will move on to a visual interpretation to control the process of model selection. Then we will look at how to analyze complex relationships extracted from text using graph analysis techniques. After that, we turn our attention to interactive agents and deepen our understanding of the syntactic and semantic analysis of the text. In conclusion, the book will present a practical discussion of scaling techniques for text analysis in multiprocessor systems using Spark, and finally, we will consider the next stage of text analysis: deep learning.
Who is this book for?
This book is written for Python programmers who are interested in using natural language processing and machine learning methods in their software products. We do not assume that our readers have special academic or mathematical knowledge, and instead focus on tools and techniques, rather than lengthy explanations. First of all, this book discusses the analysis of texts in English, so readers will need at least basic knowledge of grammatical entities such as nouns, verbs, adverbs and adjectives, and how they are related. Readers with no experience in machine learning and linguistics, but with programming skills in Python, will not feel lost in learning the concepts that we will introduce.
Excerpt. Extract graphs from text
Extracting a graph from text is a difficult task. Its solution usually depends on the subject area, and, generally speaking, the search for structured elements in unstructured or semi-structured data is determined by context-sensitive analytical questions.
We propose to break this task down into smaller steps by organizing a simple graph analysis process, as shown in Fig. 9.3.
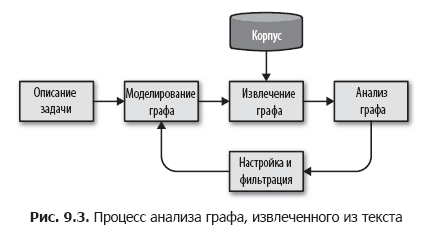
In this process, we first determine the entities and relationships between them, based on the description of the task. Further, on the basis of this scheme, we determine the methodology for selecting a graph from the corpus using metadata, documents in the corpus, and phrases or tokens in documents to extract data and the relationships between them. The technique of selecting a graph is a cyclic process that can be applied to the body, generate a graph and save this graph to disk or memory for further analytical processing.
At the analysis stage, calculations are performed on the extracted graph, for example, clustering, structural analysis, filtering or evaluation, and a new graph is created, which is used in applications. Based on the results of the analysis stage, we can return to the beginning of the cycle, refine the methodology and scheme, extract or collapse groups of nodes or edges in order to try to achieve more accurate results.
Creating a social graph
Consider our body of news articles and the task of modeling the relationships between different entities in the text. If we consider the issue of differences in coverage between different news agencies, you can build a graph from the elements representing the names of publications, names of authors and sources of information. And if the goal is to combine references to one entity in many articles, in addition to demographic details, our networks can fix the form of appeal (respectful and others). Entities of interest to us can be in the structure of the documents themselves or contained directly in the text.
Let's say our goal is to find out people, places, and anything else related to each other in our documents. In other words, we need to build a social network by performing a series of transformations, as shown in Fig. 9.4. We begin the construction of the graph using the EntityExtractor class created in Chapter 7. Then we add the transformers, one of which searches for pairs of related entities, and the second converts these pairs into a graph.
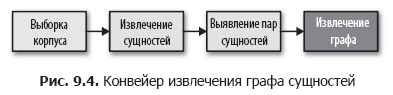
Finding Entity Pairs
Our next step is to create the EntityPairs class, which receives documents in the form of lists of entities (created by the EntityExtractor class from Chapter 7). This class should act as a converter in the Pipeline pipeline from Scikit-Learn, and therefore inherit the BaseEstimator and TransformerMixin classes, as described in Chapter 4. It is assumed that the entities in the same document are unconditionally connected to each other, so we add the pairs method using the itertools function .permutations to create all possible pairs of entities in one document. Our transform method will call pairs for each document in the body:
import itertools
from sklearn.base import BaseEstimator, TransformerMixin
class EntityPairs(BaseEstimator, TransformerMixin):
def __init__(self):
super(EntityPairs, self).__init__()
def pairs(self, document):
return list(itertools.permutations(set(document), 2))
def fit(self, documents, labels = None):
return self
def transform(self, documents):
return [self.pairs(document) for document in documents]Now you can sequentially extract entities from documents and pair up. But we can not yet distinguish pairs of entities that occur frequently from pairs that occur only once. We must somehow encode the weight of the relationship between the entities in each pair, which we will deal with in the next section.
Property Graphs
The mathematical model of the graph defines only sets of nodes and edges and can be represented as an adjacency matrix, which can be used in a variety of calculations. But it does not support a mechanism for modeling strength or types of relationships. Do two entities appear in only one document or in many? Do they meet together in articles of a particular genre? To support such reasoning, we need some way to save meaningful properties in the nodes and edges of the graph.
The property graph model allows you to embed more information in the graph, thereby expanding our capabilities. In the property graph, nodes are objects with incoming and outgoing edges and, as a rule, containing the type field, resembling a table in a relational database. Ribs are objects that define the start and end points; these objects usually contain a label field that identifies the type of connection, and a weight field that defines the strength of the connection. Using graphs for text analysis, we often use nouns as nodes, and verbs as edges. After moving on to the modeling step, this will allow us to describe the types of nodes, link labels, and the proposed graph structure.
About Authors
Benjamin Bengfort is a data science specialist based in Washington, DC, who completely ignores politics (a common thing for the District of Columbia) and prefers technology. He is currently working on his doctoral dissertation at the University of Maryland, where he is studying machine learning and distributed computing. There are robots in his laboratory (although this is not his favorite area), and much to his chagrin, the assistants constantly equip these robots with knives and tools, probably with the goal of winning a culinary competition. Watching a robot trying to chop a tomato, Benjamin prefers to host the kitchen himself, where he cooks French and Hawaiian dishes, as well as barbecue and barbecue of all kinds. Professional programmer by education,
Dr. Rebecca Bilbro - data science specialist, Python programmer, teacher, lecturer and author of articles; lives in Washington, DC. It specializes in visual assessment of machine learning results: from feature analysis to model selection and hyper parameter settings. He conducts research in the field of natural language processing, building semantic networks, resolving entities and processing information with a large number of dimensions. As an active member of the community of users and developers of open source software, Rebecca is pleased to work with other developers on projects such as Yellowbrick (a Python package that aims to predictive black box modeling). In his spare time, he often rides bicycles with his family or practices playing the ukulele. She received her doctorate from the University of Illinois, at Urbana-Champaign, where she studied the practical techniques of communication and visualization in technology.
»More information on the book can be found on the publisher’s website
» Contents
» Excerpt
For Khabrozhiteley 20% discount on coupon - Python
Upon payment of the paper version of the book, an electronic version of the book is sent by e-mail.
PS: 7% of the cost of the book will go to the translation of new computer books, the list of books handed over to the printing house is here .