Is a person needed to build self-learning models?
Another step in machine self-learning
Of course, there are many self-learning models in Data Science, but are they really? Actually, no: now in machine learning there is a situation where the human factor plays a decisive role in building effective models.
Data Science is now a kind of fusion of science and intuition, because there is no formalized knowledge of how to correctly predict predictors, which model to choose from dozens of existing ones, and how to configure many parameters in this model. All this is difficult to formalize, and therefore a paradoxical situation arises - machine learning requires a human factor.
It is the person who needs to build the learning chain, and adjust the parameters that can easily turn the best model into absolutely useless. The construction of this chain, which turns the initial data into a predictive model, can take several weeks, depending on the complexity of the task, and is often done simply by trial and error.
This is a serious flaw, and therefore the idea arose: can machine learning - educate yourself in the same way that a person does? Such a system was created, and it is surprising that this news has not yet reached the habrasociety!
TROT (Tree-based Pipeline Optimization Tool)
Randy Olson, a graduate student at Computational Genetics Lab (University of Pennsylvania), developed a Tree-based Pipeline Optimization Tool as part of his graduation project .
This system is positioned as a Data Science assistant. It automates the most tedious part of machine learning, studying and selecting among the thousands of possible building chains exactly the one that is best suited for processing your data.
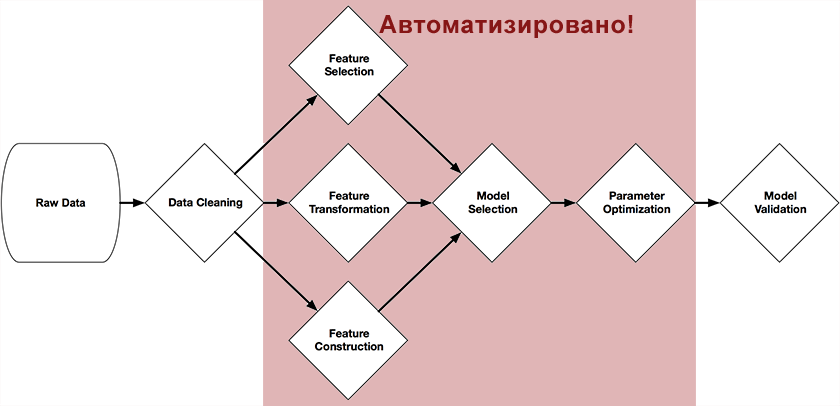
The system was written in Python using the scikit-learn library, and through genetic algorithms independently builds a complete chain of model preparation and construction. The figure at the beginning of this article presents those parts of the chain that can be automated with its help: preprocessing and selection of predictors, selection of models, optimization of their parameters.
The idea is quite simple - a genetic algorithm .
This is an algorithm for finding the chain we need by random selection, using mechanisms similar to natural selection in nature. They are written in sufficient detail about them on Wikipedia , on the Habr , or in the book "Self-learning systems"(I recommend for those interested in this topic, there is a network in electronic form).
As a function of selection (Fitness function), the accuracy of prediction in the test sample is used, as an object of the population are scikit methods and their parameters.
results
The author presents a simple example of how to use TPOT to solve the reference problem for the classification of handwritten digits from the MNIST set
from tpot import TPOT
from sklearn.datasets import load_digits
from sklearn.cross_validation import train_test_split
digits = load_digits()
X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target, train_size=0.75)
tpot = TPOT(generations=5, verbosity=2)
tpot.fit(X_train, y_train)
print( tpot.score(X_train, y_train, X_test, y_test) )
tpot.export('tpot_exported_pipeline.py')
When you run the code, after a couple of minutes, TPOT can get the model building chain, whose accuracy reaches 98%. This will happen when TPOT discovers that the Random Forest classifier works perfectly on MNIST data.
However, since this process is probabilistic, it is recommended to set the random_state parameter for repeatable results - for example, for 5 generations I only found a chain with SVC and KNeighborsClassifier.
Testing the system on another classic problem, Fisher's irises , gave an accuracy of 97% over 10 generations.
Future
Trot is an open source project that arose a month ago (which is generally a child’s age for such systems) and is now actively developing. On the project’s website, the author encourages the Data Scientists community to join the development of a system whose code is available on github (https://github.com/rhiever/tpot)
Of course, now the system is very far from ideal, but the idea of this system looks extremely logical - full automation the whole process of machine learning. And if the idea develops, then perhaps systems will soon appear where a person is only required to download data and get a result. And then another question will arise: Is a person needed at all to build self-learning models?
