My nephew is against machine learning
- Transfer
My four-year-old nephew Yali was keen on Pokémon. He has many of these toys and several cards from the collectible card game (TGG). Yesterday, he discovered in me a large collection of TGG cards, and now he has so many cards that he simply can not cope with them.
The problem is that Yali is too small to figure out how to play the game, and he invented his version of the game. The goal of the game is to sort cards into categories (Pokemon, energy and training card).
He did not ask how I know what type of card. He simply took a few cards and asked what type they were. Having received several answers, he managed to separate several cards by type (having made several mistakes at the same time). At that moment, I realized that my nephew is essentially a machine learning algorithm, and my task as an uncle is to label the data for him. Since I am a geek uncle and a machine learning enthusiast, I started writing a program that could compete with Yali.
This is what a typical Pokemon map looks like:

For an adult who can read, it is easy to understand what type of card this is written on it. But Yali is 4 years old, and he cannot read. A simple OCR module would quickly solve my problem, but I did not want to make unnecessary assumptions. I just took this card and provided it for studying the MLP neural network. Thanks to the pkmncards site , I was able to download pictures that were already sorted into categories, so there were no problems with these data.
The machine learning algorithm needed attributes, and my attributes were image pixels. I converted 3 RGB colors to one integer. Since I came across pictures of different sizes, they needed to be normalized. Having found the maximum height and width of the pictures, I added zeros to the smaller pictures.

A quick QA run before the program itself. I randomly took two cards of each type and ran a prediction. When using 100 cards from each category, the fit went very fast and the predictions were terrible. Then I took 500 cards from each category (excluding the types of energy, which were only 130), and started the fit.
The memory is over. It was possible to run fitting code in the cloud, but I wanted to come up with a way to save memory. The largest picture was 800x635, it was too much, and resizing the pictures solved my problem.
For this check, in addition to the usual cards, I added cards on which I played a bit, cards cut in half, with contours drawn on top, photographed them with a phone (with a bad camera), etc. These cards were not used for training.
I used 1533 models. Different sizes of pictures, several hidden layers (up to 3), layer length (up to 100), image colors, image reading methods (the whole, top, every second pixel, etc.). After many hours of fitting, the best result was 2 errors out of 25 cards (few models had such a result, and each of them was mistaken on different cards). 9 models out of 1533 worked with a result of 2 errors.

The combination of models gave me a result with 1 error if I raised the threshold above 44%. For the test, I used a threshold of 50%. I waited a month while Yali was playing with cards, and tested.

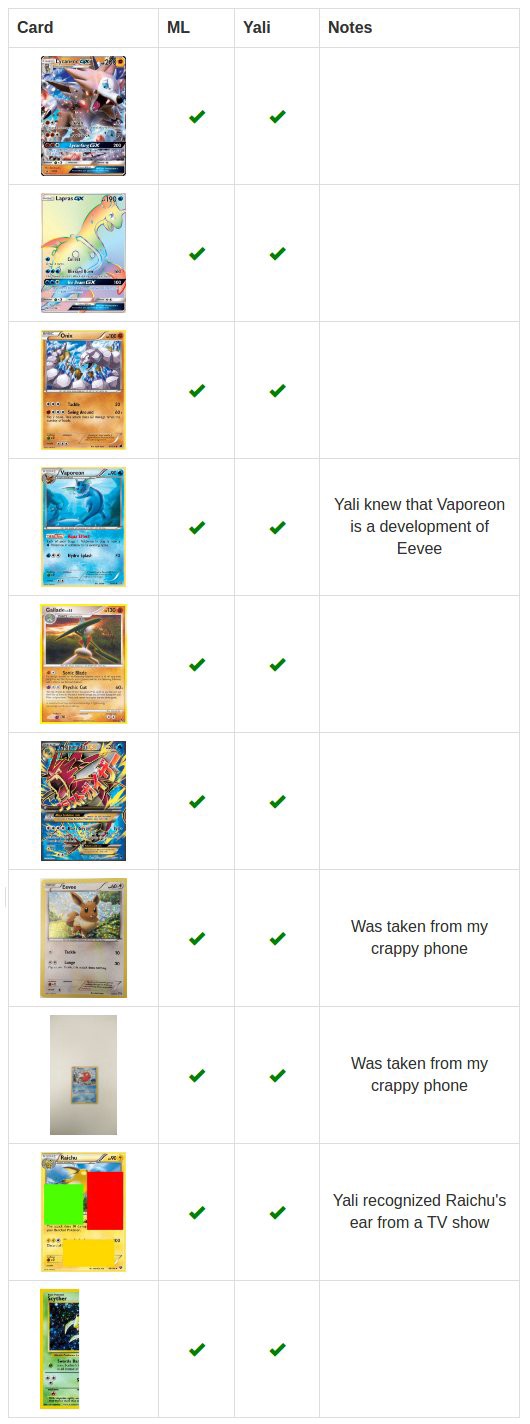
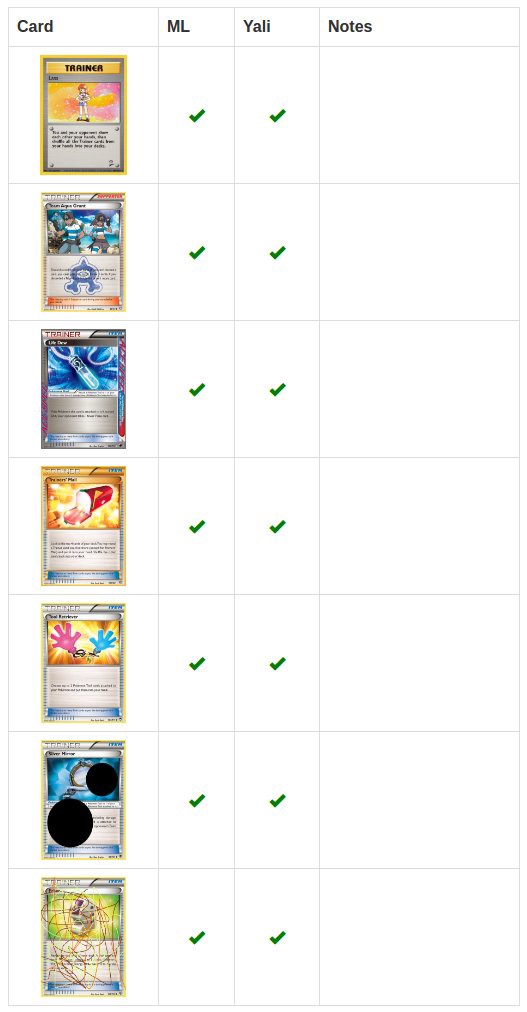
Errors occur when recognizing energy cards. There were only 130 such cards at pkmncards, unlike thousands of other types of cards. Less examples for learning.
I asked Yali about how he recognized cards, and he told me that he had seen some Pokémon in TV shows or books. That is how he recognized Raichu's ears or learned that Vaporon is a water Evie. My program didn’t have such data, only maps.
Having defeated Yali in a game with Pokemon and receiving a reward, our machine intelligence sets off to meet new adventures.

The problem is that Yali is too small to figure out how to play the game, and he invented his version of the game. The goal of the game is to sort cards into categories (Pokemon, energy and training card).
He did not ask how I know what type of card. He simply took a few cards and asked what type they were. Having received several answers, he managed to separate several cards by type (having made several mistakes at the same time). At that moment, I realized that my nephew is essentially a machine learning algorithm, and my task as an uncle is to label the data for him. Since I am a geek uncle and a machine learning enthusiast, I started writing a program that could compete with Yali.
This is what a typical Pokemon map looks like:
For an adult who can read, it is easy to understand what type of card this is written on it. But Yali is 4 years old, and he cannot read. A simple OCR module would quickly solve my problem, but I did not want to make unnecessary assumptions. I just took this card and provided it for studying the MLP neural network. Thanks to the pkmncards site , I was able to download pictures that were already sorted into categories, so there were no problems with these data.
The machine learning algorithm needed attributes, and my attributes were image pixels. I converted 3 RGB colors to one integer. Since I came across pictures of different sizes, they needed to be normalized. Having found the maximum height and width of the pictures, I added zeros to the smaller pictures.
A quick QA run before the program itself. I randomly took two cards of each type and ran a prediction. When using 100 cards from each category, the fit went very fast and the predictions were terrible. Then I took 500 cards from each category (excluding the types of energy, which were only 130), and started the fit.
The memory is over. It was possible to run fitting code in the cloud, but I wanted to come up with a way to save memory. The largest picture was 800x635, it was too much, and resizing the pictures solved my problem.
For this check, in addition to the usual cards, I added cards on which I played a bit, cards cut in half, with contours drawn on top, photographed them with a phone (with a bad camera), etc. These cards were not used for training.
I used 1533 models. Different sizes of pictures, several hidden layers (up to 3), layer length (up to 100), image colors, image reading methods (the whole, top, every second pixel, etc.). After many hours of fitting, the best result was 2 errors out of 25 cards (few models had such a result, and each of them was mistaken on different cards). 9 models out of 1533 worked with a result of 2 errors.
The combination of models gave me a result with 1 error if I raised the threshold above 44%. For the test, I used a threshold of 50%. I waited a month while Yali was playing with cards, and tested.
Errors occur when recognizing energy cards. There were only 130 such cards at pkmncards, unlike thousands of other types of cards. Less examples for learning.
I asked Yali about how he recognized cards, and he told me that he had seen some Pokémon in TV shows or books. That is how he recognized Raichu's ears or learned that Vaporon is a water Evie. My program didn’t have such data, only maps.
Having defeated Yali in a game with Pokemon and receiving a reward, our machine intelligence sets off to meet new adventures.