How the center for operational management of information security (SOC-center) is being built today
In large companies, there are people who are only involved in monitoring the state of information security and waiting for problems to begin. This is not about the guards in front of the monitors, but about the selected people (at least one in a shift) in the information security department.

Most of the time, the SOC center operator works with SIEMs. SIEM systems collect data from various sources throughout the network and, together with other solutions, compare events and assess the threat - both individually for each user and service, and for groups of users and network nodes as a whole. As soon as someone starts to behave too suspiciously, the SOC-center operator receives a notification. If the level of suspicion surpasses, first suspicious process or workplace is isolated, and only then comes a notification. Further investigation of the incident begins.
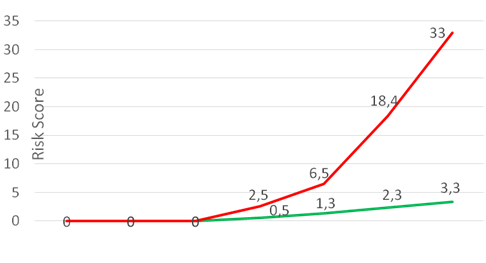
Very simplifying, for each suspicious action the user receives penalty points. If the action is characteristic of him or his colleagues, there are few points. If the action is not typical, there are a lot of points.
For UBA systems (User Behavior Analytics), the sequence of actions also matters. Separately, a sharp jump in the volume of traffic, connecting to a new IP or copying data from a file server happens from time to time. But if at first the user opened the letter, then he had a call to the newly registered domain, and then he began to rummage around the neighboring machines and send strange encrypted traffic to the Internet - this is a suspicion of an attack.
Typically, at the average level of development of the IS department, a typical company has a set of protection systems - firewalls (often NGFW), streaming antiviruses, DDoS protection systems, a DLP system with agents on workstations, and so on. But all this is rarely linked into a single information network that compares events and finds non-obvious correlations.
“Still inexperienced” are distinguished from “already inexperienced” by well-established processes of work with the constantly changing company infrastructure. That is, the system is dynamic, and the entire infrastructure is considered as a living organism, growing and continuously developing. Based on this paradigm, all work rules, procedures and regulations for interaction within the existing ecosystem are set.
If there is no such approach, then even though the data is somehow collected, and the incidents are somehow fixed, we often see that those responsible do not know how to respond to certain situations. I know you are now ready to not believe me. But recently there was a striking example. When replacing the equipment, the state-owned company did not manage to roll up the correct configs in time and caught an encryption virus. They call and ask: “What to do right now?” IT wants to block completely, clean the network segment, reinstalling all the OS, IS says that there is critical data and it is not clear what the virus reached out to - and does not give permission to touch anything. Time is running out.
We advised isolating the segment on the firewall, making a complete snapshot of all the workstations of the segment and passing it to us on forensics. While the analysis is being carried out, reinstall the OS for encrypted stations from scratch, for the rest - check for a rootkit by running an antivirus from LiveCD. Then return the stations to the network, but continue to closely monitor traffic to proxies and NGFW for the spread of infection and conduct a security audit for key systems.
As a result, the customer revised the risks of information security and redid all protection to normal, with centralized control of the settings of workstations, servers and network equipment, a centralized control system for running applications, integrity control of key systems and more stringent settings for information security.
Well, primarily because SIEM systems are reactive in nature. They have a key advantage - they connect and unite a bunch of systems of different vendors. That is, you do not need to change and redo the entire infrastructure from scratch - take your existing protection components and put the SIEM system on top of them. The problem is that the SIEM system begins to work only when the attacker has already penetrated the infrastructure. Therefore, for an effective SOC center, classic SIEM systems must be supplemented with UBA-class systems and Threat Intelligence data, which allow an attacker to be detected even in the early stages of an attack, ideally at the stage of preparation for hacking.
After several weeks of training the UBA system, what is an incident and what is an ordinary repeating routine, there remain about a dozen major alarms per day. Suppose eight of them require a quick analysis, but end in a trite way - these are bugs, hardware failures, atypical, but allowed user activity. Another is the situation when a kiddie script tries to break through the protection. And the last is a real data leak or targeted attack. Such cases require a more detailed investigation, including a retrospective analysis of a large amount of data to a depth of about several months. Here, SOC centers are well assisted by data analysis systems built on the basis of technologies of the Big Data class.

Figure 1. Typical APT attack scenario
SIEM and UBA look at who did what, what changed, and how to understand whether a node or employee is compromised or not.
Secondly, we need people who are involved in the detection and investigation of information security incidents. That is, their task is not infrastructure support, but active participation in the operational response to information security incidents. For a day on a large retail network, a hundred potential IS incidents are quite possible. Most of them are automatic attacks on web resources or unaccounted interactions with external systems, but some of them are very real external APT attacks and internal fraud.
Thirdly, the regulations and procedures for the interaction of various units at the time of the attack, the so-called Play Book, should be worked out, in accordance with which the IS incident is localized and investigated. In many situations, SOC employees must have high authority. For example, they should have the right to instantly suspend production if there is a massive data leak. In a bank, chopping off food in such a situation is the limit of courage. But if you think through everything in advance and fix the action plan in the regulations, you can choose a lesser evil in each specific situation. All this is done in order to detect the incident as early as possible and minimize potential damage.
We have implemented our own SOC-center, to which we have connected both our infrastructure and a number of our customers. It is based on the SIEM system, which we supplemented with our own development based on Big Data with machine learning for detecting anomalies and APT attacks. On the first line, we have a dedicated Helpdesk group - “universal soldiers” who will carry out basic Troubleshoot and simple incidents can be closed. The second line is analysts, information security experts, who are involved in the investigation of complex incidents and deep forensics. And there is also a team of pentesters, which from time to time checks the network perimeter for strength. All teams communicate with each other through HPSM for the convenience and support of a single knowledge base.
One of the most important features of behavioral analysis systems that are deployed within the framework of SOC centers is training and calibration. That is, the very assessments of the actions of users and nodes on a scale of potential danger, formed in real time. If the user's workstation is compromised, then his behavior in the system will be quite different from his colleagues.
It is important to localize based on typical behavior. For example, if a person works as a networker in a large company and launches a bunch of strange tools, SIEM will see that five more of the same people are working nearby, which means that everything is normal. But if the accountant begins to do something similar to the tricks of the engineer - the alarm will be right away.
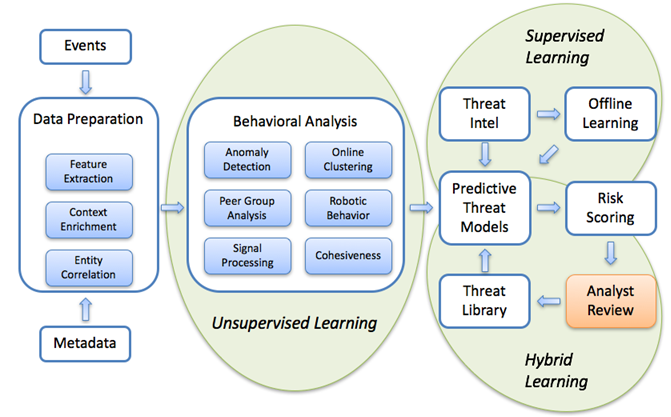
Figure 2. Machine learning models for detecting abnormal network activity
In practice, during implementations during calibrations, we found:
A very good thing is to evaluate the model and collapse the heap of incidents to the root cause. For example, uplink failure between data centers is one big problem, not hundreds of mini-failures of workstations, servers and network equipment. Operators must understand, so most often done something like this:

Figure 3. Formation of a resource-service model
A very good thing is combining disparate incidents into a single kill chain. There are a number of stages that a hacker goes through when hacking infrastructure, from preparing for scanning to data theft and destroying logs. Signs of such activity can be monitored for months and entered into the user’s "card", which allows operators to quickly identify the "zero patient".

Figure 4. Killchain example
In the end, it looks something like this:
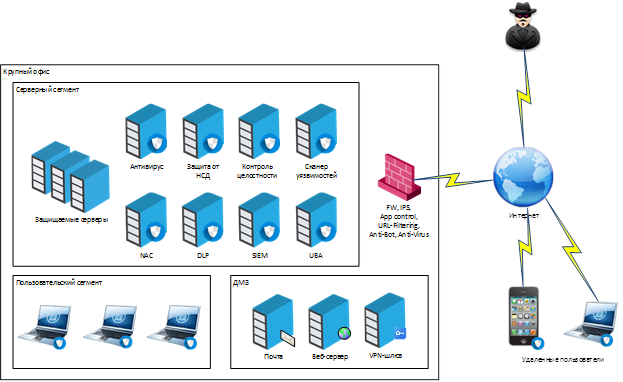
And this is an example of a set of security systems that are interconnected within the framework of SOC and exchange data via SIEM:

By the way, if you are a beginner and have long wanted to work in the field of information security, we have something for you . We are looking for a junior manager to promote information security solutions. It will be necessary to understand both current solutions, and vendors and their products. Communicate with customers, make commercial offers and so on. In general, it will not be boring. For details, write to me by mail.
Most of the time, the SOC center operator works with SIEMs. SIEM systems collect data from various sources throughout the network and, together with other solutions, compare events and assess the threat - both individually for each user and service, and for groups of users and network nodes as a whole. As soon as someone starts to behave too suspiciously, the SOC-center operator receives a notification. If the level of suspicion surpasses, first suspicious process or workplace is isolated, and only then comes a notification. Further investigation of the incident begins.
Very simplifying, for each suspicious action the user receives penalty points. If the action is characteristic of him or his colleagues, there are few points. If the action is not typical, there are a lot of points.
For UBA systems (User Behavior Analytics), the sequence of actions also matters. Separately, a sharp jump in the volume of traffic, connecting to a new IP or copying data from a file server happens from time to time. But if at first the user opened the letter, then he had a call to the newly registered domain, and then he began to rummage around the neighboring machines and send strange encrypted traffic to the Internet - this is a suspicion of an attack.
How do they usually work with information security?
Typically, at the average level of development of the IS department, a typical company has a set of protection systems - firewalls (often NGFW), streaming antiviruses, DDoS protection systems, a DLP system with agents on workstations, and so on. But all this is rarely linked into a single information network that compares events and finds non-obvious correlations.
“Still inexperienced” are distinguished from “already inexperienced” by well-established processes of work with the constantly changing company infrastructure. That is, the system is dynamic, and the entire infrastructure is considered as a living organism, growing and continuously developing. Based on this paradigm, all work rules, procedures and regulations for interaction within the existing ecosystem are set.
If there is no such approach, then even though the data is somehow collected, and the incidents are somehow fixed, we often see that those responsible do not know how to respond to certain situations. I know you are now ready to not believe me. But recently there was a striking example. When replacing the equipment, the state-owned company did not manage to roll up the correct configs in time and caught an encryption virus. They call and ask: “What to do right now?” IT wants to block completely, clean the network segment, reinstalling all the OS, IS says that there is critical data and it is not clear what the virus reached out to - and does not give permission to touch anything. Time is running out.
We advised isolating the segment on the firewall, making a complete snapshot of all the workstations of the segment and passing it to us on forensics. While the analysis is being carried out, reinstall the OS for encrypted stations from scratch, for the rest - check for a rootkit by running an antivirus from LiveCD. Then return the stations to the network, but continue to closely monitor traffic to proxies and NGFW for the spread of infection and conduct a security audit for key systems.
As a result, the customer revised the risks of information security and redid all protection to normal, with centralized control of the settings of workstations, servers and network equipment, a centralized control system for running applications, integrity control of key systems and more stringent settings for information security.
How is the construction of the SOC-center different from the implementation of the SIEM-system?
Well, primarily because SIEM systems are reactive in nature. They have a key advantage - they connect and unite a bunch of systems of different vendors. That is, you do not need to change and redo the entire infrastructure from scratch - take your existing protection components and put the SIEM system on top of them. The problem is that the SIEM system begins to work only when the attacker has already penetrated the infrastructure. Therefore, for an effective SOC center, classic SIEM systems must be supplemented with UBA-class systems and Threat Intelligence data, which allow an attacker to be detected even in the early stages of an attack, ideally at the stage of preparation for hacking.
After several weeks of training the UBA system, what is an incident and what is an ordinary repeating routine, there remain about a dozen major alarms per day. Suppose eight of them require a quick analysis, but end in a trite way - these are bugs, hardware failures, atypical, but allowed user activity. Another is the situation when a kiddie script tries to break through the protection. And the last is a real data leak or targeted attack. Such cases require a more detailed investigation, including a retrospective analysis of a large amount of data to a depth of about several months. Here, SOC centers are well assisted by data analysis systems built on the basis of technologies of the Big Data class.
Figure 1. Typical APT attack scenario
SIEM and UBA look at who did what, what changed, and how to understand whether a node or employee is compromised or not.
Secondly, we need people who are involved in the detection and investigation of information security incidents. That is, their task is not infrastructure support, but active participation in the operational response to information security incidents. For a day on a large retail network, a hundred potential IS incidents are quite possible. Most of them are automatic attacks on web resources or unaccounted interactions with external systems, but some of them are very real external APT attacks and internal fraud.
Thirdly, the regulations and procedures for the interaction of various units at the time of the attack, the so-called Play Book, should be worked out, in accordance with which the IS incident is localized and investigated. In many situations, SOC employees must have high authority. For example, they should have the right to instantly suspend production if there is a massive data leak. In a bank, chopping off food in such a situation is the limit of courage. But if you think through everything in advance and fix the action plan in the regulations, you can choose a lesser evil in each specific situation. All this is done in order to detect the incident as early as possible and minimize potential damage.
Practice
We have implemented our own SOC-center, to which we have connected both our infrastructure and a number of our customers. It is based on the SIEM system, which we supplemented with our own development based on Big Data with machine learning for detecting anomalies and APT attacks. On the first line, we have a dedicated Helpdesk group - “universal soldiers” who will carry out basic Troubleshoot and simple incidents can be closed. The second line is analysts, information security experts, who are involved in the investigation of complex incidents and deep forensics. And there is also a team of pentesters, which from time to time checks the network perimeter for strength. All teams communicate with each other through HPSM for the convenience and support of a single knowledge base.
One of the most important features of behavioral analysis systems that are deployed within the framework of SOC centers is training and calibration. That is, the very assessments of the actions of users and nodes on a scale of potential danger, formed in real time. If the user's workstation is compromised, then his behavior in the system will be quite different from his colleagues.
It is important to localize based on typical behavior. For example, if a person works as a networker in a large company and launches a bunch of strange tools, SIEM will see that five more of the same people are working nearby, which means that everything is normal. But if the accountant begins to do something similar to the tricks of the engineer - the alarm will be right away.
Figure 2. Machine learning models for detecting abnormal network activity
In practice, during implementations during calibrations, we found:
- Those who decided to mine cryptocurrency.
- Found innumerable people who send files to their personal mail. We set up automatic blocking filters - if there are a lot of such files, mail is blocked.
- They said a couple of people on the potential leak of the report, but it's just that the bookkeeping came into motion entirely and the system did not have time to learn.
- The customer somehow burned the first “combat” alarm himself - https traffic was wrapped up through some strange IP. It turned out that the finance department worked with bank clients who redirected the page to an external resource to assess browser compromise, and from there the traffic went right up to banking. It looked really strange, but talked with the bank, this is the norm.
- In one of the branches of a large company, they found an administrator who put the “left” software on his workstation, having disabled half of the information security systems before that. And they burned him on the fact that he downloaded another crack with the virus and managed to start spreading it along the internal segment of the network. The customer isolated the segment, and we did forensics.
- Caught a couple of comrades who use otchetki colleagues for their work. A colleague in Irkutsk, and here the hop - from the office works in his car. The mess. Or an account suddenly generated 10 thousand login attempts in a couple of minutes - some wrote a robot, but when changing passwords forgot to feed him a new account.
- Well, they spotted several attacks. A typical one looks like this: first, a letter came with a high suspicion of spam. Then the user turned to the website with a fresh domain registration. Then there is a pause, everything is calm. After 2 weeks at night, someone remotely connected and started downloading data from the file server. At this moment, an incident was created for manual processing, after 4 minutes only the “white sheet” filtering was turned on, then by morning we had a complete debriefing. Full automation was not used - it requires caution, because if there is a system that blocks everything, then the attack itself can go on it.
A couple more chips
A very good thing is to evaluate the model and collapse the heap of incidents to the root cause. For example, uplink failure between data centers is one big problem, not hundreds of mini-failures of workstations, servers and network equipment. Operators must understand, so most often done something like this:
- key business processes are predefined;
- a catalog of IT services is being created to ensure the work of business processes;
- for each IT service, its main components are determined: servers, network equipment, a set of application software;
- a resource-service model is constructed, which is a hierarchical graph, the nodes of which are key components, and the edges are the links between them.
Figure 3. Formation of a resource-service model
A very good thing is combining disparate incidents into a single kill chain. There are a number of stages that a hacker goes through when hacking infrastructure, from preparing for scanning to data theft and destroying logs. Signs of such activity can be monitored for months and entered into the user’s "card", which allows operators to quickly identify the "zero patient".
Figure 4. Killchain example
Security Evolution
In the end, it looks something like this:
And this is an example of a set of security systems that are interconnected within the framework of SOC and exchange data via SIEM:
By the way, if you are a beginner and have long wanted to work in the field of information security, we have something for you . We are looking for a junior manager to promote information security solutions. It will be necessary to understand both current solutions, and vendors and their products. Communicate with customers, make commercial offers and so on. In general, it will not be boring. For details, write to me by mail.
References
- We found a large company that has not been involved in information security for 5 years, and it is still alive.
- Football Stadium Safety: Some Implicit Features
- Micro-segmentation of networks in examples: how this cleverly twisted thing reacts to different attacks
- Targeted IT attacks in the field of large business: how it happens in Russia
- My mail is dberezin@croc.ru