About streams and tables in Kafka and Stream Processing, part 1
- Transfer
* Michael G. Noll — активный контрибьютор в Open Source проекты, в том числе в Apache Kafka и Apache Storm.
Статья будет полезна в первую очередь тем, кто только знакомится с Apache Kafka и/или потоковой обработкой [Stream Processing].
В этой статье, возможно, в первой из мини-серии, я хочу объяснить концепции Стримов [Streams] и Таблиц [Tables] в потоковой обработке и, в частности, в Apache Kafka. Надеюсь, у вас появится лучшее теоретическое представление и идеи, которые помогут вам решать ваши текущие и будущие задачи лучше и/или быстрее.
Содержание:
* Мотивация
* Стримы и Таблицы простым языком
* Иллюстрированные примеры
* Стримы и Таблицы в Kafka простым языком
* A close look at Kafka Streams, KSQL and analogues in Scala
* Tables are on the shoulders of giants (on streams)
* Turning the Database Inside-Out
* Conclusion
In my daily work, I communicate with many Apache Kafka users and those who are involved in streaming processing with Kafka through Kafka Streams and KSQL (streaming SQL for Kafka). Some users already have experience with streaming processing or using Kafka, some have experience using RDBMSs such as Oracle or MySQL, some have neither.
Frequently asked question: “What is the difference between Streams and Tables?” In this article I want to give both answers: both short (TL; DR) and long so that you can get a deeper understanding. Some of the explanations below will be slightly simplified because it simplifies understanding and memorization (for example, as a simpler Newton model of attraction is quite sufficient for most everyday situations, which saves us from having to go directly to the Einstein relativistic model, fortunately, stream processing does not so complicated).
Another common question: “Good, but why should it bother me? How will this help me in my daily work? ”In short, for many reasons! Once you start using streaming processing, you will soon realize that in practice in most cases both streams and tables are required . Tables, as I will explain later, represent state. Whenever you perform any processing with the state stateful processing like joins [ for example (for example, enriching data [ data enrichment ] in real time by combining the flow of facts with dimension tables [ dimension tables ]) Or aggregation [aggregations] (e.g., real-time calculation of the average values for key business metrics for 5 minutes), then the table is introduced picture stream [picture streaming] . Otherwise, it means that you will have to do it yourself [a lot of DIY pain] .
Even the notorious WordCount example, probably your first “Hello World” from this area, falls into the “state” category: this is an example of state processing, where we aggregate the stream of rows into a continuously updated table / map for word counting. This way, whether you are implementing simple WordCount streaming or something more complex like fraud detection, you want an easy-to-use solution for stream processing with basic data structures and everything you need inside (hint: streams and tables). Of course, you don’t want to build a complex and unnecessary architecture where you need to combine (only) streaming processing technology with remote storage, such as Cassandra or MySQL, and possibly with the addition of Hadoop / HDFS to provide fault tolerance processing [fault-tolerance processing ] (three things are too many).
Here is the best analogy I could come up with:
И как аперитив к будущему посту: если у вас есть доступ ко всей истории событий в мире (стрим), тогда вы можете восстановить состояние мира на любой момент времени, то есть таблицу в произвольное время
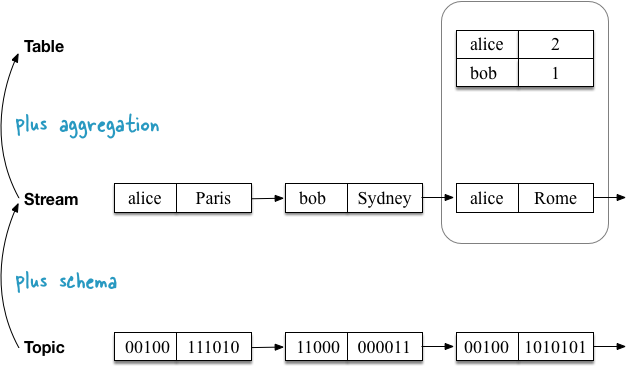
The first example shows a stream with the geolocation of users, which are aggregated into a table fixing the current (last) position of each user . As I will explain later, this also turns out to be the default semantics for tables when you read the Kafka [Topic] topic directly into the table.

The second use case demonstrates the same stream of user geolocation updates, but now the stream is aggregated into a table that records the number of places visited by each user . Since the aggregation function is different (here: counting the quantity), the contents of the table are also different. More precisely, other key values.

Before we dive into the details, let's start with a simple one.
The topic in Kafka is an unlimited sequence of key-value pairs. Keys and values are regular byte arrays, i.e.
Stream is a topic with the [schema] scheme . Keys and values are no longer byte arrays, but have certain types.
A table is a table in the usual sense of the word (I feel the joy of those of you who are already familiar with RDBMS and only get to know Kafka). But looking through the prism of stream processing, we see that the table is also an aggregated stream (you really did not expect us to stop at the definition of “table is a table”, right?).
Total:
Topics, streams and tables have the following properties in Kafka:
Let's see how topics, streams and tables relate to the Kafka Streams API and KSQL, and also draw analogies with programming languages (the analogies ignore, for example, that topics / streams / tables can be partitioned):
But this resume at this level may be of little use to you. So, let's take a closer look.
I will begin each of the following sections with an analogy in Scala (imagine that streaming is done on the same machine) and Scala REPL so that you can copy the code and play with it yourself, then I will explain how to do the same in Kafka Streams and KSQL (flexible, scalable and fault-tolerant streaming processing on distributed machines). As I mentioned at the beginning, I simplify the explanation below a bit. For example, I will not consider the impact of partitioning in Kafka.
The topic in Kafka consists of key-value messages. The topic does not depend on the serialization format or the “type” of messages: keys and values in messages are treated like regular byte arrays
Kafka Streams and KSQL do not have a “topic” concept. They only know about streams and tables. Therefore, I will show here only an analog topic in Scala.
Now we read the topic into the stream, adding information about the scheme (reading scheme [schema-on-read] ). In other words, we turn a raw, untyped topic into a "typed topic" or stream.
In Scala, this is achieved using the operation
In Kafka Streams you read the topic in
In KSQL, you should do something like the following to read the topic like
Now we are reading the same topic in the table. First, we need to add information about the circuit (read circuit). Secondly, you must convert the stream to a table. The semantics of the table in Kafka states that the final table should display each message key from the topic in the last value for this key.
Let's first use the first example, where the summary table tracks the last location of each user:
In Scala:
Adding information about the scheme is achieved by using the first operation
Что интересно касательно отношения между стримами и таблицами, так это то, что команда выше создаёт таблицу, эквивалентную короткому варианту ниже (помните о ссылочной прозрачности[referential transparency]), где мы строим таблицу напрямую из стрима, что позволяет нам пропустить задание схемы / типа, потому что стрим уже типизирован. Мы можем увидеть, что таблица является выводом [derivation], агрегацией стрима:
В Kafka Streams вы обычно используете
Но для наглядности вы также можете прочитать топик сперва в
In KSQL, you should do something like the following to read the topic like
What does this mean? This means that the table is actually an aggregate Stream [Aggregated, stream] , as we said at the beginning. We saw this directly in the special case above, when the table was created directly from the topic. However, this is actually a common case.
Conceptually, only a stream is a first-order data construct in Kafka. On the other hand, a table is either (1) derived from an existing stream through per-key aggregation, or (2) removed from an existing stream, which is always expanded to an aggregated stream (we could call the last tables “proto-streams” [ "Ur-stream"] ).
Of the two cases, (1) is more interesting for discussion, so let's focus on this. And that probably means I need to first figure out how aggregations work in Kafka.
Aggregations are one type of streaming processing. Other types, for example, include filtering [filters] and joins [joins] .
As we found out earlier, the data in Kafka are presented as key-value pairs. Further, the first property of aggregations in Kafka is that they are all computed by key . That is why we must group
The second property of aggregations in Kafka is that aggregations are continuously updated as new data arrives in incoming streams. Together with the property of computing by key, this requires a table or, more precisely, it requires a mutable table as a result and, therefore, of the type of aggregations returned. Previous values (aggregation results) for a key are constantly overwritten with new values. In both Kafka Streams and KSQL, aggregations always return a table.
Returning to our second example, in which we want to calculate the flow quantity we visited each user places:
Calculation [counting]Is a type of aggregation. To calculate the values, we only need to replace the aggregation stage from the previous section
Kafka Streams code equivalent to the Scala example above:
In KSQL:
As we saw above, tables are aggregations of their input streams or, in short, tables are aggregated streams. Whenever you perform aggregation in Kafka Streams or KSQL, the result is always a table.
The peculiarity of the aggregation stage determines whether the table is directly obtained from the stream through stateless UPSERT semantics (the table maps the keys to their last value in the stream, which is aggregation when reading the Kafka topic directly to the table), by counting the number of values seen for each key with saving state [stateful counting](see our last example), or more complex aggregations, such as summation, averaging, and so on. When using Kafka Streams and KSQL you have many options for aggregation, including aggregation window [windowed aggregations] with "flips" windows [tumbling windows], «jumping» windows [hopping windows] and "session" window [session windows].
Although the tables are an aggregation of the input stream, it also has its own output stream! Like recording change data (CDC) in databases, every change in a table in Kafka is recorded in an internal change stream called changelog stream of the table. A lot of the calculations in Kafka Streams and KSQL are actually done on changelog stream . This allows Kafka Streams and KSQL, for example, to correctly process historical data in accordance with the event-time processing semantics semantics - remember that a stream represents both the present and the past, while a table can only represent the present (or, more exactly, fixed point in time [snapshot in time] ).
Here is the first example, but with changelog stream :

Note that the changelog stream of the table is a copy of the input stream of this table. This is due to the nature of the corresponding aggregation function (UPSERT). And if you are wondering: “Wait, isn't that a 1 to 1 copy that consumes disk space?” - Under the hood of Kafka Streams and KSQL, optimization is performed to minimize unnecessary data copying and local / network IO. I ignore these optimizations in the diagram above to better illustrate what is basically happening.
And finally, a second use case, including changelog stream . Here the stream of table changes is different, because here is another aggregation function that performs the key[per-key] counting.

But these internal changelog streams also have an architectural and operational influence. Stream changes continuously backup and stored as topic in Kafka, topic and thus are part of magic, which provides elasticity [elasticity] and resiliency in Kafka Streams and KSQL. This is due to the fact that they allow you to move processing tasks between machines / virtual machines / containers without losing data and throughout all operations, regardless of processing with a state of [stateful] or without [stateless] . The table is part of the [state] stateyour application (Kafka Streams) or query (KSQL), so it’s mandatory for Kafka to transfer not only processing code (which is easy), but also processing status, including tables, between machines in a fast and reliable way (which is much more complicated). Whenever a table needs to be moved from client machine A to machine B, then on a new destination B, the table is reconstructed from its changelog stream to Kafka (server side) exactly the same state as it was on machine A. We can see this on the last diagram above, where the “ counting table” can be easily retrieved from its changelog stream without the need to process the input stream.
The term stream-table duality refers to the above relationship between streams and tables. This means, for example, that you can turn a stream into a table, this table into another stream, the resulting stream into another table, and so on. For more information, see the Confluent: Introducing Kafka Streams: Stream Processing Made Simple blog post .
In addition to what we covered in the previous sections, you may have come across the Turning the Database Inside-Out article , and now you might be interested to take a look at this whole? Since I don’t want to go into details now, let me briefly compare the world of Kafka and streaming processing with the world of databases. Be vigilant: further serious simplifications [black-and-white simplifications] .
In databases, a table is a first-order construct. This is what you work with. "Streams" also exist in databases, for example, in the form of binlog in MySQL or GoldenGate in Oraclebut they are usually hidden from you in the sense that you cannot interact with them directly. The database knows about the present, but it does not know about the past (if you need the past, restore the data from your backup tapes , which, haha, are just hardware streams).
In Kafka and stream processing, a stream is a first-order construction. Tables are derivatives of streams , as we saw before. Stream knows about the present and the past. As an example, the New York Times keeps all published articles - 160 years of journalism from the 1850s - in Kafka, the source of reliable data [-source of truth] .
In short: the database thinks first with a table, and then with a stream. Kafka thinks first with a stream, and then with a table. Nevertheless, the Kafka community realized that in most cases of practical use of streaming, streams and tables are required - even in the notorious but simple WordCount, which aggregates a stream of text strings into a table with word counts, as in our second example of use higher. Consequently, Kafka helps us connect the worlds of streaming processing and databases, providing native support for streams and tables through Kafka Streams and KSQL to save us from a lot of problems (and pager warnings). We could call Kafka and type strimingovoy platform, which it is thread-safe relational [, stream-relational] , and not only strimingovoy [stream-only].
I hope you find these explanations useful in order to better understand streams and tables in Kafka and stream processing in general. Now that we’ve finished with the details, you can return to the beginning of the article and re-read the sections “Streams and Tables in Simple Language” and “Streams and Tables in Kafka in Simple Language” once again.
If you were interested in trying thread-relational processing with Kafka, Kafka Streams, and KSQL in this article, you can continue to explore:
Regardless of whether you use Kafka Streams or KSQL, thanks to Kafka you get flexible, scalable and fault-tolerant distributed streaming processing that works everywhere (containers, virtual machines, machines, locally, at the customer, in the clouds, your option). I’ll just say if this is not obvious. :-)
Finally, I called this article “Streams and Tables, Part 1”. And although I already have ideas for the second part, I will be grateful for questions and suggestions on what I could consider next time. What do you want to know more about? Let me know in the comments or email me!
If you notice an inaccuracy in the translation, please write in a personal message or leave a comment.
Статья будет полезна в первую очередь тем, кто только знакомится с Apache Kafka и/или потоковой обработкой [Stream Processing].
В этой статье, возможно, в первой из мини-серии, я хочу объяснить концепции Стримов [Streams] и Таблиц [Tables] в потоковой обработке и, в частности, в Apache Kafka. Надеюсь, у вас появится лучшее теоретическое представление и идеи, которые помогут вам решать ваши текущие и будущие задачи лучше и/или быстрее.
Содержание:
* Мотивация
* Стримы и Таблицы простым языком
* Иллюстрированные примеры
* Стримы и Таблицы в Kafka простым языком
* A close look at Kafka Streams, KSQL and analogues in Scala
* Tables are on the shoulders of giants (on streams)
* Turning the Database Inside-Out
* Conclusion
Motivation, or why should it care?
In my daily work, I communicate with many Apache Kafka users and those who are involved in streaming processing with Kafka through Kafka Streams and KSQL (streaming SQL for Kafka). Some users already have experience with streaming processing or using Kafka, some have experience using RDBMSs such as Oracle or MySQL, some have neither.
Frequently asked question: “What is the difference between Streams and Tables?” In this article I want to give both answers: both short (TL; DR) and long so that you can get a deeper understanding. Some of the explanations below will be slightly simplified because it simplifies understanding and memorization (for example, as a simpler Newton model of attraction is quite sufficient for most everyday situations, which saves us from having to go directly to the Einstein relativistic model, fortunately, stream processing does not so complicated).
Another common question: “Good, but why should it bother me? How will this help me in my daily work? ”In short, for many reasons! Once you start using streaming processing, you will soon realize that in practice in most cases both streams and tables are required . Tables, as I will explain later, represent state. Whenever you perform any processing with the state stateful processing like joins [ for example (for example, enriching data [ data enrichment ] in real time by combining the flow of facts with dimension tables [ dimension tables ]) Or aggregation [aggregations] (e.g., real-time calculation of the average values for key business metrics for 5 minutes), then the table is introduced picture stream [picture streaming] . Otherwise, it means that you will have to do it yourself [a lot of DIY pain] .
Even the notorious WordCount example, probably your first “Hello World” from this area, falls into the “state” category: this is an example of state processing, where we aggregate the stream of rows into a continuously updated table / map for word counting. This way, whether you are implementing simple WordCount streaming or something more complex like fraud detection, you want an easy-to-use solution for stream processing with basic data structures and everything you need inside (hint: streams and tables). Of course, you don’t want to build a complex and unnecessary architecture where you need to combine (only) streaming processing technology with remote storage, such as Cassandra or MySQL, and possibly with the addition of Hadoop / HDFS to provide fault tolerance processing [fault-tolerance processing ] (three things are too many).
Streams and Tables in plain language
Here is the best analogy I could come up with:
- Stream in Kafka is a complete history of all the events that happened (or just business events) in the world from the beginning of time to the present . He represents the past and the present. As we move from today to tomorrow, new events are constantly being added to world history.
- The table in Kafka is the state of the world today . She represents the present. This is the aggregation of all events in the world, which is constantly changing as we move from today to tomorrow.
И как аперитив к будущему посту: если у вас есть доступ ко всей истории событий в мире (стрим), тогда вы можете восстановить состояние мира на любой момент времени, то есть таблицу в произвольное время
t в потоке, где t не ограничивается только t=сейчас. Другими словами, мы можем создавать «снимки» [snapshots] состояния мира (таблицу) на любой момент времени t, например, 2560 г. до н.э., когда была построена Великая Пирамида в Гизе, или 1993 год, когда был основан Европейский Союз.Иллюстрированные примеры
The first example shows a stream with the geolocation of users, which are aggregated into a table fixing the current (last) position of each user . As I will explain later, this also turns out to be the default semantics for tables when you read the Kafka [Topic] topic directly into the table.
The second use case demonstrates the same stream of user geolocation updates, but now the stream is aggregated into a table that records the number of places visited by each user . Since the aggregation function is different (here: counting the quantity), the contents of the table are also different. More precisely, other key values.
Streams and Tables in Kafka in Simple Language
Before we dive into the details, let's start with a simple one.
The topic in Kafka is an unlimited sequence of key-value pairs. Keys and values are regular byte arrays, i.e.
Stream is a topic with the [schema] scheme . Keys and values are no longer byte arrays, but have certain types.
Example: atopic is read as astream of users' geolocation.
A table is a table in the usual sense of the word (I feel the joy of those of you who are already familiar with RDBMS and only get to know Kafka). But looking through the prism of stream processing, we see that the table is also an aggregated stream (you really did not expect us to stop at the definition of “table is a table”, right?).
Example: astream withlocation updates is aggregated into a table that tracks the user's last position. At the aggregation stage, [UPSERT] values in the table are updated by the key from the input stream. We saw this in the first illustrated example above.
Example: astream is aggregated into atable that tracks the number of visited locations for each user. At the aggregation stage, values for the keys in the table are continuously calculated (and updated). We saw this in the second illustrated example above.
Total:
Topics, streams and tables have the following properties in Kafka:
| A type | There are partitions | Is not limited | There is an order | Changeable | Key uniqueness | Scheme |
|---|---|---|---|---|---|---|
| Topic | Yes | Yes | Yes | Not | Not | Not |
| Stream | Yes | Yes | Yes | Not | Not | Yes |
| Table | Yes | Yes | Not | Yes | Yes | Yes |
Let's see how topics, streams and tables relate to the Kafka Streams API and KSQL, and also draw analogies with programming languages (the analogies ignore, for example, that topics / streams / tables can be partitioned):
| A type | Kafka streams | KSQL | Java | Scala | Python |
|---|---|---|---|---|---|
| Topic | - | - | List / Stream | List / Stream [(Array[Byte], Array[Byte])] | [] |
| Stream | KStream | STREAM | List / Stream | List / Stream [(K, V)] | [] |
| Table | KTable | TABLE | HashMap | mutable.Map[K, V] | {} |
But this resume at this level may be of little use to you. So, let's take a closer look.
A closer look at Kafka Streams, KSQL, and Scala counterparts
I will begin each of the following sections with an analogy in Scala (imagine that streaming is done on the same machine) and Scala REPL so that you can copy the code and play with it yourself, then I will explain how to do the same in Kafka Streams and KSQL (flexible, scalable and fault-tolerant streaming processing on distributed machines). As I mentioned at the beginning, I simplify the explanation below a bit. For example, I will not consider the impact of partitioning in Kafka.
If you do not know Scala: Do not be embarrassed! You do not need to understand Scala analogues in every detail. It is enough to pay attention to what operations (for example,map()) are joined together, what they are (for example, itreduceLeft()represents aggregation), and how the “chain” of streams correlates with the “chain” of tables.
Topics
The topic in Kafka consists of key-value messages. The topic does not depend on the serialization format or the “type” of messages: keys and values in messages are treated like regular byte arrays
byte[]. In other words, from this point of view, we have no idea what is inside the data. Kafka Streams and KSQL do not have a “topic” concept. They only know about streams and tables. Therefore, I will show here only an analog topic in Scala.
// Scala analogy
scala> val topic: Seq[(Array[Byte], Array[Byte])] = Seq((Array(97, 108, 105, 99, 101),Array(80, 97, 114, 105, 115)), (Array(98, 111, 98),Array(83, 121, 100, 110, 101, 121)), (Array(97, 108, 105, 99, 101),Array(82, 111, 109, 101)), (Array(98, 111, 98),Array(76, 105, 109, 97)), (Array(97, 108, 105, 99, 101),Array(66, 101, 114, 108, 105, 110)))Streams
Now we read the topic into the stream, adding information about the scheme (reading scheme [schema-on-read] ). In other words, we turn a raw, untyped topic into a "typed topic" or stream.
Reading Scheme vs Writing Schema [schema-on-write] : Kafka and its topics are independent of the serialization format of your data. Therefore, you must specify the scheme when you want to read the data in a stream or table. This is called a reading scheme . The reading scheme has both pros and cons. Fortunately, you can choose the intermediate between the read scheme and the write scheme by defining a contract for your data - just like you probably define API contracts in your applications and services. This can be achieved by choosing a structured, but extensible data format, such as Apache Avro, with a registry deployment for your Avro schemes, such as the Confluent Schema Registry. And yes, both Kafka Streams and KSQL support Avro, if you're interested.
In Scala, this is achieved using the operation
map()below. In this example, we get a stream of pairs // Scala analogy
scala> val stream = topic
| .map { case (k: Array[Byte], v: Array[Byte]) => new String(k) -> new String(v) }
// => stream: Seq[(String, String)] =
// List((alice,Paris), (bob,Sydney), (alice,Rome), (bob,Lima), (alice,Berlin))In Kafka Streams you read the topic in
KStreamvia StreamsBuilder#stream(). Here you must determine the desired scheme using the parameter Consumed.with()when reading data from the topic:StreamsBuilder builder = new StreamsBuilder();
KStream stream =
builder.stream("input-topic", Consumed.with(Serdes.String(), Serdes.String())); In KSQL, you should do something like the following to read the topic like
STREAM. Here you define the desired scheme by specifying the names and types of columns when reading data from the topic:CREATE STREAM myStream (username VARCHAR, location VARCHAR)
WITH (KAFKA_TOPIC='input-topic', VALUE_FORMAT='...')Tables
Now we are reading the same topic in the table. First, we need to add information about the circuit (read circuit). Secondly, you must convert the stream to a table. The semantics of the table in Kafka states that the final table should display each message key from the topic in the last value for this key.
Let's first use the first example, where the summary table tracks the last location of each user:
In Scala:
// Scala analogy
scala> val table = topic
| .map { case (k: Array[Byte], v: Array[Byte]) => new String(k) -> new String(v) }
| .groupBy(_._1)
| .map { case (k, v) => (k, v.reduceLeft( (aggV, newV) => newV)._2) }
// => table: scala.collection.immutable.Map[String,String] =
// Map(alice -> Berlin, bob -> Lima)Adding information about the scheme is achieved by using the first operation
map()- exactly the same as in the example with the stream above. The stream is converted to the [stream-to-table] table using the aggregation step (more on this later), which in this case is a UPSERT operation (without state) on the table: this is the step groupBy().map()that contains the operation reduceLeft()for each key. Aggregation means that for each key, we compress many values into one. Please note that this particular reduceLeft()stateless aggregation - the previous aggV value is not used when calculating the new value for the given key.Что интересно касательно отношения между стримами и таблицами, так это то, что команда выше создаёт таблицу, эквивалентную короткому варианту ниже (помните о ссылочной прозрачности[referential transparency]), где мы строим таблицу напрямую из стрима, что позволяет нам пропустить задание схемы / типа, потому что стрим уже типизирован. Мы можем увидеть, что таблица является выводом [derivation], агрегацией стрима:
// Scala analogy, simplified
scala> val table = stream
| .groupBy(_._1)
| .map { case (k, v) => (k, v.reduceLeft( (aggV, newV) => newV)._2) }
// => table: scala.collection.immutable.Map[String,String] =
// Map(alice -> Berlin, bob -> Lima)В Kafka Streams вы обычно используете
StreamsBuilder#table() для чтения топика Kafka в KTable простым однострочником:KTable table = builder.table("input-topic", Consumed.with(Serdes.String(), Serdes.String())); Но для наглядности вы также можете прочитать топик сперва в
KStream, а затем выполнить такой же этап агрегации, как показано выше, чтобы превратить KStream в KTable.KStream stream = ...;
KTable table = stream
.groupByKey()
.reduce((aggV, newV) -> newV); In KSQL, you should do something like the following to read the topic like
TABLE. Here you must determine the desired scheme by specifying the names and types for the columns when reading from the topic:CREATE TABLE myTable (username VARCHAR, location VARCHAR)
WITH (KAFKA_TOPIC='input-topic', KEY='username', VALUE_FORMAT='...')What does this mean? This means that the table is actually an aggregate Stream [Aggregated, stream] , as we said at the beginning. We saw this directly in the special case above, when the table was created directly from the topic. However, this is actually a common case.
Tables stand on the shoulders of giants (on streams)
Conceptually, only a stream is a first-order data construct in Kafka. On the other hand, a table is either (1) derived from an existing stream through per-key aggregation, or (2) removed from an existing stream, which is always expanded to an aggregated stream (we could call the last tables “proto-streams” [ "Ur-stream"] ).
Tables are often also described as a materialized view of a stream. Streaming is nothing more than aggregation in this context.
Of the two cases, (1) is more interesting for discussion, so let's focus on this. And that probably means I need to first figure out how aggregations work in Kafka.
Aggregations in Kafka
Aggregations are one type of streaming processing. Other types, for example, include filtering [filters] and joins [joins] .
As we found out earlier, the data in Kafka are presented as key-value pairs. Further, the first property of aggregations in Kafka is that they are all computed by key . That is why we must group
KStreambefore the aggregation phase in Kafka Streams through groupBy()or groupByKey(). For the same reason, we had to use groupBy()in the examples on Scala above.Partitsirovanie [partition] and key messages: Another important aspect of The Kafka, which I ignore in this article, is that the topics, and the stream table partitsirovany . In fact, the data is processed and aggregated by key by partition. By default, messages / records are distributed among partitions based on their keys; therefore, in practice, simplifying “key aggregation” instead of the technically more complex and more correct “partition by key partitioning” is perfectly acceptable. But if you are using a custom partitioning assigners algorithm , then you should consider this in your processing logic.
The second property of aggregations in Kafka is that aggregations are continuously updated as new data arrives in incoming streams. Together with the property of computing by key, this requires a table or, more precisely, it requires a mutable table as a result and, therefore, of the type of aggregations returned. Previous values (aggregation results) for a key are constantly overwritten with new values. In both Kafka Streams and KSQL, aggregations always return a table.
Returning to our second example, in which we want to calculate the flow quantity we visited each user places:
Calculation [counting]Is a type of aggregation. To calculate the values, we only need to replace the aggregation stage from the previous section
.reduce((aggV, newV) -> newV)with .map { case (k, v) => (k, v.length) }. Please note that the return type is a table / map (and please ignore the fact that the code in Scala is mapimmutable [immutable map] , because Scala uses immutable by default map).// Scala analogy
scala> val visitedLocationsPerUser = stream
| .groupBy(_._1)
| .map { case (k, v) => (k, v.length) }
// => visitedLocationsPerUser: scala.collection.immutable.Map[String,Int] =
// Map(alice -> 3, bob -> 2)Kafka Streams code equivalent to the Scala example above:
KTable visitedLocationsPerUser = stream
.groupByKey()
.count(); In KSQL:
CREATE TABLE visitedLocationsPerUser AS
SELECT username, COUNT(*)
FROM myStream
GROUP BY username;Tables - aggregated streams (input stream → table)
As we saw above, tables are aggregations of their input streams or, in short, tables are aggregated streams. Whenever you perform aggregation in Kafka Streams or KSQL, the result is always a table.
The peculiarity of the aggregation stage determines whether the table is directly obtained from the stream through stateless UPSERT semantics (the table maps the keys to their last value in the stream, which is aggregation when reading the Kafka topic directly to the table), by counting the number of values seen for each key with saving state [stateful counting](see our last example), or more complex aggregations, such as summation, averaging, and so on. When using Kafka Streams and KSQL you have many options for aggregation, including aggregation window [windowed aggregations] with "flips" windows [tumbling windows], «jumping» windows [hopping windows] and "session" window [session windows].
There are change streams in tables (table → output stream)
Although the tables are an aggregation of the input stream, it also has its own output stream! Like recording change data (CDC) in databases, every change in a table in Kafka is recorded in an internal change stream called changelog stream of the table. A lot of the calculations in Kafka Streams and KSQL are actually done on changelog stream . This allows Kafka Streams and KSQL, for example, to correctly process historical data in accordance with the event-time processing semantics semantics - remember that a stream represents both the present and the past, while a table can only represent the present (or, more exactly, fixed point in time [snapshot in time] ).
Примечание: В Kafka Streams вы можете явно преобразовывать таблицу в стрим изменений [changelog stream] через KTable#toStream().Here is the first example, but with changelog stream :
Note that the changelog stream of the table is a copy of the input stream of this table. This is due to the nature of the corresponding aggregation function (UPSERT). And if you are wondering: “Wait, isn't that a 1 to 1 copy that consumes disk space?” - Under the hood of Kafka Streams and KSQL, optimization is performed to minimize unnecessary data copying and local / network IO. I ignore these optimizations in the diagram above to better illustrate what is basically happening.
And finally, a second use case, including changelog stream . Here the stream of table changes is different, because here is another aggregation function that performs the key[per-key] counting.
But these internal changelog streams also have an architectural and operational influence. Stream changes continuously backup and stored as topic in Kafka, topic and thus are part of magic, which provides elasticity [elasticity] and resiliency in Kafka Streams and KSQL. This is due to the fact that they allow you to move processing tasks between machines / virtual machines / containers without losing data and throughout all operations, regardless of processing with a state of [stateful] or without [stateless] . The table is part of the [state] stateyour application (Kafka Streams) or query (KSQL), so it’s mandatory for Kafka to transfer not only processing code (which is easy), but also processing status, including tables, between machines in a fast and reliable way (which is much more complicated). Whenever a table needs to be moved from client machine A to machine B, then on a new destination B, the table is reconstructed from its changelog stream to Kafka (server side) exactly the same state as it was on machine A. We can see this on the last diagram above, where the “ counting table” can be easily retrieved from its changelog stream without the need to process the input stream.
Duality Stream Table
The term stream-table duality refers to the above relationship between streams and tables. This means, for example, that you can turn a stream into a table, this table into another stream, the resulting stream into another table, and so on. For more information, see the Confluent: Introducing Kafka Streams: Stream Processing Made Simple blog post .
Turning the Database Inside-Out
In addition to what we covered in the previous sections, you may have come across the Turning the Database Inside-Out article , and now you might be interested to take a look at this whole? Since I don’t want to go into details now, let me briefly compare the world of Kafka and streaming processing with the world of databases. Be vigilant: further serious simplifications [black-and-white simplifications] .
In databases, a table is a first-order construct. This is what you work with. "Streams" also exist in databases, for example, in the form of binlog in MySQL or GoldenGate in Oraclebut they are usually hidden from you in the sense that you cannot interact with them directly. The database knows about the present, but it does not know about the past (if you need the past, restore the data from your backup tapes , which, haha, are just hardware streams).
In Kafka and stream processing, a stream is a first-order construction. Tables are derivatives of streams , as we saw before. Stream knows about the present and the past. As an example, the New York Times keeps all published articles - 160 years of journalism from the 1850s - in Kafka, the source of reliable data [-source of truth] .
In short: the database thinks first with a table, and then with a stream. Kafka thinks first with a stream, and then with a table. Nevertheless, the Kafka community realized that in most cases of practical use of streaming, streams and tables are required - even in the notorious but simple WordCount, which aggregates a stream of text strings into a table with word counts, as in our second example of use higher. Consequently, Kafka helps us connect the worlds of streaming processing and databases, providing native support for streams and tables through Kafka Streams and KSQL to save us from a lot of problems (and pager warnings). We could call Kafka and type strimingovoy platform, which it is thread-safe relational [, stream-relational] , and not only strimingovoy [stream-only].
The database thinks first with a table, and then with a stream. Kafka thinks first with a stream, and then with a table.
Conclusion
I hope you find these explanations useful in order to better understand streams and tables in Kafka and stream processing in general. Now that we’ve finished with the details, you can return to the beginning of the article and re-read the sections “Streams and Tables in Simple Language” and “Streams and Tables in Kafka in Simple Language” once again.
If you were interested in trying thread-relational processing with Kafka, Kafka Streams, and KSQL in this article, you can continue to explore:
- Изучение того, как использовать KSQL, стриминговый SQL-движок для Kafka, для обработки данных в Kafka без написания какого-либо кода. Это то, что я рекомендовал бы в качестве отправной точки, особенно если вы новичок в Kafka или потоковой обработке, поскольку вы должны приступить к работе в считанные минуты. Также есть замечательная демка с KSQL clickstream (включая вариант с Docker), где вы можете поиграться с Kafka, KSQL, Elasticsearch и Grafana для создания и настройки real-time dashboard.
- Изучение того, как создавать Java или Scala приложения для потоковой обработки с использованием Kafka Streams API.
- И да, вы, конечно, можете объединить их, например вы можете начать обработку ваших данных с использованием KSQL, затем продолжить работу с Kafka Streams, а затем опять вернуться к KSQL.
Regardless of whether you use Kafka Streams or KSQL, thanks to Kafka you get flexible, scalable and fault-tolerant distributed streaming processing that works everywhere (containers, virtual machines, machines, locally, at the customer, in the clouds, your option). I’ll just say if this is not obvious. :-)
Finally, I called this article “Streams and Tables, Part 1”. And although I already have ideas for the second part, I will be grateful for questions and suggestions on what I could consider next time. What do you want to know more about? Let me know in the comments or email me!
If you notice an inaccuracy in the translation, please write in a personal message or leave a comment.