Overview of the first day of Data Science Weekend 2018. The practice of machine learning, a new approach to competitions and much more
Hello, Habr! On March 2-3, the attic of our partners, the company Rambler & Co, hosted the traditional Data Science Weekend , where there were many presentations by specialists in the field of working with data. As part of this article, we will tell you about the most interesting moments of the first day of our conference, when all the attention was paid to the practice of using machine learning algorithms, team management and conducting competitions in the field of Data Science.

Open Data Science Weekend 2018 has the honor of graduating from our Big Data Specialist program , Roman Smirnov, from VectorX, a company that processes information distribution in the company and configures the information field. As part of his speech, Roman spoke about why it is so difficult to work with a team of data scientists and how to make their work as efficient as possible.
Based on my experience, there are 4 main problems that the company faces when working with data scientists (we will call them experts):
Problem: unpredictable performance caused by high demand for expertise.The expert does not belong to you, but to society, because he is a scientist and uses his knowledge to make us all healthier and richer. It turns out that they just want him all, but he doesn't give a damn about everyone. From this are possible problems with motivation and labor efficiency.
Solution: firstly, there should always be an alternative in the form of another expert, whose existence must remain a secret. Secondly, it is necessary to keep a record of all projects, collect statistics in order to give the expert feedback and maintain a sense of personal worth. Finally, it turned out that CRM is good not only for customers, but also when working with distributed teams.
Problem: Conflict of motivation.Data scientist is a person who tries to convince everyone that he is a pioneer, deals with critical issues, tries to discover the secret of the philosopher's stone. Unfortunately, basic physiological motives are not alien to him, and this conflict does not allow him to prioritize, but to you - to conclude a favorable agreement with him.
Solution: this dualism can be used for your own purposes. If the expert says that he does not have enough money, you can call on his humanistic values and say: "My friend, you are a scientist!" And vice versa: it is worth reminding him that he is a person in status and that he should not go for a year in a suit with patches on his elbows.

Problem: spec speculation.It often happens that an indisputably experienced theorist is not able to solve a trivial practical problem. Consequently, he cannot soberly assess the complexity of the project with all the consequences: failed deadlines, loss of motivation by the team, exorbitant costs, etc.
Solution: request a portfolio from a potential project manager and do not hesitate to spend money on code review to confirm or dispel concerns.
Problem: ulterior motives. An expert, as a scientist, wants to become above society, and not in its ranks. Therefore, he always has a desire to popularize his opinion in the widest possible range of areas of knowledge, which, however, does not correlate well with the commercial benefits of the project: if something threatens the reputation of an expert in the company, then there is a risk of losing it.
Solution: today science is very closely intertwined with business: a couple of years ago no one even thought that marketing would extend to scientific articles. Co-sponsor the writing of scientific articles - for science-intensive projects, this is an excellent marketing move.
And in the event of a threat of loss of expertise, hire an expert from a competing laboratory. Such an act can offend the first scientist and stimulates him to take action to wipe his nose with a competitor.
Then it was the turn of another of our graduates, Alexander Ulyanov, who is the Data science executive director at Sberbank. Using an example of a cash management project in an ATM network across the country, he talked about why, instead of immediately attacking complex models and trying to build them, you must first sit down and thoroughly conduct statistical data analysis. This is extremely important when working with real data, because they often have a large number of omissions, outliers, incorrect measurements and banal errors in recording information, so each data scientist must, for example, have statistical methods for detecting anomalies or at least be able to look at the number zeros in the dataset, maximum and minimum values of features. The principle of "garbage in - garbage out" has not been canceled.

You can soon read more about Alexander’s speech and the case for managing an ATM network in the corporate blog of Sberbank on Habré. Wait!
Further, Artem Pichugin, Head of educational programs for working with data at Newprolab, introduced a new approach to the conduct of machine learning competitions, which will be tested on the upcoming program "Big Data Specialist 8.0" . The start of the program is March 22.
It all started in 2009 with a competition from Netflix, in which the winner received $ 1 million, which made these events popular, Kaggle appeared and it all started to develop rapidly. However, it turned out that from the very beginning everything went wrong: in 2012 it turned out that the decision of the winner of the contest from Netflix was simply impossible to implement in production, it was too complicated and difficult.
Several years have passed, and what do we see? It's 2018, and people are still trying to make super complex models, they are building huge ensembles. And it more and more resembles a sport of high achievements.
Of course, on the program, we also used this approach, ranking students by a certain metric, regardless of the complexity of their decision. However, realizing how far all these decisions can be from the business, we take a completely new approach to competition in the program.
Now the final rating will take into account only those solutions that are suitable for SLA, that is, fit into some reasonable period of time. Moreover, unlike some other approaches, not the total model training time, buthow quickly the forecast is calculated for one element of the test sample.
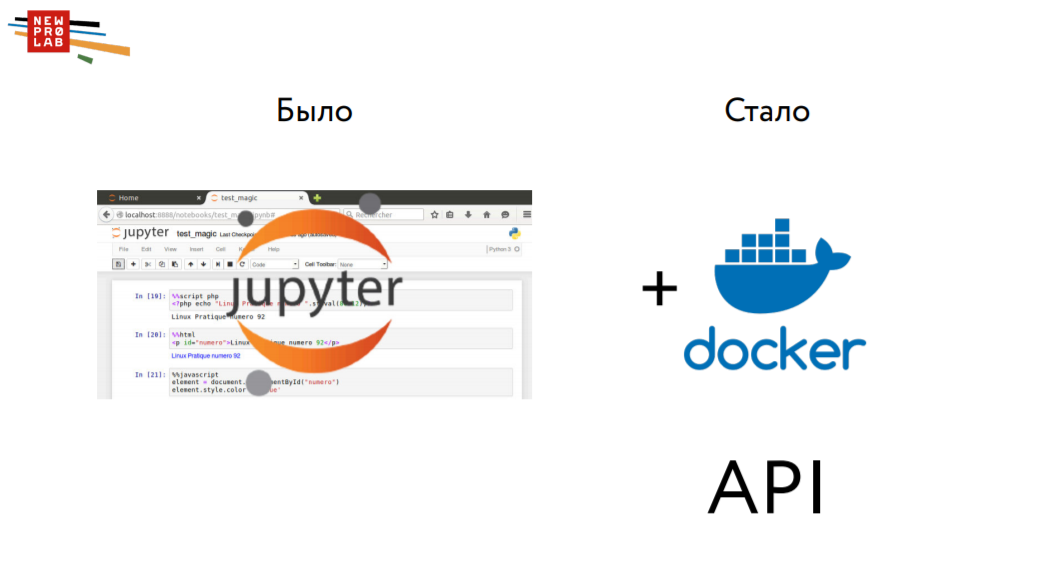
Previously, a person made a model in a Jupyter Notebook, made a forecast for a test sample, saved, sent and calculated the final metric. Now, he needs to pack this model into Docker, that is, make a small “cookie”, having received a JSON file . Thus, we will become closer to production and urge everyone who organizes competitions and hackathons to move in this direction.
By the way, in the next few months we will hold our hackathon. Subscribe to us on Facebook and Telegram so as not to miss information!
Now let's talk about the group presentation of machine learning specialists from Rambler & Co, who sorted out an interesting case on the use of computer vision in cinema halls to recognize the number, gender and age of cinema visitors.
We were tasked with assessing the composition of the audience at sessions in a network of cinemas in order to report to advertisers who need to understand the socio-demographic composition of the audience and who give us money for one or another advertisement shown before the sessions.
Let's start with data sources.. It would seem that we have a Rambler-Cashier, therefore we have a lot of information about users, however, according to these data, the estimate will actually be biased. For family viewing, tickets are bought by dad or mom, if this is a couple, then most likely a guy will buy them and so on. Therefore, we were able to find another solution: in each room there is a camera that sees everyone who sits in the cinema:
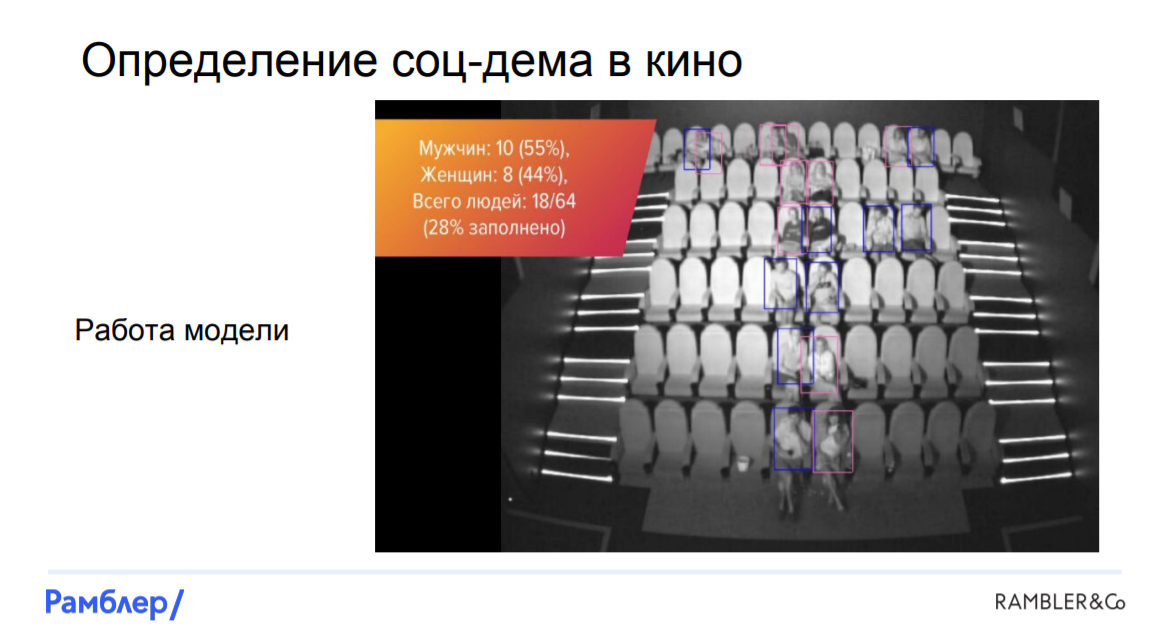
Looking ahead, we say that we managed to build a model that estimates from photographs who is sitting where, gender and age of visitors. We were able to determine the number of people with almost 100% accuracy, distinguish men from women with 90%, and recognize children with a slightly lower probability. How did we do it?
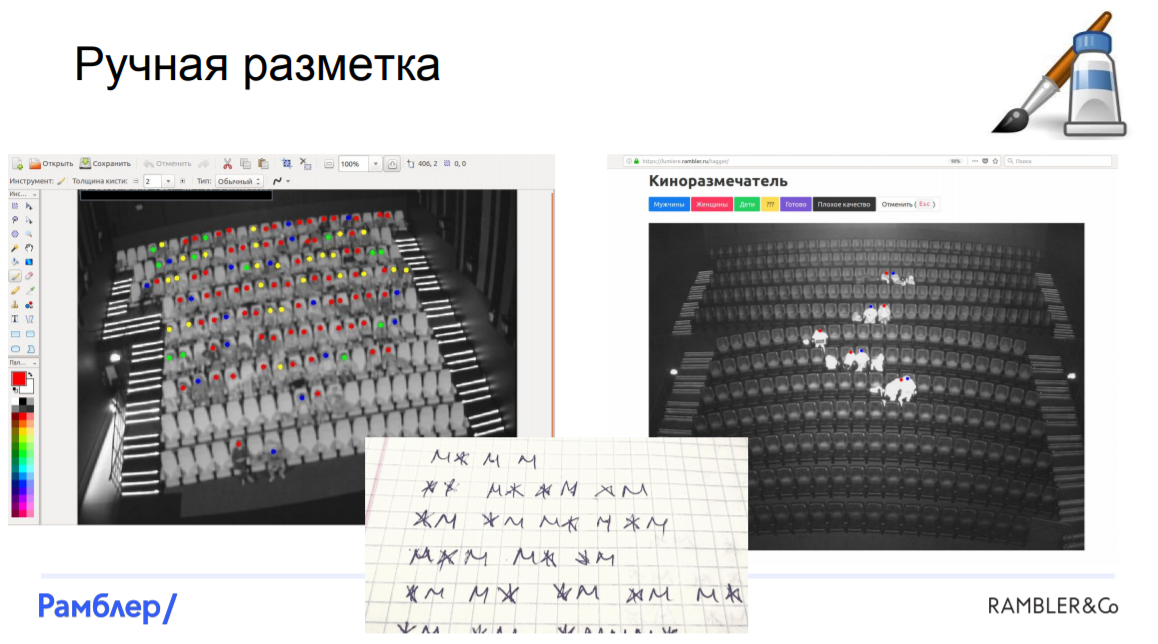
Markup data.From the very beginning, we ran into a bunch of problems. First of all, it is very difficult to find at least two similar cinema halls, they are all different, with different scales and perspectives. There are cameras that do not capture the entire hall, shoot at an angle. We add to this a different illumination of the hall, depending on what is happening on the screen at the time of shooting, and it turns out that we have data of different quality, which is simply impossible to mark up automatically.
We had to resort to manual marking. It was very expensive, difficult, took up most of the working time, so we decided to hire a team of “elite markers” from the outside - people who would normally and thoroughly mark up the data. Of course, it is impossible to exclude the human factor, there were a number of errors, but in the end we still managed to mark all the photos and we were ready to build models.
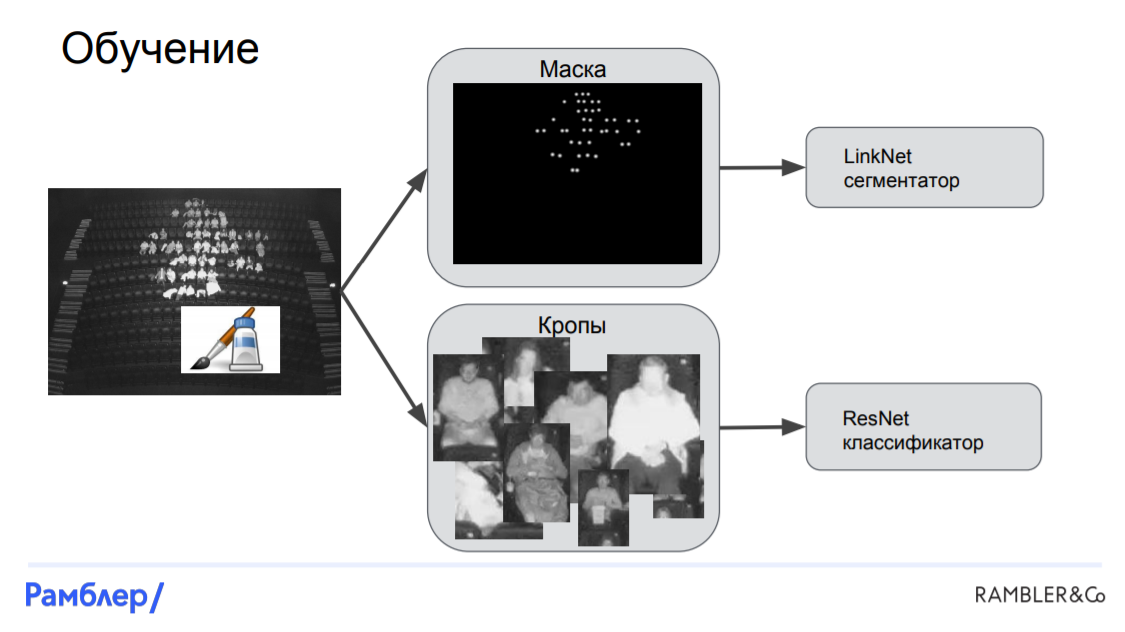
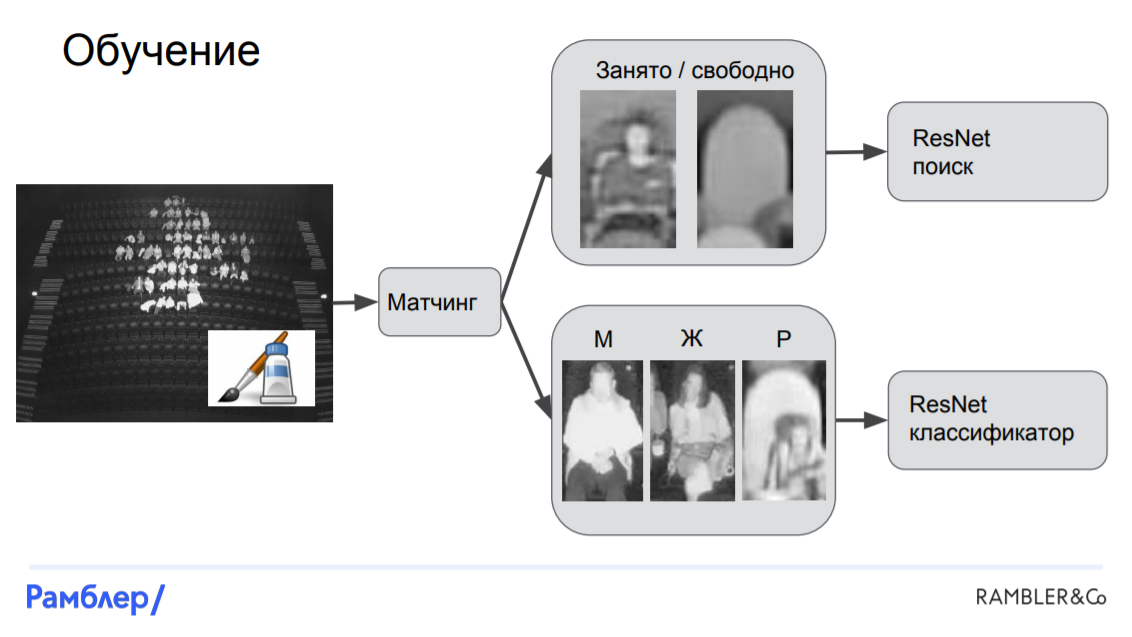
LinkNet-ResNet Model. This was our first model, and it showed a fairly high quality. It consisted of three main parts: a segmenter (LinkNet) , which finds the mask of the heads in the picture, a localizer , which finds the coordinates of the head and the bounding box for each person, andclassifier (ResNet) , which based on crop bounding box-a, determines who is sitting in this picture: man, woman or child.
Training begins with a tagged picture. In this picture, we get a mask by applying a white Gaussian spot on each person’s head. After that, we cut the picture into crop using bounding boxes around each head, and after that we submit everything received to our networks. The mask along with the source image is fed to the segmenter and LinkNet is obtained, and the crop along with the target targets are served in ResNet.
PredictionsBut they are done a little differently. We give the source image in LinkNet, we get a mask. We submit it to the localizer, which finds the coordinates of the head and bounding boxes. Then, the crop is cut out on them, which are fed to ResNet and the outputs of the neural network are obtained, on the basis of which we can get all the necessary analytics: the number of people in the session and the socio-demographic composition.
Model "Crusader". In the previous model, we did not use a priori knowledge that there are armchairs in the halls that are nailed to the floor, and in the pictures they always appear in the same place. In addition, when people come to the gym, they usually end up in chairs. Given this information, we will build a model.
First, we need to teach the model to recognize where the seats are in the picture, and here again we have to resort to manual marking. In each chair of each hall, a mark was put in the place where the head of the average person would be if he was sitting in a chair.
Let's move on to the model. First, we need to match: match the heads with the chairs, and then for each chair determine whether it is occupied or free, and if it is occupied, by whom exactly. After that, we can cut out the image sections corresponding to these chairs and train two models on them: one will recognize if the chair is occupied, and the second will classify the audience into 3 categories. Both models are based on the ResNet neural network. Thus, the difference between “Armchair” and LinkNet-ResNet is that in it all the crop are fixed, they are tied to the location of the seats in the picture, while in the first model they were cut out arbitrarily - where the head is, there we cut it.
Another speaker on this busy day was Artem Prosvetov, Senior Data Scientist at CleverData, a company that specializes in various data management solutions. His project was to optimize marketing communications for the beauty industry, which he described.

In order to understand to whom, what, and when to send out, you need to have knowledge of what a person has a purchase history, what he needs now, at what point to contact him and through which channel. Moreover, this information can be obtained not only from the history of purchases, but also from how a person behaves on the site, which links he clicks, which mailings he opens, and so on. The main question: how to get features for the model from this sequence of actions?
The most obvious way seems to encode these sequences of events as follows:

Everything is simple: the action is encoded by one, the omission of the action is zero. However, a problem arises here: different people have different numbers of actions. Therefore, the next logical step is to set the vectors of a fixed length equal to the duration of the actions of a person with the longest history.
It is also worth noting that such an encoding does not take into account the time elapsed between adjacent actions, which can be very important. Therefore, as an additional vector, we add the time difference between the events, and so that there are no values of tens of thousands of seconds, we logarithm this vector. By the way, then the distribution will look like a lognormal.

Finally, the features are received and we are ready to train the model, namely the neural network, which is the most popular method of processing a series of events. A model consisting of auto-encoders and several layers of the LSTM network showed a relatively high quality - the ROC-AUC metric was 0.87.
The first day of the conference was completed by Artem Trunov, another of our graduates and coordinators of the Big Data Specialist 8.0 program . Artem talked about how he managed to win the machine learning competition from the TrainMyData platform.
As part of the competition, it was necessary to predict the time series of Ascott Group's weekly sales. Of course, today the most popular method for predicting time series is neural networks, but this does not mean that classical econometric algorithms do not work. It was they who helped me win this contest, so I would like to remind you about each of them:
Some feedback on the event:
“It was very useful and interesting to know how the declared technologies are used in real projects.” - Andrey Tolmachev, Assi LLC.
“Thank you for a good event: the right working format, worthy preparation, a good composition of speaker practitioners and a lot of useful information.” - Maxim Sorokin, Head of R&D Group, STC “Volcano”.
You can watch videos of all the speeches on our Facebook page .
Soon we will publish a review of the second day of Data Science Weekend 2018, when the emphasis was on Data Engineering, the use of various data engineer tools for the needs of data platforms, ETL, search hints services and much more. Stay tuned!
Vectorx
Open Data Science Weekend 2018 has the honor of graduating from our Big Data Specialist program , Roman Smirnov, from VectorX, a company that processes information distribution in the company and configures the information field. As part of his speech, Roman spoke about why it is so difficult to work with a team of data scientists and how to make their work as efficient as possible.
Based on my experience, there are 4 main problems that the company faces when working with data scientists (we will call them experts):
Problem: unpredictable performance caused by high demand for expertise.The expert does not belong to you, but to society, because he is a scientist and uses his knowledge to make us all healthier and richer. It turns out that they just want him all, but he doesn't give a damn about everyone. From this are possible problems with motivation and labor efficiency.
Solution: firstly, there should always be an alternative in the form of another expert, whose existence must remain a secret. Secondly, it is necessary to keep a record of all projects, collect statistics in order to give the expert feedback and maintain a sense of personal worth. Finally, it turned out that CRM is good not only for customers, but also when working with distributed teams.
Problem: Conflict of motivation.Data scientist is a person who tries to convince everyone that he is a pioneer, deals with critical issues, tries to discover the secret of the philosopher's stone. Unfortunately, basic physiological motives are not alien to him, and this conflict does not allow him to prioritize, but to you - to conclude a favorable agreement with him.
Solution: this dualism can be used for your own purposes. If the expert says that he does not have enough money, you can call on his humanistic values and say: "My friend, you are a scientist!" And vice versa: it is worth reminding him that he is a person in status and that he should not go for a year in a suit with patches on his elbows.
Problem: spec speculation.It often happens that an indisputably experienced theorist is not able to solve a trivial practical problem. Consequently, he cannot soberly assess the complexity of the project with all the consequences: failed deadlines, loss of motivation by the team, exorbitant costs, etc.
Solution: request a portfolio from a potential project manager and do not hesitate to spend money on code review to confirm or dispel concerns.
Problem: ulterior motives. An expert, as a scientist, wants to become above society, and not in its ranks. Therefore, he always has a desire to popularize his opinion in the widest possible range of areas of knowledge, which, however, does not correlate well with the commercial benefits of the project: if something threatens the reputation of an expert in the company, then there is a risk of losing it.
Solution: today science is very closely intertwined with business: a couple of years ago no one even thought that marketing would extend to scientific articles. Co-sponsor the writing of scientific articles - for science-intensive projects, this is an excellent marketing move.
And in the event of a threat of loss of expertise, hire an expert from a competing laboratory. Such an act can offend the first scientist and stimulates him to take action to wipe his nose with a competitor.
Sberbank
Then it was the turn of another of our graduates, Alexander Ulyanov, who is the Data science executive director at Sberbank. Using an example of a cash management project in an ATM network across the country, he talked about why, instead of immediately attacking complex models and trying to build them, you must first sit down and thoroughly conduct statistical data analysis. This is extremely important when working with real data, because they often have a large number of omissions, outliers, incorrect measurements and banal errors in recording information, so each data scientist must, for example, have statistical methods for detecting anomalies or at least be able to look at the number zeros in the dataset, maximum and minimum values of features. The principle of "garbage in - garbage out" has not been canceled.
You can soon read more about Alexander’s speech and the case for managing an ATM network in the corporate blog of Sberbank on Habré. Wait!
New professions lab
Further, Artem Pichugin, Head of educational programs for working with data at Newprolab, introduced a new approach to the conduct of machine learning competitions, which will be tested on the upcoming program "Big Data Specialist 8.0" . The start of the program is March 22.
It all started in 2009 with a competition from Netflix, in which the winner received $ 1 million, which made these events popular, Kaggle appeared and it all started to develop rapidly. However, it turned out that from the very beginning everything went wrong: in 2012 it turned out that the decision of the winner of the contest from Netflix was simply impossible to implement in production, it was too complicated and difficult.
Several years have passed, and what do we see? It's 2018, and people are still trying to make super complex models, they are building huge ensembles. And it more and more resembles a sport of high achievements.
Of course, on the program, we also used this approach, ranking students by a certain metric, regardless of the complexity of their decision. However, realizing how far all these decisions can be from the business, we take a completely new approach to competition in the program.
Now the final rating will take into account only those solutions that are suitable for SLA, that is, fit into some reasonable period of time. Moreover, unlike some other approaches, not the total model training time, buthow quickly the forecast is calculated for one element of the test sample.
Previously, a person made a model in a Jupyter Notebook, made a forecast for a test sample, saved, sent and calculated the final metric. Now, he needs to pack this model into Docker, that is, make a small “cookie”, having received a JSON file . Thus, we will become closer to production and urge everyone who organizes competitions and hackathons to move in this direction.
By the way, in the next few months we will hold our hackathon. Subscribe to us on Facebook and Telegram so as not to miss information!
Rambler & Co
Now let's talk about the group presentation of machine learning specialists from Rambler & Co, who sorted out an interesting case on the use of computer vision in cinema halls to recognize the number, gender and age of cinema visitors.
We were tasked with assessing the composition of the audience at sessions in a network of cinemas in order to report to advertisers who need to understand the socio-demographic composition of the audience and who give us money for one or another advertisement shown before the sessions.
Let's start with data sources.. It would seem that we have a Rambler-Cashier, therefore we have a lot of information about users, however, according to these data, the estimate will actually be biased. For family viewing, tickets are bought by dad or mom, if this is a couple, then most likely a guy will buy them and so on. Therefore, we were able to find another solution: in each room there is a camera that sees everyone who sits in the cinema:
Looking ahead, we say that we managed to build a model that estimates from photographs who is sitting where, gender and age of visitors. We were able to determine the number of people with almost 100% accuracy, distinguish men from women with 90%, and recognize children with a slightly lower probability. How did we do it?
Markup data.From the very beginning, we ran into a bunch of problems. First of all, it is very difficult to find at least two similar cinema halls, they are all different, with different scales and perspectives. There are cameras that do not capture the entire hall, shoot at an angle. We add to this a different illumination of the hall, depending on what is happening on the screen at the time of shooting, and it turns out that we have data of different quality, which is simply impossible to mark up automatically.
We had to resort to manual marking. It was very expensive, difficult, took up most of the working time, so we decided to hire a team of “elite markers” from the outside - people who would normally and thoroughly mark up the data. Of course, it is impossible to exclude the human factor, there were a number of errors, but in the end we still managed to mark all the photos and we were ready to build models.
LinkNet-ResNet Model. This was our first model, and it showed a fairly high quality. It consisted of three main parts: a segmenter (LinkNet) , which finds the mask of the heads in the picture, a localizer , which finds the coordinates of the head and the bounding box for each person, andclassifier (ResNet) , which based on crop bounding box-a, determines who is sitting in this picture: man, woman or child.
Training begins with a tagged picture. In this picture, we get a mask by applying a white Gaussian spot on each person’s head. After that, we cut the picture into crop using bounding boxes around each head, and after that we submit everything received to our networks. The mask along with the source image is fed to the segmenter and LinkNet is obtained, and the crop along with the target targets are served in ResNet.
PredictionsBut they are done a little differently. We give the source image in LinkNet, we get a mask. We submit it to the localizer, which finds the coordinates of the head and bounding boxes. Then, the crop is cut out on them, which are fed to ResNet and the outputs of the neural network are obtained, on the basis of which we can get all the necessary analytics: the number of people in the session and the socio-demographic composition.
Model "Crusader". In the previous model, we did not use a priori knowledge that there are armchairs in the halls that are nailed to the floor, and in the pictures they always appear in the same place. In addition, when people come to the gym, they usually end up in chairs. Given this information, we will build a model.
First, we need to teach the model to recognize where the seats are in the picture, and here again we have to resort to manual marking. In each chair of each hall, a mark was put in the place where the head of the average person would be if he was sitting in a chair.
Let's move on to the model. First, we need to match: match the heads with the chairs, and then for each chair determine whether it is occupied or free, and if it is occupied, by whom exactly. After that, we can cut out the image sections corresponding to these chairs and train two models on them: one will recognize if the chair is occupied, and the second will classify the audience into 3 categories. Both models are based on the ResNet neural network. Thus, the difference between “Armchair” and LinkNet-ResNet is that in it all the crop are fixed, they are tied to the location of the seats in the picture, while in the first model they were cut out arbitrarily - where the head is, there we cut it.
Cleverdata
Another speaker on this busy day was Artem Prosvetov, Senior Data Scientist at CleverData, a company that specializes in various data management solutions. His project was to optimize marketing communications for the beauty industry, which he described.
In order to understand to whom, what, and when to send out, you need to have knowledge of what a person has a purchase history, what he needs now, at what point to contact him and through which channel. Moreover, this information can be obtained not only from the history of purchases, but also from how a person behaves on the site, which links he clicks, which mailings he opens, and so on. The main question: how to get features for the model from this sequence of actions?
The most obvious way seems to encode these sequences of events as follows:
Everything is simple: the action is encoded by one, the omission of the action is zero. However, a problem arises here: different people have different numbers of actions. Therefore, the next logical step is to set the vectors of a fixed length equal to the duration of the actions of a person with the longest history.
It is also worth noting that such an encoding does not take into account the time elapsed between adjacent actions, which can be very important. Therefore, as an additional vector, we add the time difference between the events, and so that there are no values of tens of thousands of seconds, we logarithm this vector. By the way, then the distribution will look like a lognormal.
Finally, the features are received and we are ready to train the model, namely the neural network, which is the most popular method of processing a series of events. A model consisting of auto-encoders and several layers of the LSTM network showed a relatively high quality - the ROC-AUC metric was 0.87.
TrainMyData
The first day of the conference was completed by Artem Trunov, another of our graduates and coordinators of the Big Data Specialist 8.0 program . Artem talked about how he managed to win the machine learning competition from the TrainMyData platform.
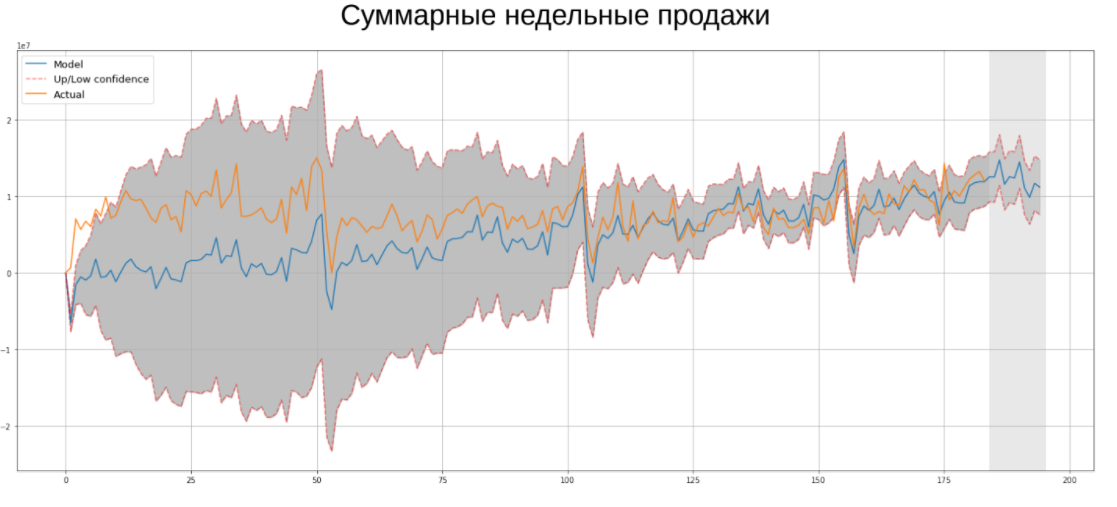
As part of the competition, it was necessary to predict the time series of Ascott Group's weekly sales. Of course, today the most popular method for predicting time series is neural networks, but this does not mean that classical econometric algorithms do not work. It was they who helped me win this contest, so I would like to remind you about each of them:
- Exponential smoothing. It is one of the simplest methods for predicting time series and has a short memory, since later observations are assigned more weight.
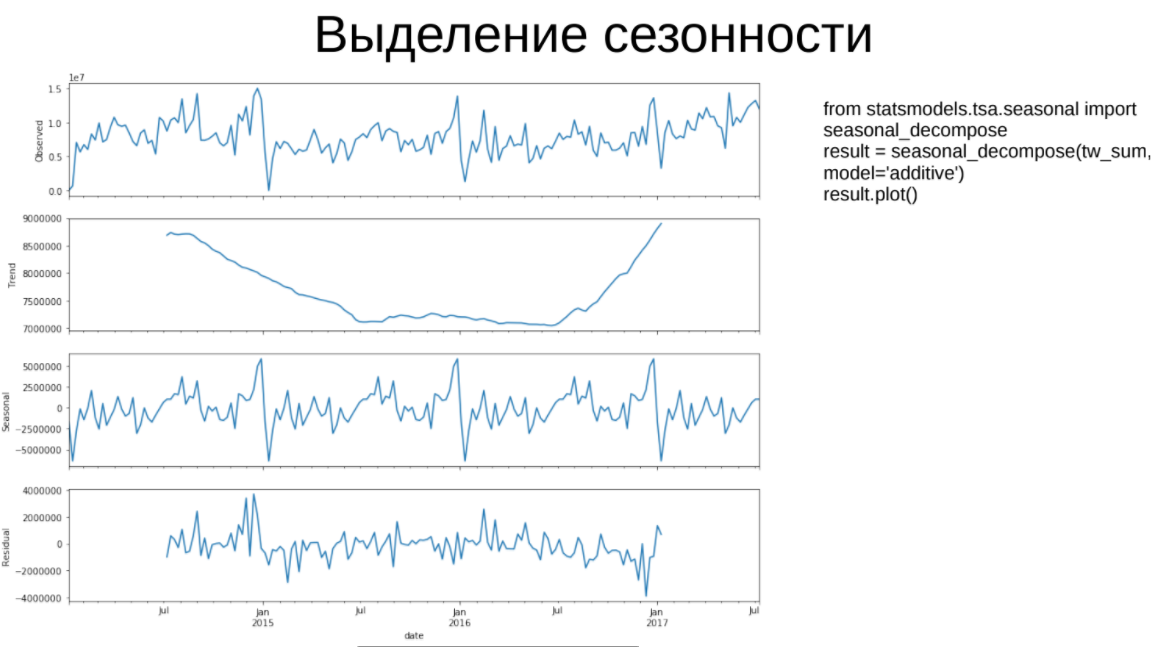
- Highlight seasonality. Within the framework of this algorithm, the time series is decomposed into 3 components: trend, seasonal component and residuals, which should be similar to “white noise”.
- Holt-Winters model. It is a triple exponential smoothing: according to the initial series, trend and seasonal component.
- (S) ARIMA. ARIMA is an autoregressive model that learns on the lags of the target variable. The lags are needed to bring the series to stationary (in which the mean, variance and covariance are time-independent). A modification of the algorithm is SARIMA, which allows you to take into account seasonality in the data. The advantage of ARIMA over neural networks is a small number of parameters for training, it is less prone to retraining. This also means that the parameters can be quickly and efficiently sorted through the grid until the Akaike information criterion (AIC) is minimal.
Some feedback on the event:
“It was very useful and interesting to know how the declared technologies are used in real projects.” - Andrey Tolmachev, Assi LLC.
“Thank you for a good event: the right working format, worthy preparation, a good composition of speaker practitioners and a lot of useful information.” - Maxim Sorokin, Head of R&D Group, STC “Volcano”.
You can watch videos of all the speeches on our Facebook page .
Soon we will publish a review of the second day of Data Science Weekend 2018, when the emphasis was on Data Engineering, the use of various data engineer tools for the needs of data platforms, ETL, search hints services and much more. Stay tuned!