Nomad: problems and solutions
I launched the first service in Nomad in September 2016. At the moment, I use as a programmer and do support as an administrator of two Nomad clusters - one “home” for my personal projects (6 micro virtual machines in Hetzner Cloud and ArubaCloud in 5 different European data centers) and a second worker (about 40 private virtual and physical servers in two data centers).
Since then, quite a lot of experience has been gained with the Nomad environment, in the article I will describe the Nomad problems we have encountered and how to cope with them.

Yamal Nomad makes Continous Delivery of your software instance © National Geographic Russia
1. Number of server nodes per data center
Solution: one server node is enough for one data center.
The documentation does not explicitly indicate how many server nodes are required in one data center. It is indicated only that a region needs 3-5 nodes, which is logical for the raft protocol consensus.
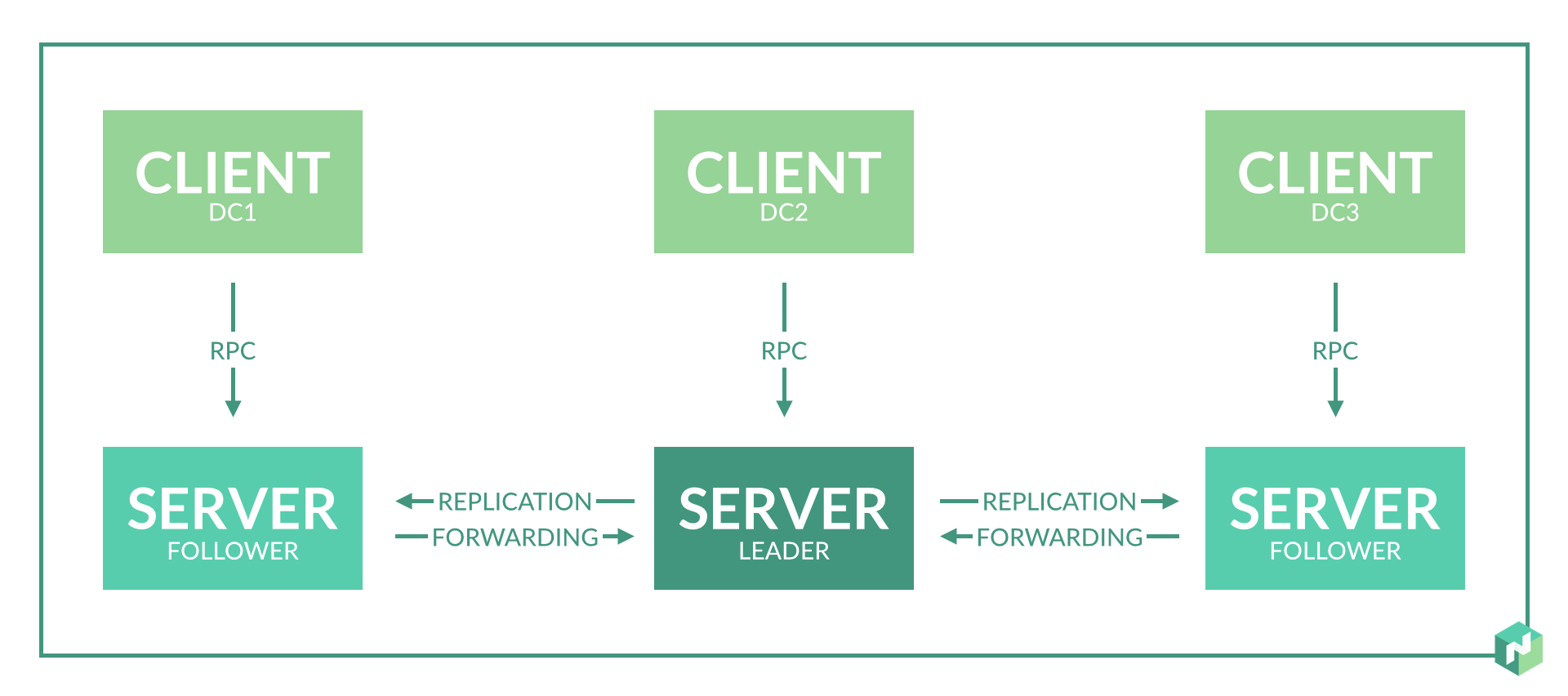
At the beginning I planned 2-3 server nodes in each data center to provide redundancy.
In fact of use it turned out:
- This is simply not necessary, since if a node fails in a data center, the role of a server node for agents in this data center will be performed by other server nodes in this region.
- It turns out even worse if the problem number 8 is not solved. When re-election wizard mismatch can occur and Nomad will restart some of the services.
2. Server resources for server node
Solution: a small virtual machine is enough for a server node. On the same server, it is allowed to run other non-resource service services.
Memory consumption by the Nomad daemon depends on the number of running tasks. CPU consumption is based on the number of tasks and the number of servers / agents in the region (not linear).
In our case: for 300 running tasks, memory consumption is about 500 MB for the current master node.
In a working cluster, a virtual machine for a server node: 4 CPU, 6 GB RAM.
Additionally launched: Consul, Etcd, Vault.
3. Consensus on the lack of data centers
Solution: we make three virtual datacenters and three server nodes for two physical datacenters.
Nomad's work within the region is based on the raft protocol. To work correctly, you need at least 3 server nodes located in different data centers. This will enable correct operation with the complete loss of network connectivity with one of the data centers.
But we have only two data centers. We go to a compromise: we choose a data center, which we trust more, and make an additional server node in it. We do this by introducing an additional virtual data center, which will physically be located in the same data center (see subsection 2 of problem 1).
Alternative solution: we break data centers into separate regions.
As a result, data centers operate independently and consensus is needed only within a single data center. Inside the data center in this case it is better to make 3 server nodes by implementing three virtual data centers in one physical one.
This option is less convenient for the distribution of tasks, but gives 100% guarantee of the independence of the work of services in case of network problems between data centers.
4. "Server" and "agent" on one server
Solution: valid if you have limited number of servers.
The Nomad documentation says that doing so is undesirable. But if you are not able to allocate separate virtual machines for server nodes, you can place the server and agent node on one server.
Simultaneous launch means starting the Nomad daemon in both client mode and server mode.
What does it threaten with? With a heavy load on the CPU of this server, the Nomad server node will become unstable, there may be a loss of consensus and heartbits, and services will be restarted.
To avoid this, we increase the limits from the description of Problem 8.
5. Implementation of namespaces (namespaces)
Solution: perhaps through the organization of a virtual data center.
Sometimes you need to run some of the services on separate servers.
The first solution is simple, but more demanding of resources. We divide all services into groups by purpose: frontend, backend, ... Add meta attributes to servers, prescribe attributes to run all services.
The second solution is simple. We add new servers, prescribe meta attributes for them, prescribe these launch attributes for the necessary services, for all other services we prescribe a launch ban on servers with this attribute.
The third decision is difficult. Create a virtual data center: run Consul for the new data center, launch the Nomad server node for this data center, not forgetting the number of server nodes for the region. Now you can run individual services in this dedicated virtual data center.
6. Vault integration
Solution: avoid Nomad's cyclic dependencies <-> Vault.
A running Vault should have no dependencies on Nomad. The Vault address prescribed in Nomad should preferably point directly to the Vault, without balancers strings (but valid). Backup Vault in this case can be done through DNS - Consul DNS or external.
If the Vault data is written in the Nomad configuration files, then Nomad tries to access the Vault at startup. If access fails, the Nomad refuses to start.
I made a mistake with a cyclic dependency a long time ago, with this, for a short time, almost completely destroying the Nomad cluster. The Vault was run correctly, regardless of Nomad, but Nomad looked at the Vault address through the balancers that were running in the Nomad itself. Reconfiguration and reboot of the Nomad server nodes caused the reboot of the balancer services, which led to a failure to start the server nodes themselves.
7. Launching important statefull services
Solution: valid, but I do not.
Can I run PostgreSQL, ClickHouse, Redis Cluster, RabbitMQ, MongoDB via Nomad?
Imagine that you have a set of important services for which most of the other services are tied. For example, DB in PostgreSQL / ClickHouse. Or shared short-term storage in Redis Cluster / MongoDB. Or data bus in Redis Cluster / RabbitMQ.
All these services in some form implement a fault-tolerant scheme: Stolon / Patroni for PostgreSQL, its own raft implementation in Redis Cluster, its own cluster implementation in RabbitMQ, MongoDB, ClickHouse.
Yes, all these services can be easily run through Nomad with binding to specific servers, but why?
Plus - ease of launch, a single script format, like the rest of the services. No need to bother with scripts ansible / something else.
Minus - an additional point of failure, which does not give any advantages. Personally, I completely dropped the Nomad cluster twice for different reasons: once “home”, once working. This was in the early stages of introducing Nomad and due to inaccuracy.
Also, Nomad starts to behave badly and restart services due to problem # 8. But even if that problem is solved, the danger remains.
8. Stabilization of work and restarts of services in an unstable network.
Solution: use of the heartbit tuning options.
By default, Nomad is configured so that any short-term network problem or CPU load causes loss of consensus and re-election of the master or marking the agent node unavailable. And this leads to spontaneous reloads of services and transfer them to other nodes.
Statistics of the "home" cluster before fixing the problem: the maximum lifetime of the container before the restart is about 10 days It is still aggravated by launching an agent and a server on one server and placing it in 5 different European data centers, which implies a greater load on the CPU and a less stable network.
Statistics of the working cluster before the problem is fixed: the maximum lifetime of the container before the restart is more than 2 months. Everything is relatively good here because of the separate servers for Nomad server nodes and the excellent network between data centers.
Default values
heartbeat_grace = "10s"
min_heartbeat_ttl = "10s"
max_heartbeats_per_second = 50.0Judging by the code: in this configuration, the Hits are made every 10 seconds. If two heartbits are lost, the re-election of the master or the transfer of services from the agent node begin. The controversial settings, in my opinion. Edit them depending on the application.
If you have all the services running in several instances and are separated by data centers, then most likely you don’t have a long time to determine if the server is unavailable (approximately 5 minutes, in the example below), we do less often the interval of hits and the longer the time to determine inaccessibility. This is an example of setting up my "home" cluster:
heartbeat_grace = "300s"
min_heartbeat_ttl = "30s"
max_heartbeats_per_second = 10.0If you have good network connectivity, separate servers for server nodes, and the determination period for server unavailability is important (there is some service running in one instance and it is important to transfer it quickly), then we increase the period for determining unavailability (heartbeat_grace). Optionally, you can make more frequent hartbits (by reducing min_heartbeat_ttl) - this will slightly increase the load on the CPU. An example of a working cluster configuration:
heartbeat_grace = "60s"
min_heartbeat_ttl = "10s"
max_heartbeats_per_second = 50.0These settings completely eliminate the problem.
9. Run periodic tasks
Solution: Nomad periodic services can be used, but "cron" is more convenient for support.
Nomad has the ability to periodically launch a service.
The only plus is the simplicity of this configuration.
The first minus is that if the service starts frequently, it will clutter up the task list. For example, when running every 5 minutes - 12 extra tasks will be added to the list every hour, until the GC Nomad triggers, which deletes old tasks.
The second minus is not clear how to properly set up monitoring of such a service. How to understand that the service starts, works and performs its work to the end?
As a result, for myself, I came to the "cron" implementation of periodic tasks:
- This may be a regular cron in a constantly running container. Cron periodically runs a script. Script-healthcheck is easily added to such a container, which checks for any flag that the script runs.
- It can be a constantly running container, with a constantly running service. A periodic launch has already been implemented inside the service. On such a service, it is easy to add either a similar script-healthcheck or http-healthcheck, which checks the status immediately by its "insides".
At the moment, most of the time I write on Go, respectively, I prefer the second option with http healthcheck - Go and periodic launch, and http healthcheck are added with a few lines of code.
10. Providing service redundancy.
Solution: no simple solution. There are two options more difficult.
The provisioning scheme provided by the Nomad developers is to support the number of services running. You say to the nomad “launch me 5 service instances” and he launches them somewhere. There is no control over the distribution. Instances can run on the same server.
If the server is down, the instances are transferred to other servers. While instances are being transferred, the service does not work. This is a bad backup option.
We do it right:
- We distribute instansa across servers through distinct_hosts .
- We distribute instansa on data centers. Unfortunately, only through the creation of a copy of the script of the type service1, service2 with the same content, different names and an indication of the launch in different data centers.
In Nomad 0.9, a functional will appear that will eliminate this problem: it will be possible to distribute services as a percentage between servers and data centers.
11. Web UI Nomad
Solution: the built-in UI is terrible, hashi-ui is beautiful.
The console client performs most of the required functionality, but sometimes you want to see the charts, press the buttons ...
UI is built into Nomad. It is not very convenient (even worse than the console).
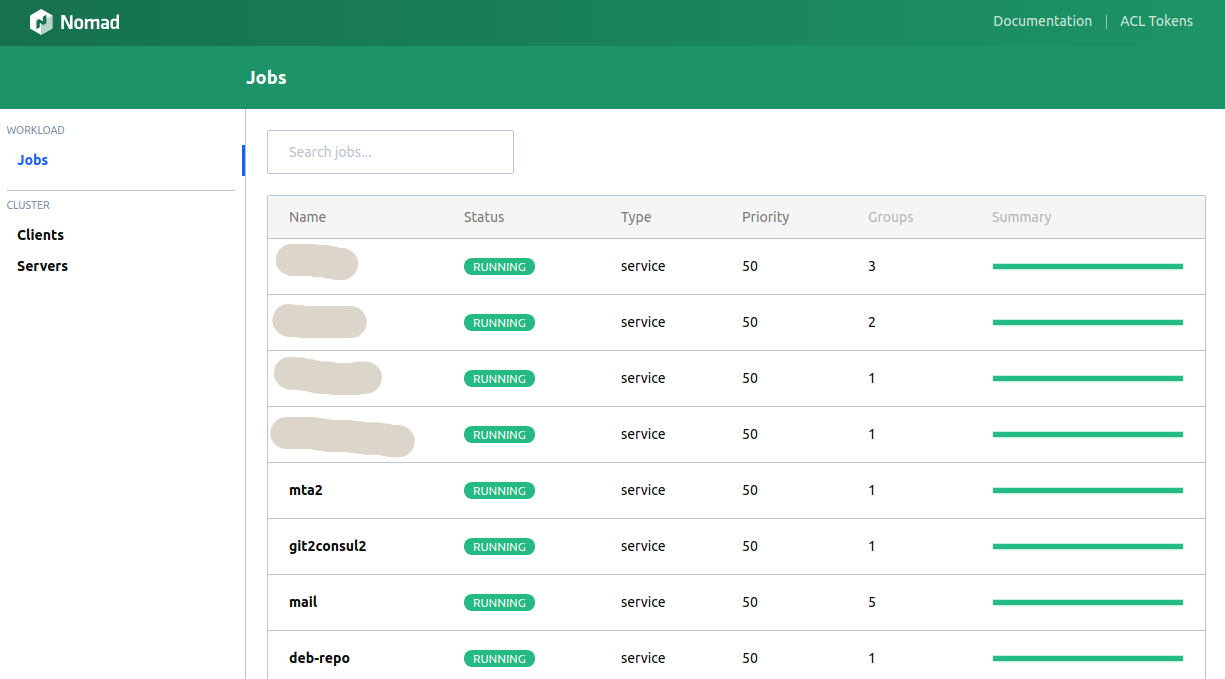
The only alternative I know is hashi-ui .
In fact, now I personally need a console client only for "nomad run". And even this is in plans to transfer to CI.
12. Memory oversubscription support
Solution: no.
In the current version of Nomad, be sure to specify a strict memory limit for the service. If you exceed the limit - the service will be killed OOM Killer.
Oversubscription is when service limits can be specified "from and to". Some services require more memory at startup than during normal operation. Some services may temporarily consume more memory than usual.
The choice is strictly limited or soft - a topic for discussion, but, for example, Kubernetes gives the programmer a choice. Unfortunately, in current versions of Nomad there is no such possibility. I admit that will appear in future versions.
13. Cleaning the server from Nomad services.
Decision:
sudo systemctl stop nomad
mount | fgrep alloc | awk '{print $3}' | xargs -I QQ sudo umount QQ
sudo rm -rf /var/lib/nomad
sudo docker ps | grep -v '(служебный-сервис1|служебный-сервис2|...)' | fgrep -v IMAGE | awk '{print $1}' | xargs -I QQ sudo docker stop QQ
sudo systemctl start nomadSometimes "something goes wrong." On the server, kills the agent node and it refuses to start. Or the agent node stops responding. Or the agent node "loses" services on this server.
This sometimes happened with the old versions of Nomad, now it either does not happen, or very rarely.
What then is the easiest way to do, given that the drain of the server will not give the desired result? Manually clear the server:
- Stop the nomad agent.
- We do umount on the mount it creates.
- Delete all agent data.
- Remove all containers by filtering service containers (if any).
- We start the agent.
14. What is the best way to deploy Nomad?
Solution: of course, through Consul.
Consul in this case is not an extra layer, but an organically integrated service that provides more advantages than minuses: DNS, KV storage, search for services, monitoring accessibility of the service, the ability to safely exchange information.
In addition, it unfolds as easily as Nomad itself.
15. Which is better - Nomad or Kubernetes?
Solution: depends on ...
Previously, I sometimes had the idea to start migration to Kubernetes - I was so annoyed by the periodic spontaneous restart of services (see problem number 8). But after a complete solution of the problem, I can say: Nomad suits me at the moment.
On the other hand: in Kubernetes, there is also a semi-spontaneous restart of services — when the scheduler Kubernetes reallocates instances depending on the load. This is not very cool, but most likely it is configured there.
Nomad advantages: very easy to deploy infrastructure, simple scripts, good documentation, built-in support for Consul / Vault, which in turn gives: a simple solution to the problem of storing passwords, built-in DNS, easy to set up healschacks.
Pros Kubernetes: now it is a "standard de facto." Good documentation, many ready-made solutions, with a good description and standardization of the launch.
Unfortunately, I do not have the same great expertise in Kubernetes to unequivocally answer the question of what to use for the new cluster. Depends on the planned needs.
If you have a lot of namespaces planned (problem number 5) or your specific services consume a lot of memory at the start, then freeing it up (problem number 12) is definitely Kubernetes, since These two problems in Nomad are not completely resolved or uncomfortable.