blk-mq and I / O schedulers

In the field of storage devices in recent years, major changes have taken place: new technologies are being introduced, the volume and speed of disk drives are growing. In this case, the following situation develops, in which the bottleneck is not the device, but the software. The Linux kernel mechanisms for working with the disk subsystem are completely unsuitable for new, fast block devices.
In recent versions of the Linux kernel, much work has been done to solve this problem. With the release of version 4.12, users have the opportunity to use several new schedulers for block devices. These schedulers are based on a new method for sending requests - multiqueue block layer (blk-mq).
In this article, we would like to examine in detail the features of the work of new schedulers and their impact on the performance of the disk subsystem.
The article will be interesting to everyone involved in the testing, implementation and administration of highly loaded systems. We will talk about traditional and new schedulers, analyze the results of synthetic tests and draw some conclusions about testing and choosing a scheduler for load. Let's start with the theory.
Bit of theory
Traditionally, the subsystem for working with block device drivers in Linux provided two options for transmitting a request to a driver: one with a queue, and the second without a queue.
In the first case, a queue is used for requests to the device, common to all processes. On the one hand, this approach allows the use of various schedulers, which in the general queue can rearrange requests in places, slowing down some and speeding up the others, combine several requests to neighboring blocks into a single request to reduce costs. On the other hand, when accelerating the processing of requests from the block device, this queue becomes a bottleneck: one for the entire operating system.
In the second case, the request is sent directly to the device driver. Of course, this makes it possible to bypass the general queue. But at the same time, there is a need to create a turn and schedule requests inside the device driver. This option is suitable for virtual devices that process requests and redirect in transit to real devices.
In the past few years, the processing speed of requests by block devices has increased, and therefore the requirements for the operating system, as well as for the data transfer interface, have changed.
In 2013, the third option was developed - multiqueue block layer (blk-mq).
We describe the architecture of the solution in general terms. The request first enters the software queue. The number of these queues is equal to the number of processor cores. After passing the program queue, the request falls into the send queue. The number of send queues already depends on the device driver, which can support from 1 to 2048 queues. Since the work of the scheduler is carried out at the level of software queues, a request from any software queue can fall into any send queue provided by the driver.
Standard Schedulers
Most modern Linux distributions have three standard schedulers available: noop , CFQ, and deadline .
The name noop is an abbreviation for no operation, which suggests that this scheduler does nothing. In fact, this is not so: noop implements a simple FIFO queue and aggregation of requests to neighboring blocks. It does not change the order of the requests and relies on the underlying level in this, for example, on the planning capabilities of the Raid controller.
CFQ(Completely fair queuing) works harder. It shares bandwidth between all processes. For synchronous requests, a process queue is created. Asynchronous requests are queued by priority. In addition, CFQ sorts queries to minimize disk sector searches. The time to execute requests between queues is distributed according to the priority, which can be configured using the ionice utility . When configuring, you can change both the process class and the priority within the class. We will not dwell on the settings in detail , we only note that this scheduler has great flexibility, and setting priority for processes is a very useful thing to limit the execution of administrative tasks for the user.
The deadline scheduler uses a different strategy. The basis is the time the request was in the queue. Thus, it ensures that every request will be served by the scheduler. Since most applications are blocked on reading, deadline gives priority to read requests by default.
The blk-mq mechanism was developed after the advent of NVMe disks, when it became clear that the standard kernel tools did not provide the necessary performance. It was added to kernel 3.13, but the schedulers were written later. The latest Linux kernel versions (≥4.12) have the following schedulers for blk-mq: none, bfq, mq-deadline, and kyber. Consider each of these planners in more detail.
Blk-mq planners: overview
Using blk-mq, you can really disable the scheduler, just set it to none.
A lot has been written about BFQ , I can only say that it inherits part of the settings and the main algorithm from CFQ, introducing the concept of budget and a few more parameters for tuning. Mq-deadline is, as you might guess, an implementation of deadline using blk-mq. And the last option is kyber . It was written to work with fast devices. Using two queues - write and read requests, kyber prioritizes read requests over write requests. The algorithm measures the completion time of each request and adjusts the actual queue size to achieve the delays set in the settings.
Tests
Introductory remarks
Checking the scheduler is not so simple. A simple single-threaded test will not show convincing results. There are two test options - simulate multi-threaded load using, for example, fio; install the real application and check how it will show itself under load.
We conducted a series of synthetic tests. All of them were carried out with the standard settings of the schedulers themselves (such settings can be found in / sys / block / sda / queue / iosched /).
Which case will we test?
We will create a multi-threaded load on the block device. We will be interested in the least delay (the smallest latency parameter) at the highest data rate. We assume that reading requests are in priority.
HDD tests
Let's start by testing the planners with the hdd.
For HDD tests, the server was used:
- 2 x Intel® Xeon® CPU E5-2630 v2 @ 2.40GHz
- 128 GB RAM
- 8TB HGST HUH721008AL Disk
- Ubuntu linux 16.04 OS, kernel 4.13.0-17-generic from official repositories
Fio options
[global]
ioengine=libaio
blocksize=4k
direct=1
buffered=0
iodepth=1
runtime=7200
random_generator=lfsr
filename=/dev/sda1
[writers]
numjobs=2
rw=randwrite
[reader_40]
rw=randrw
rwmixread=40
From the settings it can be seen that, we bypass caching, set the queue depth to 1 for each process. Two processes will write data in random blocks, one - write and read. The process described in reader_40 will send 40% of requests for reading, the remaining 60% for writing ( rwmixread option ).
The fio options are described in more detail on the man page .
The test duration is two hours (7200 seconds).
Test results
CFQ:
Deadline:
Noop:
BFQ:
Mq-deadline:
Kyber:
None:


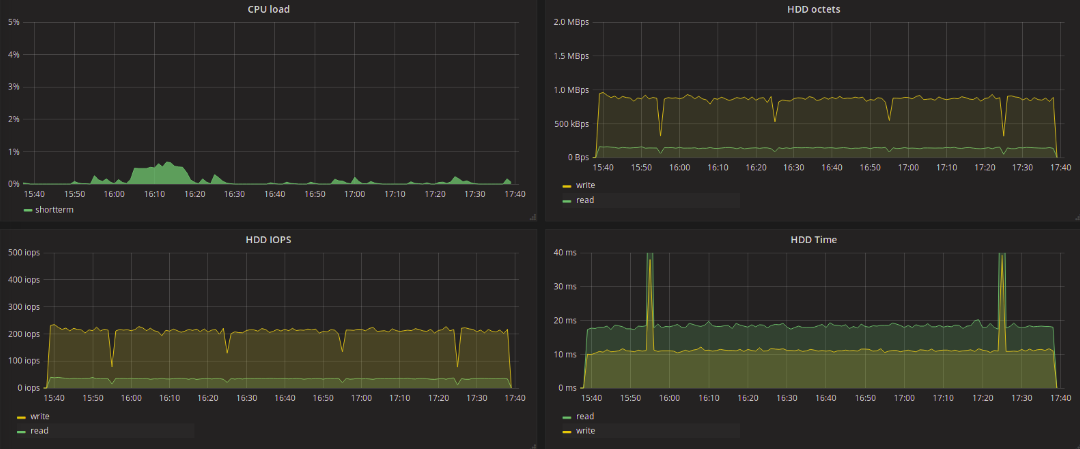

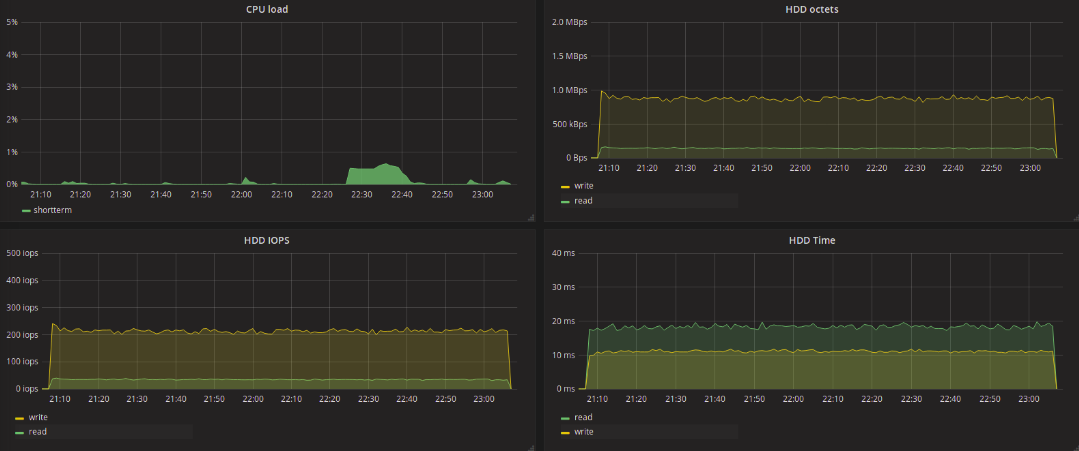
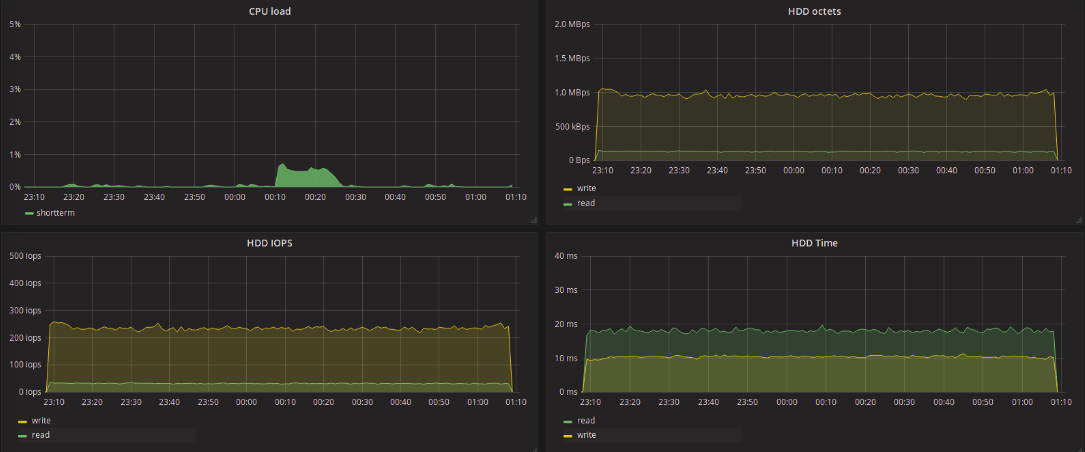
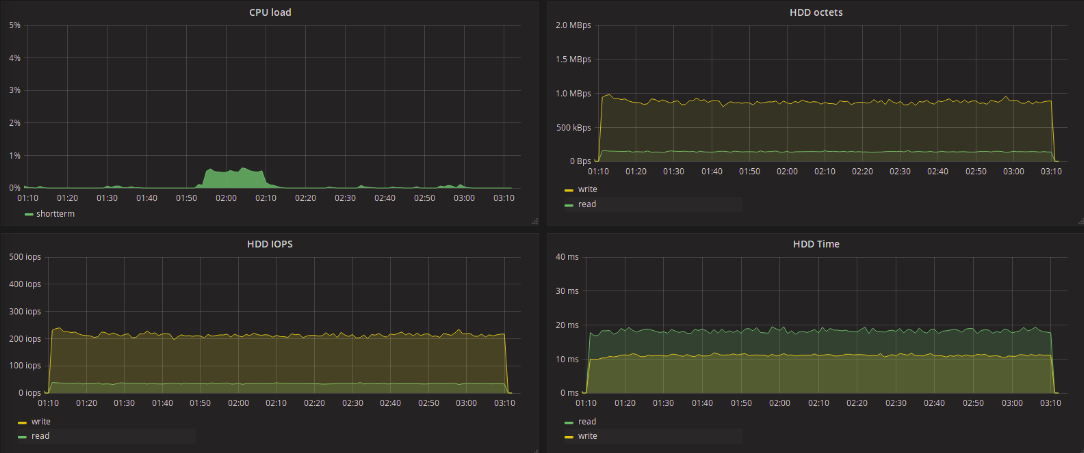







Test results in the table
* hereinafter in the writers column, the median from the writers streams is taken, similarly in the reader_40 columns. The delay value in milliseconds.
| writers randwrite | reader_40 randwrite | reader_40 read | ||
| CFQ | bw | 331 KB / s | 210 KB / s | 140 KB / s |
| iops | 80 | 51 | 34 | |
| avg lat | 12.36 | 7.17 | 18.36 | |
| deadline | bw | 330 KB / s | 210 KB / s | 140 KB / s |
| iops | 80 | 51 | 34 | |
| avg lat | 12.39 | 7.2 | 18.39 | |
| noop | bw | 331 KB / s | 210 KB / s | 140 KB / s |
| iops | 80 | 51 | 34 | |
| avg lat | 12.36 | 7.16 | 18.42 | |
| Bfq | bw | 384 KB / s | 208 KB / s | 139 KB / s |
| iops | 93 | fifty | 33 | |
| avg lat | 10.65 | 6.28 | 03/20 | |
| mq-deadline | bw | 333 KB / s | 211 KB / s | 142 KB / s |
| iops | 81 | 51 | 34 | |
| avg lat | 12.29 | 7.08 | 18.32 | |
| kyber | bw | 385 KB / s | 193 KB / s | 129 KB / s |
| iops | 94 | 47 | 31 | |
| avg lat | 10.63 | 9.15 | 01/18 | |
| none | bw | 332 KB / s | 212 KB / s | 142 KB / s |
| iops | 81 | 51 | 34 | |
| avg lat | 12.3 | 7.1 | 18.3 | |
* hereinafter in the writers column, the median from the writers streams is taken, similarly in the reader_40 columns. The delay value in milliseconds.
Take a look at the test results of traditional (single-queue) schedulers. The values obtained as a result of the tests practically do not differ from each other. It should be noted that the latency bursts that are found on the graphs of the deadline and noop tests also occurred during CFQ tests, although less frequently. When testing the blk-mq schedulers, this was not observed, the maximum delay reached as much as 11 seconds, regardless of the type of request - writing or reading.
Everything is much more interesting when using blk-mq-schedulers. We are primarily interested in the delay in processing requests for reading data. In the context of such a task, BFQ differs for the worse. The maximum delay for this scheduler reached 6 seconds for writing and up to 2.5 seconds for reading. The smallest maximum delay value was shown by kyber - 129ms for writing and 136 for reading. 20ms longer maximum delay at none for all streams. For mq-deadline, it was 173ms for writing and 289ms for reading.
As the results show, it was not possible to achieve any significant reduction in the delay by changing the scheduler. But you can highlight the BFQ scheduler, which showed a good result in terms of the number of recorded / read data. On the other hand, when looking at the graph obtained during BFQ testing, the uneven distribution of the load on the disk seems strange, despite the fact that the load from the fio side is quite uniform and uniform.
SSD tests
For SSD tests, the server was used:
- Intel® Xeon® CPU E5-1650 v3 @ 3.50GHz
- 64 GB RAM
- 1.6TB INTEL Intel SSD DC S3520 Series
- Ubuntu linux 14.04 OS, kernel 4.12.0-041200-generic ( kernel.ubuntu.com )
Fio options
[global]
ioengine=libaio
blocksize=4k
direct=1
buffered=0
iodepth=4
runtime=7200
random_generator=lfsr
filename=/dev/sda1
[writers]
numjobs=10
rw=randwrite
[reader_20]
numjobs=2
rw=randrw
rwmixread=20
The test is similar to the previous one for hdd, but differs in the number of processes that will access the disk - 10 for writing and two for writing and reading and with a write / read ratio of 80/20, as well as the queue depth. A 1598GB partition was created on the drive, two gigabytes left unused.
Test results
CFQ:
Deadline:
Noop:
BFQ:
Mq-deadline:
Kyber:
None:
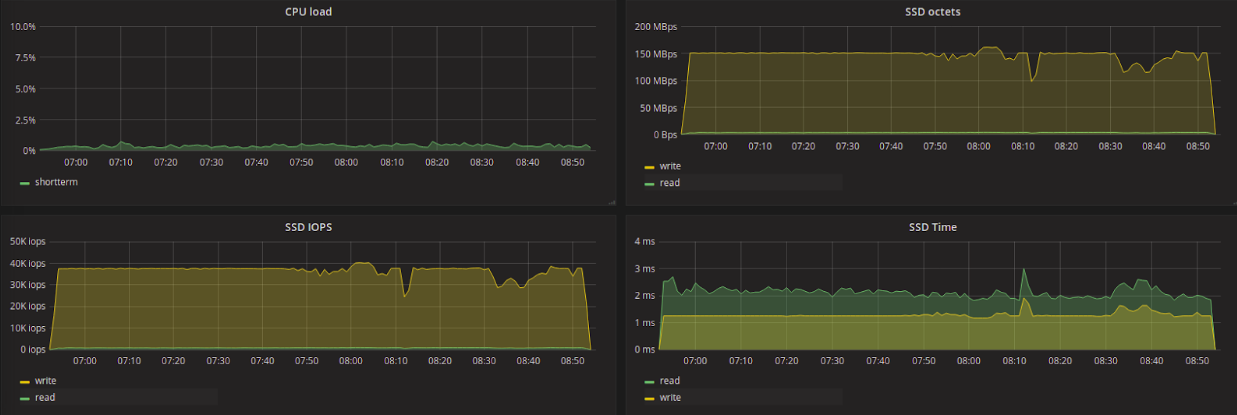
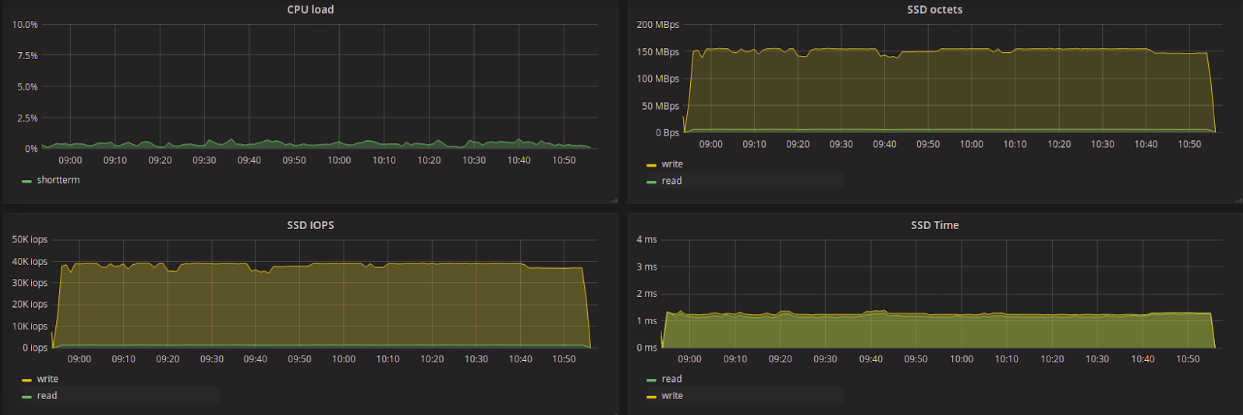
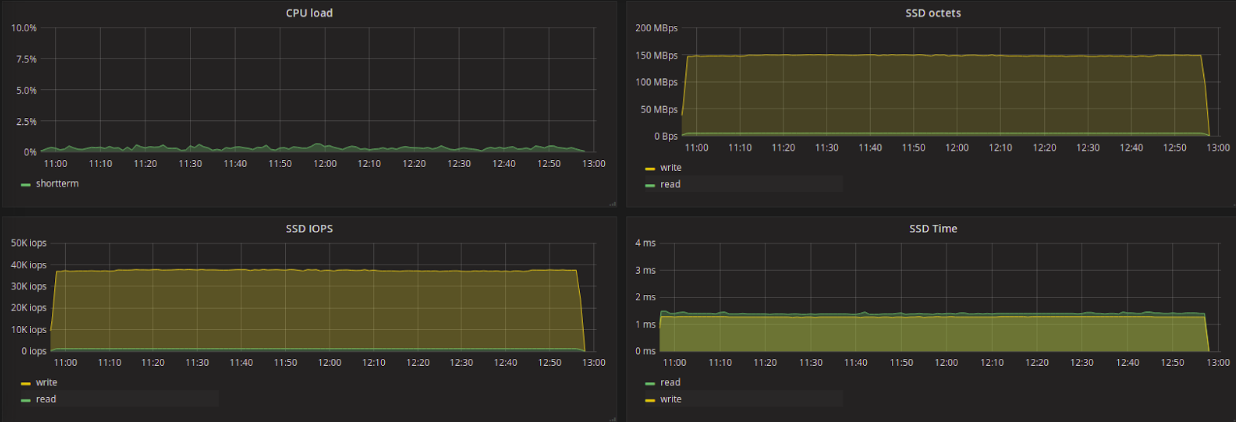



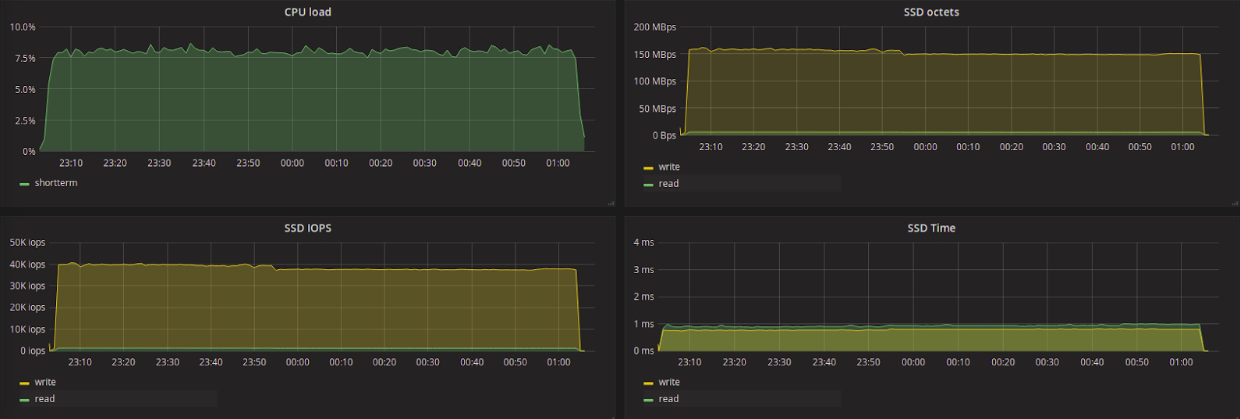







Test results in the table
| writers randwrite | reader_20 randwrite | reader_20 read | ||
| CFQ | bw | 13065 KB / s | 6321 KB / s | 1578 KB / s |
| iops | 3265 | 1580 | 394 | |
| avg lat | 1.223 | 2,000 | 2.119 | |
| deadline | bw | 12690 KB / s | 10279 KB / s | 2567 KB / s |
| iops | 3172 | 2569 | 641 | |
| avg lat | 1.259 | 1.261 | 1.177 | |
| noop | bw | 12509 KB / s | 9807 KB / s | 2450 KB / s |
| iops | 3127 | 2451 | 613 | |
| avg lat | 1.278 | 1.278 | 1.405 | |
| Bfq | bw | 12803 KB / s | 10000 KB / s | 2497 KB / s |
| iops | 3201 | 2499 | 624 | |
| avg lat | 1.248 | 1.248 | 1.398 | |
| mq-deadline | bw | 12650 KB / s | 9715 KB / s | 2414 KB / s |
| iops | 3162 | 2416 | 604 | |
| avg lat | 1.264 | 1.298 | 1.423 | |
| kyber | bw | 8764 KB / s | 8572 KB / s | 2141 KB / s |
| iops | 2191 | 2143 | 535 | |
| avg lat | 1.824 | 1.823 | 0.167 | |
| none | bw | 12835 KB / s | 10174 KB / s | 2541 KB / s |
| iops | 3208 | 2543 | 635 | |
| avg lat | 1.245 | 1.227 | 1.376 | |
Pay attention to the average reading delay. Among all the planners, kyber, which showed the least delay, and CFQ, the largest, stand out strongly. Kyber was designed to work with fast devices and aims to reduce latency in general, with priority for synchronous requests. For read requests, the delay is very low and the amount of data read is less than when using other schedulers (with the exception of CFQ).
Let's try to compare the difference in the number of data read per second between kyber and, for example, deadline, as well as the difference in the reading delay between them. We see that kyber showed a 7-fold lower read delay than deadline, with a decrease in read throughput of only 1.2 times. At the same time, kyber showed worse results for write requests - a 1.5-fold increase in delay and a decrease in throughput by 1.3 times.
Our initial goal is to get the least read latency with the least bandwidth damage. According to the test results, it can be considered that kyber is better than other planners to solve this problem.
It is interesting to note that CFQ and BFQ showed a relatively low write delay, but in this case, when working with CFQ, processes that performed only write to disk got the highest priority. What conclusion can be drawn from this? Probably, BFQ more “honestly” prioritizes requests, as announced by the developers.
The maximum latency was much higher for * FQ schedulers and mq-deadline - up to ~ 3.1 seconds for CFQ and up to ~ 2.7 seconds for BFQ and mq-deadline. For other planners, the maximum delay during the tests was 35-50 ms.
NVMe Tests
For NVMe tests, the Micron 9100 was installed in the server on which the SSD tests were carried out. The disk layout is similar to the SSD - a section for the 1598GB test and 2GB of unused space. We used the same settings as in the previous test, fio settings, only the queue depth (iodepth) was increased to 8.
[global]
ioengine=libaio
blocksize=4k
direct=1
buffered=0
iodepth=8
runtime=7200
random_generator=lfsr
filename=/dev/nvme0n1p1
[writers]
numjobs=10
rw=randwrite
[reader_20]
numjobs=2
rw=randrw
rwmixread=20
Test results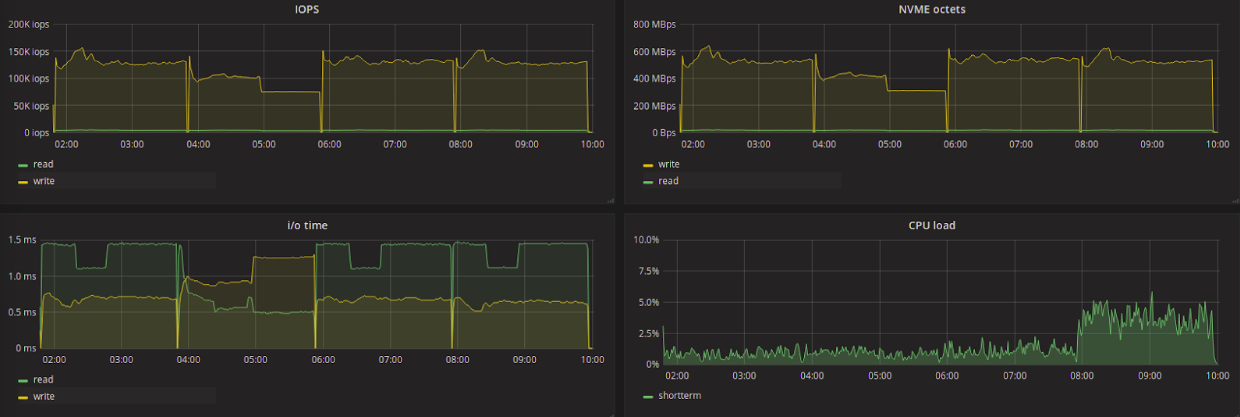

Test results in the table
| writers randwrite | reader_20 write | reader_20 read | ||
| Bfq | bw | 45752 KB / s | 30541 KB / s | 7634 KB / s |
| iops | 11437 | 7635 | 1908 | |
| avg lat | 0.698 | 0.694 | 1.409 | |
| mq-deadline | bw | 46321 KB / s | 31112 KB / s | 7777 KB / s |
| iops | 11580 | 7777 | 1944 | |
| avg lat | 0.690 | 0.685 | 1.369 | |
| kyber | bw | 30460 KB / s | 27709 KB / s | 6926 KB / s |
| iops | 7615 | 6927 | 1731 | |
| avg lat | 1.049 | 1,000 | 0.612 | |
| none | bw | 45940 KB / s | 30867 KB / s | 7716 KB / s |
| iops | 11484 | 7716 | 1929 | |
| avg lat | 0.695 | 0.694 | 1.367 | |
The graph shows the test results with a change of the scheduler and a pause. Testing order: none, kyber, mq-deadline, BFQ.
In the table and on the graph, the active operation of the kyber algorithm to reduce the delay is again visible: 0.612ms versus 1.3-1.4 for other schedulers. It is generally believed that it does not make sense to use any kind of scheduler for NVMe disks, but if the priority is to reduce latency and you can sacrifice the number of I / O operations, then it makes sense to consider kyber. Looking at the graphs, you can notice an increase in CPU load when using BFQ (last tested).
Conclusions and recommendations
Our article is a very general introduction to the topic. And all the data from our tests should be taken taking into account the fact that in real practice everything is much more complicated than in experimental conditions. It all depends on a number of factors: the type of load, the file system used, and much more. A lot depends on the hardware component: drive model, RAID / HBA / JBOD.
Generally speaking: if an application uses ioprio to prioritize specific processes, then choosing a scheduler in the direction of CFQ / BFQ will be justified. But it is always worth starting from the type of load and the composition of the entire disk subsystem. For some solutions, developers give very specific recommendations: for example, they recommend for clickhouseuse CFQ for HDD and noop for SSD drives. If the drives require more bandwidth, the ability to perform more I / O and the average delay is not important, then you should look in the direction of BFQ / CFQ, and for ssd-drives also noop and none.
If it is necessary to reduce the delay and each operation separately, and in particular the read operation, should be performed as quickly as possible, then in addition to using ssd, it is worth using the deadline scheduler specially designed for this, or one of the new ones - mq-deadline, kyber.
Our recommendations are general in nature and are far from suitable for all cases. When choosing a planner, in our opinion, the following points should be considered:
- The hardware component plays an important role: the situation is quite possible when the RAID controller uses the built-in query scheduling algorithms - in this case, the choice of the none or noop scheduler will be justified.
- The type of load is very important: not in experimental, but in “combat conditions” the application may show other results. The fio utility used for tests holds the same constant load, but in real practice, applications rarely access the disk uniformly and constantly. The real queue depth, average per minute, can stay in the range of 1-3, but in peaks rise to 10-13-150 requests. It all depends on the type of load.
- We tested only writing / reading random data blocks, and when working with the schedulers, sequence is important. With linear load, you can get a lot of bandwidth if the scheduler groups requests well.
- Each scheduler has options that can be configured additionally. All of them are described in the documentation for the planners.
An attentive reader must have noticed that we used different cores to test schedulers for HDD and SSD / NVMe drives. The fact is that during testing on the 4.12 kernel with the HDD, the work of the BFQ and mq-deadline schedulers looked rather strange - the delay decreased, then grew and kept very high for several minutes. Since this behavior did not look quite adequate and the 4.13 kernel came out, we decided to run tests with the HDD on the new kernel.
Do not forget that the code of the planners may change. In the next kernel release, it turns out that the mechanism due to which a particular scheduler showed degradation of performance on your load has already been rewritten and now, at least, does not reduce performance.
The Linux I / O scheduler features are a complex topic and can hardly be considered in a single publication. We plan to return to this topic in future articles. If you have experience testing planners in combat, we will be happy to read about it in the comments.