Track for extracting word meanings from texts and resolving lexical ambiguity
The largest conference on computer linguistics “Dialogue” is held annually in Russia, at which experts discuss methods of computer analysis of the Russian language, assess the level of computer linguistics and determine the direction of its development. Every year, within the framework of the "Dialogue" , competitions are organized for automatic processing of the Russian language - Dialogue Evaluation. In this post we will talk about how the Dialogue Evaluation competition is organized, and in more detail about how one of its components, RUSSE, is going on and what awaits its participants this year. Go.

In total, over the past seven years, 13 Dialogue Evaluation competitions have been held on a variety of topics: from a competition of morphological analyzers to a campaign to assess the quality of machine translation systems. All of them are similar to the international competitions of SemEval text analysis systems , but with a focus on the features of word processing in Russian - a rich morphology or a freer word order than in English. The assignments at Dialogue Evaluation are similar in structure to the tasks at Kaggle in the field of data analysis, SemEval in the field of computer linguistics, TREC in the field of information retrieval and ILSVRC in the field of pattern recognition.
The participants of the competition are given a task that must be solved within the agreed time frame (usually in a few weeks). SemEval and Dialogue Evaluation competitions are held in two stages. Initially, participants receive a description of the problem and a training sample that can be used to develop methods for solving the problem and assess the quality of the methods obtained. For example, in the track 2015there were pairs of semantically related words that participants could use to develop models of vector representations of words. The organizers discuss a list of external resources that can or cannot be used. At the second stage, participants receive a test sample. They must apply the models developed in the first stage to it. Unlike the training sample, the test sample does not contain any markup. The markup of the test sample at this stage is available only to the organizers, which guarantees the integrity of the competition. As a result, participants send their decisions on a test sample to the organizers, who evaluate the results and publish the rank of the participants.
As a rule, after the end of the competition, test samples are made publicly available. They can be used in further research. If the competition is held as part of a scientific conference, participants may publish reports on participation in the proceedings of the conference.
RUSSE - competition for evaluating the methods of computational lexical semantics for the Russian language
RUSSE (Russian Semantic Evaluation) - a series of activities for the systematic evaluation of methods of computational lexical semantics of the Russian language. The first RUSSE competition took place in 2015 during the Dialogue conference and was devoted to a comparison of methods for determining semantic similarity of words . To assess the quality of distribution models of semantics, data sets in Russian were created for the first time, similar to the widely used datasets in English - such as WordSim353 . More than ten teams evaluated the quality of such models of vector representations of words for the Russian language as word2vec and GloVe .
Second RUSSE Competitionwill be held this year. It will focus on evaluating vector representations of word meanings ( word sense embeddings ) and other models for extracting meanings and resolving lexical ambiguity ( word sense induction & disambiguation ).
RUSSE 2018: extracting word meanings from texts and resolving lexical ambiguity
Many words of a language have several meanings. However, simple models of vector representations of words, such as word2vec, do not take this into account and mix different meanings of the word in one vector. This problem is intended to be solved by the task of extracting the meanings of words from texts and automatically detecting the meanings of an ambiguous word in the body of texts. As part of the SemEval competitioninvestigated methods for the automatic extraction of word meanings and the resolution of lexical ambiguity for Western European languages - English, French and German. However, a systematic assessment of such methods for the Slavic languages was not carried out. The competition in 2018 will draw the attention of researchers to the problem of automatic resolution of lexical ambiguity and identify effective approaches to solving this problem using the example of the Russian language.
One of the main difficulties in processing Russian and other Slavic languages is the lack or limited availability of high-quality lexical resources such as WordNetfor english language. We believe that RUSSE results will be useful for the automatic processing of not only Slavic languages, but also other languages with limited lexical and semantic resources.
Task description
RUSSE 2018 participants are invited to solve the problem of clustering short texts. In particular, at the testing stage, participants receive a set of ambiguous words, for example, the word “castle”, and a set of text fragments (contexts) in which target ambiguous words are mentioned. For example, “Vladimir Monomakh’s castle in Lubech” or “moving the bolt with a key in the castle”. Participants should cluster the resulting contexts so that each cluster matches a single word value. The number of values and, accordingly, the number of clusters is not known in advance. In this example, we need to group the contexts into two clusters corresponding to the two meanings of the word “castle”: “a device that blocks access to somewhere” and “construction”.
For the competition, the organizers prepared three data sets from different sources. For each such set, you need to fill in the column "predicted value identifier" and upload the file with the answers using the CodaLab platform . CodaLab gives the participant the opportunity to immediately see their results, calculated on the part of the test data set.
The task set in this competition is close to the task formulated for the English language at the SemEval-2007 and SemEval-2010 competitions . Note that in tasks of this type, participants are not provided with a standard list of word meanings - the so-called. inventory of values. Therefore, to mark contexts, a participant can use arbitrary identifiers, for example, lock # 1 or a lock (device).
The main stages of the competition
From December 15 to January 15, participants can download the results of solving the problem on the CodaLab platform. In total, it is proposed to mark out three sets of data designed as separate tasks on CodaLab :
The competition offers three data sets for constructing models based on various cases and inventories of word meanings, described in the table below:

The first data set ( wiki-wiki ) uses the division proposed in Wikipedia as word meanings; contexts taken from Wikipedia articles. The bts-rnc dataset uses the Great Explanatory Dictionary of the Russian Language edited by S. A. Kuznetsov ( BTS ) as an inventory of word meanings ; contexts taken from the National Corps of the Russian Language ( NKRYA ). Finally, active-dict uses the meanings of words from the Active Dictionary of the Russian Language edited by Yu. D. Apresyan; contexts are also taken from the Active dictionary of the Russian language- These are examples and illustrations from dictionary entries.
For training and system development, participants are provided with six data sets (three main and three additional) using different inventories of word meanings. All training data sets are listed in the table:
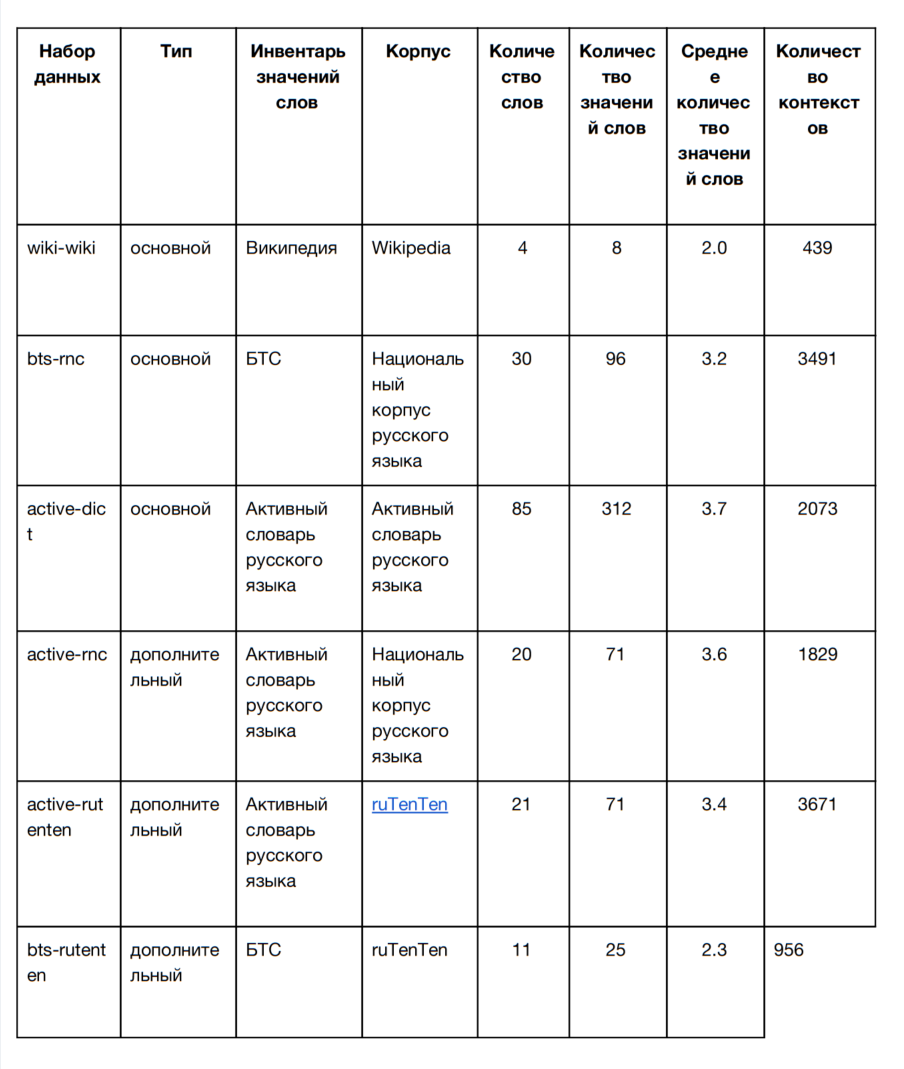
Test data sets (wiki-wiki, bts-rnc, active-dict) are organized in the same way as training ones. But they do not fill in the field with the value of the target word - 'identifier of the predicted value'. This field is filled in by participants. Their answers will be compared with the reference. Participating systems are compared based on a quality measure. The training and test data sets are marked out on the same principle, but the target ambiguous words in them are different.
Quality measure
As in other similar competitions, for example, SemEval-2010 , in our competition the quality of the system is evaluated by comparing its answers with the gold standard. The gold standard is a multitude of sentences in which people define the meanings of targeted ambiguous words. The target word in each sentence is manually assigned one or another identifier from the specified inventory of word meanings. After the system of each participant indicates the identifier of the predicted value of the target word in each sentence of the test sample, we compare the grouping of sentences according to the word values from the participant system with the gold standard. For comparison, we will use the adjusted Rand coefficient . Such a comparison can be considered a comparison of two clustering .
Competition tracks
The competition includes two tracks:
Our approach to evaluating systems suggests that practically any model for resolving lexical ambiguity can participate in the competition: both approaches based on machine learning without a teacher (distributed vector representations, graph methods), and approaches based on lexical resources such as WordNet .
Reference systems
To make the task more understandable, we publish several ready-made solutions with which you can compare your results. For a track without the use of linguistic resources (knowledge-free), we recommend that you pay attention to systems for resolving lexical ambiguity without a teacher, for example, AdaGram . For a track using linguistic resources (knowledge-rich), we recommend using vector representations of word meanings constructed using existing lexical and semantic resources, for example RuTez and RuWordNet . This can be done using methods such as AutoExtend .
Recommendations to participants
Training datasets have already been published. As a starting point, you can take our models published in the repository on GitHub (there is a detailed guide there), and refine and improve them. Please follow the instructions, but do not be afraid to ask questions - the organizers will be happy to help!
Discussion and publication of results
Participants are invited to write an article about their system and submit it to the
international conference on computer linguistics "Dialogue 2018" . The proceedings of this conference are indexed by Scopus. As part of a special section of this conference, the results of the competition will be discussed.
Organizers
The competition organizers will be happy to answer your questions in the group on Google and on Facebook . More information is available on the competition page .
Sponsors and partners
Dialogue Evaluation - quality assessment competition of text analysis methods in Russian
In total, over the past seven years, 13 Dialogue Evaluation competitions have been held on a variety of topics: from a competition of morphological analyzers to a campaign to assess the quality of machine translation systems. All of them are similar to the international competitions of SemEval text analysis systems , but with a focus on the features of word processing in Russian - a rich morphology or a freer word order than in English. The assignments at Dialogue Evaluation are similar in structure to the tasks at Kaggle in the field of data analysis, SemEval in the field of computer linguistics, TREC in the field of information retrieval and ILSVRC in the field of pattern recognition.
The participants of the competition are given a task that must be solved within the agreed time frame (usually in a few weeks). SemEval and Dialogue Evaluation competitions are held in two stages. Initially, participants receive a description of the problem and a training sample that can be used to develop methods for solving the problem and assess the quality of the methods obtained. For example, in the track 2015there were pairs of semantically related words that participants could use to develop models of vector representations of words. The organizers discuss a list of external resources that can or cannot be used. At the second stage, participants receive a test sample. They must apply the models developed in the first stage to it. Unlike the training sample, the test sample does not contain any markup. The markup of the test sample at this stage is available only to the organizers, which guarantees the integrity of the competition. As a result, participants send their decisions on a test sample to the organizers, who evaluate the results and publish the rank of the participants.
As a rule, after the end of the competition, test samples are made publicly available. They can be used in further research. If the competition is held as part of a scientific conference, participants may publish reports on participation in the proceedings of the conference.
RUSSE - competition for evaluating the methods of computational lexical semantics for the Russian language
RUSSE (Russian Semantic Evaluation) - a series of activities for the systematic evaluation of methods of computational lexical semantics of the Russian language. The first RUSSE competition took place in 2015 during the Dialogue conference and was devoted to a comparison of methods for determining semantic similarity of words . To assess the quality of distribution models of semantics, data sets in Russian were created for the first time, similar to the widely used datasets in English - such as WordSim353 . More than ten teams evaluated the quality of such models of vector representations of words for the Russian language as word2vec and GloVe .
Second RUSSE Competitionwill be held this year. It will focus on evaluating vector representations of word meanings ( word sense embeddings ) and other models for extracting meanings and resolving lexical ambiguity ( word sense induction & disambiguation ).
RUSSE 2018: extracting word meanings from texts and resolving lexical ambiguity
Many words of a language have several meanings. However, simple models of vector representations of words, such as word2vec, do not take this into account and mix different meanings of the word in one vector. This problem is intended to be solved by the task of extracting the meanings of words from texts and automatically detecting the meanings of an ambiguous word in the body of texts. As part of the SemEval competitioninvestigated methods for the automatic extraction of word meanings and the resolution of lexical ambiguity for Western European languages - English, French and German. However, a systematic assessment of such methods for the Slavic languages was not carried out. The competition in 2018 will draw the attention of researchers to the problem of automatic resolution of lexical ambiguity and identify effective approaches to solving this problem using the example of the Russian language.
One of the main difficulties in processing Russian and other Slavic languages is the lack or limited availability of high-quality lexical resources such as WordNetfor english language. We believe that RUSSE results will be useful for the automatic processing of not only Slavic languages, but also other languages with limited lexical and semantic resources.
Task description
RUSSE 2018 participants are invited to solve the problem of clustering short texts. In particular, at the testing stage, participants receive a set of ambiguous words, for example, the word “castle”, and a set of text fragments (contexts) in which target ambiguous words are mentioned. For example, “Vladimir Monomakh’s castle in Lubech” or “moving the bolt with a key in the castle”. Participants should cluster the resulting contexts so that each cluster matches a single word value. The number of values and, accordingly, the number of clusters is not known in advance. In this example, we need to group the contexts into two clusters corresponding to the two meanings of the word “castle”: “a device that blocks access to somewhere” and “construction”.
For the competition, the organizers prepared three data sets from different sources. For each such set, you need to fill in the column "predicted value identifier" and upload the file with the answers using the CodaLab platform . CodaLab gives the participant the opportunity to immediately see their results, calculated on the part of the test data set.
The task set in this competition is close to the task formulated for the English language at the SemEval-2007 and SemEval-2010 competitions . Note that in tasks of this type, participants are not provided with a standard list of word meanings - the so-called. inventory of values. Therefore, to mark contexts, a participant can use arbitrary identifiers, for example, lock # 1 or a lock (device).
The main stages of the competition
- November 1, 2017 - publication of the training dataset
- December 15, 2017 - release of a test data set
- February 1, 2018 - completion of acceptance of results for evaluation
- February 15, 2018 - announcement of the competition results
From December 15 to January 15, participants can download the results of solving the problem on the CodaLab platform. In total, it is proposed to mark out three sets of data designed as separate tasks on CodaLab :
- based on Wikipedia ,
- based on illustrations and examples from the explanatory dictionary ,
- based on texts from the internet
Datasets
The competition offers three data sets for constructing models based on various cases and inventories of word meanings, described in the table below:
The first data set ( wiki-wiki ) uses the division proposed in Wikipedia as word meanings; contexts taken from Wikipedia articles. The bts-rnc dataset uses the Great Explanatory Dictionary of the Russian Language edited by S. A. Kuznetsov ( BTS ) as an inventory of word meanings ; contexts taken from the National Corps of the Russian Language ( NKRYA ). Finally, active-dict uses the meanings of words from the Active Dictionary of the Russian Language edited by Yu. D. Apresyan; contexts are also taken from the Active dictionary of the Russian language- These are examples and illustrations from dictionary entries.
For training and system development, participants are provided with six data sets (three main and three additional) using different inventories of word meanings. All training data sets are listed in the table:
Test data sets (wiki-wiki, bts-rnc, active-dict) are organized in the same way as training ones. But they do not fill in the field with the value of the target word - 'identifier of the predicted value'. This field is filled in by participants. Their answers will be compared with the reference. Participating systems are compared based on a quality measure. The training and test data sets are marked out on the same principle, but the target ambiguous words in them are different.
Quality measure
As in other similar competitions, for example, SemEval-2010 , in our competition the quality of the system is evaluated by comparing its answers with the gold standard. The gold standard is a multitude of sentences in which people define the meanings of targeted ambiguous words. The target word in each sentence is manually assigned one or another identifier from the specified inventory of word meanings. After the system of each participant indicates the identifier of the predicted value of the target word in each sentence of the test sample, we compare the grouping of sentences according to the word values from the participant system with the gold standard. For comparison, we will use the adjusted Rand coefficient . Such a comparison can be considered a comparison of two clustering .
Competition tracks
The competition includes two tracks:
- In a track without the use of linguistic resources (knowledge-free track), participants should cluster contexts according to different values and assign each identifier some kind of identifier, using only the corpus of texts.
- In a knowledge-rich track, participants can use any additional resources, such as dictionaries, to identify the meaning of the target words.
Our approach to evaluating systems suggests that practically any model for resolving lexical ambiguity can participate in the competition: both approaches based on machine learning without a teacher (distributed vector representations, graph methods), and approaches based on lexical resources such as WordNet .
Reference systems
To make the task more understandable, we publish several ready-made solutions with which you can compare your results. For a track without the use of linguistic resources (knowledge-free), we recommend that you pay attention to systems for resolving lexical ambiguity without a teacher, for example, AdaGram . For a track using linguistic resources (knowledge-rich), we recommend using vector representations of word meanings constructed using existing lexical and semantic resources, for example RuTez and RuWordNet . This can be done using methods such as AutoExtend .
Recommendations to participants
Training datasets have already been published. As a starting point, you can take our models published in the repository on GitHub (there is a detailed guide there), and refine and improve them. Please follow the instructions, but do not be afraid to ask questions - the organizers will be happy to help!
Discussion and publication of results
Participants are invited to write an article about their system and submit it to the
international conference on computer linguistics "Dialogue 2018" . The proceedings of this conference are indexed by Scopus. As part of a special section of this conference, the results of the competition will be discussed.
Organizers
- Alexander Panchenko , University of Hamburg
- Konstantin Lopukhin, Scrapinghub Inc.
- Anastasia Lopukhina , Laboratory of Neurolinguistics, Higher School of Economics and the Russian Academy of Sciences
- Dmitry Ustalov , University of Mannheim and IMM UB RAS
- Nikolay Arefyev, Moscow State University and Samsung Research Center
- Natalya Lukashevich , Moscow State University
- Alexey Leontiev, ABBYY
Contacts
The competition organizers will be happy to answer your questions in the group on Google and on Facebook . More information is available on the competition page .