Bloody Enterprise Devops
That's what you can strive for.
We have more than 350 of our software developers and testers throughout the country, plus we often interact with engineers and customer developers. To switch to the practical use of devops, we needed to ensure not only the implementation of the methodology, but also to accustom our beloved Russian customers to some basic culture. Just a couple of dialogs to understand:
- Why did everything fall?
- Because you skated it at the stand, tested everything, and then deployed to the prod. Here you have a setting that did not fall into the instructions, and lived only in the head of the old admin.
Or:
- Why doesn't it launch all over the country?
- Because you have several dozen different regional installations, each was done with your hands, and each one has different configs. And in a couple of cases the engineer made a mistake.
- Correct until tomorrow? Very necessary! Only access remotely we will not give you.
- ..! Of course, we have a team of highly paid specialists who love to travel to the Far East. No problems.
Cultural cultures
- What about the test bench?
“He's busy with a demonstration for the findirector.”
- And where should I test?
- Well, roll yourself a little one the same, then turn in a private cloud.
- Two hours to the stand. I just adore you!
- Wait, do you have a template?
Or here:
Parallel contractor on the project:
- Hello, dear state customer, and we brought you the binary!
We intervene:
- No, no, no, the dear state customer has a repository, assembly, everything. Fold the code here, check it in, see how it unfolds ...
- OH! WE DO NOT WORK!
“How many administrators do you have?”
- Well, about a hundred, who counts them.
“Why so many?”
- The circuit is large, but automation has not yet been done, something is expensive ... Although stop!
In general, by basic culture I mean something like the following:
- Infrastructure from the rise in the cloud to the pouring of system software must be obtained in the form of a code.
- Pour a successful build from the build server automatically according to the process, without touching anything (i.e., in the same way, only managing the settings in special cases). Okay, you can press the "Start" button with your hand.
- It is convenient to visually control the progress of all assemblies along the delivery conveyor - from checkin to automatic test run.
As a result, time and money will be saved. And even when you receive the code from the contractors, it will not be such that after two years, the dear customer discovers that the source disk, folded on the rack, has nothing to do with what is spinning on the server, and the contractor is gone.
Planting this culture
This is pain, snot, tears and other dramas. Often, communication takes place roughly like this:
- Yes, that's cool. I read posts on Habré, I know how cool it is. Automation is needed.
- So let's introduce it?
- No, what are you. We have Documentum not the latest version.
- So what?
- And Java is old ...
- Look, already on five projects such a pipeline has been run in. It is with your software configuration. Including Alfrescu and WebSphere.
- Our deadline is on.
- Well, when will it stop burning?
“Well, it's been burning for two years now, probably another year somewhere.” Then we’ll introduce it.
- Do you understand that you do not have free engineers and can the project really be accelerated?
- Yeah, what do you need?
- Download the finished role, plug it into Ansible - and everything will unfold. Here is an engineer who will help you and set everything up. And she’ll also teach you.
- Well, let me consider your proposal in January at a meeting ...
Until last year, in our development projects, only Continuous Integration was strictly required (assembly on TeamCity / Jenkins, code analysis, unit tests). A full-fledged transition to continuous delivery and continuous deployment at the company level was complicated by the variety of used infrastructure, technologies, and the nuances of working with external customers. So until last year, we did not have a single standard and a set of recommendations for engineers engaged in operation (customer services), each working with its own stack.
Few people understand how automation works. Some believe that it is expensive and difficult - "We will not take risks on this project." But for example, after several teams run their stack inside the CROC, many in practice realized that the saved time and human resources were much more realistic than they seemed. And from that moment it started. Therefore, if an engineer from a previous project receives a task from the manager “Deploy a dozen servers to me manually,” he has every right to offer to go towards automation, and I, as a leader, will be on his side.
Since we are not accustomed to instilling culture with administrative measures, we arranged a discussion, selected tools and drew in on the most intricate projects with a variety of technological stacks (integration projects on the WebSphere, ECM projects on Documentum and Alfresco, custom development on java & .Net). As a result, we got satisfied guys (and girls), reinforced concrete arguments for convinced pessimists, and a base of groundwork.
Next is the story of a review of tools and implementation. If you know everything - go straight down, in the "Tools" section it is unlikely that there will be anything interesting for experts, this is more than educational program.
Instruments
350 developers work with their technology stacks, their zoos - plus there is both the Amazon EC2 API and Openstack with VMware in the CROC virtual laboratory. We also had a bunch of scripting tools at the lower level. But it’s not clear at the top that where it fell off, where which build, what the conveyor looks like and what happens. I needed a visualization tool.
We faced the difficult task of assembling a comprehensive solution for automating the supply pipeline from free, free software, which in turn would not be much inferior to industrial proprietary solutions of this class.
The architecture of systems of this class consists of three components:
• At the top level, a solution for automating and visualizing the application delivery pipeline. This is primarily a web interface in which the end user can track the passage of all stages of the release - from the initial assembly of the package from the source code to the passage of all tests, restart any stage, see the logs if the process fails.
• A solution for automating deployment of infrastructure. This is a kind of orchestra, whose task is to create the infrastructure for our application - virtual machines in a particular cloud provider. In this case, the component is responsible for creating the basic infrastructure; the following component is responsible for fine-tuning and configuring the software.
• A configuration management solution needed to configure an already created infrastructure, such as: installing system software, additional applications required for release, configuration of the database and application servers, initiating the execution of various scripts and directly installing the release of our application.
For each of the blocks, we analyzed the most relevant and sought-after tools suitable for us. Consider each of the components in more detail, let's start from the top level.
What we wanted from the tools and what we watched
The main criteria for choosing tools (besides the fact that it should be an open source) were:
• universality in terms of integration: the tool should support all the main source control systems that are used on projects (git, mercurial, TFS), should be friends with CI Jenkins and Teamcity, to be able to work with Selenium and JMeter testing systems, there should be easily customizable interaction with open source infrastructure deployment and configuration management systems;
• the ability to export / import a customized pipeline and settings to a text config (Pipeline-as-a-Code);
• learning curve: ultimately, it was required to train the founding tool of ordinary implementing engineers. The tool should be easy to learn and tune.
Started with jenkins: as CI, he already stood and functioned with us. Would it suit us as a CD and Pipeline Automation solution? As it turned out, no, despite the huge number of plug-ins and integrations, and here's why:
• The Blue Ocean project does not yet have an administrative interface, you can observe beautiful pictures of the release passing through the stages, but you cannot restart a specific step from the same interface;
• the pipeline itself needs to be written in the form of source code, and the language for writing declarative pipelines is still damp - difficulties with administration and training;
• along with Jenkins we operate Teamcity, for some projects it is more convenient.
Due to these reasons, for reasons of stability (there is a stable functioning Jenkins that I did not want to load with additional plugins) and functional separation (after all, Jenkins, like TeamCity, we are used as CI servers for directly building software), we continued the study.
Hygeia , a project of developers of the banking firm CapitalOne, attracted us primarily with an informative user interface, in which, among other things, you can see statistical information on commits and contributors, a summary of sprint tasks, a list of features implemented in the sprint. Nevertheless, despite the comprehensive web ui, the tool turned out to be highly specialized for the tasks of the creators.
Hygeia did not fit our criteria because of the lack of the necessary integration, insufficient documentation at the time of the study, and because of the difficulties with expanding and customizing the tool’s functionality.
Next, we drew attention to the Consourse CIcreated by the Cloud Foundry Foundation community primarily to support Cloud Foundry related projects. Concourse CI is suitable for very large projects with the need to deploy and test several releases per minute, the interface allows you to evaluate the status of several branches of application releases at once. Concourse wasn’t suitable for our tasks because of the lack of flexibility and universality we needed in terms of integration, plus we needed a more detailed picture of the progress of different versions of releases of a particular application branch (in Concourse, the status shows only the latest versions).
Last we reviewed the GoCD project. GoCD has been leading its history since 2007, in 2014 the source code was posted in the community. GoCD met our criteria for universality of integration: everything we needed in GoCD was supported out of the box or was able to be easily configured. GoCD also has an implementation of the Pipeline-as-a-code paradigm that is important for DevOps practitioners.
Among the minuses can be noted:
• nesting of entities that is not intuitive for quick immersion: it is not easy to immediately deal with all stages, jobs, tasks, etc .;
• the need to install agents, and scaling and multithreading require the installation of additional agents.
We decided on the upper level, consider the remaining two blocks
The main criterion for choosing infrastructure deployment tools was support for heterogeneous environments of well-known cloud providers: AWS, Openstack and VMware vSphere. We looked at Bosh, Terraform, and Cloudify.
Bosh , like Concourse CI, was created by the Cloud Foundry Foundation community. A fairly powerful tool with a complex architecture, among the advantages include:
• the ability to monitor services deployed through Bosh;
• the ability to recover from failures of deployed services both automatically and by button;
• object repository for deployable components;
• built-in functionality for version control of deployed components.
However, rich functionality is provided due to the proprietary virtual machine template formats, for this reason and because of the total complexity of the Bosh tool, it did not suit us.
Terraform- Hashicorp's well-known community tool. Like other freely distributed products of the company - architecturally represents a binary file. Easy to install, easy to learn: it is enough to describe the infrastructure necessary for deployment in a declarative format, check how all this will be deployed with the terraform plan command, and start the terraform apply command directly. For industrial applications, the disadvantage of free Terraform may be the lack of a server part, aggregating logs, monitoring the status of running processes (in other words, the lack of centralized management and audit). This point is decided in the paid Terraform, but we were interested in exclusively free tools, so in some cases besides Terraform we decided to use Cloudify.
Cloudify is an infrastructure deployment tool created by GigaSpaces. A distinctive feature of the tool is de facto support in the declarative IaaC templates of the OASIS TOSCA standard. In terms of functionality, Cloudify is close to Bosh: it is possible to monitor services deployed from Cloudify, there is a process for recovering from failures, as well as scaling the deployed service. Unlike Bosh, Cloudify has an intuitive web interface; Cloudify uses standard VM templates for the cloud provider to deploy the infrastructure. The functionality of the tool is expanded due to plugins, it is possible to write your own plugins in Python. But I must say that most of the graphical interfaces in the latest version of the product switched to the paid version.
So, for the deployment of the infrastructure, we chose Terraform due to its simplicity, speed of training and implementation, and the free version of Cloudify due to its functionality and versatility. Quickly made an OpenStack-compatible API for a virtual lab, making friends with Terraform.
It remains to decide on a solution for configuration management. We looked at the big four: Ansible, Chef, Puppet and Salt.
Puppet and Chef- “oldies” in the market of configuration management tools (the first versions were released in 2005 and 2009, respectively). Written in Ruby, well scalable, have a client-server architecture. They didn’t suit our tasks, first of all, because of the high entry threshold: I really didn’t want to train the implementation engineers in the Ruby language, which also contains configuration templates.
Salt is a newer solution written in Python. Configuration templates are already in a convenient YAML format. An interesting feature of Salt is the possibility of both an agent and agentless way of interacting with controlled machines. Nevertheless, the Salt documentation is poorly structured and difficult to understand, we wanted to work with an even simpler tool for new users.
And there is such a tool - thisAnsible . This tool is easy to install, easy to use, easy to learn. Ansible is also written in Python, configuration templates in YAML format. Ansible has an agentless architecture, you do not need to install clients on managed machines - the interaction is through SSH / PowerShell. Of course, in an infrastructure with a capacity of more than a thousand hosts, agentless architecture is not the best choice due to possible drawdowns in speed, but we did not face such a problem: the volume of infrastructure of our projects is much smaller, Ansible was perfect for us.
Decision
As a result, we got the following set of tools for automating the DevOps pipeline.
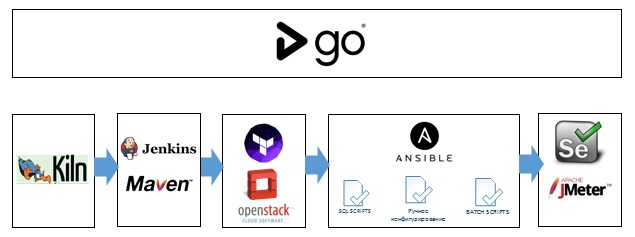
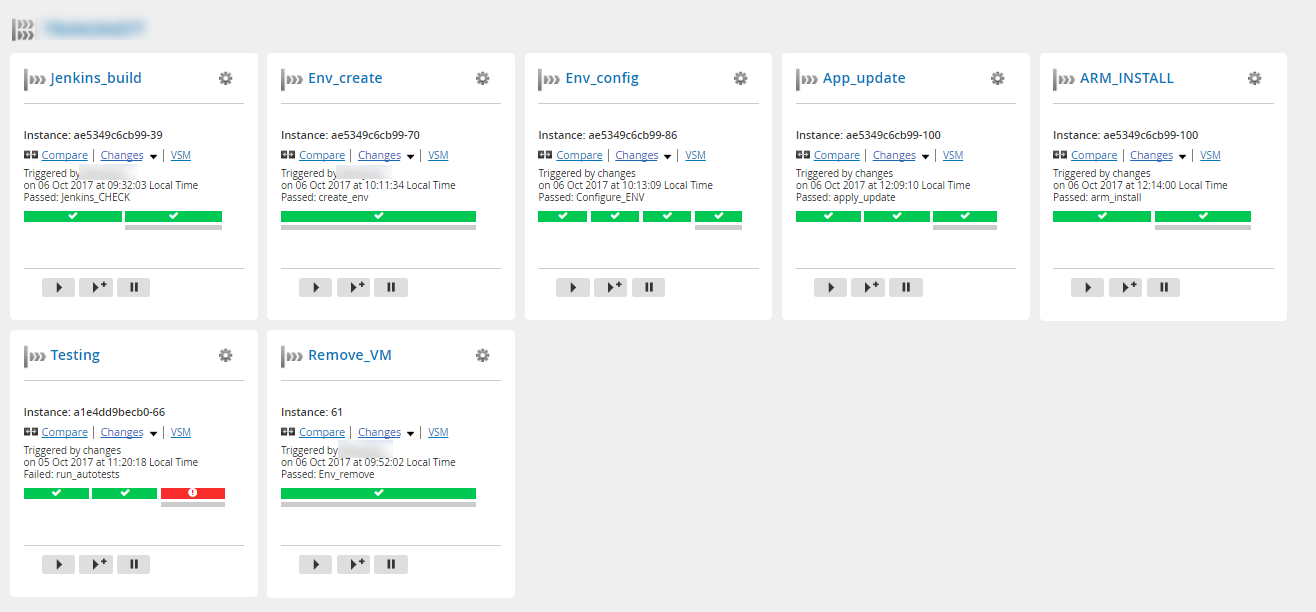
Under the hood Ansible and (depending on the case) Cloudify or Terraform. At the top level is GoCD.
Next, we will talk about the practical application of the selected tools on one of our projects. The case of using DevOps practices for this project was not trivial. Development was carried out in several mercurial repositories, there was no centralized repository of releases. Special attention is paid to the technical documentation on software deployment, which was provided to Release engineers (specially trained people who performed manual installation of updates). To get to the truth, it was required bit by bit to collect information from word documents, entries in Confluence and messages in Slack. Sometimes the documentation was more like fiction with fantasy elements. Quote:
Part Two The Gates Of Hell. Filling the database.
2.1 In this part, we will face especially many difficulties and trials, be careful. First, connect to the database as user SYS with DBA
2.2 privileges. Read spells. Run scripts.
After the audit and unification of all operations, the developers managed to finalize the documentation and present it in a convenient format that is understandable to both humans and configuration management systems.
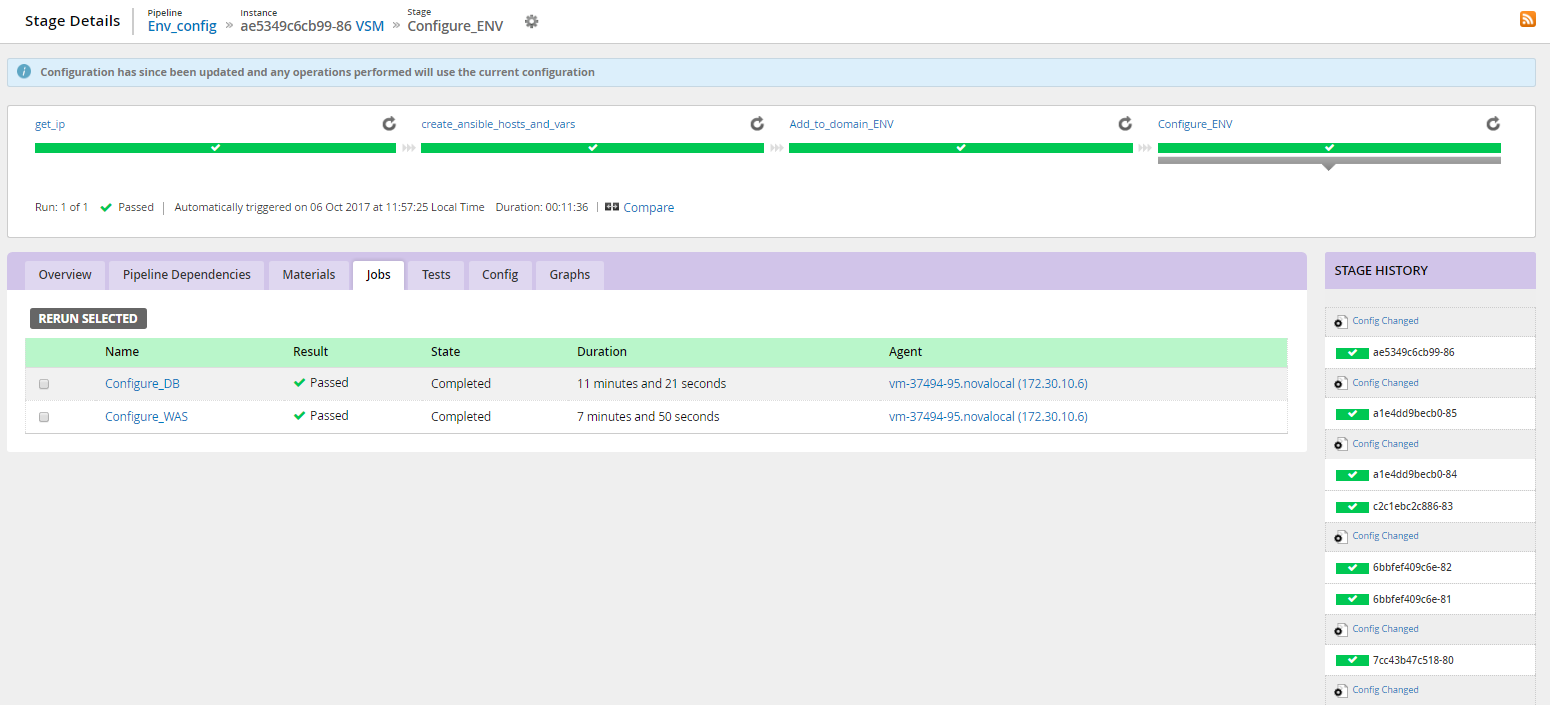
Development was carried out under several stands with minor changes. The test environment contained the most complete CI / CD pipeline , which can be divided into 7 stages:
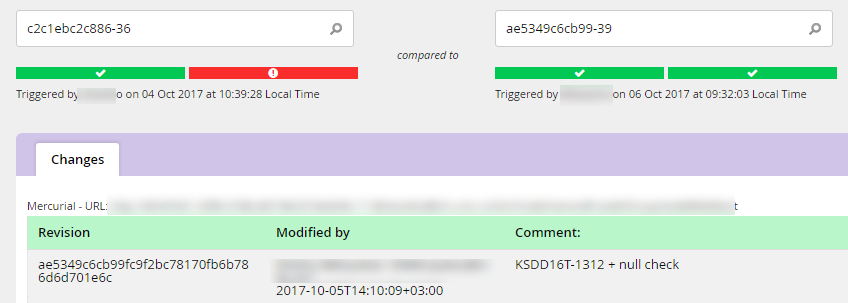
1. Assembling the release in Jenkins
The customer used Jenkins before, however, he made assemblies locally on the developer's machine, and he transmitted the releases in the form of archives. We said that it would be nice to transfer the assembly to a centralized Jenkins server, and store artifacts in Artifactory. This gave us the opportunity to have end-to-end indexing of all artifacts, the ability to quickly install the correct version, test individual script blocks and see what changes caused errors in the script:
2. Deployment of the infrastructure
We transferred the test environment to the CROC virtual laboratory and stopped keeping it in a permanent state. At the request of the tester or automatically after the appearance of a new release in Jenkins, the environment is raised based on the Terraform manifest from the VM templates previously loaded into the Openstack of our CROC virtual laboratory.
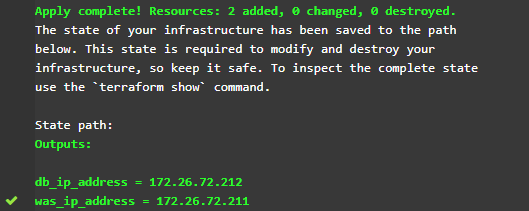
In the form of output variables, we get the addresses of the stands and use them later in our scenario.
3. Configuring stands
The most time-consuming part of the pipeline was to develop a mechanism for automated configuration of stands.
It was necessary to configure the Oracle database, configure the IBM MQ bus and the IBM WAS application server. The situation was complicated by the fact that all these settings had to be done on the Russian-speaking Windows (sic!). If everything is more or less transparent with the database, then no one configured the MQ and WAS in the project from the CLI or other automated means, but could only show where to click in the interface to make everything work.
We managed to write universal playbooks that in 11 minutes do what the engineer took a couple of days to do.

4. Installing basic applications
To install and update applications in WAS, the customer executed bat scripts, we did not delve into them much and built them into the pipeline in the initial form. We check the exit code, and if it is not zero, then we already look at the logs and understand why this or that application did not take off. The script execution logs are stored as script artifacts:

5. Installing an application that provides a user interface
This stage is very similar to the previous one and is performed from the same pipeline template. The only difference is which configuration file is used in the bat script. However, it was necessary to separate it into a separate stage for the convenience of updating, since not all stands require a user interface.
6. Testing
For testing applications used different tools (Selenium, JMeter). The script allows you to vary several test plans, the choice of which is set in the form of variables at this stage. Based on the test results, reports are generated for which we made a custom tab. Now it’s convenient to view them directly from the GoCD interface:
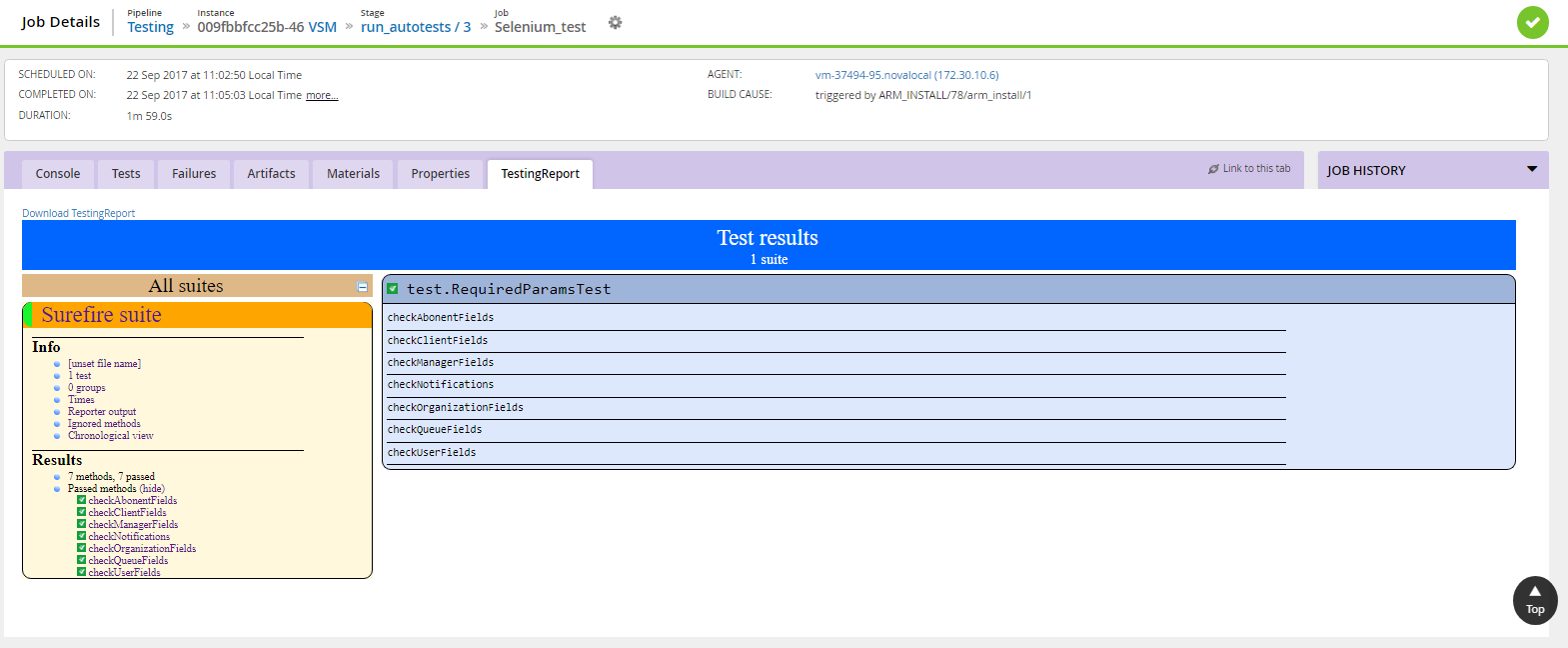
7. Deleting the infrastructure
According to the results of testing, responsible persons receive notifications and decide whether to let this assembly into production or to make changes. If all is well, then the test benches can be removed and not waste the resources of the CROC virtual laboratory.
As a result, we got the following logic for using the DevOps pipeline for this project:
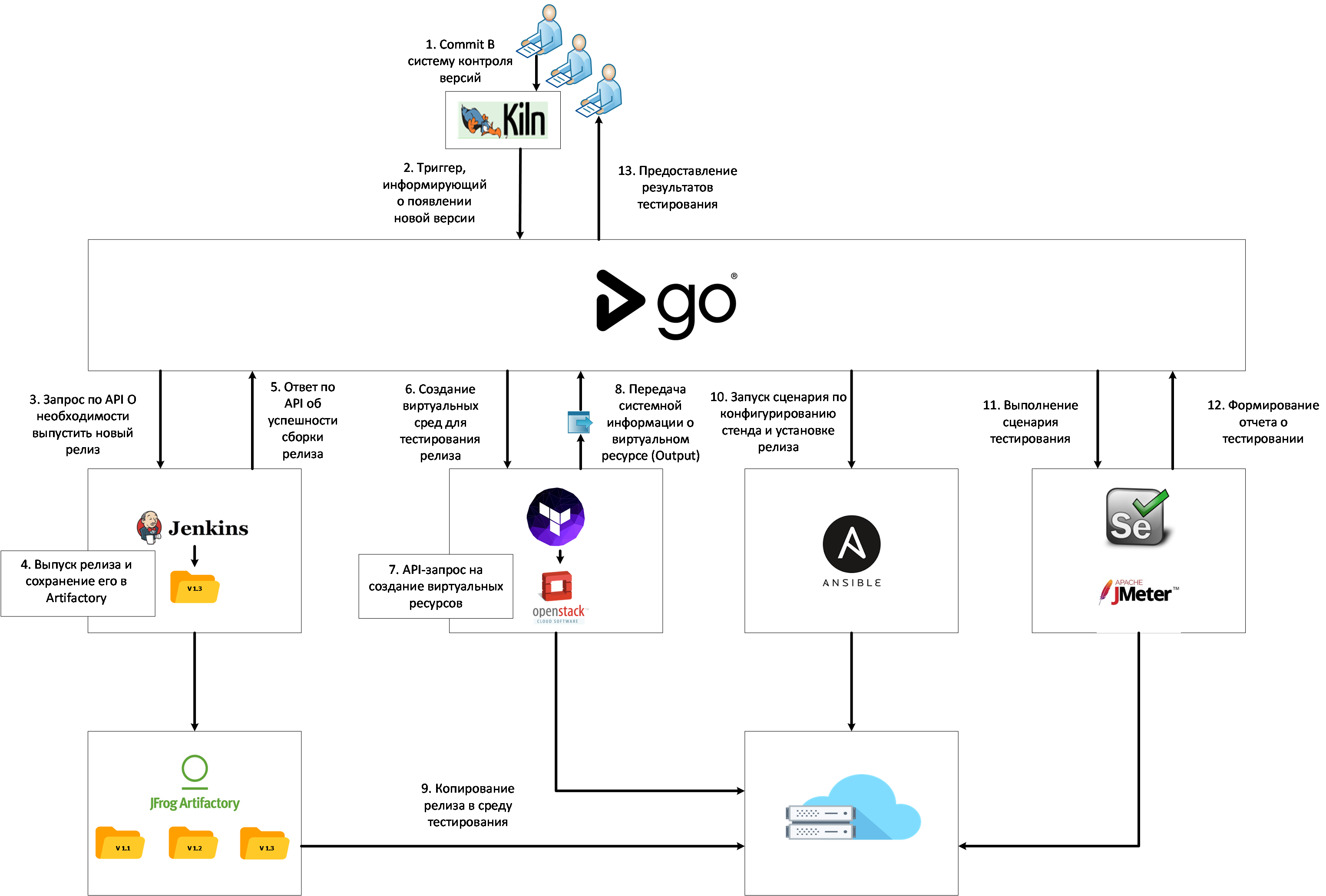
And these interfaces:
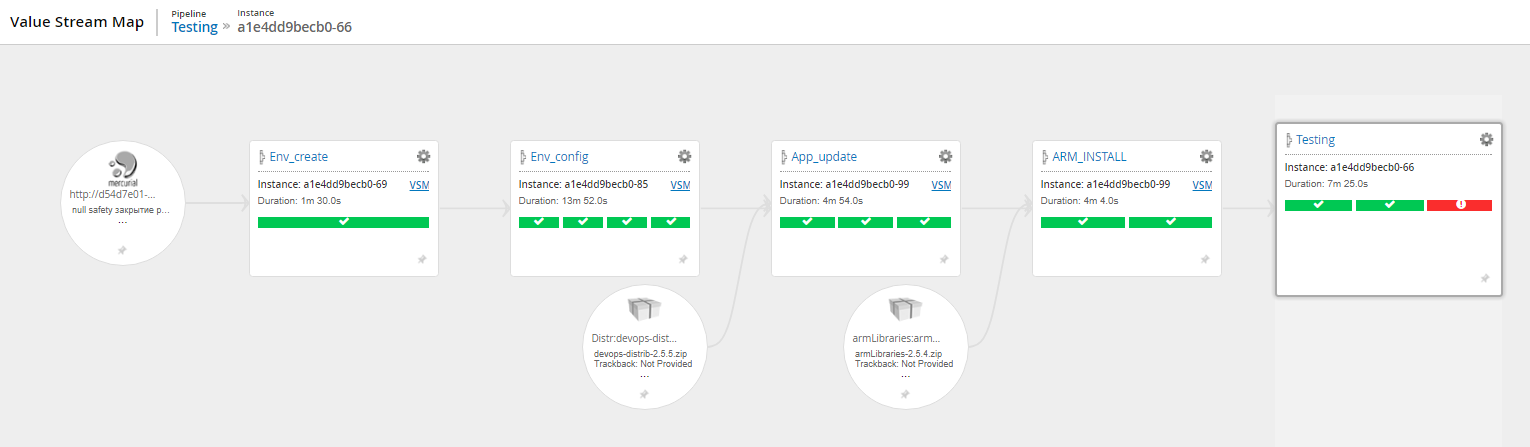
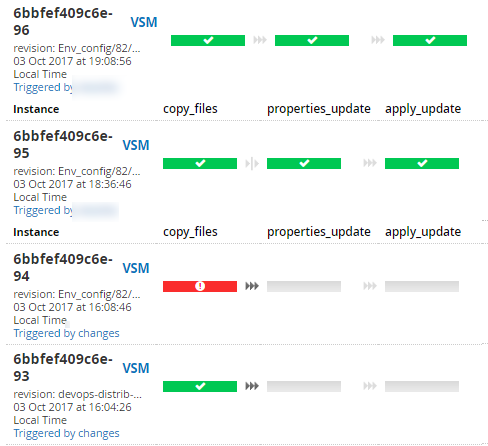
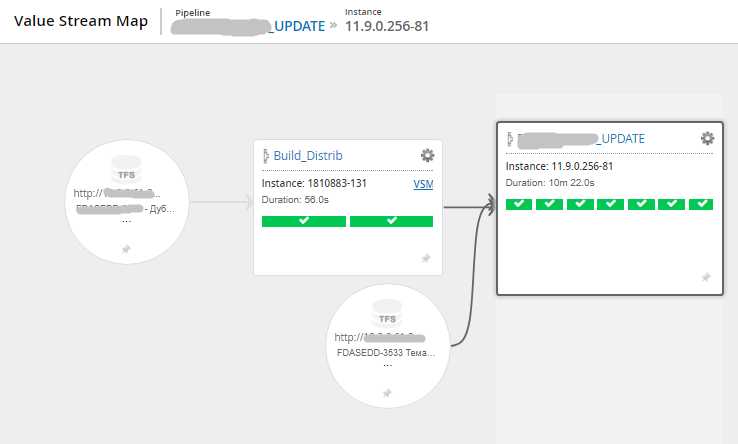
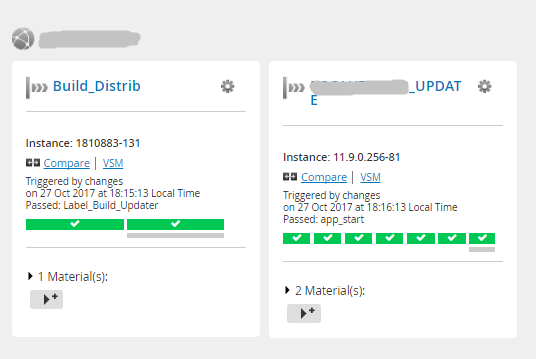
Stream map (release movement from a commit to a version control system to tests) Visualization of the status of the stages of one scenario Detailed information about the stages of the scenario (logs, history of changes to the scenario, time of the stages) Stream map (another project, more compact) General view of the scenario from 2 pipeline Another example is the general view of the scenario from 7 pipeline in the picture before kat. Based on the results of the introduction of the new delivery conveyor, it was important to get feedback from the team (without cuts):
“Significantly (from days to hours) the time for creating new stands decreased. Now you can not keep several stands for different versions. If necessary, the desired version is raised from scratch, and the stand itself is guaranteed to correspond to its state at the time of release of the desired version, because the DevOps code is versioned along with the project code. Explosion quality increased documentation. Since the DevOps code clearly repeats the instructions, there are no "implied" things left in them, etc. The number of routine operations for engineers has decreased.
The ability of testers to create test stands for complex cases (load, fault tolerance) with minimal involvement of engineers. The first step to managing the project infrastructure is versioning, testing, etc. Quickly, conveniently, and incomprehensibly. ”
It is incomprehensible, unusual - quite frequent words, so we periodically conduct training on accepted tools.
And this is the feedback from the project for the energy company:
“Automation of lengthy routine operations. Saving about 0.5–1 people a day. And during the preparation of the release, in fact, 50% of one engineer used to be engaged in update builds. Speed up the update process. The routine maintenance work on updating all sites (7 pieces) is on average 3 hours - update automation + self-tests + make sure with your eyes (i.e., actually overtime work is minimized). Streamlining the storage of information about all environments, a guarantee of its relevance and timely updating. The introduction of night auto-detection and auto-testing - increasing the transparency of the state of the product. Improving product quality. There is practically no need to release Hot fixes. Reduced release costs. ”
What did you get
- Operational information on the quality of the assembled build, a visual representation of the delivery conveyor.
- There is always a build in the standard distribution repository.
- The ability to quickly see the current changes on the stand.
- Ability to program infrastructure (infrastructure as a code) in all our variety of virtualization.
- The ability to quickly deploy the right infrastructure and application system to the right on demand version.
- Ansible sample roles for configuring sample projects.
I had to suspend work on some project tasks in order to establish infrastructure. The sooner devops is implemented, the less time is spent. Otherwise, you have to implement it during periods of low activity in the project, and when do they happen?
We continue to gently inform the inside of the company about the need for automation. Politely. Neatly.
References:
- Funny bike of our ops a year before the start of centralization of the whole thing
- Here are the results of a project in nuclear energy where we used this stack
- About our development centers throughout the country (by the way, since then more centers have been added to them in Voronezh and Chelyabinsk).
- My mail is sstrelkov@croc.ru.