Greenplum 5: First Steps in Open Source
 For two years now, one of the best distributed enterprise-level analytic DBMSs has become open source. What has changed during this time? What gave the opening of the source code to the project? How will Greenplum develop further?
For two years now, one of the best distributed enterprise-level analytic DBMSs has become open source. What has changed during this time? What gave the opening of the source code to the project? How will Greenplum develop further? Under the cut, I’ll talk about what's new in the first major open source DBMS release, how the project is developing in the current minor versions, and what innovations should be expected in the future.
If you are not familiar with Greenplum DBMS, you can start your acquaintance with this review article .
Release 5.0.0 took place on September 7th. This is the first release, which includes improvements made by third-party developers (community). Releases version 4.3, although they were laid out in an open repository, were developed only by Pivotal specialists.
The release brought a lot of innovations, it seems to me that the main reason for this is that users who have been working with Greenplum for a long time finally got the opportunity to realize all their Wishlist that Pivotal could not realize and that have been accumulating for so long. I will give a brief description, in my opinion, of the most important changes in the new major release and in the subsequent minor updates, since there are too many changes to tell about everything. At the end of the article I will provide links to Release Notes of the new release and its minor updates.
Conventionally, all innovations can be divided into three groups:
- New features ported from the latest versions of PostgreSQL
- Greenplum innovations
- New additional services and extensions
Let's start in order.
1. New features ported from the latest versions of PostgreSQL
- Rebase on PostgreSQL 8.3
. Unlike many other PostgreSQL-based projects, Greenplum does not seek to have the latest version of PostgreSQL as its base - until version 5.0.0, Greenplum was based on PostgreSQL 8.2; in the current major release, the version was raised to 8.3. At the same time, the possibilities of newer versions of PostgreSQL are actively transferred to the project; - Heap tables can now have a checksum.
Greenplum allows you to create two types of internal tables - heap tables and append-optimized tables. If for the latter, the function of calculating the checksum of files on the disk was always available, for heap tables it appeared in the current release. The function is enabled by the parameter; - Anonymous Blocks
This innovation has been dragged from PostgreSQL unchanged. Not the most important (a code block could always be wrapped in a function), but so long awaited by administrators and developers, a revision.DO $$DECLARE r record; BEGIN FOR r IN SELECT table_schema, table_name FROM information_schema.tables WHERE table_type = 'VIEW' AND table_schema = 'public' LOOP EXECUTE 'GRANT ALL ON ' || quote_ident(r.table_schema) || '.' || quote_ident(r.table_name) || ' TO webuser'; END LOOP; END$$; - DBlink
Mechanism allows you to perform queries in external third-party DBMS and collect the result. It would seem that this mechanism greatly expands the capabilities of Greenplum, allowing you to take data into an analytical DBMS directly from sources, but the applicability of DBlink is very limited - due to the Greenplum architecture, data transfer when using DBlink is performed not in parallel segments, but single-threaded through the master. This fact forces DBlink to be used only for control requests to third-party databases, avoiding direct data transfer. In fairness, it is worth noting that with the parallel sampling of data from third-party DBMSs, another 5-innovation will help to cope, which we will talk about in the third part of the review of new functions.SELECT * FROM dblink('host=remotehost port=5432 dbname=postgres', 'SELECT * FROM testdblink') AS dbltab(id int, product text); - Controlling ORDER BY Perception of NULL Values
Now with a SELECT query, it is possible to specify the [NULLS {FIRST | LAST}], which controls how NULL values are displayed - at the beginning or end of sorted values.SELECT * from my_table_with_nulls ORDER BY 1 NULLS FIRST; - Extensions
Also ported from PostgreSQL unchanged. Now it is this mechanism that is used to create, delete, and update various third-party extensions. In essence, the CREATE EXTENSION expression executes the specified SQL script.
2. Greenplum innovations
- Improvements to the query optimizer - ORCA
An alternative cost-based query optimizer existed in version 4.3, however, it was included there optionally. In the new release, the optimizer was significantly improved, in particular, the performance of short light queries, queries with a very large number of join and a number of other cases increased. The mechanism for cutting off unnecessary partitions was also improved if there was a condition on the partition key in the request. Now this optimizer is used by default; - Resource Groups
Greenplum already has a load management mechanism - Resource queues (resource queues), but it only allows you to limit the launch of requests based on their cost. The new mechanism allows you to limit requests for memory and CPU (but, alas, not for the load on the disk subsystem);CREATE RESOURCE GROUP rgroup1 WITH (CPU_RATE_LIMIT=20, MEMORY_LIMIT=25); - PL / Python 2.6 -> 2.7 The
built-in version of Python is now 2.7; - COPY
improvements In the already small regiment of parallel downloads and uploads of data from Greenplum arrived - now the standard command for uploading data from a table to a flat local file supports the ON SEGMENT construct - with it, data is downloaded on all database segments to the local file system. The PROGRAM construct also appeared - to pick up and send data to an external bash command. By the way, these two options can be used together:COPY mydata FROM PROGRAM 'cat /tmp/mydata_.csv' ON SEGMENT CSV;
3. New services and extensions
- PXF Support
In my opinion, this is the most important development of Greenplum in the new release. PXF is a framework that allows Greenplum to simultaneously exchange data with third-party systems. This is not a new technology, it was originally developed for the Greenplum fork - HAWQ, working on top of the Hadoop cluster. Greenplum already had a parallel implementation of the connector for the Hadoop cluster, while PXF brings much more flexibility and the ability to connect arbitrary third-party systems to the integration bank by writing your own connector.
The framework is written in Java and is a separate process on the Greenplum segment server, on the one hand communicating with Greenplum segments through the REST API, on the other - using third-party Java clients and libraries. So, for example, now there is support for the basic services of the Hadoop stack (HDFS, Hive, Hbase) and parallel downloading of data from third-party DBMSs via JDBC.
In this case, the PXF service must be running on each server in the Greenplum cluster.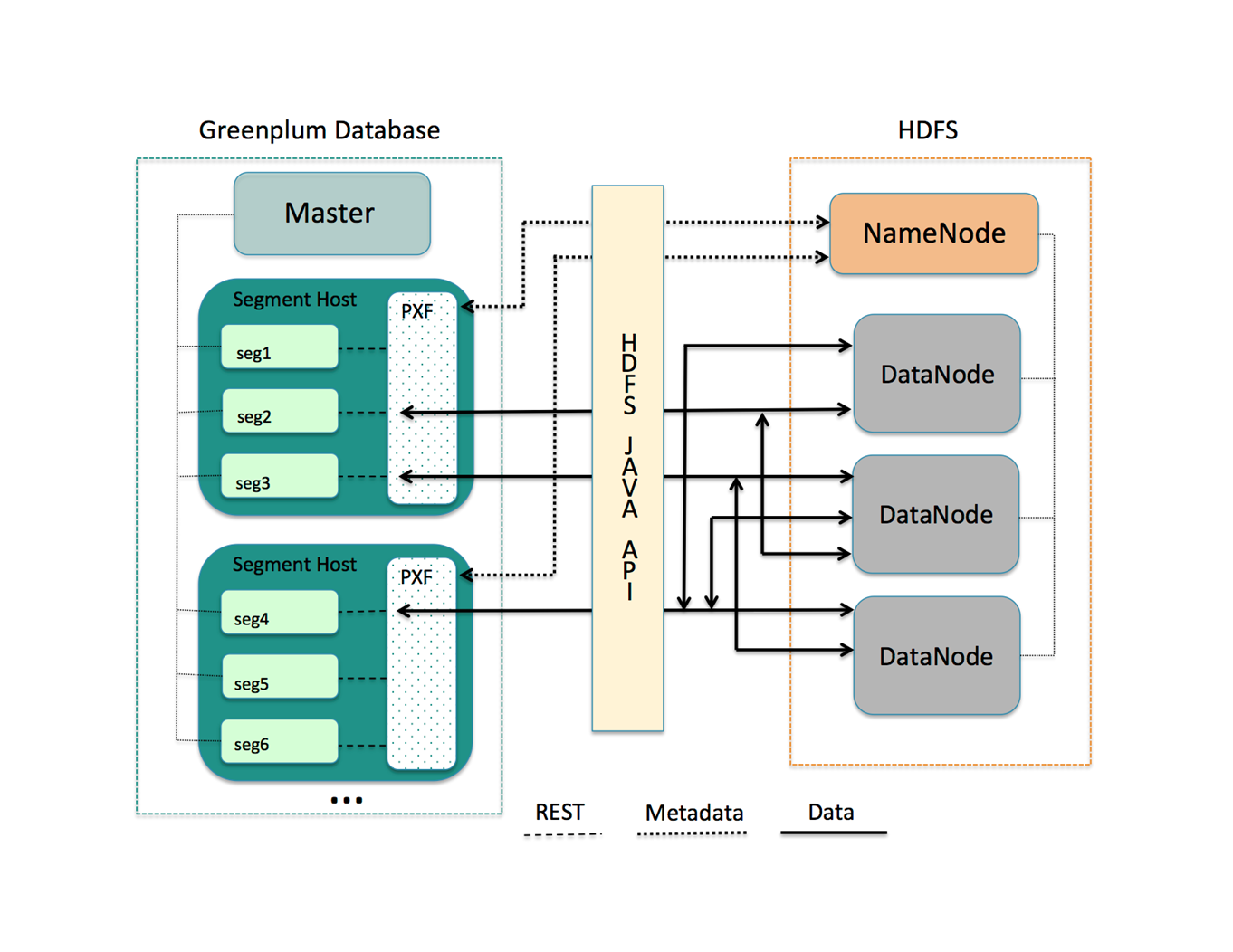
PXF to HDFS Scheme
It seems to me that the most interesting is the ability to integrate Greenplum with third-party DBMSs via JDBC. So, for example, adding a JDBC-thin-driver for Oracle Database in CLASSPATH, we will be able to request data from the tables of the DBMS of the same name, while each Greenplum segment in parallel will request its data shard, based on the logic specified in the external table:CREATE EXTERNAL TABLE public.insurance_sample_jdbc_ora_ro( policyid bigint, statecode text, ... point_granularity int ) LOCATION ('pxf://myoraschema.insurance_test?PROFILE=JDBC&JDBC_DRIVER=oracle.jdbc.driver.OracleDriver&DB_URL=jdbc:oracle:thin:@//ora-host:1521/XE&USER=pxf_user&PASS=passoword&PARTITION_BY=policyid:int&RANGE=100000:999999&INTERVAL=10000') FORMAT 'CUSTOM' (FORMATTER='pxfwritable_import');
Taking into account the possibility of using partitions (sections) as external tables in one table, PXF allows you to build amazingly flexible and productive data processing platforms on the basis of Greenplum - for example, store hot, fresh data in Oracle, warm in Greenplum itself and cold, archived - in a Hadoop cluster, while the user will see all the data in one table; - Passwordcheck
module This module allows you to limit the setting of “weak” passwords when creating or changing a role (CREATE ROLE or ALTER ROLE); - PGAdmin 4 The
popular PostgreSQL client now supports enhanced interaction with Greenplum. On board support DDL partitioned tables, AO and Heap tables. DDL of external tables is not yet supported.
The innovations of a two-year stay in open source can be summarized as follows:
- Greenplum architecture remains true to itself. No significant changes (such as inhomogeneous segments or a variable number of mirrors) did not happen
and thank God; - The development of the PostgreSQL component of the DBMS remains the same - porting new functions instead of constantly upgrading due to rebase;
- One can see the development towards integration with third-party systems, and this, it seems to me, is very, very correct;
- Greenplum gains modularity and flexibility, old, inflexible functionalities are slowly removed from the system (GPHDFS, Legacy Optimizer).
What's next?
Not so long ago, the release 6.0.0 was tagged in the official repository. This release should be released in September next year, and here are some (at least) innovations in it that will definitely be:
- PXF pushdown - transfer to the DBMS source side of the data selection conditions (where-filters). This will allow you to transfer part of the load to third-party systems and take the finished result from them;
- PXF passing user identity - in the future, PXF will forward the Greenplum username under which the request runs to the external system. Safety, all things. Perhaps this revision will be implemented in one of the minor updates of the "five";
- A new type of compression is Zstd. According to the results of the first tests, Zstd in Greenplum is 4 times faster, while compressing data 10% more efficiently compared to Zlib. Of particular pride is the fact that this feature was developed by our team (Arenadata);
- Further improvements to the new ORCA optimizer.
It seems to me that going to open source definitely went Greenplum. The development of the project, remaining true to the previous course, greatly accelerated and expanded. I think in the near future we will see a lot of completely new functionality for Greenplum.
Related links:
Official repository
5.0.0 Release notes
5.1.0 Release notes
5.2.0 Release notes
5.3.0 Release notes
A little about us: the Arenadata project was founded by immigrants from Pivotal (the developer company Greenplum and Pivotal Hadoop) in 2015, its goal was to create its own distributions of Greenplum and Hadoop enterprise-level to build modern data storage and processing platforms.
In early 2017, the project was acquired by IBS.
Now the project portfolio has three own distributions and all the necessary services. In particular, in the direction of Greenplum we:
- We provide technical support;
- We provide consulting services;
- We migrate data and processes from third-party DBMSs to Greenplum.
In the comments I will try to answer any questions about the Arenadata project and Greenplum in general. We will also be glad to see you in the Greenplum user channel in Telegram. You are welcome!
