Getting ready to investigate incidents
Is it possible to fully protect against cyber attacks? Perhaps you can, if you surround yourself with all existing means of protection and hire a huge team of experts to manage the processes. However, it is clear that in reality it is impossible: the budget for information security is not infinite, and incidents will still occur. And if they happen, it means you need to prepare for them!
In this article, we will share sample scenarios for investigating malware-related incidents, tell you what to look for in the logs, and give technical recommendations on how to configure information protection tools in order to increase the chances of an investigation success.

The classic process of responding to a malware-related incident involves such stages as detection, deterrence, recovery, etc., but all of your capabilities, in fact, are determined at the preparation stage. For example, the rate of detection of infections depends on how well the company is set up an audit.
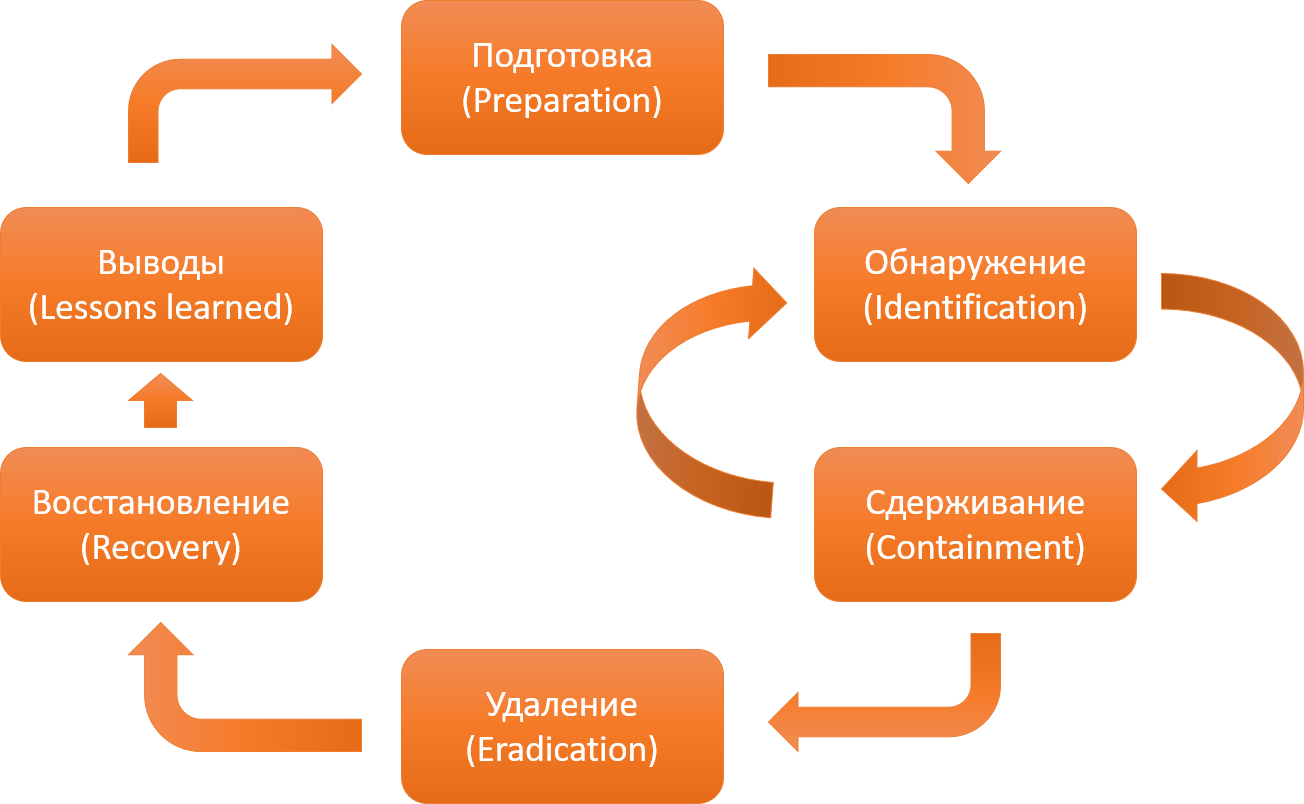
Classic SANS Incident Response Cycle Based on the SANS methodology.
In general, the actions of analysts during the investigation are as follows:
Of course, there is no point in testing all possible hypotheses - at least because time is limited. Therefore, here we will consider the most likely versions and typical scenarios for the investigation of incidents involving malware.
As part of the development of this version, you should perform three simple steps:

Outputting all running processes and services in the Event Log Explorer
In theory, this is a fairly trivial process. However, in practice there are a number of pitfalls, which should be prepared.
First, the standard Windows audit setup does not log the facts of the processes launch (event 4688), so it must be enabled in advance in the domain group policy. If it so happens that this audit was not enabled in advance, you can try to get a list of executable files from other Windows artifacts, for example, from the Amcache registry . You can extract data from this registry file using the AmcaheParser utility .
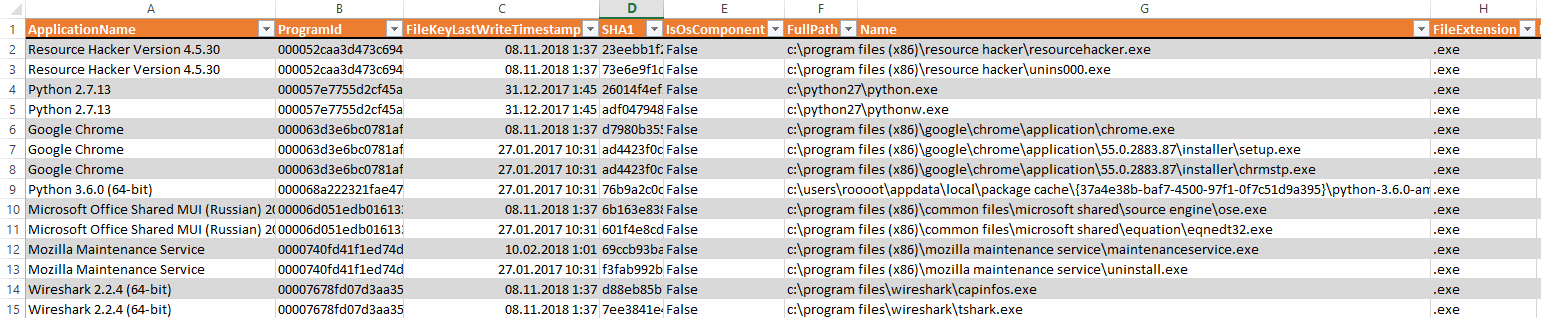
An example of extracting the facts of running processes from Amcache.hve
However, this method is not very reliable, since it does not provide accurate information about when exactly and how many times the process was launched.
Secondly, evidence of launching processes such as cmd.exe, powershell.exe, wscript.exe and other interpreters will be of little use without information about the command line with which the processes were launched, since it contains the path to a potentially malicious script file.
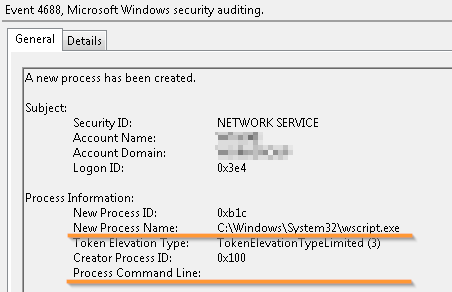
Running the script interpreter without information that the script was launched
Another Windows feature is that the command line audit of the process being started is done by setting the domain group policy separately:Computer Configuration -> Policies -> Administrative Templates -> System -> Audit Process Creation -> Include command line in process creation events . At the same time, quite popular Windows 7/2008 does not log the command line without installing the KB3004375 update , so install it in advance.
If it so happens that you did not set anything up in advance or forgot about the update, you can try to find out the location of the script in the Prefetch files ( utility to help ). They contain information about all files (mostly DLLs) loaded into the process in the first 10 seconds of life. And the script contained in the command line arguments of the interpreter will most certainly be there.

An example of searching for the “lost” command line argument in Prefetch
But this method is far from reliable — the next time the process starts, the Prefetch cache will be overwritten.
Preparing for the investigation:
One of the options for responding to such alarms may be to check which process made the connection - if it is an Internet browser, then in the absence of other facts indicating a compromise, the incident can be considered a false alarm.
There are many ways to find out which process initiated the connection: you can run netstat and see the current sockets or collect a memory dump and then set a volatility on it that can show including already completed connections. But all this is long, not scalable, and the most important thing is not reliable. It is much more reliable to get all the necessary information from the Windows security-log.
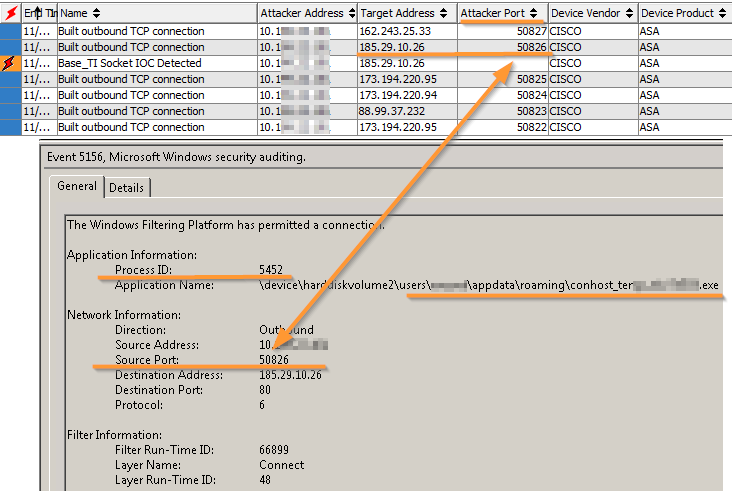
Correlation of the “access to malicious IP address” event on the HPE Arcsight SIEM system and the corresponding process in the Windows security log
Preparing for an investigation
In order to run this scenario on a user machine, you should enable the security log of all network connections. This can be done on the basis of eventsaudit platform filtering and packet drop auditing .
At the same time, the journal can start to get quickly clogged, so increase its size to 2-3 GB. In our experience, on a regular user host of this volume, it takes about 3 days to record all sockets, and this period is enough for a successful investigation.
On high-load servers, such as domain controllers, web servers, etc., you should not do this, the log will fill up much faster.
If potential intelligence is carried out from a single host, it can be investigated, including using the logs of running processes. However, if there are many hosts, and attacks of the same type (occurred at the same time, or the same set of entities were requested from AD), then it makes sense to first exclude a typical false response. For this you need to create and check the following versions:
The statistical analysis of the logs will help to detect these key points (general user or process). We have demonstrated this method in one of the previous articles in relation to DNS server logs . However, using such effective investigation methods will not work if the storage of data has not been organized in advance.
Preparing for an investigation
It is necessary to organize long-term storage of at least the following data from the general network services logs:
 Suppose something terrible happened: you find that your domain administrator account is compromised.
Suppose something terrible happened: you find that your domain administrator account is compromised.
Responding to such an incident includes a very large amount of work, including an analysis of all actions taken under this account. Part of this investigation can be carried out using only domain controller logs. For example, you can study the events related to issuing Kerberos tickets in order to understand where you went from under this account. Or, you can analyze events related to changes in critical AD objects to check whether the composition of highly privileged groups (of the same domain administrators) has changed. Naturally, all this requires a pre-configured audit.
However, there is a problem related to the fact that an attacker with domain administrator rights can modify AD objects using the DCShadow technique, which is based on the replication mechanism between domain controllers.
Its essence lies in the fact that the attacker himself is represented by the domain controller, makes changes to AD and then replicates (synchronizes) these changes with legitimate controllers, thus bypassing the audit of object changes configured on them. The result of such an attack may be the addition of a user to the domain administrators group or trickier attachments through a change in the SID History attribute or a modification of the AdminSDHolder ACL object .
In order to check the version of the presence of unfixed changes in AD, it is required to examine the controller replication logs: if the replication involved IP addresses that are not domain controllers, it can be said with a high degree of confidence that the attack was successful.
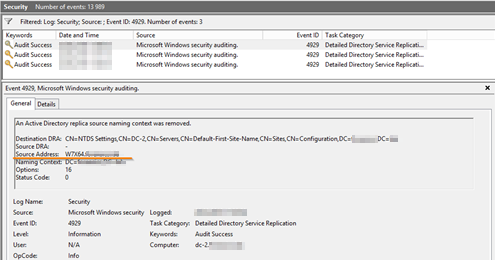
Remove unknown domain controller from AD replication
Preparing for an investigation:
In this article, we talked about some typical scenarios for investigating security incidents and measures of preventive preparation for them. If you are interested in this topic and you are ready to go further, I recommend paying attention to this document describing in which Windows events you can find traces of the use of popular hacker techniques.
To finish, I would like to quote from a recent study of a company working in the field of cyber security:
In this article, we will share sample scenarios for investigating malware-related incidents, tell you what to look for in the logs, and give technical recommendations on how to configure information protection tools in order to increase the chances of an investigation success.
The classic process of responding to a malware-related incident involves such stages as detection, deterrence, recovery, etc., but all of your capabilities, in fact, are determined at the preparation stage. For example, the rate of detection of infections depends on how well the company is set up an audit.
Classic SANS Incident Response Cycle Based on the SANS methodology.
In general, the actions of analysts during the investigation are as follows:
- Formation of versions explaining the causes of the incident (for example, “the malware was installed on the host because the user launched it from a phishing email” or “the incident is a false alarm because the user visited a legitimate site located on the same hosting server as malware ”).
- Prioritization of versions according to probability. The probability is calculated (or rather, it pretends) on the basis of statistics of past incidents, the severity of the incident or system, and also on the basis of personal experience.
- Elaboration of each version, search for facts proving or disproving it.
Of course, there is no point in testing all possible hypotheses - at least because time is limited. Therefore, here we will consider the most likely versions and typical scenarios for the investigation of incidents involving malware.
Scenario 1
You have a suspicion that an uncritical system was compromised by malware. Due to the uncriticality of the system, quite a bit of time is allotted for checking.The first thing that most response engineers do is run antivirus checks. However, as we know, antivirus is not so difficult to get around. Therefore, it is worthwhile to form and work out the following highly probable version: the malware is a separate executable file or service.
As part of the development of this version, you should perform three simple steps:
- Filter the Security log by event 4688 - so we get a list of all the running processes.
- Filter the System log by event 7045 - so we get a list of the settings for all services.
- Identify new processes and services that were not previously in the system. Copy these modules and analyze them for the presence of malicious code (scan with several antivirus programs, check the validity of the digital signature, decompile the code, etc.).
Outputting all running processes and services in the Event Log Explorer
In theory, this is a fairly trivial process. However, in practice there are a number of pitfalls, which should be prepared.
First, the standard Windows audit setup does not log the facts of the processes launch (event 4688), so it must be enabled in advance in the domain group policy. If it so happens that this audit was not enabled in advance, you can try to get a list of executable files from other Windows artifacts, for example, from the Amcache registry . You can extract data from this registry file using the AmcaheParser utility .
An example of extracting the facts of running processes from Amcache.hve
However, this method is not very reliable, since it does not provide accurate information about when exactly and how many times the process was launched.
Secondly, evidence of launching processes such as cmd.exe, powershell.exe, wscript.exe and other interpreters will be of little use without information about the command line with which the processes were launched, since it contains the path to a potentially malicious script file.
Running the script interpreter without information that the script was launched
Another Windows feature is that the command line audit of the process being started is done by setting the domain group policy separately:Computer Configuration -> Policies -> Administrative Templates -> System -> Audit Process Creation -> Include command line in process creation events . At the same time, quite popular Windows 7/2008 does not log the command line without installing the KB3004375 update , so install it in advance.
If it so happens that you did not set anything up in advance or forgot about the update, you can try to find out the location of the script in the Prefetch files ( utility to help ). They contain information about all files (mostly DLLs) loaded into the process in the first 10 seconds of life. And the script contained in the command line arguments of the interpreter will most certainly be there.
An example of searching for the “lost” command line argument in Prefetch
But this method is far from reliable — the next time the process starts, the Prefetch cache will be overwritten.
Preparing for the investigation:
- Enable advanced audit of creation and termination of processes.
- Enable logging of process command line arguments.
- Install the update KB3004375 on Windows 7 / Server 2008.
Scenario 2
A request to the malware management server was fixed on the perimeter router. The IP address of the malicious server was obtained from a medium-reliability threat intelligence subscription.In one of the previous articles, we told that TI-analysts sin by adding to the lists of indicators a compromise of IP addresses of servers hosted by both malware control centers and legitimate websites. If you have just started to formulate response processes, then at the first stages it is better to abandon the use of such indicators, because every attempt by a user to access a legitimate website will look like a full-fledged incident.
One of the options for responding to such alarms may be to check which process made the connection - if it is an Internet browser, then in the absence of other facts indicating a compromise, the incident can be considered a false alarm.
There are many ways to find out which process initiated the connection: you can run netstat and see the current sockets or collect a memory dump and then set a volatility on it that can show including already completed connections. But all this is long, not scalable, and the most important thing is not reliable. It is much more reliable to get all the necessary information from the Windows security-log.
Correlation of the “access to malicious IP address” event on the HPE Arcsight SIEM system and the corresponding process in the Windows security log
Preparing for an investigation
In order to run this scenario on a user machine, you should enable the security log of all network connections. This can be done on the basis of eventsaudit platform filtering and packet drop auditing .
At the same time, the journal can start to get quickly clogged, so increase its size to 2-3 GB. In our experience, on a regular user host of this volume, it takes about 3 days to record all sockets, and this period is enough for a successful investigation.
On high-load servers, such as domain controllers, web servers, etc., you should not do this, the log will fill up much faster.
Scenario 3
Your NG / ML / Anti-APT Anomaly Detection System reports that reconnaissance is taking place from 30 hosts in order to obtain the same accounts.When they enter a new network, attackers, as a rule, try to find out which services are present in it and which accounts are used - this helps a lot in the process of further movement through the infrastructure. In particular, this information can be obtained from Active Directory itself using the net user / domain command .

If potential intelligence is carried out from a single host, it can be investigated, including using the logs of running processes. However, if there are many hosts, and attacks of the same type (occurred at the same time, or the same set of entities were requested from AD), then it makes sense to first exclude a typical false response. For this you need to create and check the following versions:
- Intelligence is fixed on 30 hosts in relation to the same AD objects, because the same legitimate user, the administrator, launched the net command .
- Intelligence is fixed on 30 hosts in relation to the same AD objects, because it made the same legitimate software.
The statistical analysis of the logs will help to detect these key points (general user or process). We have demonstrated this method in one of the previous articles in relation to DNS server logs . However, using such effective investigation methods will not work if the storage of data has not been organized in advance.
Preparing for an investigation
It is necessary to organize long-term storage of at least the following data from the general network services logs:
- Domain controllers - logins, account outlets, and Kerberos ticket issuance ( Account Logon category in advanced audit settings).
- Proxy servers - addresses, source and external server ports, as well as the full URL.
- DNS servers - successful and unsuccessful DNS queries and their source within the network.
- Perimeter routers - Built and Teardown for all TCP / UDP connections, as well as connections that attempt to violate logical access rules: for example, attempts to send a DNS request to the outside directly, bypassing the corporate DNS server.
Scenario 4
Your domain has been compromised, and it bothers you that an attacker could gain a foothold in the infrastructure using the DCShadow technique.
Suppose something terrible happened: you find that your domain administrator account is compromised. Responding to such an incident includes a very large amount of work, including an analysis of all actions taken under this account. Part of this investigation can be carried out using only domain controller logs. For example, you can study the events related to issuing Kerberos tickets in order to understand where you went from under this account. Or, you can analyze events related to changes in critical AD objects to check whether the composition of highly privileged groups (of the same domain administrators) has changed. Naturally, all this requires a pre-configured audit.
However, there is a problem related to the fact that an attacker with domain administrator rights can modify AD objects using the DCShadow technique, which is based on the replication mechanism between domain controllers.
Its essence lies in the fact that the attacker himself is represented by the domain controller, makes changes to AD and then replicates (synchronizes) these changes with legitimate controllers, thus bypassing the audit of object changes configured on them. The result of such an attack may be the addition of a user to the domain administrators group or trickier attachments through a change in the SID History attribute or a modification of the AdminSDHolder ACL object .
In order to check the version of the presence of unfixed changes in AD, it is required to examine the controller replication logs: if the replication involved IP addresses that are not domain controllers, it can be said with a high degree of confidence that the attack was successful.
Remove unknown domain controller from AD replication
Preparing for an investigation:
- To investigate actions taken by a compromised account, you must enable in advance:
- Audit of entries, exits of account and issuance of Kerberos tickets ( Account Logon category in advanced audit settings).
- Audit changes to accounts and groups (category Account Management ).
- To investigate versions related to possible applications of the DCShadow attack:
- Enable detailed directory service replication auditing .
- Organize long-term storage of events 4928/4929, in which the source of events is not a legitimate domain controller (DCShadow attribute).
Conclusion
In this article, we talked about some typical scenarios for investigating security incidents and measures of preventive preparation for them. If you are interested in this topic and you are ready to go further, I recommend paying attention to this document describing in which Windows events you can find traces of the use of popular hacker techniques.
To finish, I would like to quote from a recent study of a company working in the field of cyber security:
“Russian information security directors are mostly inclined to give pessimistic answers [to research questions]. So, half (48%) believes that the budget will not change in any way, and 15% think that funding will be reduced. ”For me personally, this is a signal to the fact that the remaining budget in the new year is better to spend not on the purchase of new-fashioned GIS like Machine Learning detectors, the next IDS of a new generation, etc., but to fine-tune the GIS that already exists. And the best SZI is correctly configured Windows logs. IMHO.