An Introduction to Neural Network Architecture
Grigory Sapunov (Intento)
My name is Grigory Sapunov, I am a service station of the Intento company. I have been engaged in neural networks for a long time and machine learning, in particular, was engaged in the construction of neural network recognizers of road signs and numbers. I participate in a project on neural network stylization of images, I help many companies.
Let's get right to the point. My goal is to give you basic terminology and understanding of what’s happening in this area, from which bricks neural networks are assembled, and how to use it.
The outline of the report is as follows. First, a small introduction about what a neuron is , a neural network , a deep neural network , so that we communicate in the same language.
Further I will talk about important trends that are happening in this area. Then we delve deeper intoarchitecture of neural networks , consider 3 of their main classes . This will be the most meaningful part.
After that, we will consider 2 relatively advanced topics and end with a short overview of frameworks and libraries for working with neural networks.
At the conference, Natalia Efremova from NTechLab talked about practical cases. I’ll tell you how the neural networks are arranged inside, of what bricks they are made of inside.
Summary

Recap: neuron, neural network, deep neural network
A brief reminder

An artificial neuron is a very distant resemblance to a biological neuron.
What is an artificial neuron? This is a simple function actually. She has inputs. Each input is multiplied by certain weights, then everything is summed up, run through some non-linear function, the result is output - everything, this is one neuron.
If you are familiar with logistic regression, by which we mean the non-linear function of SIGMOID, then one neuron is a complete analogue of logistic regression, a simple linear classifier.
In fact, there are many different activation functions, including the hyperbolic tangent (TANH), SIGMOID, RELU shown in the figure.
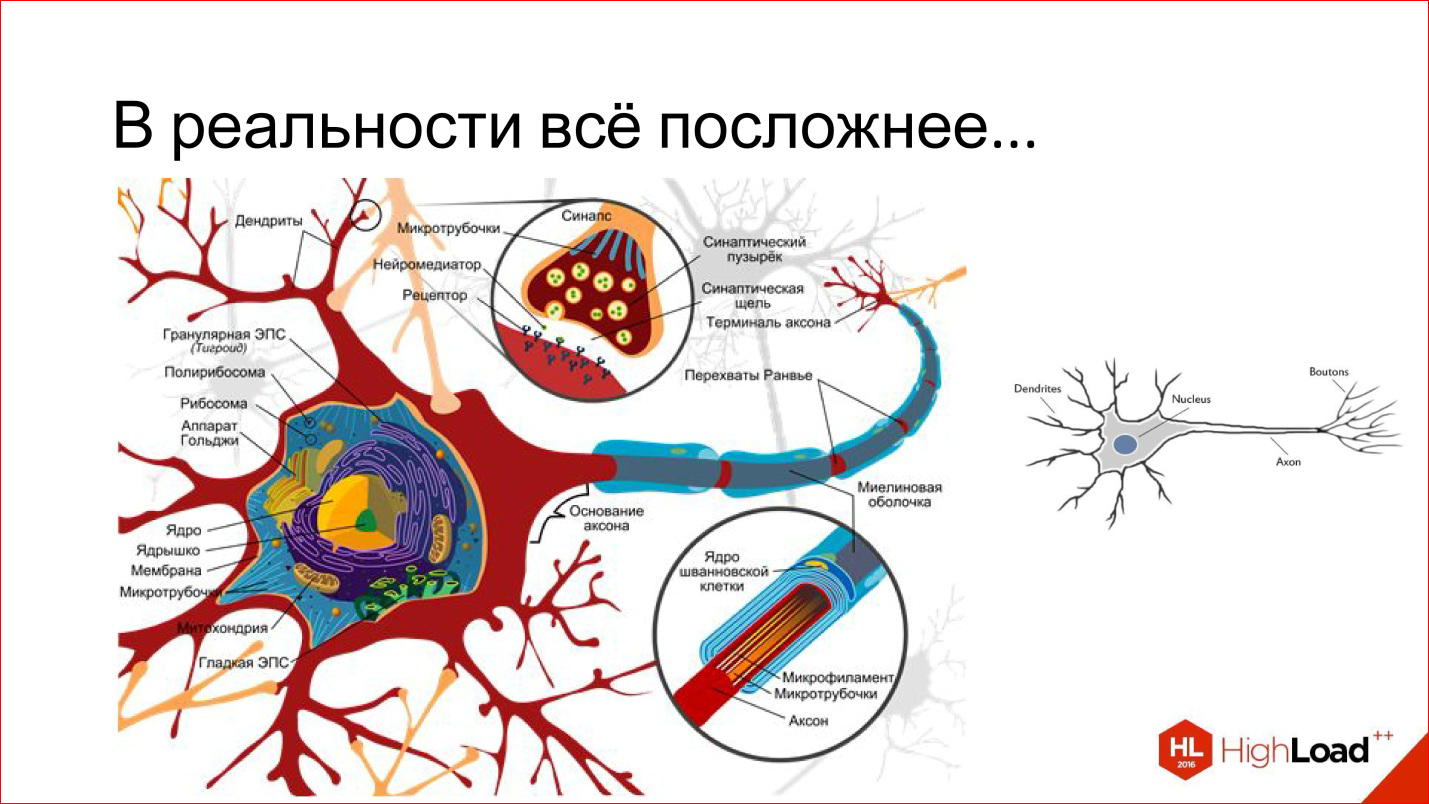
In reality, everything is much more complicated. We will not touch on this topic.
I gave a very basic idea of an artificial neuron, as a kind of biological neuron.
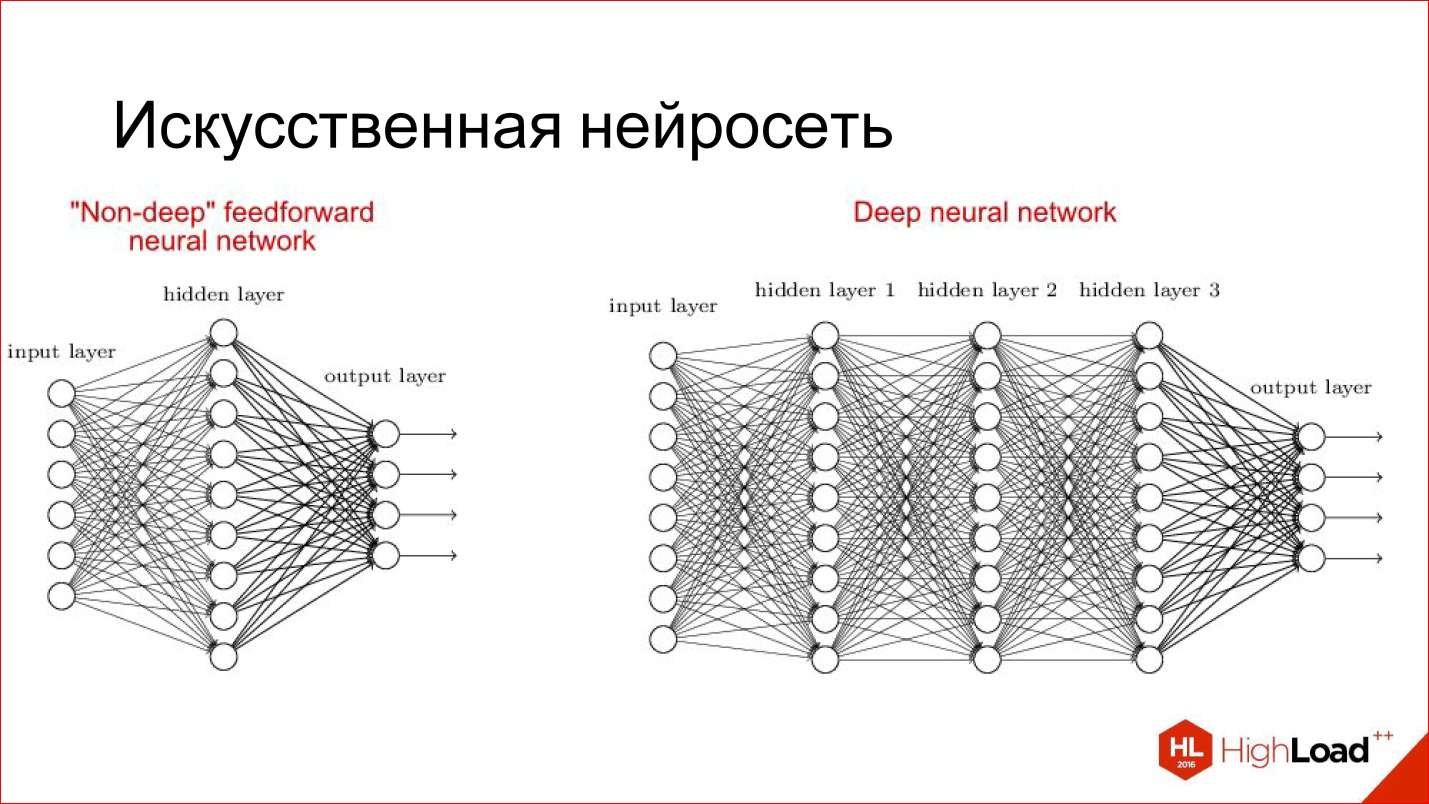
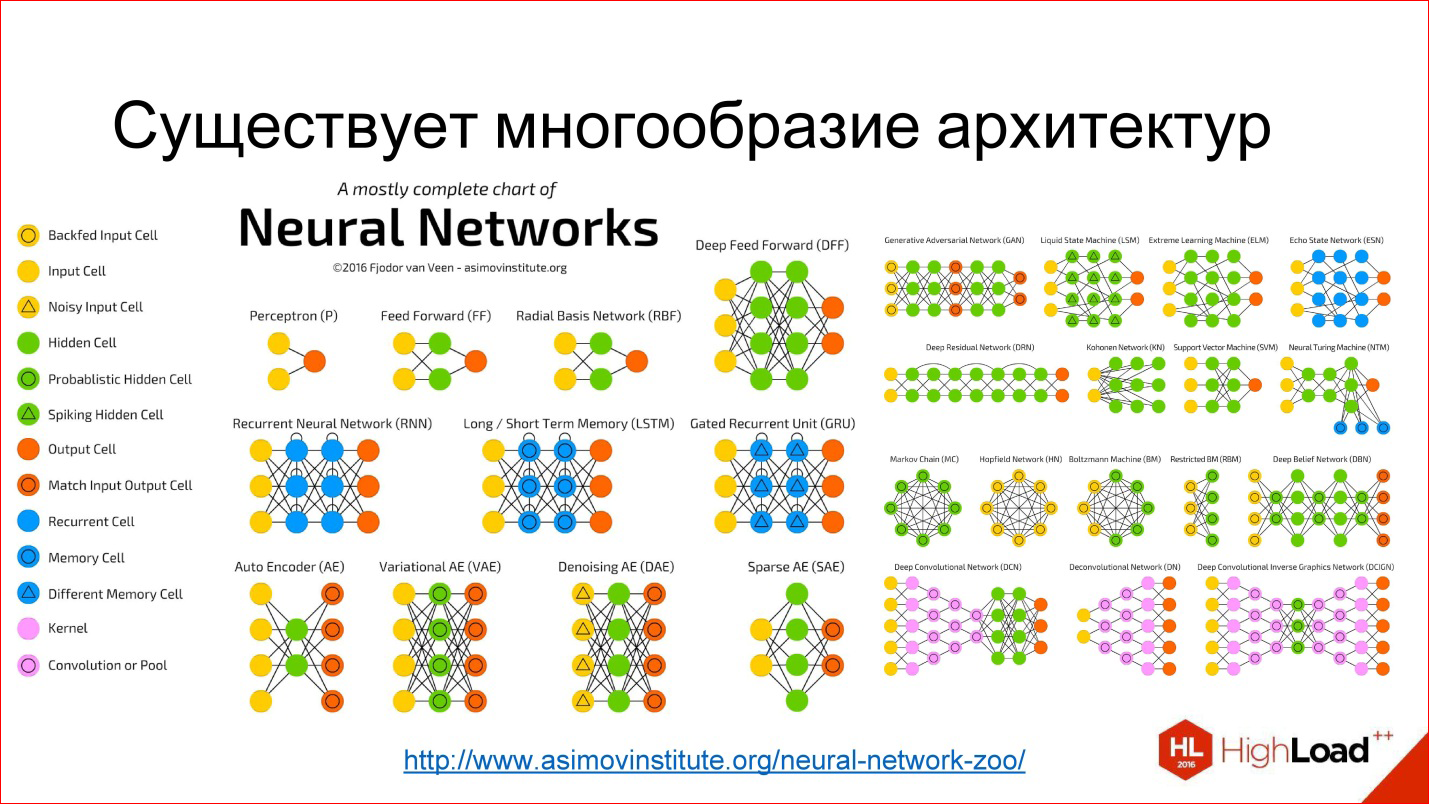
An artificial neural network is a way to collect neurons into a network so that it solves a specific problem, for example, a classification problem. Neurons gather in layers. There is an input layer where the input signal is supplied, there is an output layer, where the result of the neural network is taken from, and there are hidden layers between them. There may be 1, 2, 3, many. If there are more than 1 hidden layers, the neural network is deemed deep, if 1, then shallow.
There is a huge variety of different architectures, the main of which we will consider. But keep in mind that there are a lot of them. If interested, then follow the link - look, read.
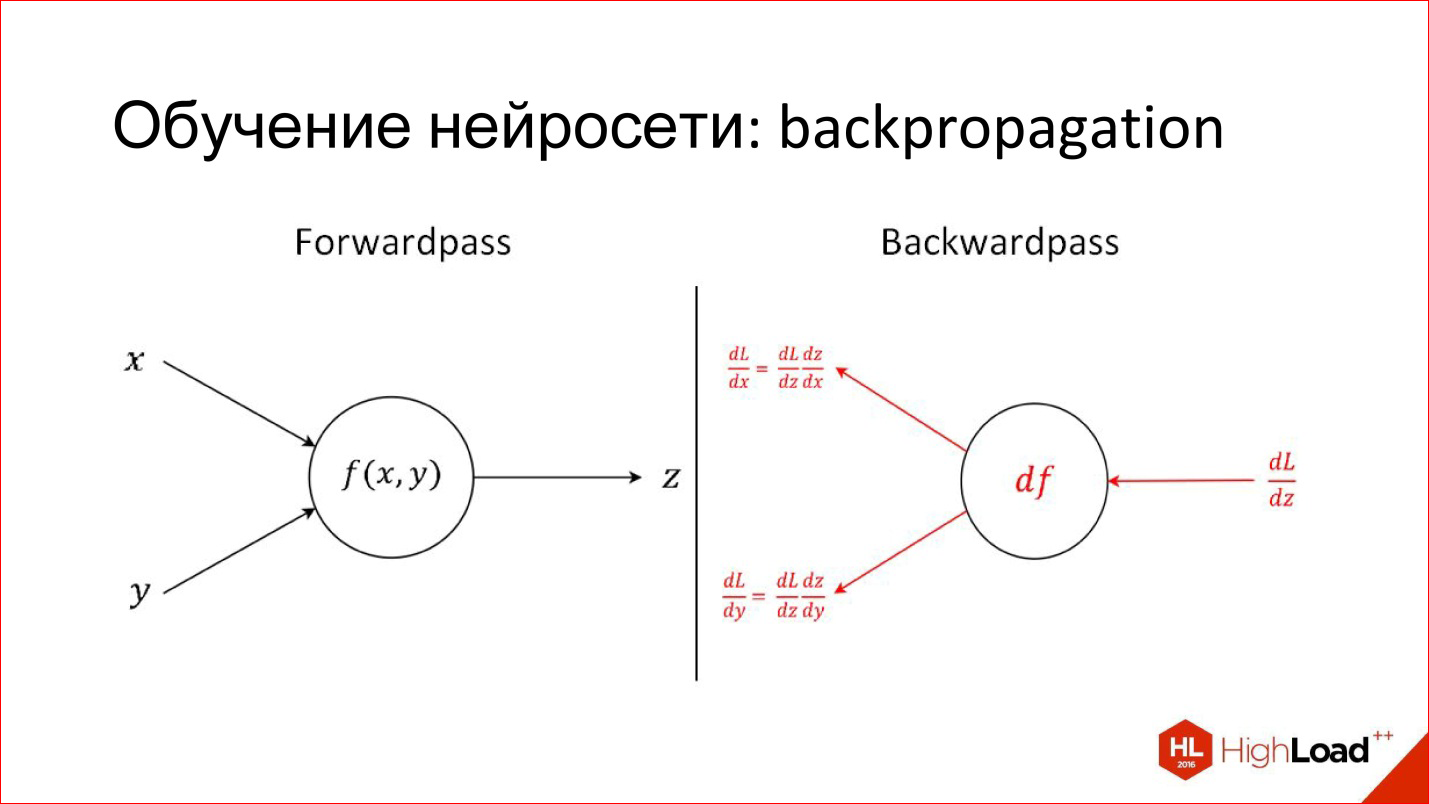
Another useful thing you need to know to discuss neural networks. I already told how one neuron works: how each input multiplies by weights, by coefficients, sums, multiplies by non-linearity. This is, let's say, the production mode of the neuron, that is, inference, how it works in an already trained form.
There is a completely different task - to train a neuron. Training is to find these right weights. The training is based on the simple idea that if at the output of a neuron we know what the answer should be, and we know what it turned out, we become aware of this difference, error. This error can be sent back to all inputs of the neuron and understand what input has affected this error so much, and accordingly, adjust the weight at this input so that the error is reduced.
This is the main idea of Backpropagation, the backpropagation algorithm. This process can be driven through the entire network and for each neuron to find how its weights can be modified. For this you need to take derivatives, but in principle, recently, this is not required. All packages for working with neural networks are automatically differentiated. If 2 years ago it was necessary to manually write complex derivatives for tricky layers, now packages do it themselves.
Recap: Important Trends
What is happening with the quality and complexity of models?

Firstly, the accuracy of neural networks is growing, and it is growing very much. There are already several examples when neural networks come to some area and completely supplant the classical algorithm. This has already happened in image processing and speech recognition, and this will happen in different areas. That is, neural networks appear that greatly reduce the error.
Deep Learning is highlighted in purple on the diagram, and the classic computer vision algorithm is highlighted in blue. It can be seen that Deep Learning appeared, the error decreased and continues to decrease further. That is why Deep Learning completely displaces all, conditionally, classical algorithms.
Another important milestone is that we begin to overtake a person in quality. At ImageNet, this was the first time in 2015. But in fact, neural network systems that are superior in quality to humans appeared earlier. The first documented distinct case is the year 2011, when a system was built that recognized German traffic signs and made it 2 times better than a person.
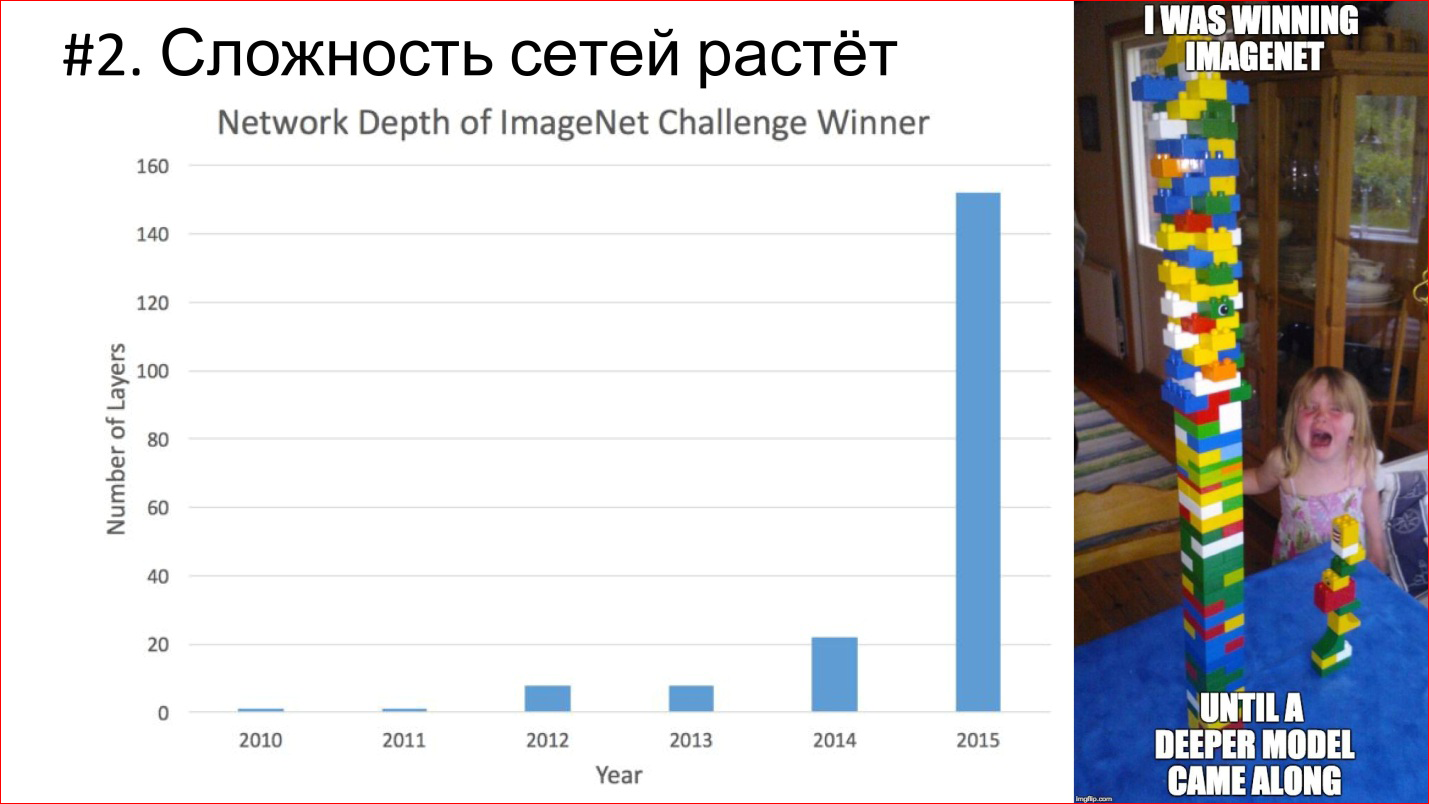
The second important trend - the complexity of neural networks is growing. In terms of depth, depth grows. If the winner of 2012 on ImageNet - the AlexNet network - there were less than 10 layers, then in 2014 there were already more than 20, in 2015 - under 150. This year, it seems, already over 200. What will happen next is unclear, perhaps there will be even more.

http://cs.unc.edu/~wliu/papers/GoogLeNet.pdf
In addition to the growing depth, the architectural complexity itself is growing. Instead of just joining the layers one by one, they begin to branch, blocks, structure appear. In general, architectural complexity is also growing.
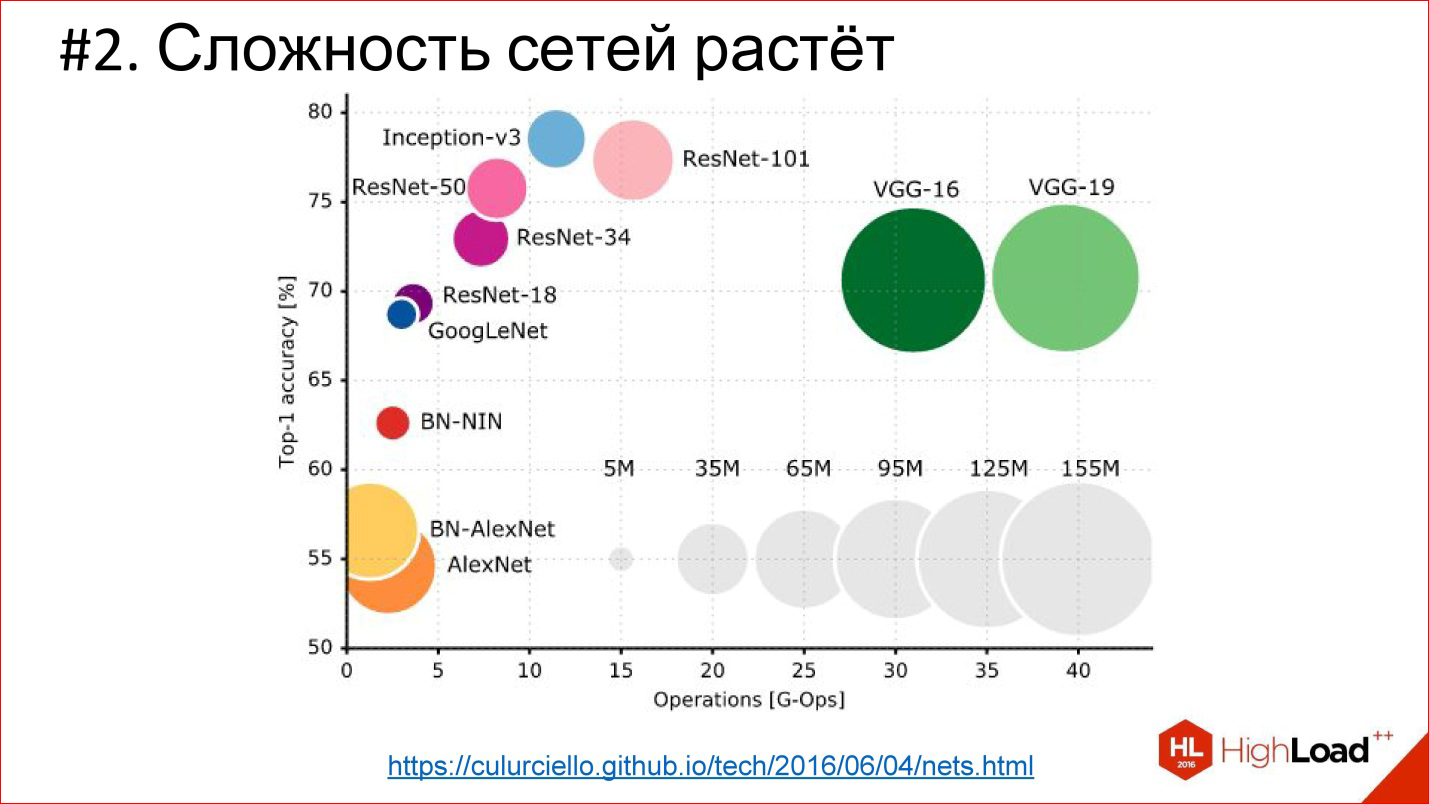
https://culurciello.github.io/tech/2016/06/04/nets.html
This is a graph of the accuracy of various neural networks. It shows the time it takes to execute, to miscalculate this network, that is, some kind of computing load. The size of the circle is the number of parameters that are described by the neural network. It is interesting to compare the classic AlexNet network - the winner of 2012 and later networks. They are better in accuracy, but usually contain fewer parameters. This is also an important trend that neural networks are becoming very sophisticated. That is, the architecture is changing so that even though the number of layers is 150, the total number of parameters is less than in the 6-7-layer network, which was in 2012. The architecture is somehow complicated in a very interesting way.

Another trend is the growth in data volumes. In 1998 for convolutional training
neural network that recognized handwritten checks, 10 7 pixels were used , in 2012 (IMAGENET) - 10 14 .
7 orders in 14 years - this is a crazy difference and a huge shift!

At the same time, the number of transits on the processor is also growing, computing power is growing - Moore's law is valid. Over these 14 years, processors have become conditionally 1000 times faster. This is illustrated by the GPUs that currently dominate the Deep Learning field. Almost everything is counted on graphic accelerators.
NVIDIA has transformed itself from a gaming company into a company for artificial intelligence. Its exhibitors left far behind Intel exhibitors, which against this background do not look at all.
This is a picture of 2013 when the top-end graphics card was 4.5 TFLOPS. Now the new TITAN X is already 11 TFLOPS. In general, the exhibitor continues!
In fact, we can expect that FPGAs will appear in the near future, which will partially displace the GPU, and maybe even neuromorphic processors will appear over time. Keep track of this - there is also a lot of interesting going on.
Architecture of neural networks. Direct distribution neural networks
Fully Connected Feed-
Forward Neural Network, FNN The first classical architecture is direct-link fully connected neural networks, or Fully Connected Feed-Forward Neural Network, FNN.

Multilayer Perceptron is generally a classic of neural networks. That picture of neural networks that you saw, this is it - a multilayer fully connected network. Fully connected - this means that each neuron is connected to all neurons of the previous layer. A good network works, it is suitable for classification, many classification problems are successfully solved.
However, she has 2 problems:
- Many options
For example, if you take a neural network of 3 hidden layers, which needs to process images 100 * 100 ps, this means that there will be 10,000 ps at the input, and they will start up in 3 layers. In general, to be honest with all the parameters, such a network will have about a million of them. This is actually a lot. To train a neural network with a million parameters, you need a lot of training examples, which are not always there. In fact, there are examples now, but they weren’t before - therefore, in particular, the networks could not train properly.
In addition, a network with many parameters has an additional tendency to retrain. It can be imprisoned on something that in reality does not exist: some kind of noise Data Set. Even if, in the end, the network remembers examples, but on those that it has not seen, then it will not be able to be used normally.
Plus there is another problem called:
- Fading gradients
Remember the story about Backpropagation, when an error from the outputs is sent to the input, distributed to all weights and sent further through the network? Further, these derivatives - that is, the gradient (derivative of the error) - are driven back through the neural network. When there are many layers in the neural network, a very, very small part can remain from this gradient at the very end. In this case, the input weight will be almost impossible to change because this gradient is practically “dead”, it is not there.
This is also a problem, because of which deep neural networks are also difficult to train. We will return to this topic further, especially on recurrent networks.

There are various variations of FNN networks. For example, a very interesting variation of the Auto Encoder. This is a direct distribution network with a so-called bottleneck in the middle. This is a very small layer, for example, only 10 neurons.
What are the advantages of such a neural network?
The purpose of this neural network is to take some kind of input, drive it through itself and generate the same input at the output, that is, so that they coincide. What's the point? If we can train such a network that takes an input, drives through itself and generates the exact same output, this means that these 10 neurons in the middle are enough to describe this input. That is, you can greatly reduce the space, reduce the amount of data, economically encode any input data in new terms of 10 vectors.
It is convenient and it works. Such networks can help you, for example, reduce the dimension of your task or find some interesting features that you can use.

There is still an interesting RBM model. I wrote it in a variation of FNN, but in fact this is not true. Firstly, it is not deep, and secondly, it is not Feed-Forward. But it is often associated with FNN networks.
What it is?
This is a shallow model (it is drawn in the corner on the slide), which has an input and has some kind of hidden layer. You give an input signal and try to train the hidden layer so that it generates this input.
This is a generative model. If you trained her, then later you can generate analogs of your input signals, but slightly different ones. It is stochastic, that is, each time it will generate something a little different. If, for example, you trained such a model to generate handwritten units, then it will generate a certain amount of slightly different ones.

What makes RBM good is that it can be used to train deep networks. There is such a term - Deep Belief Networks (DBN) - in fact, this is a way of learning deep networks, when 2 lower layers of a deep network are taken separately, input is input and RBM is trained on these first two layers. After that, these weights are fixed. Next, the second layer is taken, considered as a separate RBM and trained in the same way. And so on throughout the network. Then these RBMs are joined, combined into one neural network. It turns out a deep neural network, which it should have been.
But now there is a huge advantage - if you used to train it simply from some random (random) state, now it is not random - the network is trained to restore or generate data from the previous layer. That is, her weights are reasonable, and in practice this leads to the fact that such neural networks are really quite well trained. Then they can be slightly trained by some examples, and the quality of such a network will be good.
Plus there is an added advantage. When you use RBM, you are essentially working on unallocated data, which is called Un supervised learning. You just have pictures, you don’t know their classes. You drove away the millions, billions of pictures that you downloaded from Flickr or somewhere else, and you have some kind of structure in the network itself that describes these pictures.
You do not know what it is yet, but these are reasonable weights that you can then take and retrain with a small number of different pictures, and it will already be good. This is a cool way to use a combination of 2 neural networks.
Further you will see that this whole story is actually about Lego. That is, you have separate networks - recurrent neural networks, some other networks - these are all blocks that can be combined. They combine well on different tasks.
These were classic direct distribution neural networks. Next, we turn to convolutional neural networks.
Neural Network Architecture: Convolutional Neural Networks
Convolutional Neural Networks, CNN

https://research.facebook.com/blog/learning-to-segment/
Convolutional neural networks solve 3 main tasks:
- Classification. You submit a picture, and the neural network just says - you have a picture about a dog, about a horse, about something else, and it gives out a class.
- Detection is a more advanced task when the neural network not only says that there is a dog or horse in the picture, but also finds the Bounding box - where it is in the picture.
- Segmentation. In my opinion, this is the coolest task. In fact, this is a pixel-by-pixel classification. Here we are talking about every pixel in the image: this pixel refers to a dog, this one to a horse, and this one to something else. In fact, if you know how to solve the segmentation problem, then the other 2 tasks are already automatically given.
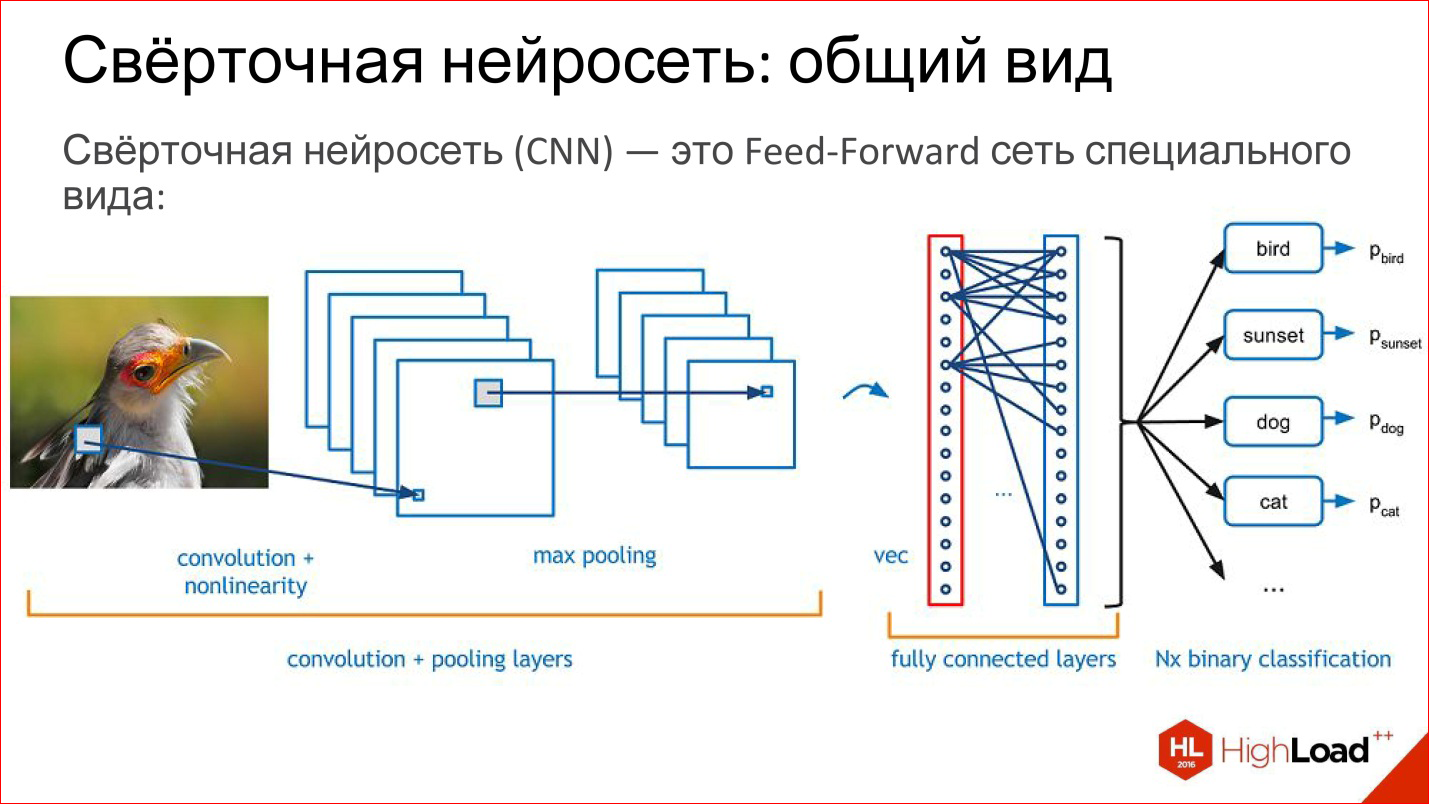
What is a convolutional neural network? In fact, the convolutional neural network is an ordinary Feed-Forward network, it’s just a little special. Lego already begins.
What is in the convolution network? She has:
- Convolutional layers - I will tell you further what it is;
- Subsampling, or Pooling layers, which reduce the size of the image;
- Ordinary fully connected layers, the same multilayer perceptron, which is simply hung from above on these first 2 tricky layers.
A little more detail about all these layers.

- Convolutional layers are usually drawn as a set of planes or volumes. Each plane in such a figure or each slice in this volume is, in fact, one neuron that implements the convolution operation. Again, later I will tell you what it is. In fact, this is a matrix filter that transforms the original image into some other, and this can be done many times.
- Sub- sampling layers (I will call Subsampling, it's easier) simply reduce the image size: it was 200 * 200 ps, after Subsampling it became 100 * 100 ps. In fact, averaging is a little trickier.
- Fully connected layers are usually used by the perceptron for classification. There is nothing special about them.
http://intellabs.github.io/RiverTrail/tutorial/
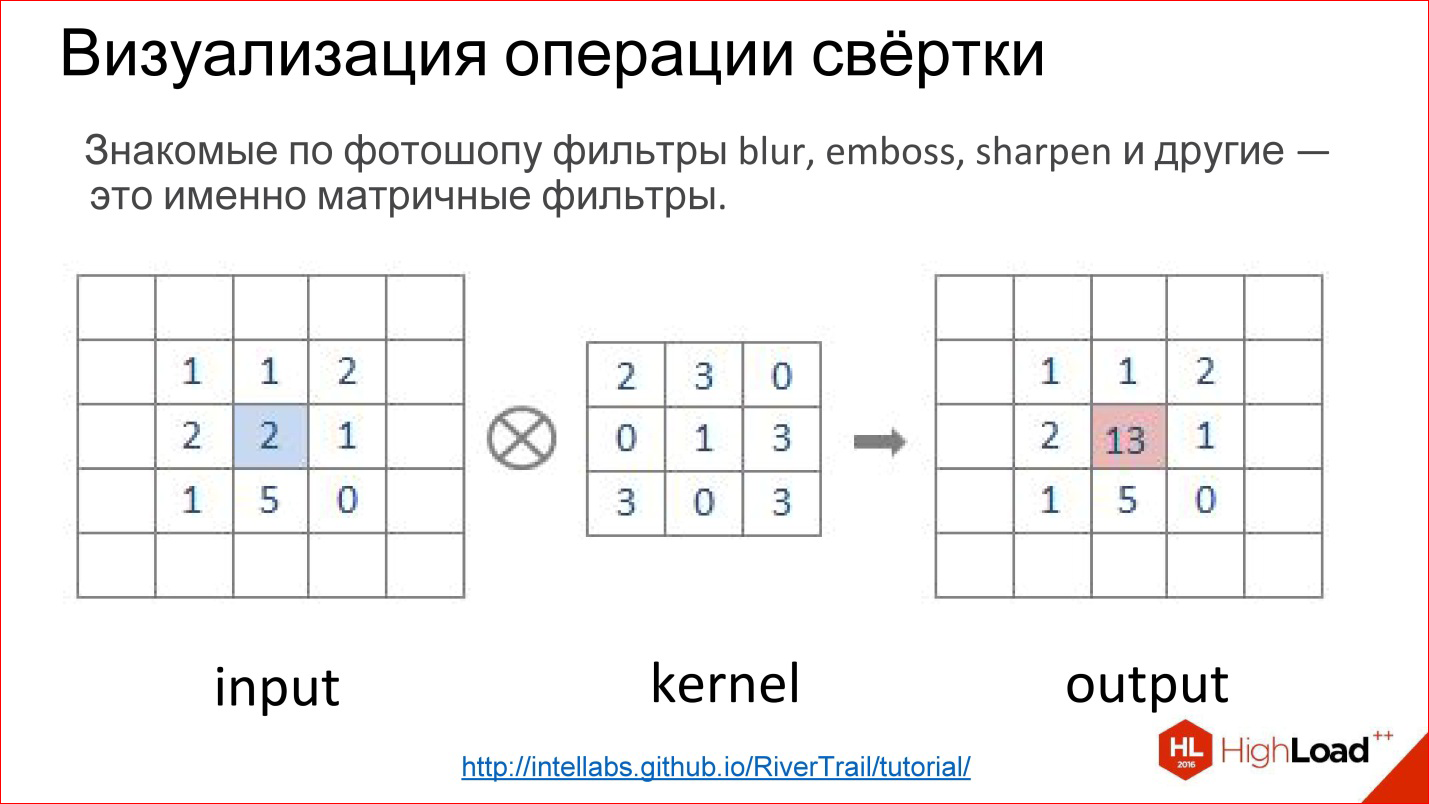
What is a convolution operation? It scares everyone, but in fact it is a very simple thing. If you worked in Photoshop and did Gaussian Blur, Emboss, Sharpen and a bunch of other filters, these are all matrix filters. Matrix filters - this is actually a convolution operation.
How is it implemented? There is a matrix called the filter core (in the kernel picture). For Blur, it will be all units. There is an image. This matrix is superimposed on a piece of the image, the corresponding elements are simply multiplied, the results are added and written to the center point.

http://intellabs.github.io/RiverTrail/tutorial/
So it looks more clearly. There is an Image Input, there is a filter. You run a filter through the entire image, honestly multiply the corresponding elements, add, write to the center. Run, run - built a new image. This is a convolution operation.
That is, in fact, the convolution in convolutional neural networks is a tricky digital filter (Blur, Emboss, anything else), which itself is trained.

http://cs231n.github.io/convolutional-networks/
Actually, convolutional layers all work on volumes. That is, even if we take a regular RGB image, there are already 3 channels - this, in fact, is not a plane, but a volume of 3, conditionally, cubes.
The convolution in this case is no longer represented by a matrix, but by a tensor - a cube in fact.
You have a filter, you run through the entire image, it immediately looks at all 3 color layers and generates one new point for this one volume. Run through the entire image - built one channel, one plane of the new image. If you have 5 neurons, you have built 5 planes.
This is how the convolutional layer works. The task of training a convolutional layer is the same task as in ordinary neural networks - to find weights, that is, to actually find the very convolution matrix that is completely equivalent to weights in neurons.
What do such neurons do? They actually learn to look for some features, some local signs in that small part that they see - that’s all. Running one such filter is building a certain map of the location of these signs in the image.
Then you built a lot of such planes, then use them as an image, applying to the following inputs.

http://vaaaaaanquish.hatenablog.com/entry/2015/01/26/060622
The Pooling operation is an even simpler operation. This is simply averaging or taking a maximum. It also works on some small squares, for example, 2 * 2. You superimpose on the image and, for example, select the maximum element from this 2 * 2 box, send it to the output.
Thus, you reduced the image, but not with the tricky Average, but with a slightly more advanced thing - you took the maximum. This gives slight displacement invariance. That is, it doesn’t matter to you, some sign was found in this position or 2 ps to the right. This thing allows the neural network to be slightly more resistant to image shifts.
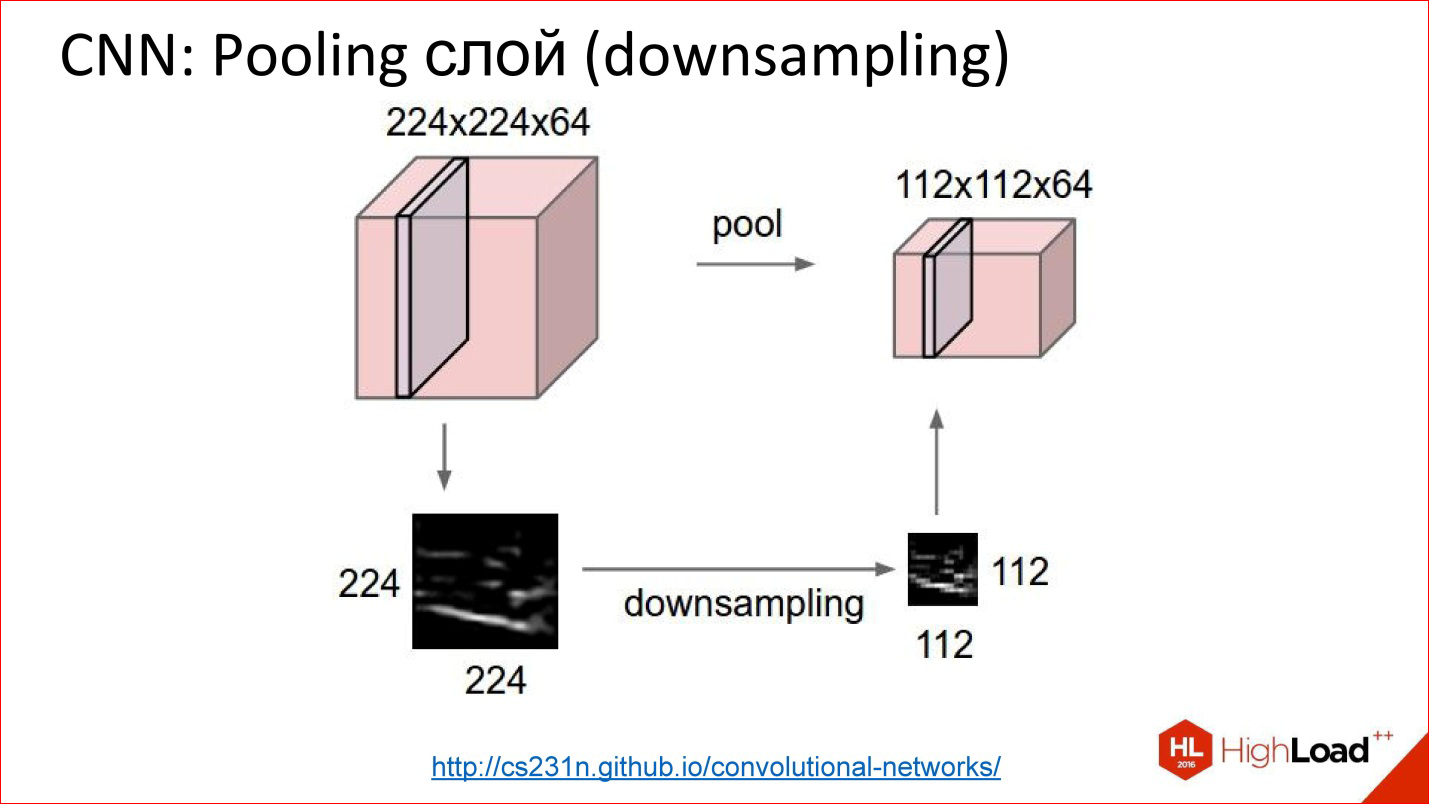
http://cs231n.github.io/convolutional-networks/
This is how the Pooling layer works. There is a cube of some volume - 3 channels, 10, or 100 channels that you counted as convolutions. It simply reduces it in width and height, but does not touch the rest of the dimensions. Everything is a primitive thing.

What are convolutional networks good for?
They are good in that they have significantly fewer parameters than a conventional fully connected network. Remember the example of a fully-connected network, which we considered, where we got a million weights. If we take a similar, more precisely, similar one, it cannot be called similar, but a close convolutional neural network, which will have the same input, the same output, will also have one fully connected layer at the output and another 2 convolutional layers, where there will also be 100 neurons, as in the core network, it turns out that the number of parameters in such a neural network has decreased by more than an order of magnitude.
It’s great if the parameters are so fewer - it’s easier to train the network. We see this, it is really easier to train.
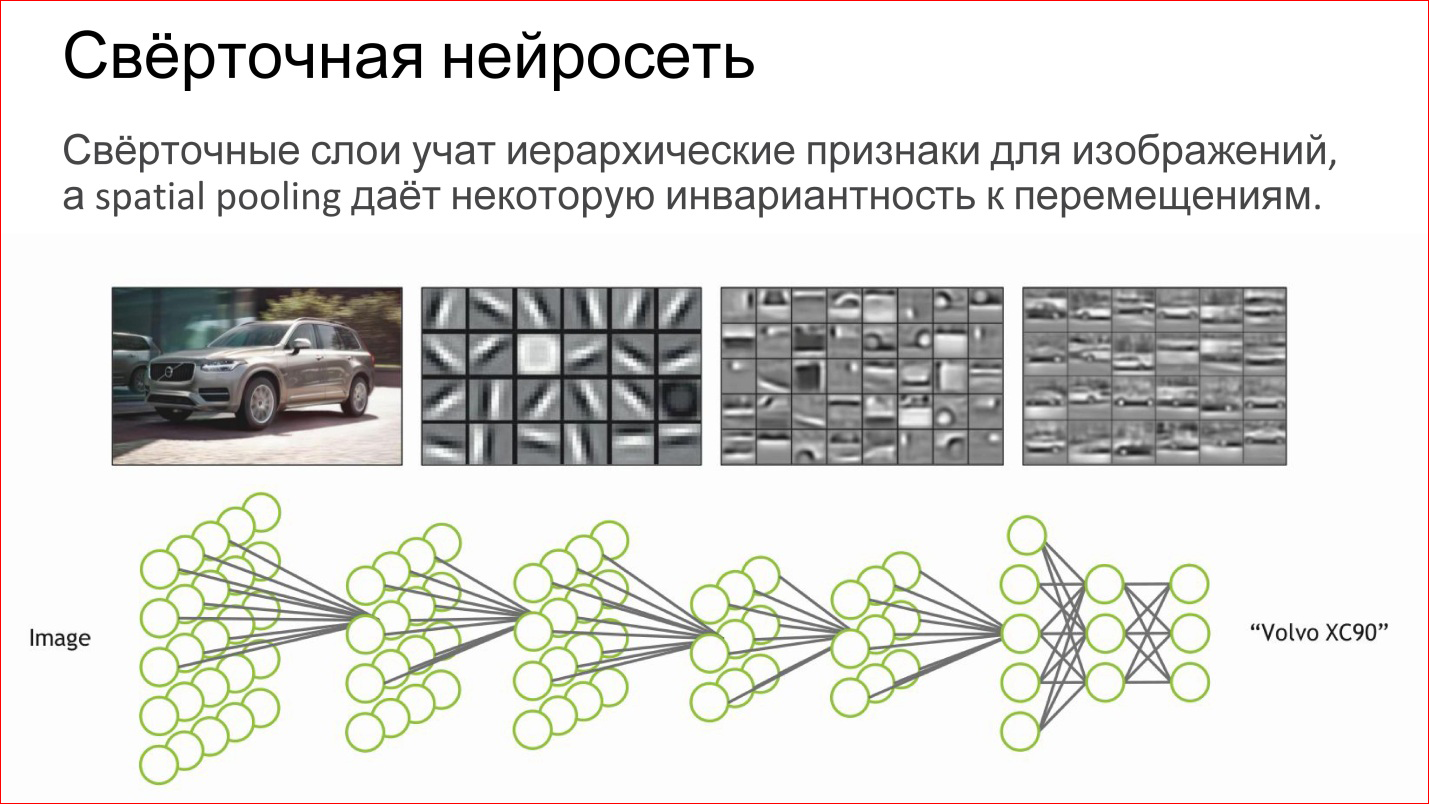
What does a convolutional neural network do?
In fact, it automatically teaches some hierarchical features for images: first, basic detectors, lines of different tilt, gradients, etc. Of these, she collects some more complex objects, then even more complex ones.
If you perceive a neuron as a simple logistic regression, a simple classifier, then a neural network is just a hierarchical classifier. First you select simple signs, from them you combine complex signs, from them even more complex, even more complex, and in the end you can combine some very complex sign - a specific person, a specific machine, an elephant, anything else.
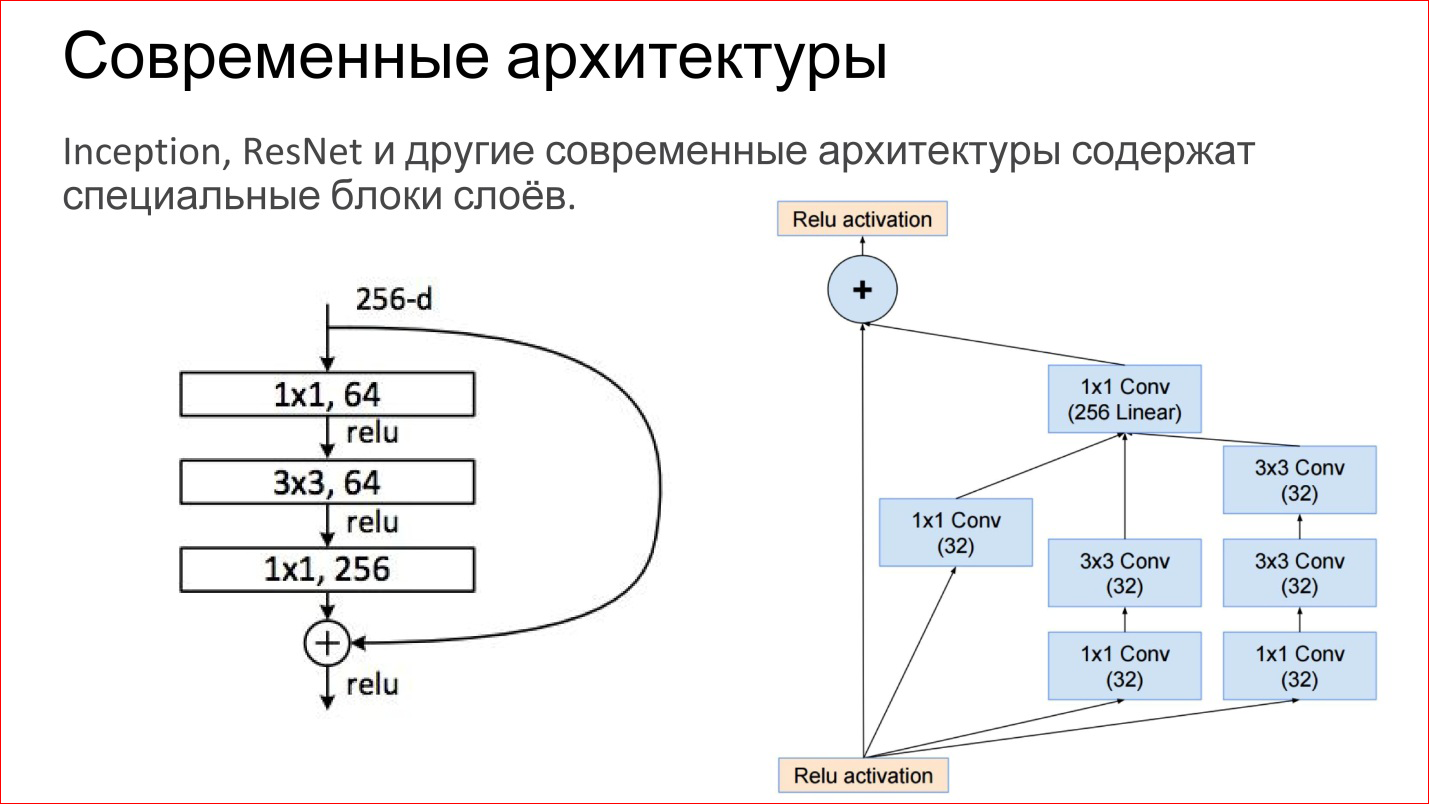
Modern architectures of convolutional neural networks have become much more complicated. Those neural networks that won the latest ImageNet competitions are no longer just convolutional layers, Pooling layers. These are directly finished blocks. The figure shows examples from the Inception network (Google) and ResNet (Microsoft).
In fact, inside are the same basic components: the same convolutions and pullings. It’s just that now there are more of them, they are somehow artfully combined. Plus now there are direct connections that do not allow you to transform the image at all, but simply transfer it to the output. This, incidentally, helps ensure that the gradients do not fade. This is an additional way of passing the gradient from the end of the neural network to the beginning. It also helps to train such networks.
It was a very classic convolutional neural network. Yes, there are different types of layers that can be used for classification. But there are more interesting applications.

https://arxiv.org/abs/1411.4038
For example, there is such a variety of convolutional neural networks called Fully-convolutional networks (FCN). They are rarely talked about, but this is a cool thing. You can take and tear off the last multilayer perceptron, it is not needed - and throw it away. And then the neural network can magically work on images of arbitrary size.
That is, she learned, for example, to define 1000 classes in the images of kitties, dogs, something else, and then we took the last layer and did not tear it off, but transformed it into a convolutional layer. There are no problems - you can count the weight. Then it turns out that this neural network, as it were, works with the same window for which it was trained, 100 * 100 ps, but now it can run through this window throughout the image and build a kind of heat map at the output - where in this particular image is specific class.
You can build, for example, 1000 of these Heatmap for all your classes and then use this to determine the location of the object in the picture.
This is the first example where a convolutional neural network is used not for classification, but in fact for image generation.
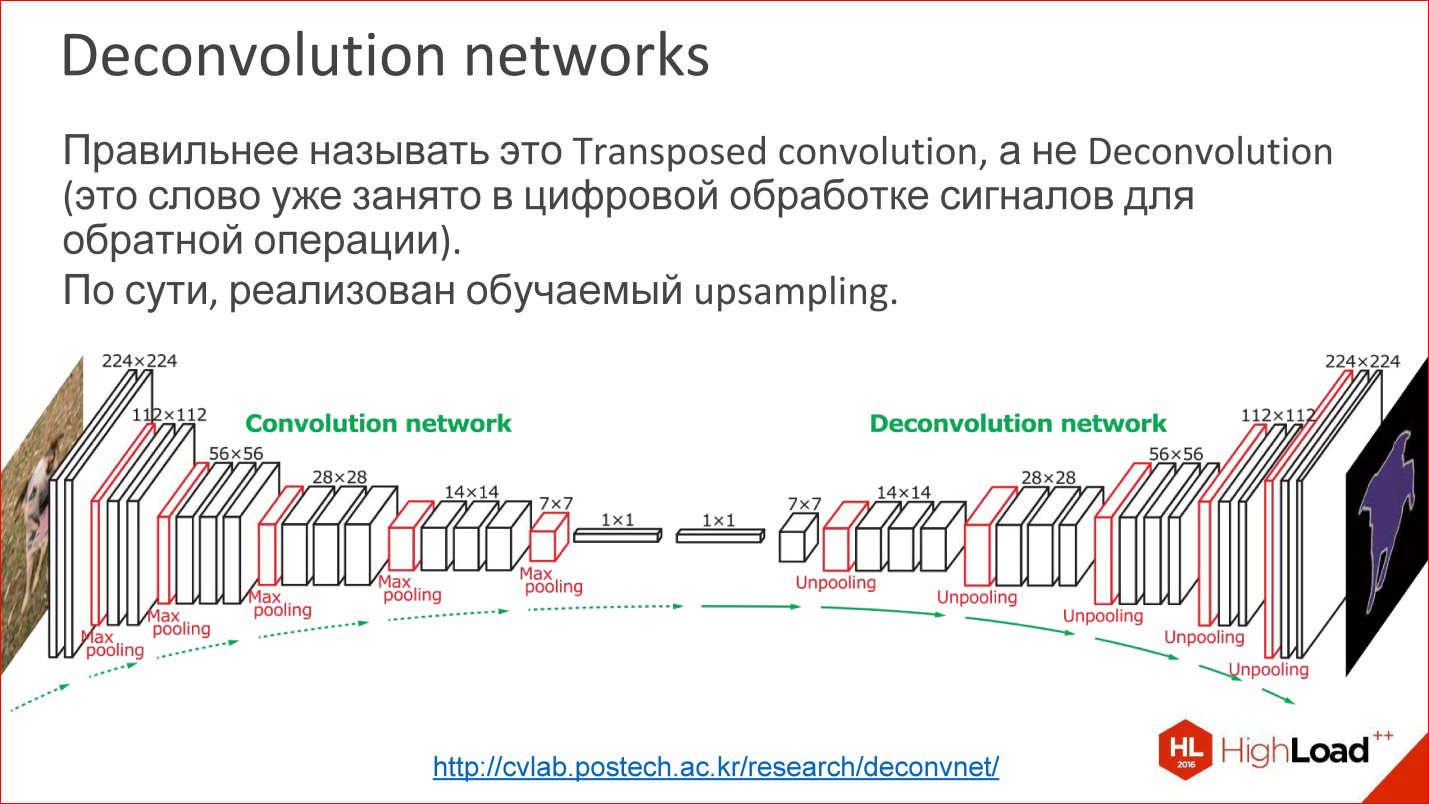
http://cvlab.postech.ac.kr/research/deconvnet/
A more advanced example is Deconvolution networks. They are also rarely talked about, but this is an even cooler thing.
In fact, Deconvolution is the wrong term. In digital signal processing, this word is occupied by a completely different thing - similar, but not like that.
What it is? Essentially, this is Upsampling learner. That is, at some point, you reduced your image to some small size, maybe even to 1 ps. Rather, not to a pixel, but to some small vector. Then you can take this vector and reveal it.
Or, if at some point you get a 10 * 10 ps image, you can now do the upsampling of this image, but in some tricky way in which the upsampling weights are also trained.
This is not magic, it works, and in fact it allows you to train neural networks that get some kind of output picture from the input image. That is, you can submit entry / exit samples, and what is in the middle will learn by itself. It is interesting.
In fact, many tasks can be reduced to generating pictures. Classification is a cool task, but it is still not comprehensive. There are many tasks where you need to generate pictures. Segmentation is basically a classic task where you need to have a picture at the output.
Moreover, if you have learned to do so, then you can do it another way, more interesting.
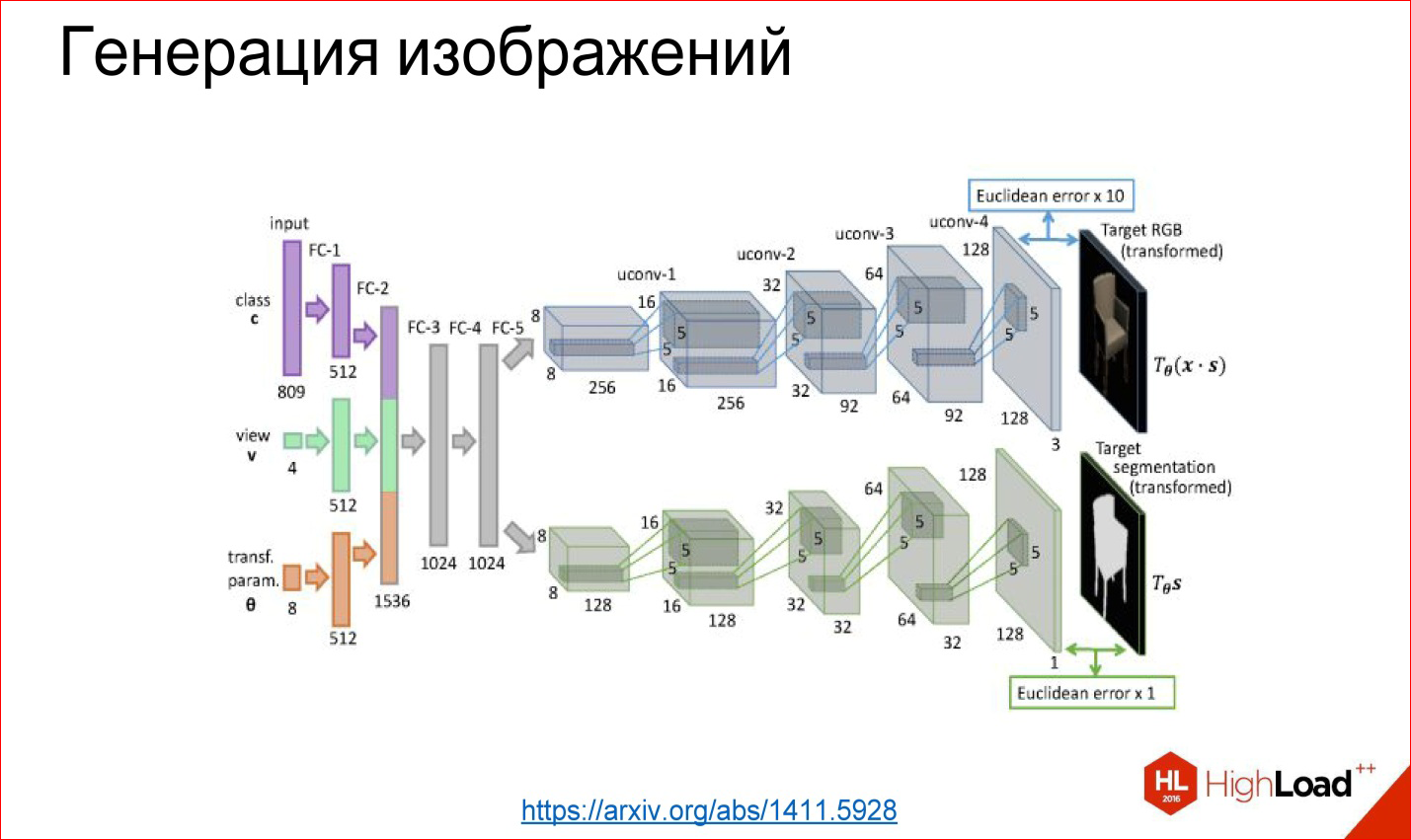
https://arxiv.org/abs/1411.5928
You can tear off the first part, for example, and fasten some kind of fully connected network again, which we will train - that it receives, for example, a class number: generate a chair for me at such an angle and in such and such a way. These layers generate further some internal representation of this chair, and then it unfolds into the picture.
This example is taken from a work where they really taught the neural network to generate different chairs and other objects. It works too, and it's fun. This is assembled, in principle, from the same base units, but they are wrapped in a different way.

https://arxiv.org/abs/1508.06576
There are non-classical tasks, for example, transferring the style that we all hear about in the last year. There are a bunch of applications that can do this. They work on roughly the same technology.

https://arxiv.org/abs/1508.06576
There is a ready-made trained network for classification. It turned out that if you take a derivative picture, load it into this neural network, then different convolutional layers will be responsible for different things. That is, on the first convolutional layers there will be stylistic features of the image, on the last - the content features of the image, and this can be used.
You can take a picture as a style sample, drive it through a ready-made neural network that you haven’t been trained at all, remove style attributes, remember. You can take any other picture, drive away, take content signs, remember. And then drive the random picture (noise) again through this neural network, get signs on the same layers, compare with those that should have been received. And you have a task for Backpropagation. In fact, further by gradient descent, you can transform the random picture to one for which these weights on the desired layers will be as needed. And you got a stylized picture.
The only problem with this method is that it is long. This iterative run of the picture back and forth is a long time. Whoever played with this style generation code knows that the classic code is long, and you have to torment yourself. All services like Prisms and so on, which generate more or less quickly, work differently.
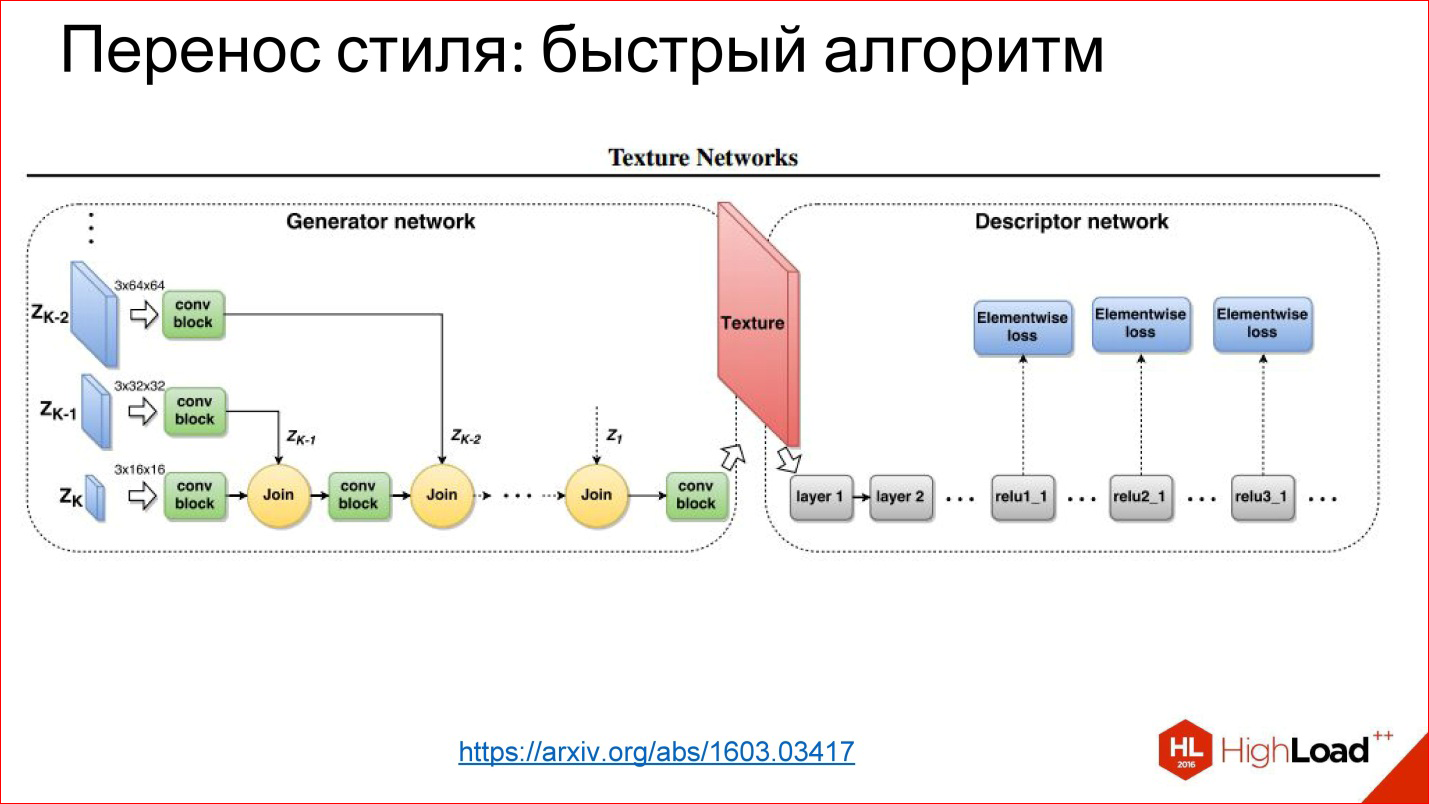
https://arxiv.org/abs/1603.03417
Since then, we have learned to generate networks that simply generate a picture in 1 pass. This is the same task of image transformation that you have already seen: there is something at the input, there is something at the output, you can teach everything in the middle.
In this case, the trick is that the loss function is the very error function you add to this neural network, and the error function is removed from the usual neural network that was trained for classification.
These are such hacker methods for using neural networks, but it turned out that they work, and this leads to cool results.
Next, we turn to recurrent neural networks.
Neural Network Architecture: Recursive Neural Networks
Recurrent Neural Networks, RNN A
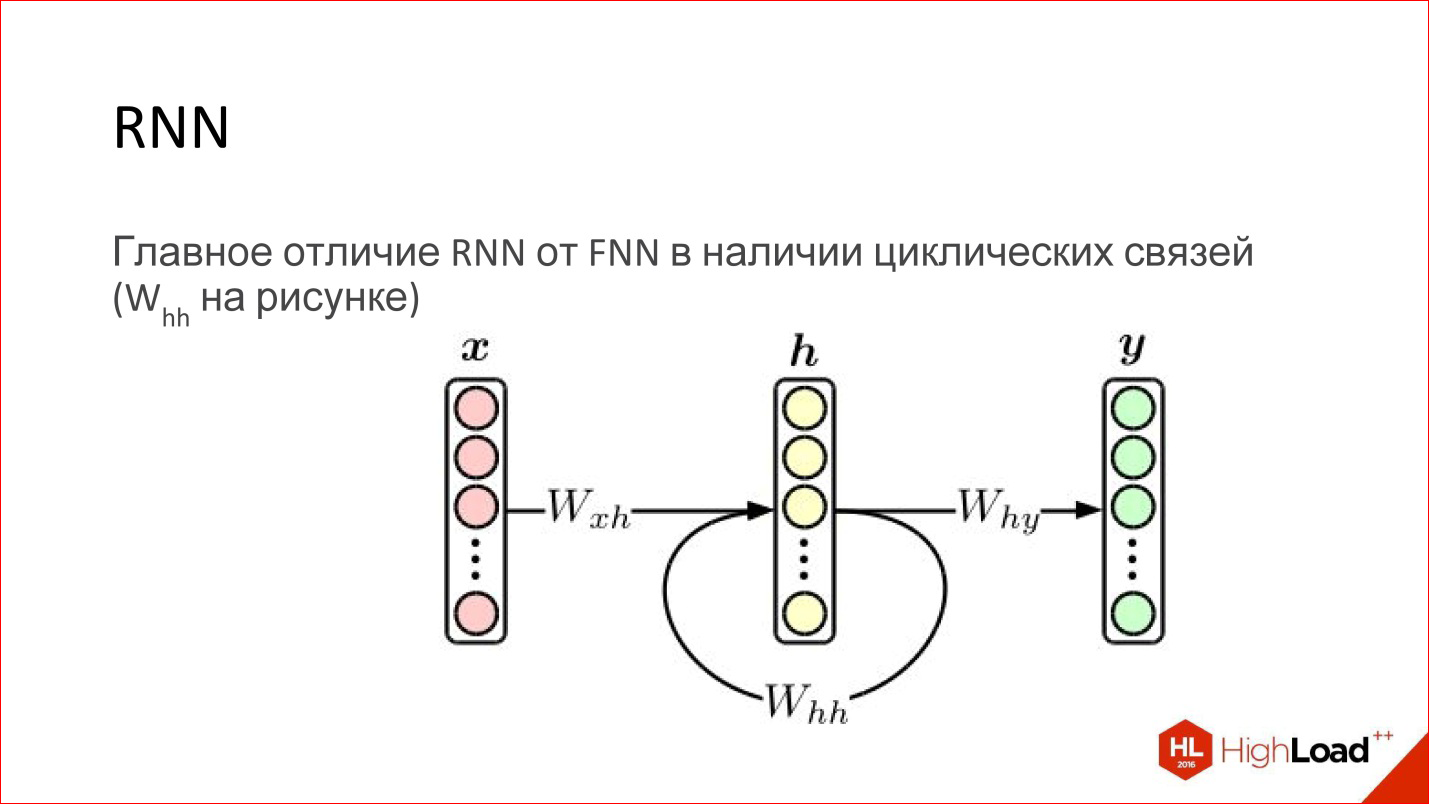
recurrent neural network is actually a really cool thing. At first glance, the main difference between them and ordinary FNN networks is that some kind of cyclic connection just appears. That is, the hidden layer sends its own values to itself in the next step. It would seem like a minor thing, but there is a fundamental difference.

About the usual Feed-Forward neural network, it is known that this is a universal approximator. They can approximate more or less any continuous function (there is such a Tsybenko theorem). It's great, but recurrent neural networks - Turing is complete. They can calculate any computable.
In fact, recurrent neural networks are a regular computer. The task is to properly train him. Potentially, it can read any algorithm. Another thing is that it is difficult to teach.
In addition, conventional Feed-Forward-neural networks have no way to take into account the order in time - they do not have this, it is not represented. Recursive networks do this explicitly; the concept of time is embedded in them.
Conventional Feed-Forward networks do not have any memory except that which was obtained at the training stage, and recurrent networks possess. Due to the fact that the contents of the layer are transferred back to the neural network, this is, as it were, its memory. It is stored during the operation of the neural network. This also adds a lot.
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
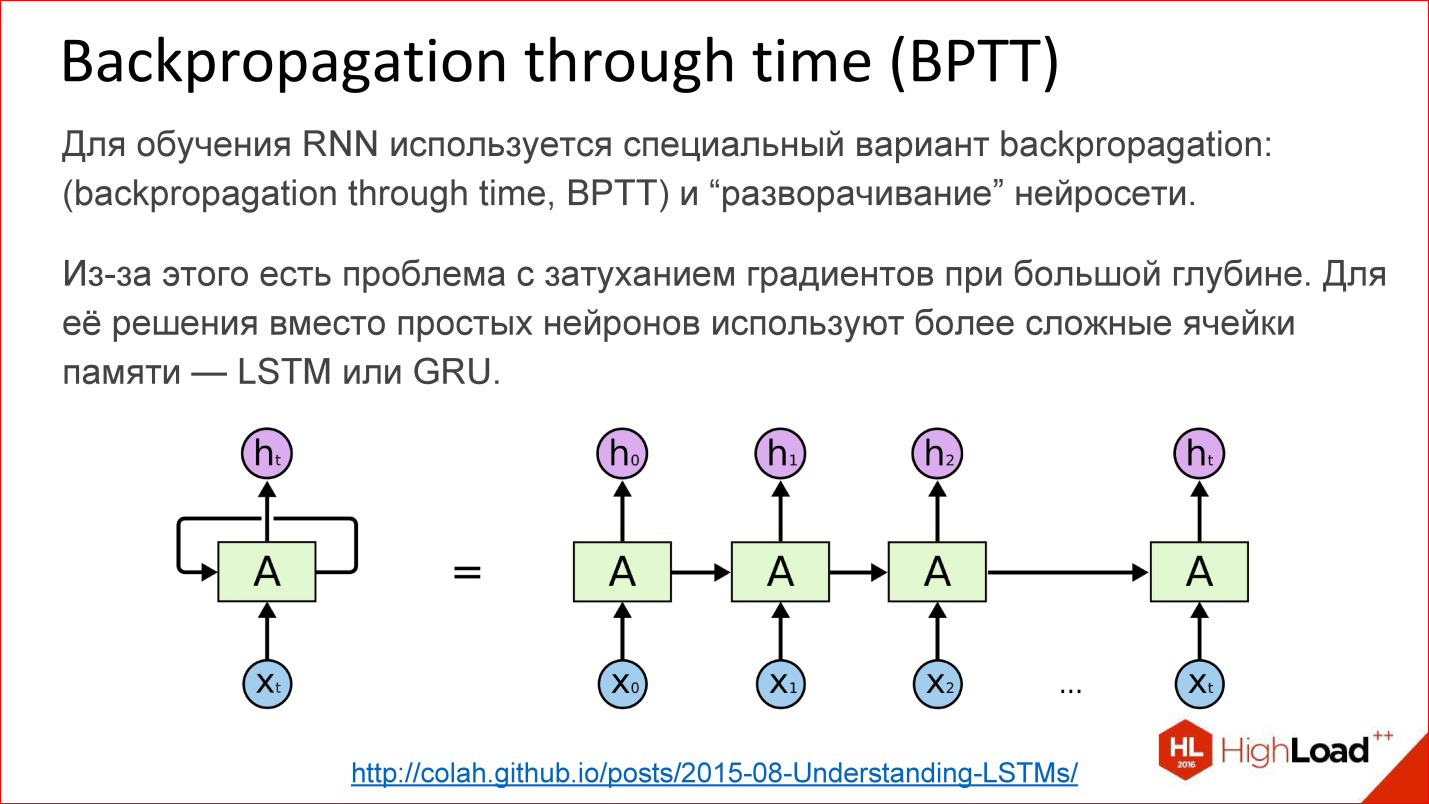
How are recurrent neural networks trained? In fact, almost the same. In addition to Backpropagation, of course, there are many other algorithms, but at the moment, Backpropagation works best.
For recurrent neural networks, there is a variation of this algorithm - Backpropagation through time. The idea is very simple - you take a recurrent neural network and simply unroll the cycle into several steps, for example, 10, 20 or 100, and you get the usual deep neural network, which after that you teach ordinary Backpropagation.
But there is a problem. As soon as we start talking about deep neural networks - where 10, 20, 100 layers - from gradients that should go from the end to the very beginning, nothing remains for 100 layers. Something needs to be done with this. At this point, they came up with a hack, a beautiful engineering solution called LSTM or GRU is a memory cell.

https://deeplearning4j.org/lstm
Their idea is that the visualization of a normal neuron is replaced by some tricky thing that has memory and has a gate that controls when this memory needs to be reset, overwritten or saved, etc. These gates are also trained in the same way as everything else. In fact, this cell, when it was trained, can tell the neural networks that we now hold this internal state for a long time, for example, 100 steps. Then, when the neural network has used this state for something, it can be reset. It became unnecessary, we went to a new count.
In all more or less serious tests, these neural networks devote much quality to ordinary classical recurrent ones, which are just on neurons. Almost all recurrent networks are currently built on either LSTM or GRU.
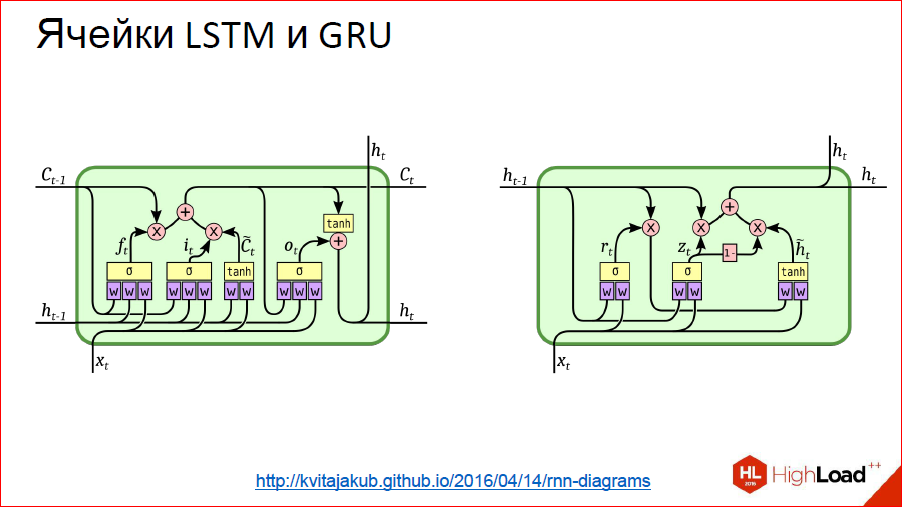
http://kvitajakub.github.io/2016/04/14/rnn-diagrams
I will not go deep into what it is inside, but it’s such tricky blocks, much more complicated than ordinary neurons, but, in essence, they are similar. There are some gates that control this very thing: “remember - do not remember”, “pass on - do not pass on”.
These were classic recurrent neural networks. Next begins the topic, which is often silent, but it is also important.

When we work with a sequence in a recurrent network, we usually feed one element, then the next, and bring the previous state of the network to the input, this natural direction arises - from left to right. But it is not the only one! If we have, for example, a sentence, we begin to submit his words in the usual way to the neural network - yes, this is a normal way, but why not submit it from the end?
That is, in many cases, the sequence is given entirely from the very beginning. We have this proposal, and it makes no sense to somehow single out one direction relative to another. We can drive out a neural network on the one hand, on the other hand, actually having 2 neural networks, and then combine their result.
This is called Bidirectional, a bi-directional recurrent neural network. Their quality is even higher than ordinary recurrent networks, because there is more context: for each point there are now 2 contexts - what happened before and what comes after. For many tasks, this adds quality, especially for tasks related to the language.
For example, there is a German language, where something must be hung in the end, and the offer will change - such a network will help.
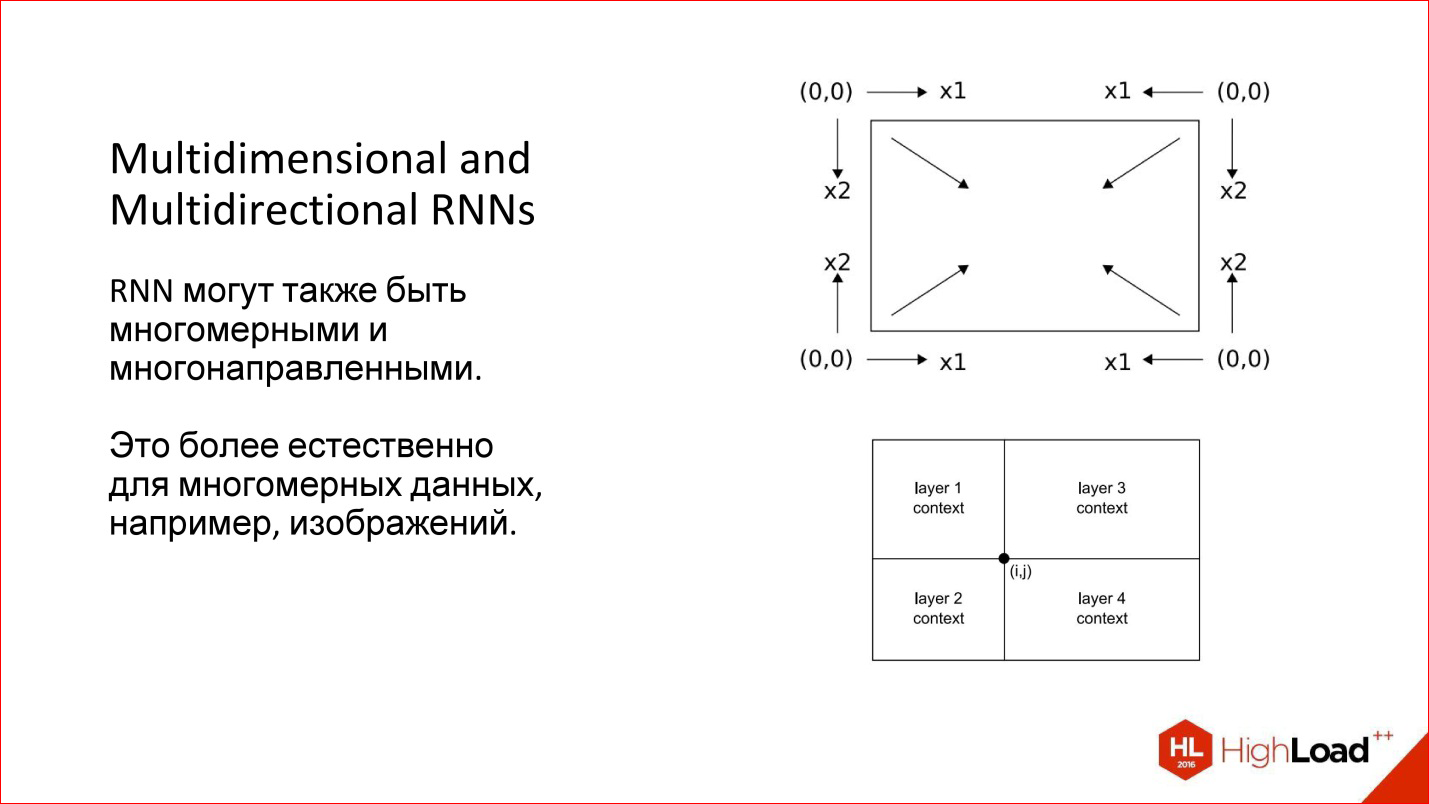
Moreover, we considered one-dimensional cases - for example, sentences. But there are multidimensional sequences - the same image can also be considered as a sequence. Then he generally has 4 directions, which are reasonable in their own way. For an arbitrary point in the image, there are, in fact, 4 contexts with such a round.
There are interesting multidimensional recurrent neural networks: they are both multidimensional and multidirectional. Now they are a little forgotten. This, incidentally, is an old development, which is already 10 years old, probably, but now it is starting to surface.

Here are the latest works (2015). This neural network is an analogue of the classical LeNet neural network, which classified handwritten numbers. But now it is never convolutional, but recurrent and multidirectional. There are arrows, which in different directions pass through the image.
The second example is the cunning neural network, which was used to segment brain sections. She, too, has never been convolutional, but recursive, and she won in some other contest.
This is actually a cool technology. I think that in the near future recurrent networks will greatly suppress convolutional networks because even for images they add a lot of things. This is a potentially more powerful class.
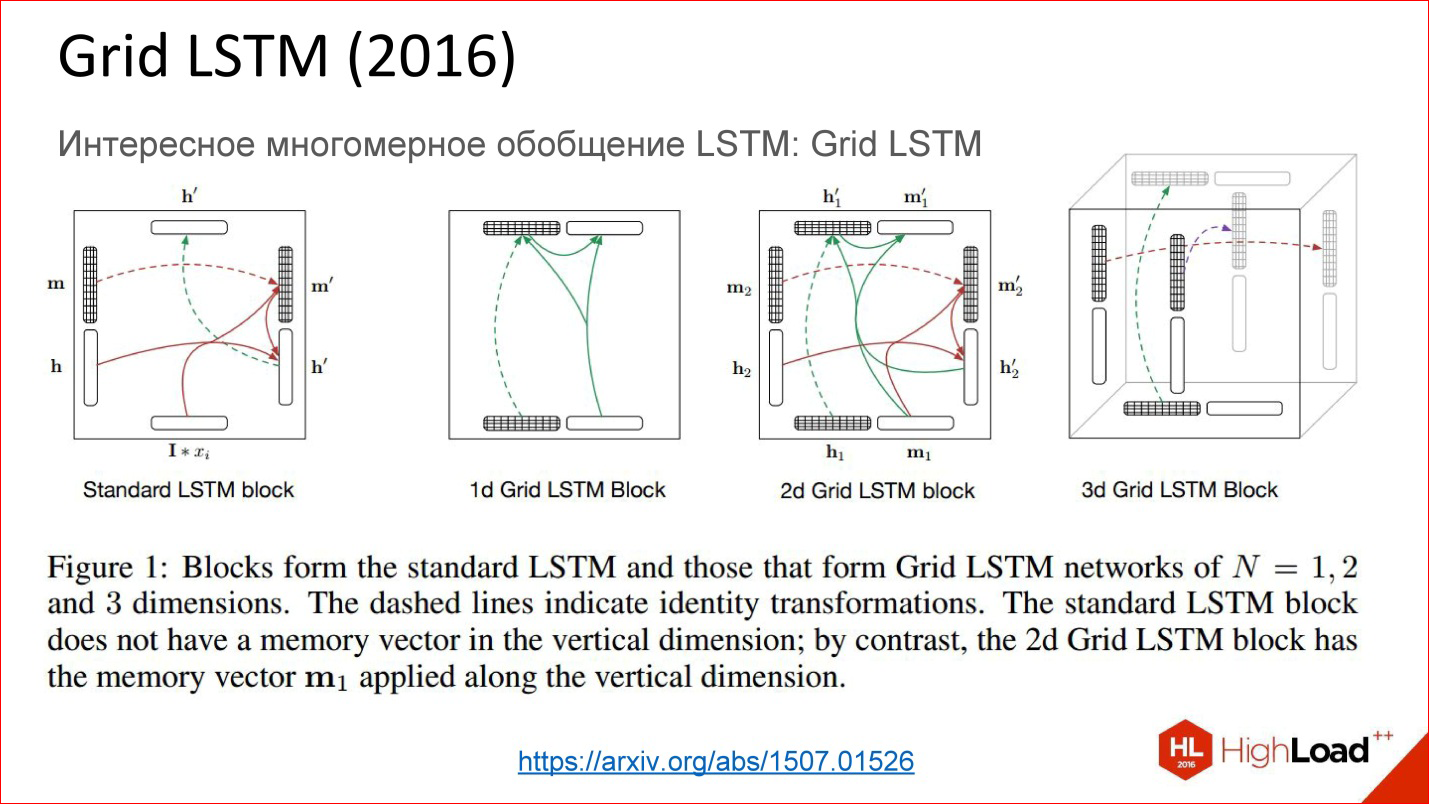
https://arxiv.org/abs/1507.01526
And there is also a very recent development of Grid LSTM, which is still not very meaningful and realized. In fact, the idea is simple - they took a recurrent network, at some point replaced the neurons with some tricky cells, so that the state could be stored for a long time. If our network is deep in this direction, then there is no gate; gradients are also lost. What if something else is added in this direction? Yes, they added, it turned out cool!
Just a problem - now there are almost no ready-made software libraries where this is implemented. There are 1-2 pieces of code that you can try to use. I hope that in the coming year these things will be publicly available, and it will be really cool.
This is a wonderful thing, look what will happen to her, she is good.
Now advanced topics begin.
Multimodal Learning
Mixing different modalities in one neural network, for example, image and text.
Multimodal training is also ideologically simple thing, when we take and mix 2 modalities in a neural network, for example, pictures and text. Prior to this, we examined cases of work on 1 modality - only in pictures, only in sound, only in text. But you can mix it up!

http://arxiv.org/abs/1411.4555
For example, there is a cool case - generating a description of pictures. You submit a picture to the neural network, it generates text at the output, for example, in normal English, which describes what is happening in this picture. This technology a few years ago seemed completely impossible because it was not clear how to do it. But now it is implemented.
By the way, we posted publicly available videos of the last five years of the conference of developers of high-loaded systems HighLoad ++ . Watch, study, share and subscribe to the YouTube channel .
Everything is simple inside. There is a convolutional neural network that processes the image, extracts some signs from it, and writes it in some tricky state vector. There is a recurrent network, which is taught from this state to generate and expand the text.
This combination of 2 modalities is very productive. There are many such examples.

https://www.cs.utexas.edu/~vsub/
For example, there is an interesting task of annotating a video. In fact, another dimension is simply added to the previous task - time.
For instance:
- There is a soccer player who runs around the field;
- Есть сверточная нейросеть, которая генерит признаки;
- Есть рекуррентная нейросеть, которая описывает, что произошло в каждом кадре или в последовательности кадров.
It is interesting!
In a little more detail, how multimodal learning looks inside.
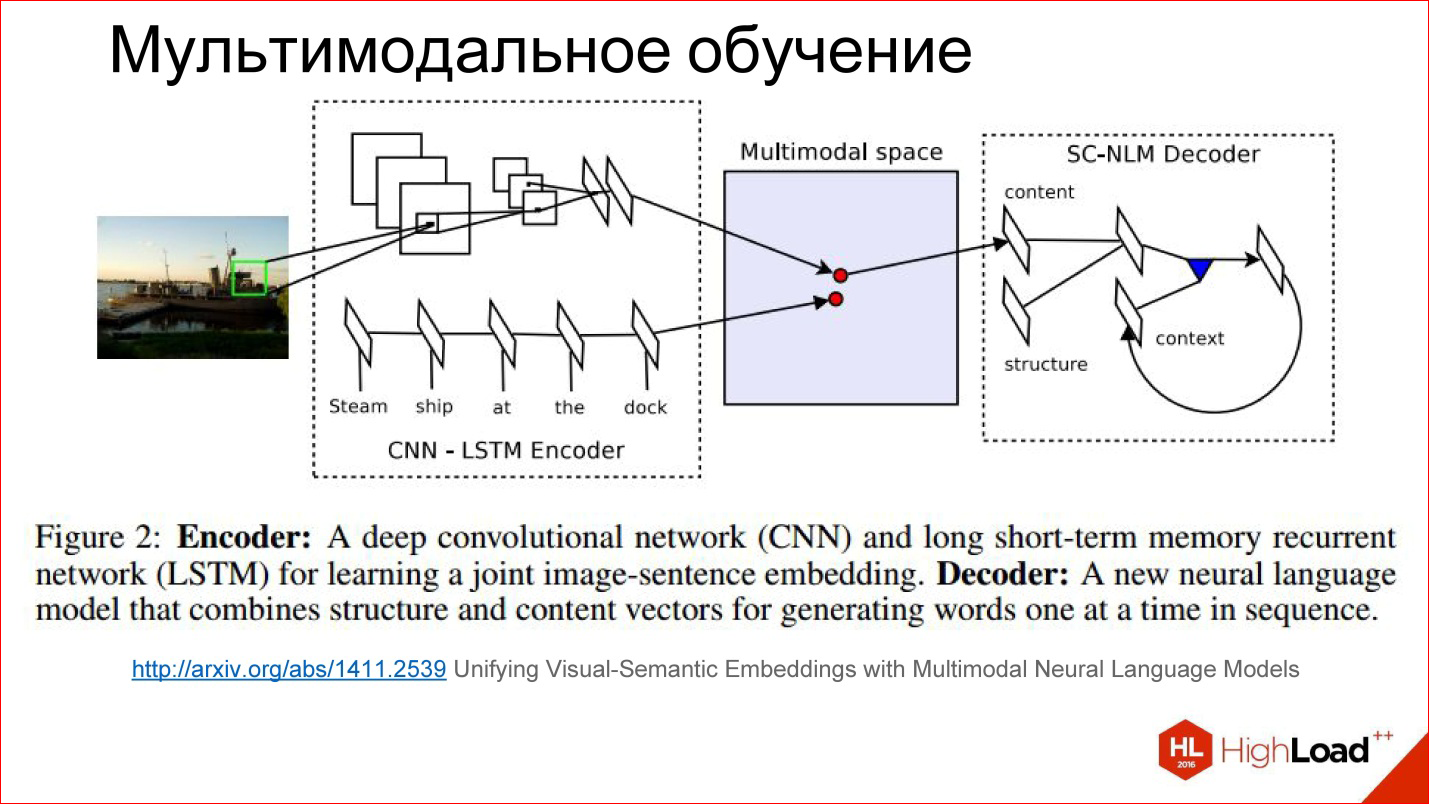
http://arxiv.org/abs/1411.2539
There is some tricky space that we don’t see at all, but it exists inside the neural network in the form of these weights, which it considers for itself. It turns out that in the learning process, we teach as if 2 different neural networks: convolutional and recurrent for the text that describes the picture and for the picture itself to generate vectors in this tricky space in one place. That is, to combine 2 modalities into one.
If we learned how to do this, then to a certain extent it doesn’t matter there: we submit a picture - we generate a text, we submit a text - we find a picture. You can play with different things and build interesting things.
By the way, there are already attempts to build networks that generate pictures in the text. It is interesting, it also works. Not very good yet, but the potential is huge.
Sequence Learning and the seq2seq paradigm
When to work with sequences of arbitrary lengths at the input and / or output
The second interesting topic is Sequence Learning or the seq2seq paradigm. I won’t even translate it. The idea is that a lot of your tasks come down to having sequences. That is, not just a picture that needs to be classified, give one number, but there is one sequence, and the output needs a different sequence.
For example, the translation is a classic task of Sequence 2 Sequence Learning: they set the text in English, you want to get it in French.
In fact, there are many such tasks. This is a picture description case.

http://karpathy.github.io/2015/05/21/rnn-effectiveness/
The usual neural networks that we examined - drove something, drove through the network, removed at the output - is not interesting.
There is an option called One to many. They drove the picture to the network, and then she went to work, work and generated a description of this picture. Wow.
It is possible in the opposite direction. For example, classification of texts. This is the favorite task of all marketers - to classify tweets - they are positive or negative in terms of emotional coloring. You drove your proposal into a recurrent neural network, and then at the end it gave out one number - yes, a positively colored tweet, no, a negatively colored tweet, or neutral, for example.
There is a story about translation. You drove a sequence in one language for a long time. Then the network worked and began to generate a sequence in another language. This is generally the most general setting.
There is another interesting setting when the inputs and outputs are synchronized. For example, if you want to annotate every frame of an image, is there something on it or not.
The figure shows all the options for Sequence 2 Sequence Learning, and this is a very powerful paradigm. It is powerful in that if everything inside the neural network is differentiable - and the neural networks that we discussed are completely differentiable inside, it means that you can train the neural network, so to speak, end-to-end: you have to send one sequence to the input, others to output and what’s going on inside doesn't matter to you at all. The neural network itself will cope - a bunch of examples in English are input, a bunch of examples in French is output, excellent, she herself will learn how to translate. And really with good quality, if you have a large database and good computing power to drive it all away.

Another insanely important thing that almost no one talks about, but without which Google Speech Recognition, Baidu, or Microsoft works, is CTC.
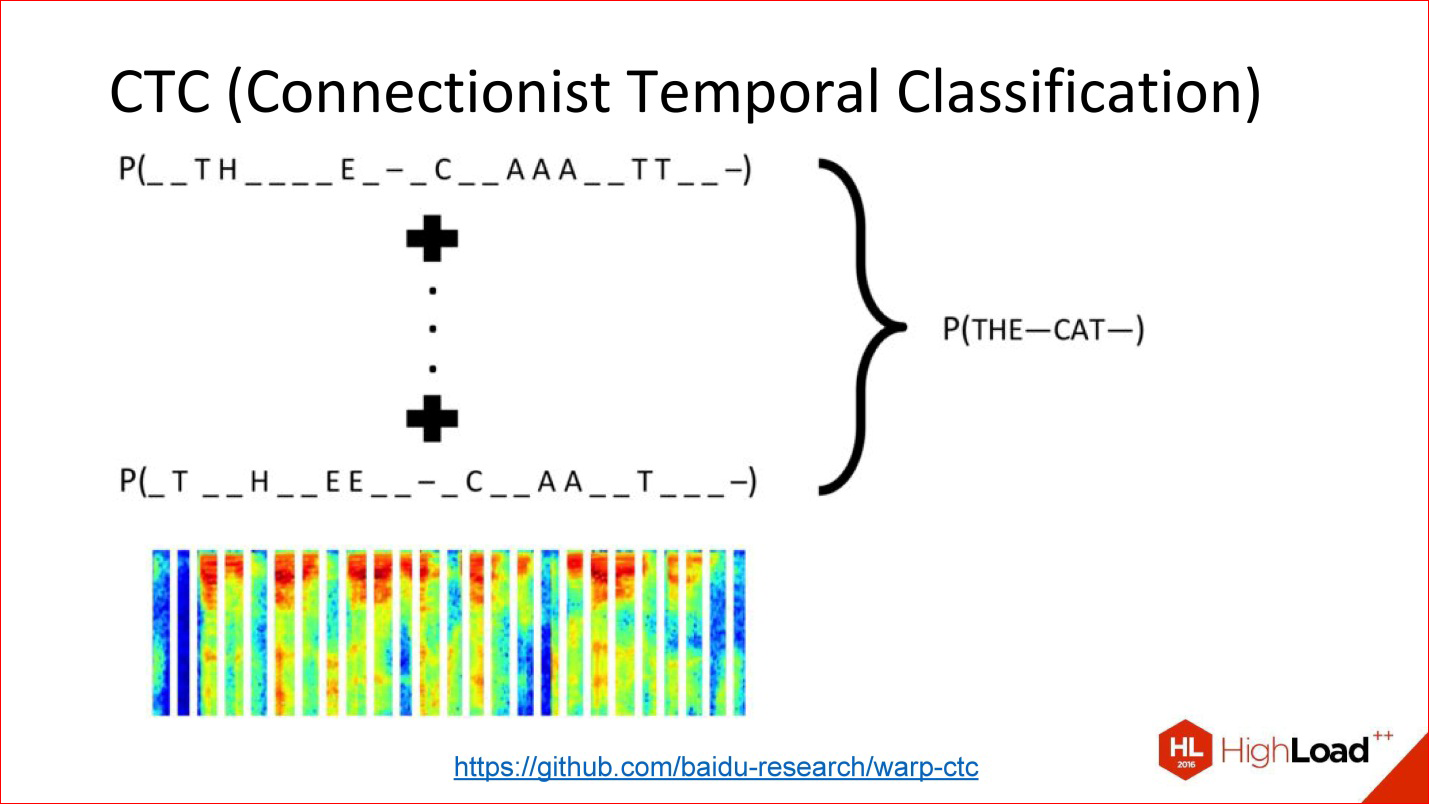
https://github.com/baidu-research/warp-ctc
CTC is such a tricky output layer. What is he doing? There are many tasks in which alignment within this sequence is not really important. There is a speech recognition task. You took a sound, cut it into short frames of 50 ms, for example, and then at the output you need to generate what word it was, a sequence of phonemes. By and large, it doesn't matter to you where in the original signal this or that phoneme was. Only the order between each other is important, in order to simply receive a word at the output.
The fact that you can throw out all the information about the exact position is actually a lot, which adds. For example, you do not need to have accurate phoneme marking for all sound frames, because getting such markup is insanely expensive. It is necessary to plant a man who will mark everything up.
You can just take everything and throw it away - there is input, there is a way out - what should happen in terms of the output sequence - a word, there is this tricky CTC layer that itself will do some kind of alignment inside itself, and this will, again, end- to-end to train such a cunning network for which you did not mark anything at all.
This is a powerful thing, it is also not implemented in all modern packages. But, for example, a year ago Baidu laid out its implementation of the CTC layer - that's great.
A few words about different architectures.
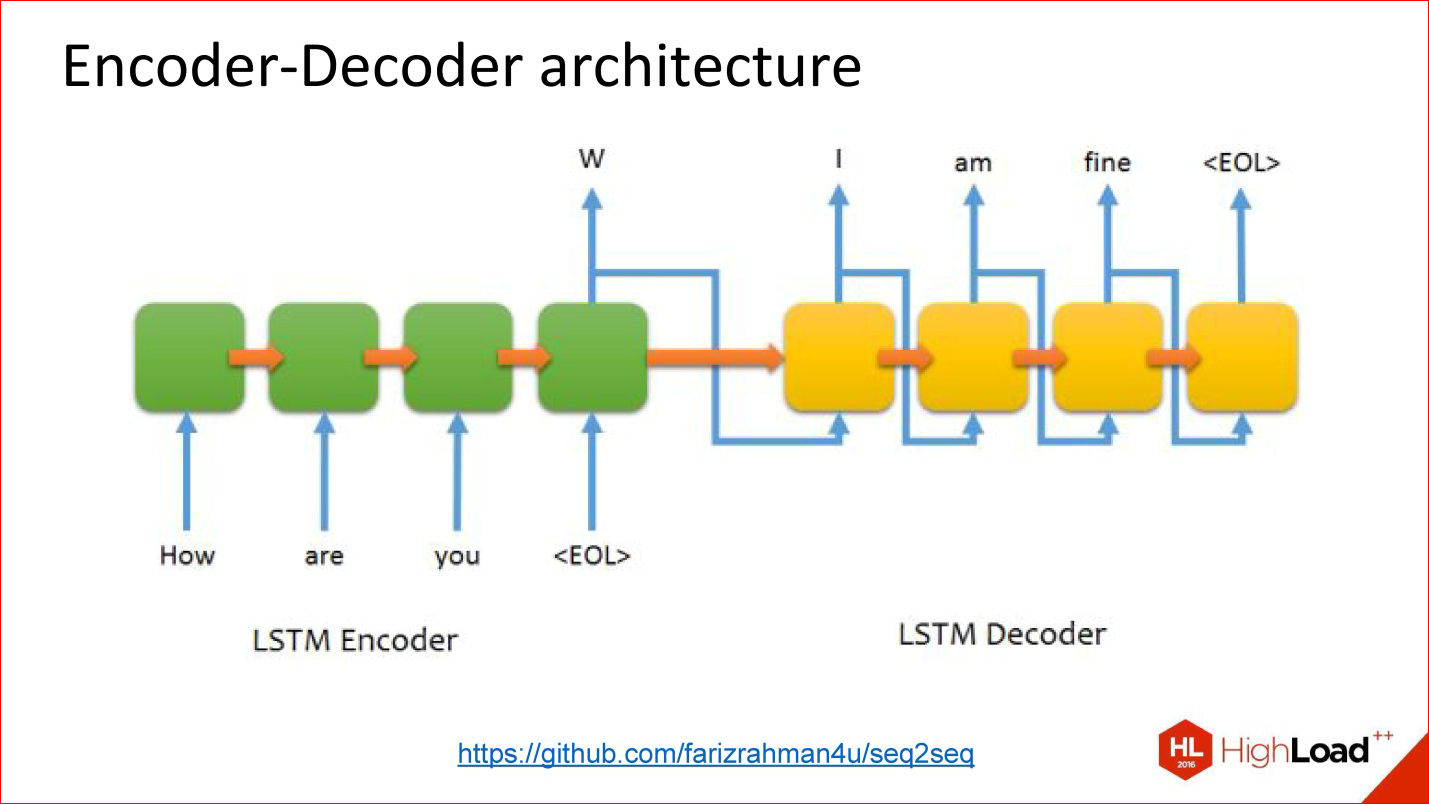
https://github.com/farizrahman4u/seq2seq
There is a classic Encoder-Decoder architecture. The translation example that I spoke about is almost entirely reduced to this architecture.
There is one input neural network, words are delivered into it. The output of this neural network is seemingly ignored until the end of sentence symbol is supplied. After that, the second network is included in the case, which reads the state of the first network and starts generating output words from it. Its results at the previous step are fed to the input.
It works. Many translation systems work like this.
But this architecture has one problem - the bottleneck too. The state vector (the size of the hidden layer) that is transmitted is limited and fixed. That is, it turns out that it is the same for a short sentence, and for an insanely long one - this is not very good. It may turn out that a long sentence does not fit into this volume.
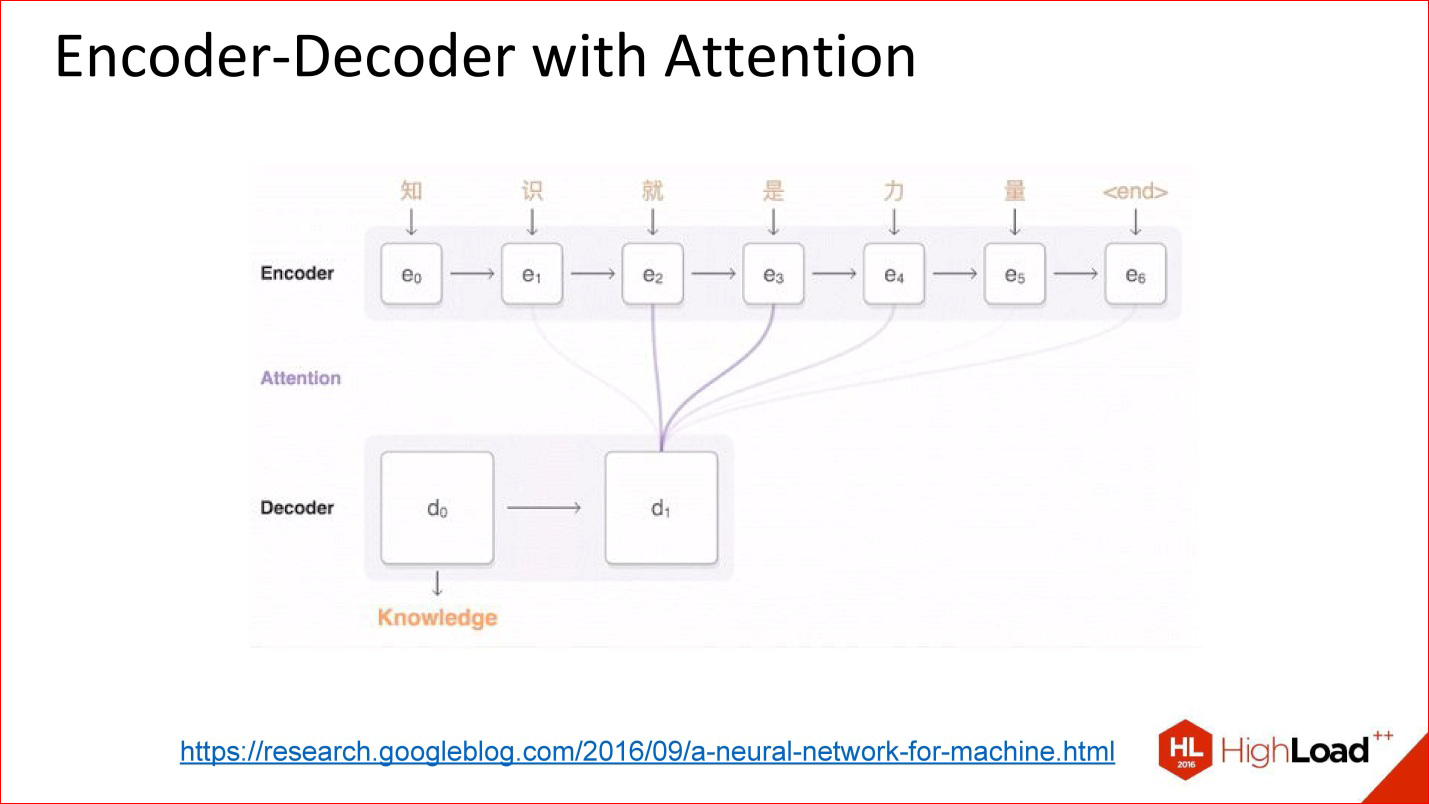
https://research.googleblog.com/2016/09/a-neural-network-for-machine.html
Architecture appeared, as they say, with attention.
Attention is such a tricky thing, which is actually, in fact, very simple. The idea is that now the neural network output decoder does not look at the output value of the previous neural network, but at all its intermediate states, but with some kind of balance. Weights are the coefficients of how much you need to take each of those states into the final large amount with which the decoder will work.
That is, attention is actually a simple linear combination of all the previous states of the encoder, which is also trained.
Neural networks with attention to the fact work very well. For translation and other complex tasks, they are very much superior in quality to neural networks without attention.

http://kelvinxu.github.io/projects/capgen.html
An additional bonus of such networks. The figure shows the combination of 2 different neural networks: a convolutional neural network from which we got some signs, then a recursive neural network generates text. If we implemented the concept of attention, set some pictures, then we can look at the generation of a specific word, which weights were large. This actually indicates which pixels of the image at a particular moment played a role in generating this particular word. That is, what the neural network seemed to pay attention to.
By the way, the concept of attention is far from being implemented in every library, that is, there are no ready-made box solutions. Sometimes you can find ready-made code that someone published as part of their work.

http://kelvinxu.github.io/projects/capgen.html
CNN + RNN with attention = beautiful pictures.
When a neural network generates text about the STOP sign, it really looks like that sign - its weight, its contribution to the generation of a specific STOP sign is very high, and all other pixels play little role.
This is an interesting concept, keep an eye on it too. It will also be used a lot.
Framework and libraries for working with neural networks
A very brief overview
In fact, you can talk about it for hours. I have no purpose to tell you - yes, use this library or this one - because this is not so. There are a huge number of libraries. I will give a more or less relevant list of different libraries.

Detailed list: http://deeplearning.net/software_links/
Universal libraries and services:
- Torch7 (http://torch.ch/) [Lua]
- TensorFlow (https://www.tensorflow.org/) [Python, C++]
- Theano (http://deeplearning.net/software/theano/) [Python]
- Keras (http://keras.io/)
- Lasagne (https://github.com/Lasagne/Lasagne)
- blocks (https://github.com/mila-udem/blocks)
- pylearn2 (https://github.com/lisa-lab/pylearn2)
- Microsoft Cognitive Toolkit (CNTK) (http://www.cntk.ai/) [Python, C++, C#, BrainScript]
- Neon (http://neon.nervanasys.com/) [Python]
- Deeplearning4j (http://deeplearning4j.org/) [Java]
- MXNet (http://mxnet.io/) [C++, Python, R, Scala, Julia, Matlab, Javascript]
- …
Firstly, there are universal libraries, about many of which you have heard.
For example, TensorFlow (Google) is probably one of the most popular, although quite recent. It can be used in Python and C ++.
There is a Torch library that actively supports Facebook at the moment. This is the Lua language. But don’t be scared, it’s actually a cool language. This library has a lot of what has been implemented, there are a lot of fresh research directly in the form of Lua code. It's great.
There is a Theano library - TensorFlow has now slightly replaced it, but many different cool high-level wrappers have been built around Theano - a neural network can be written in several lines. This is really great!
Some of these wrappers, such as Keras, can work with TensorFlow, like the backend, as they say. That is, TensorFlow is a rather low-level code in terms of neural networks, Keras is a high-level code, or a single-line layer is convenient.
Microsoft has published something, there is Neon, Deeplearning4j - a rare case - the Java library for Deeplearning. They are few in Java. Lots of Python and C ++. In other languages less.
In addition, there are special tools for video processing.
Image and video processing:
- OpenCV ( http://opencv.org/ ) [C, C ++, Python]
- Caffe ( http://caffe.berkeleyvision.org/ ) [C ++, Python, Matlab]
- Torch7 ( http://torch.ch/ ) [Lua]
- clarifai ( https://www.clarifai.com/ )
- Google Vision API ( https://cloud.google.com/vision/ )
- ...
I included OpenCV here. This is of course never a Deeplearning library, but it integrates well with other libraries.
Caffe is a great library, we used it in Production. This is a plus library, it is very fast, there is not much faster than it is. It is still cool, although those who are currently mastering neural networks, for some reason, think only of TensorFlow. But keep in mind that there are tons of other great solutions, including Caffe - a very cool thing.
In addition, there are a number of different APIs that you can use in WEB.
Speech recognition. It is actually getting worse.
Speech recognition:
- Microsoft Cognitive Toolkit (CNTK) (http://www.cntk.ai/) [Python, C++, C#, BrainScript]
- KALDI (http://kaldi-asr.org/) [C++]
- Google Speech API (https://cloud.google.com/)
- Yandex SpeechKit (https://tech.yandex.ru/speechkit/)
- Baidu Speech API (http://www.baidu.com/)
- wit.ai (https://wit.ai/)
- …
There is one cool KALDI library for speech recognition, it is a plus. But in general, speech recognition is more or less closed within large corporations because no one has a large Data Set about speech and sound. But there are a large number of APIs from Yandex, Google, Baidu, Microsoft, it seems, also has.
Word processing:
- Torch7 ( http://torch.ch/ ) [Lua]
- Theano / Keras / ... [Python]
- TensorFlow ( https://www.tensorflow.org/ ) [C ++, Python]
- Google Translate API ( https://cloud.google.com/translate/ )
- ...
For texts, there is nothing especially special, but all universal libraries are great. Take Keras (or any other, it doesn’t matter), write something in a few lines - you have a neural network ready to work with text. Or any other library - it doesn’t matter.
That's all, thanks. There is no universal answer to the question of which universal library to take. Look at your task. There are many subtleties - and what technology you have, what is embedded in it, and what ready-made code is already in nature - there are really a lot of codes that you can use at http://github.com/ . This is an engineering task that must be approached thoughtfully. There is no single universal answer and cannot be.
FAQ
Question : Can you advise some kind of literature for a beginner - what would be better to read, to see, in order to better understand how to program neural networks?
Answer : Here a lot depends on your current level, on how deeply you want to get an understanding. In fact, there are a huge number of blogs. First, forget about the Russian language - there is practically nothing on it. There are some translations on the Habré, but this is not serious against the background of the array that exists in nature.
In English there are a huge number of cool blogs where different examples are understood. There are a lot of them, just google it and find something on a specific topic. There are various tutorials, again in English, more or less small. There is an 800-page Deeplearning book, which is now available on paper at AMT-Press, and has been available in PDF for a long time.
In general, there is literature. There are some courses online, for example, at Coursera, there are attempts to launch the course offline. In particular, I will be participating in one of these courses soon.
In fact, there are quite a few different options. Look on the Internet - however, there are many opportunities. Most of them are still reading various foreign literature, but it is really good and comprehensive.
But at the same time, the code on GitHub is also good. A lot of code is published, which you can at least see. Often it can be read, it is not very scary. And often with this code there are some intelligible comments about how this all works. Just go to the Internet - there is a lot of everything there.
Question : What, in general, are approaches to training neural networks? Is it possible to just google a bunch of pictures from the Internet, or is it possible to take some neural networks that train other neural networks?
Answer : Yes, this is a cool question. In the training of neural networks, I think, in the coming years there will also be a lot of progress. There are different approaches. Firstly, yes - when you typed the Data Set and trained on it - this is a classic approach. He is, there is no getting away from him, he is basic in many cases.
But now, by the way, a different approach, called Transfer learning, often becomes the basic one. There are some published neural networks that are trained on different tasks - on the same ImageNet. You can take a ready-made ImageNet neural network for 1000 classes and retrain it for some of your special classes. This may turn out to be simpler because you have, say, only 1000 images of your classes, and you cannot train a good neural network from scratch on such a volume. In order to train a deep neural network, you really need a lot of data. It is about hundreds of thousands and millions of objects. But if you have a ready-made grid, you took it, trained it a little bit, and you already have a sane result. Transfer learning is a good approach. He works.
An option when other neural networks teach neural networks - there are also such options. They are more research than production. This is a very cool topic, it's great to follow. I don’t know any very good production solutions, but if you are interested in the scientific side, then yes, read directly, there are cool articles where a neural network-teacher, which contains a model of some kind of world, teaches another neural network, and it works .
Question : Are there tools in which you can modify existing neural network architectures or create, for example, your own?
Answer: Look, if you want a visual tool, then no rather than yes. Although there are some plugins on TensorFlow that render something there. But in general, this is actually not a very big problem because the neural network is often set in the form of some kind of structure, text file or code, it is not very difficult to change it, there you can add layers and program them. This is not even very programming, it is such a special DSL in fact. You took and added a couple of layers.
The most difficult thing in all these works is the dimension to observe between the layers. If you do not really understand how the tensors are arranged there, these multidimensional arrays, there is a chance to get confused with dimensions. This is the hardest part in all of this.
Question : You talked about a lot of different recurrent architectures
neural networks. And what exactly did you use and for what tasks
Answer : For most tasks, simple neural networks from the LSTM box work well, of sufficient depth and of sufficient size. There are many tasks of text classification, classification of anything in sequences. If you start with any of the LSTM networks, this is, in principle, a normal start. If you understand that bi-directionality is useful in this place, you are doing Bidirectional LSTM.
It would be great to start with all sorts of cool options with attention and so on, but it's just hard to start with them because they are hard to program from scratch. It’s not trivial after all. And there are not very many such good pieces of code that you take and use. For me, Base line so far is LSTM networks - unidirectional or bidirectional. I used them to classify texts and images (number recognition).
Question: I know that neural networks are used to crack cryptographic algorithms, for example, plaintext is input and encrypted text is the output. And then, in the opposite direction, the encrypted text is submitted, and the training simply receives open at the output. The question is - what progress is now in this area, does it really work, and what architectures can be used for this?
Answer: I cannot say much about this. I am not competent in this area, so to speak, competent. I do not work at the interface with such security of cryptography. I saw some fresh work by Google, where one neural network was taught to generate a code, and the other to crack. But it seems to me, nevertheless, these examples are far from good cryptographic algorithms. It seems to me that this is still research at the level of the series “It is interesting to see what comes of it.” I have not heard about cool work about breaking serious ciphers.
Этот доклад — расшифровка одного из лучших выступлений на конференции разработчиков высоконагруженных систем HighLoad++. До конференции HighLoad++ 2017 осталось меньше месяца.
У нас уже готова Программа конференции, сейчас активно формируется расписание.
В этом году продолжаем исследовать тему нейронных сетей:
- Определение атрибутов и визуальный поиск в UGC-фотографиях одежды / Дмитрий Соловьев
- Распознавание облаков и теней на спутниковых изображениях с использованием глубокого обучения / Анатолий Филин
- Нейронные сети: быстрый инференс на GPU с помощью TensorRT (демо) / Дмитрий Коробченко
- Обнаружение аномалий во временных рядах с помощью автоэнкодеров / Павел Филонов
- Face Recognition: From Scratch To Hatch / Eduard Tyantov
Also, some of these materials are used by us in an online training course on the development of highly loaded systems HighLoad. Guide is a chain of specially selected letters, articles, materials, videos. Already in our textbook more than 30 unique materials. Get connected!