How Discord Scaled Elixir to 5 Million Concurrent Users
- Transfer
From the very beginning, Discord has been actively using Elixir. The Erlang virtual machine was the ideal candidate for creating the highly parallel real-time system we were planning to create. The original Discord prototype was developed at Elixir; now it underlies our infrastructure. The mission and purpose of Elixir is simple: access the full power of Erlang VM through a much more modern and friendly language and toolkit.
Two years have passed. We now have five million concurrent users , and millions of events per second pass through the system. Although we absolutely do not regret the choice of architecture, we had to do a lot of research and experimentation to achieve this result. Elixir is a new ecosystem, and the Erlang ecosystem lacks information about its use in production (although Erlang in Anger is something). As a result of the whole journey, trying to adapt Elixir to work in Discord, we learned some lessons and created a number of libraries.
Although Discord has many features, it basically comes down to pub / sub. Users connect to the WebSocket and unwind the session (GenServer), which then establishes a connection with the remote Erlang nodes, where guild processes (also GenServer's) work. If something is published in guild (the internal naming convention is “Discord Server”), it will fan out for every connected session.
When a user goes online, he connects to guild, and he publishes the status of presence in all other connected sessions. There is a lot of other logic, but here is a simplified example:
This was a normal approach when we initially created Discord for groups of 25 or fewer users. However, we were fortunate enough to encounter the “good problems” of growth when people started using Discord in large groups . As a result, we came to the conclusion that on many Discord servers like / r / Overwatch there are up to 30,000 users at a time. At peak hours, we observed that these processes could not cope with message queues. At some point, I had to manually intervene and disable the message generation functions to help cope with the load. It was necessary to deal with the problem before it became widespread.
We started with benchmarksfor the busiest paths within the guild processes and soon revealed the obvious cause of the trouble. The exchange of messages between Erlang processes was not as efficient as it seemed to us, and the Erlang unit of work for process shedding was also very expensive. We found that the time of a single call
It was necessary to somehow distribute the work of sending messages. Since spawn processes in Erlang are cheap, our first idea was to simply spawn a new process to handle every post we publish. However, all publications could occur at different times, and Discord clients depend on the linearizability of events. Moreover, such a solution cannot be scaled well, because the guild service has become more and more work.
Inspired by a blog post about improving performance in messaging between nodes, we created Manifold . Manifold distributes the work of sending messages between remote nodes with PIDs (process identifier in Erlang). This ensures that the distribution processes will invoke
A wonderful side effect of Manifold was that we managed not only to distribute the CPU load of fan messages, but also to reduce network traffic between nodes:
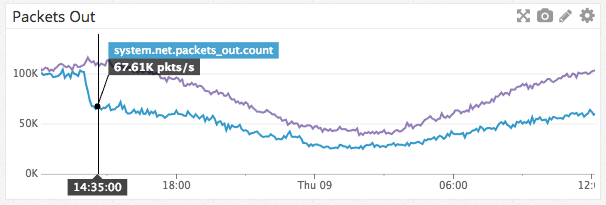
Reducing network traffic per node Guild
Manifold lies on GitHub , so try it.
Discord is a distributed system that uses consistent hashing . Using this method required the creation of a ring data structure that can be used to search for a node of a particular object. We wanted the system to work fast, so we chose the wonderful Chris Mus libraryby connecting it through the Erlang C port (the process responsible for the interface with the C code). It worked great, but as Discord scaled up, we began to notice problems during outbursts with reconnecting users. The Erlang process, which is responsible for managing the ring, began to be so loaded with work that it could not cope with requests for the ring, and the whole system could not cope with the load. The solution at first glance seemed obvious: to start many processes with ring data for the best use of all the cores of the machine to process all requests. But this is too important a task. Is there a better option?

Let's look at the components.
If the session server crashed and rebooted, it took about 30 seconds to simply search the ring. This is not even counting the despatching on the part of Erlang of one process involved in the work of other ring processes. Can we completely eliminate these costs?
When working with Elixir, if you need to speed up access to data, the first thing to do is to use ETS . This is a fast, mutable C dictionary; the flip side of the coin is that the data is copied there and read from there. We could not just transfer our ring to ETS, because we used port C to control the ring, so we rewrote the code on a pure Elixir. Once this was finished, we had a process that owned the ring and continuously copied it to the ETS, so that other processes could read data directly from the ETS. This markedly improved performance, but the ETS read operations took about 7 μs and we still spent 17.5 seconds on the value search operations in the ring. The data structure of the ring is actually quite large, and copying it to the ETS and reading from there took up most of the time. We were disappointed; in any other programming language, one could simply make a general meaning for safe reading. There must be some way to do this on Erlang!
After some research, we found the mochiglobal modulethat uses the function of a virtual machine: if Erlang encounters a function that constantly returns the same data, it places this data in a read-only heap with shared access to which processes have access. Copying is not required. mochiglobal uses this by creating an Erlang module with one function and compiling it. Since the data is not copied anywhere, search costs decreased to 0.3 μs, which reduced the total time to 750 ms! However, there is no complete freebie; the creation of a module with a data structure of this size in runtime can take up to a second. The good news is that we rarely change the ring, so we are willing to pay that price.
We decided to port mochiglobal to Elixir and add some functionality to avoid atomization. Our version is calledFastGlobal .
After solving an important problem with node search performance, we noticed that the processes responsible for processing the search
It was necessary to make session processes smarter; ideally, they should not even try to make these calls to the guild registry if an unsuccessful outcome is inevitable. We did not want to use a circuit breaker so that there would not be a situation where a surge in timeouts leads to a temporary state, when no attempts are made at all. We knew how to implement this in other languages, but how to do it in Elixir?
In most other languages, we could use an atomic counter to track outgoing requests and early warning if their number is too large, effectively implementing a semaphore. Erlang VM is built on coordination between processes, but we did not want to load the process responsible for this coordination too much. After some research, we came across
This library helped protect our infrastructure at Elixir. Just as last week, a situation similar to the aforementioned cascading outages occurred, but this time there were no outages. Our presence services failed for another reason, but the session services did not even budge, and the presence services were able to recover a few minutes after a reboot:
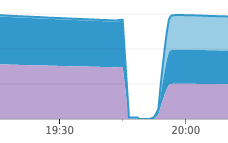
Presence services
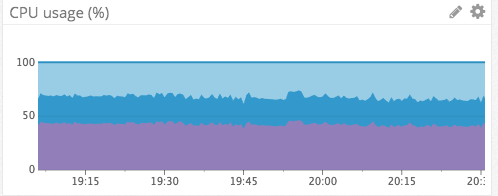
use CPU session services for the same period
You can find our Semaphore library on GitHub .
Choosing and working with Erlang and Elixir proved to be a great experience. If we were forced to come back and start over, we would definitely choose the same path. We hope that the story about our experience and tools will be useful to other developers Elixir and Erlang, and we hope to continue to talk about our work, solving problems and gaining experience during this work.
Two years have passed. We now have five million concurrent users , and millions of events per second pass through the system. Although we absolutely do not regret the choice of architecture, we had to do a lot of research and experimentation to achieve this result. Elixir is a new ecosystem, and the Erlang ecosystem lacks information about its use in production (although Erlang in Anger is something). As a result of the whole journey, trying to adapt Elixir to work in Discord, we learned some lessons and created a number of libraries.
Fan Deployment of Messages
Although Discord has many features, it basically comes down to pub / sub. Users connect to the WebSocket and unwind the session (GenServer), which then establishes a connection with the remote Erlang nodes, where guild processes (also GenServer's) work. If something is published in guild (the internal naming convention is “Discord Server”), it will fan out for every connected session.
When a user goes online, he connects to guild, and he publishes the status of presence in all other connected sessions. There is a lot of other logic, but here is a simplified example:
def handle_call({:publish, message}, _from, %{sessions: sessions}=state) do
Enum.each(sessions, &send(&1.pid, message))
{:reply, :ok, state}
endThis was a normal approach when we initially created Discord for groups of 25 or fewer users. However, we were fortunate enough to encounter the “good problems” of growth when people started using Discord in large groups . As a result, we came to the conclusion that on many Discord servers like / r / Overwatch there are up to 30,000 users at a time. At peak hours, we observed that these processes could not cope with message queues. At some point, I had to manually intervene and disable the message generation functions to help cope with the load. It was necessary to deal with the problem before it became widespread.
We started with benchmarksfor the busiest paths within the guild processes and soon revealed the obvious cause of the trouble. The exchange of messages between Erlang processes was not as efficient as it seemed to us, and the Erlang unit of work for process shedding was also very expensive. We found that the time of a single call
send/2can vary from 30 μs to 70 μs due to the de-scheduling of the Erlang call process. This meant that during peak hours, publishing one event from a large guild could take from 900 ms to 2.1 s! Erlang processes are completely single-threaded, and shards seemed to be the only parallelization option. Such an event would require considerable effort, and we knew that there would be a better option.It was necessary to somehow distribute the work of sending messages. Since spawn processes in Erlang are cheap, our first idea was to simply spawn a new process to handle every post we publish. However, all publications could occur at different times, and Discord clients depend on the linearizability of events. Moreover, such a solution cannot be scaled well, because the guild service has become more and more work.
Inspired by a blog post about improving performance in messaging between nodes, we created Manifold . Manifold distributes the work of sending messages between remote nodes with PIDs (process identifier in Erlang). This ensures that the distribution processes will invoke
send/2maximum as many times as remote nodes involved. Manifold does this by first grouping the PIDs by their remote nodes, and then sending them to the “separator” Manifold.Partitioneron each of these nodes. Then the separator sequentially hashes the PIDs, using it :erlang.phash2/2, groups them by the number of cores and sends them to the child workers. In the end, workers send messages to real processes. This ensures that the separator is not overloaded and continues to provide linearizability like send/2. This solution has become an effective replacement send/2:Manifold.send([self(), self()], :hello)A wonderful side effect of Manifold was that we managed not only to distribute the CPU load of fan messages, but also to reduce network traffic between nodes:
Reducing network traffic per node Guild
Manifold lies on GitHub , so try it.
General quick access data
Discord is a distributed system that uses consistent hashing . Using this method required the creation of a ring data structure that can be used to search for a node of a particular object. We wanted the system to work fast, so we chose the wonderful Chris Mus libraryby connecting it through the Erlang C port (the process responsible for the interface with the C code). It worked great, but as Discord scaled up, we began to notice problems during outbursts with reconnecting users. The Erlang process, which is responsible for managing the ring, began to be so loaded with work that it could not cope with requests for the ring, and the whole system could not cope with the load. The solution at first glance seemed obvious: to start many processes with ring data for the best use of all the cores of the machine to process all requests. But this is too important a task. Is there a better option?
Let's look at the components.
- The user can be in any number of guilds, but the average is 5.
- The Erlang VM session manager can support up to 500,000 sessions.
- When connecting a session, she needs to find a remote node for each guild that she is interested in.
- The communication time with another Erlang process using request / reply is about 12 microseconds.
If the session server crashed and rebooted, it took about 30 seconds to simply search the ring. This is not even counting the despatching on the part of Erlang of one process involved in the work of other ring processes. Can we completely eliminate these costs?
When working with Elixir, if you need to speed up access to data, the first thing to do is to use ETS . This is a fast, mutable C dictionary; the flip side of the coin is that the data is copied there and read from there. We could not just transfer our ring to ETS, because we used port C to control the ring, so we rewrote the code on a pure Elixir. Once this was finished, we had a process that owned the ring and continuously copied it to the ETS, so that other processes could read data directly from the ETS. This markedly improved performance, but the ETS read operations took about 7 μs and we still spent 17.5 seconds on the value search operations in the ring. The data structure of the ring is actually quite large, and copying it to the ETS and reading from there took up most of the time. We were disappointed; in any other programming language, one could simply make a general meaning for safe reading. There must be some way to do this on Erlang!
After some research, we found the mochiglobal modulethat uses the function of a virtual machine: if Erlang encounters a function that constantly returns the same data, it places this data in a read-only heap with shared access to which processes have access. Copying is not required. mochiglobal uses this by creating an Erlang module with one function and compiling it. Since the data is not copied anywhere, search costs decreased to 0.3 μs, which reduced the total time to 750 ms! However, there is no complete freebie; the creation of a module with a data structure of this size in runtime can take up to a second. The good news is that we rarely change the ring, so we are willing to pay that price.
We decided to port mochiglobal to Elixir and add some functionality to avoid atomization. Our version is calledFastGlobal .
Limited concurrency
After solving an important problem with node search performance, we noticed that the processes responsible for processing the search
guild_pidin guild nodes began to back up. A slow search for nodes used to protect them. The new problem was that about 5,000,000 session processes tried to push ten of these processes (one on each guild node). Here, speeding up the processing did not solve the problem; the fundamental reason was that session processes accessing this registry of guilds fell out in timeout and left a request in the queue for the registry. After some time, the request was repeated, but constantly accumulated requests turned into an unrecoverable state. Receiving messages from other services, the sessions would block these requests until they time out, which led to the bloating of the message queue and, as a result, to the OOM of the entire Erlang VM, resulting in cascading outages .It was necessary to make session processes smarter; ideally, they should not even try to make these calls to the guild registry if an unsuccessful outcome is inevitable. We did not want to use a circuit breaker so that there would not be a situation where a surge in timeouts leads to a temporary state, when no attempts are made at all. We knew how to implement this in other languages, but how to do it in Elixir?
In most other languages, we could use an atomic counter to track outgoing requests and early warning if their number is too large, effectively implementing a semaphore. Erlang VM is built on coordination between processes, but we did not want to load the process responsible for this coordination too much. After some research, we came across
:ets.update_counter/4, which performs atomic operations with incremental conditions on a number that is in the ETS key. Since good parallelization was needed, it was possible to run ETS in mode write_concurrency, but still read the value as it :ets.update_counter/4returns the result. This gave us the fundamental foundation for creating the Semaphore library . It is extremely easy to use, and it works very well with high bandwidth:semaphore_name = :my_sempahore
semaphore_max = 10
case Semaphore.call(semaphore_name, semaphore_max, fn -> :ok end) do
:ok ->
IO.puts "success"
{:error, :max} ->
IO.puts "too many callers"
endThis library helped protect our infrastructure at Elixir. Just as last week, a situation similar to the aforementioned cascading outages occurred, but this time there were no outages. Our presence services failed for another reason, but the session services did not even budge, and the presence services were able to recover a few minutes after a reboot:
Presence services
use CPU session services for the same period
You can find our Semaphore library on GitHub .
Conclusion
Choosing and working with Erlang and Elixir proved to be a great experience. If we were forced to come back and start over, we would definitely choose the same path. We hope that the story about our experience and tools will be useful to other developers Elixir and Erlang, and we hope to continue to talk about our work, solving problems and gaining experience during this work.