Finding the best place in the world for a windmill
The story of how NASA, ESA, Danish Technological University, neural networks, decision trees and other good people helped me find the best free hectare in the Far East, as well as in Africa, South America and other “so-so” places.
It seems that two years ago, or maybe already three, they announced a program for distributing free hectares in the Russian Far East . Looking quickly at the map, it became clear that just choosing the right hectare wasn’t so easy, and the best and most obvious places near cities would probably go away or were already left to the locals. Probably, it was at that moment that I had the idea that it was possible to somehow automate the search for the best place.
Starting to romantically think further, I thought that it was not necessary to look at the Far East. Now there is a lot of land that nobody needs anywhere, but that can change, 50 years from now, when fossil fuels begin to come to an end. And people will go look for new sources of energy. Then I began to look at renewable energy sources. And he quickly realized that the map of resources and territories where this new energy could be extracted would change dramatically. Having found such places now, you can purchase them in advance and be rich later.Having estimated still, it seemed to me that in a couple of days off it can be easily done ... Now, looking back, I understand that it took me about a year. I want to immediately note that at that time I was not very versed in energy, or in renewable sources, or in machine learning. Below is a brief retelling of my one-year project.
Having decided on the idea, I quickly went to see what renewable energy sources are generally and which one is the most energetic. Here is an incomplete but most common list:
But how to determine which one is the best and will defeat everyone else in the future? After reading some more interesting articles from the journals “Science and Life” and “Young Technician”. I went to the LCOE (levelized cost of electricity) methodology , which has a simple principle: smart guys are trying to estimate the total cost of a kilowatt hour of energy, taking into account production, materials, maintenance, etc. Below is a picture based on data from 2016 with some projection on 2022. I took a picture fresher from here , below is a boring plate from this document.

In general, I have such pictures for different countries made by different organizations and everything looks about the same:
I did not like the geothermal and hydro, because in my opinion, the places where it would be possible to extract this energy can be counted on the fingers. Wind and the sun is another matter, since you can put them on almost every roof and balcony. The sun turned out to be more expensive, and three years ago the difference was 30 percent more; I chose Wind.
By the way, already in the middle of the project, I began to come across documents with similar thoughts of the US state, namely NREL organizations, the US Department of Energy and others that made forecasts and bets on different energy sources in order to understand now how to modernize the energy system countries. For example, in one of these documents it all came down to several options: the share of wind energy will be large or very large.
The idea of how to crank this up was quite simple and looked like this:
In graphical form, this plan, as it turned out later, looked like this famous picture:

The first stage was quite easy. I just uploaded all the point records from OpenStreetMaps.
By the way, I want to note that OSM is just a storehouse of information about objects around the world with their coordinates, there is almost everything. Therefore, note to data lovers, OSM is the coolest Big Data source.
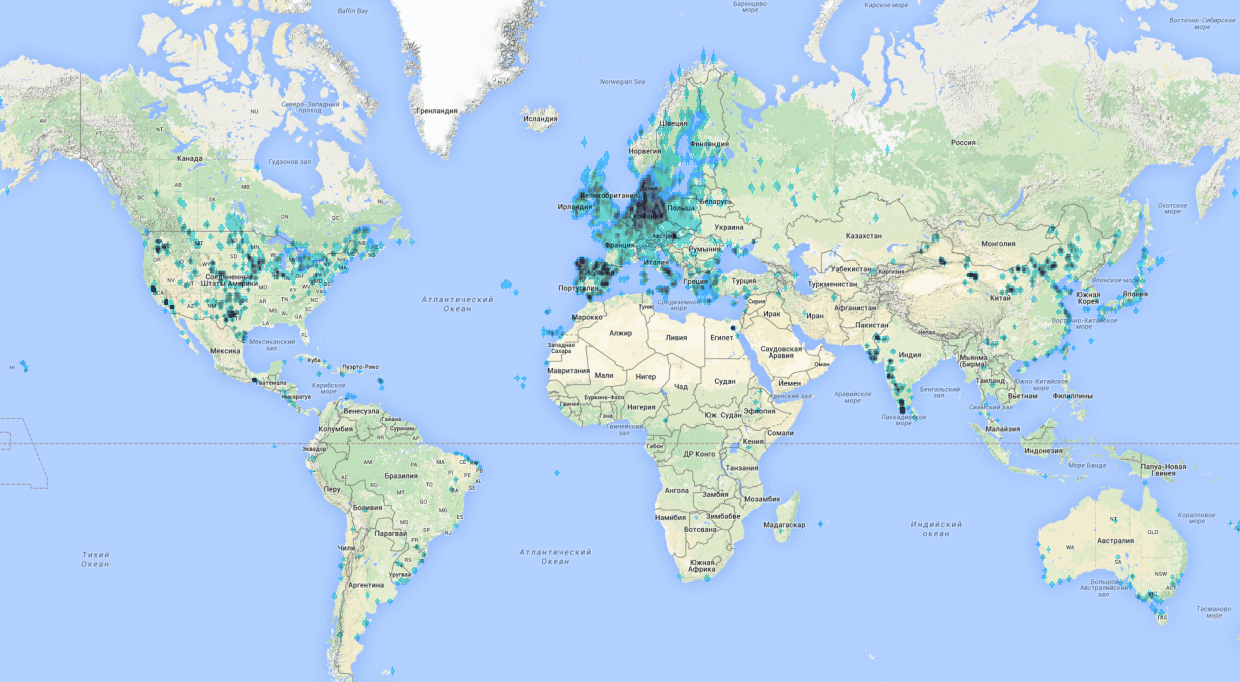
It wasn’t very difficult to do. At first I tried using online utilities, it seems overpass-turbo.eu, by the way, is a very cool thing, but it didn’t work out due to limitations on the number of points and not very fast work on a lot of data. Therefore, I had to deal with utilities that downloaded data from the OSM data cast locally. You can always download the current cast here? In compressed form, it takes about 40GB. Data can be downloaded from it using the Osmosis utility . As a result, I had a date set for 140 thousand points around the world with coordinates and heatmap. It looked something like this:
All problems began in the second stage , since I did not really understand what information needed to be collected. Therefore, for a couple of days I went into reading the principles of operation of windmills and recommendations for their placement, restrictions, etc. Even in the notes I have left here such amusing schemes about placement, wind gradients, wind roses and other other useful terms.

As a result, I got the following list of parameters, which, in my opinion, are important when choosing a place:
WIND . Actually, as 90% of all big data projects break down at the stage of “so now let's look at your data about which you talked so much”, mine also cracked. Having run to look for data on wind speed in Russia, I came across this:

And with a dozen similar and useless pictures. Then I began to guess that it is possible in Russia and there really is no wind energy, since we simply do not blow the wind in sufficient strength and somewhere at that moment Sechin's laughter was heard. But I clearly remember that in the Samara region there are only steppes and very often going out for bread as a child I was blown back to the porch.
Having started looking for data on Russia and what, I realized that it was not like the data with which you could do something useful. Therefore, I moved to foreign sources and immediately found beautiful wind maps from Tier3 (Vaisala). In appearance, the resolution was sufficient and the coverage of the whole world was simply excellent. Then I realized that such data cost good money about ~ $ 1000 per 10 square km (data from three years ago). Failure, I thought.
After a sad week, I decided to write Vaisala, Tier3 and other consulting foreign agencies working with winds and other wind generators, and ask for data. I thought that after telling what a cool idea I was going to do, everyone would immediately download everything to me .. Only one answered - from the Sander-Partner company. Sander himself gave some advice, and also gave links to what I need: data from the MERRA programled by NASA. It is worth noting that it took me about a week in the evenings to figure out what Reanalysis, WRF is and roughly understand what is happening at all: collecting, aggregating, simulating and predicting weather, winds and other things.
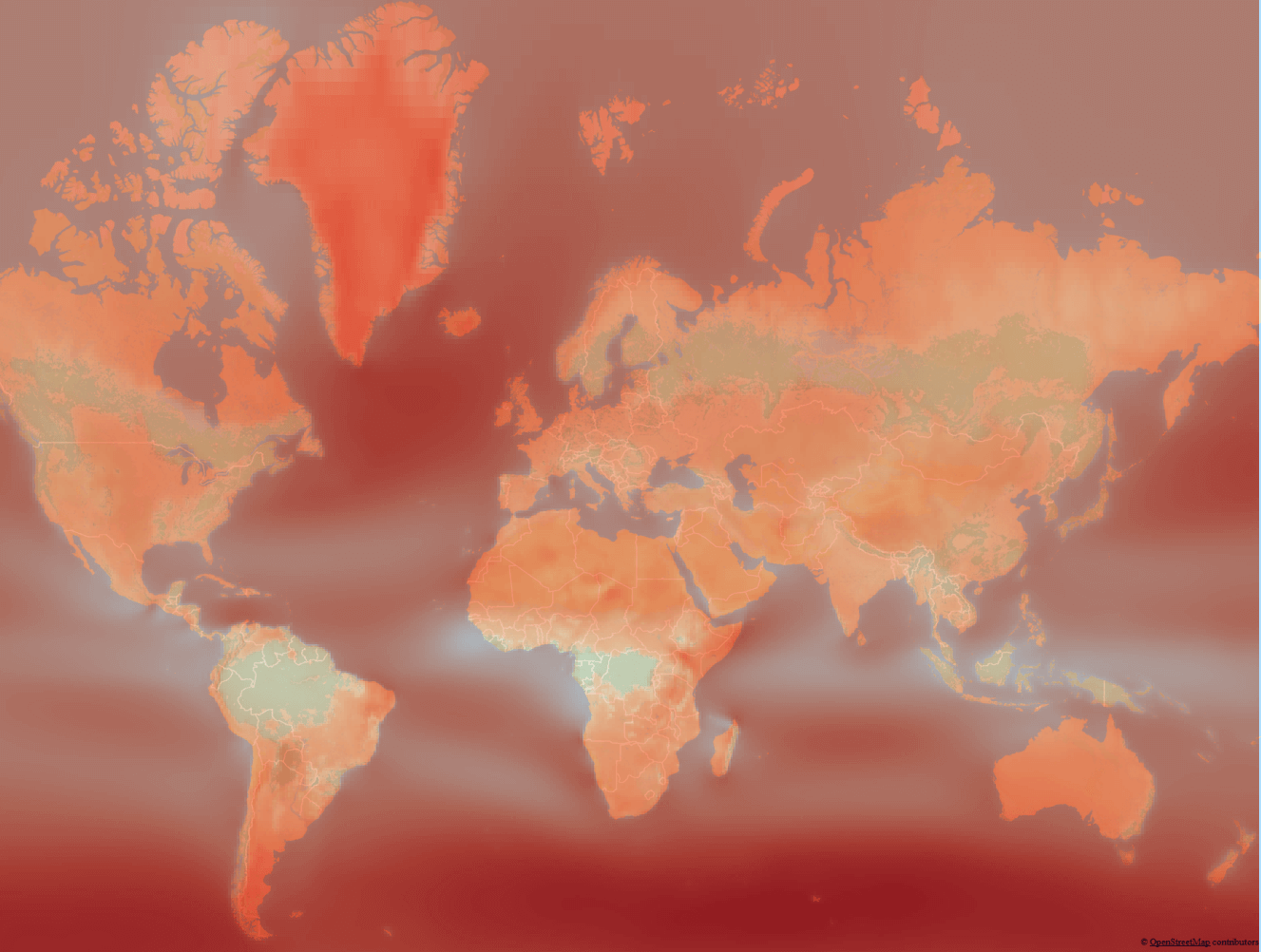
In short, mankind has collected a bunch of weather data, a bunch of maps with average temperatures and wind speeds have been drawn, but it was still impossible to collect all this data at every point on the globe, so white spots were filled with weather simulation results for past years and called it Reanalysis . For example, here is a site with the visualization of such wind simulations, but here is how it looks:

This data was essentially a .csv grid file with an average wind speed with a large step, I made such a map using the coolest free QGIS package and the data grid interpolation method.
And then with the help of it he pulled out data on the wind speed from each pair of coordinates from this map. In fact, I got a map, and a data layer for each pixel on it.
Having understood the principle of working with QGIS in about a couple of weeks, I began to build the same maps for the rest of the data sources and pull out the values by coordinates. For temperature, humidity, pressure and other things. Here it should be noted that the data arrays themselves were mainly taken from NASA, NOAA, ESA, WorldClimetc. All of them are in the public domain. With the help of QGIS, I made calculations and searched for the distance to the nearest points, from cities, airports and other infrastructure facilities. Each card, according to one parameter, was considered to be about 6-8 hours for me. And if something was wrong, you had to do it again and again. My home computer rustled at night for about a couple of weeks, but after that even the neighbors got tired of listening to the loose cooler on it and I crawled into the cloud, where I picked up a small virtual machine for calculation.
After several months I came across this site,made by the Danish Department of Wind Energy (DTU Wind Energy). It quickly became clear that their permission was many times better than my card, I wrote to them and they gladly uploaded data to me all over the world, since only small impressions can be obtained through the site. By the way, they also made this map using a simulation of the movement of the wind layers by the WRF, WAsP models and achieved a data resolution of up to 50-100 meters, as I had about 1-10km.
RELIEF. Remember, I wrote that the terrain is very important, so I decided to use this parameter in the same way, but it turned out to be not easy either. First I wrote a utility that downloaded data from the Google Elevation API. She did a great job and downloaded the data on all my points of the whole world with a step of 10 km, it took only about 12 hours of work. But I also had the parameters of the smoothness of the relief or the average value of the difference in the territory around the potential location of the windmill. That is, I needed data with increments of meters in 100-200 of the whole world, with the help of which I could already calculate the average value of the difference.

In order to calculate the differences, it would take a couple of months to download data from Google Elevation. So I went looking for other options.
The first thing I found was Wolfram cloud , which already had the necessary data. Just by writing a formula, this thing began to count, using data from the Wolfram cloud. But there, too, a failure was waiting for me, since I came across some kind of limits that were not indicated anywhere and after receiving a funny correspondence with the support of this service, I went to look for another option.
Then NASA data sources and data from the STRM (NASA Shuttle Radar Topography Mission Global) space program helped me again. I honestly tried to pump them out of the site, but there the data was only for small territories. Having the courage, I wrote a letter to NASA and after about a week of correspondence, they uploaded the necessary data to me, for which many thanks to them. The truth is, the data turned out to be in some tricky satellite binary format, which I probably raked for a week.
Everything ended well, and I calculated the necessary elevation metrics for the whole world with a step of 10 km. By the way, by the way, I made my own API service, which returns the altitude by coordinates and published it herealgorithmia.com/algorithms/Gaploid/Elevation. It works on Azure Tables, where I cunningly fit the data and store it there literally for the centers. By the way, even someone bought access to the API a couple of times, since it is cheaper than from Google.
TOTAL . After spending about 4 months searching, cleaning, and calculating in QGIS, I got a data set data that I could use in machine learning models. And which contained about 20 different parameters in the following categories: Climate, Relief, Infrastructure, Necessity or Consumers.
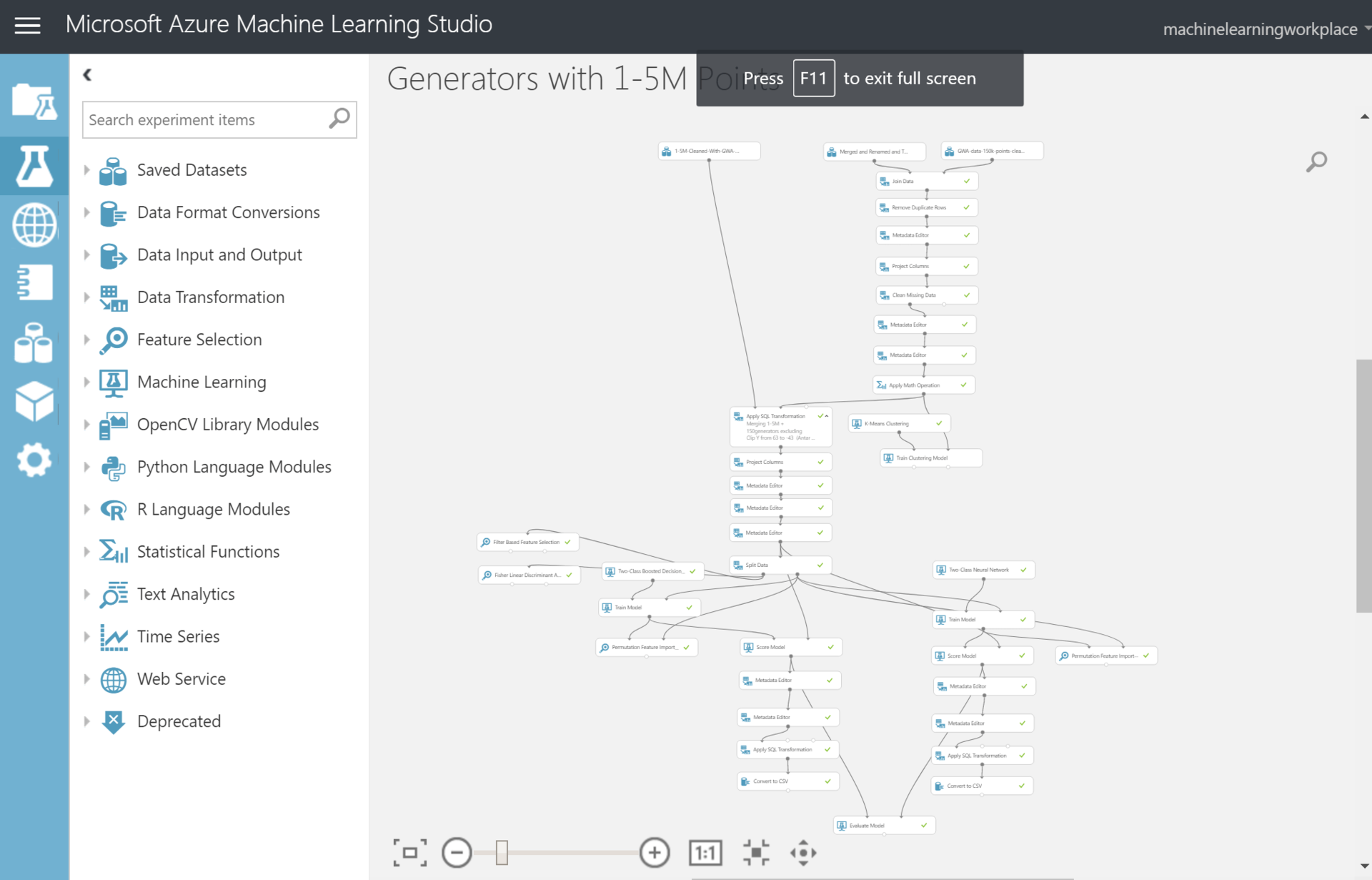
At that time, I already had some knowledge and understanding of how machine learning algorithms work, but I didn’t really want to deploy all these Python and Anaconda. Therefore, I used the online service for dummies without SMS from Microsoft Azure ML Studio. Bribed that it is free and everything can be done with the mouse in the browser. Here, in theory, there should be a description of how I spent another month on creating a model, clustering data and other things. All these clustering was especially difficult because QGIS did them for a very long time on my old home PC. As a result, the experiment looks like this.
The total number of points that needed to be estimated was about 1.5 million . Each such point is a territory of 10 by 10 km and so the whole world. I removed the cells that already have windmills within a radius of 100 km, as well as some areas, and received a set date of ~ 1,500,000 records. The model assessed the suitability of each such square on planet Earth . I used mainly neural networks and boosted decision trees. Accuracy at those points where windmills are already standing and what my model predicted came out like this: Accuracy - ~ 0.9; Precision - ~ 0.9 . What, it seems to me, is pretty accurate, well, or somewhere, retraining took place. From this exercise, I got:
In total, I found about 30,000 of the most suitable places (these are new places where there are no windmills nearby at a distance of 100 km).
Having received 30,000 points with new locations, I visualized them and it looks like a heatmap.

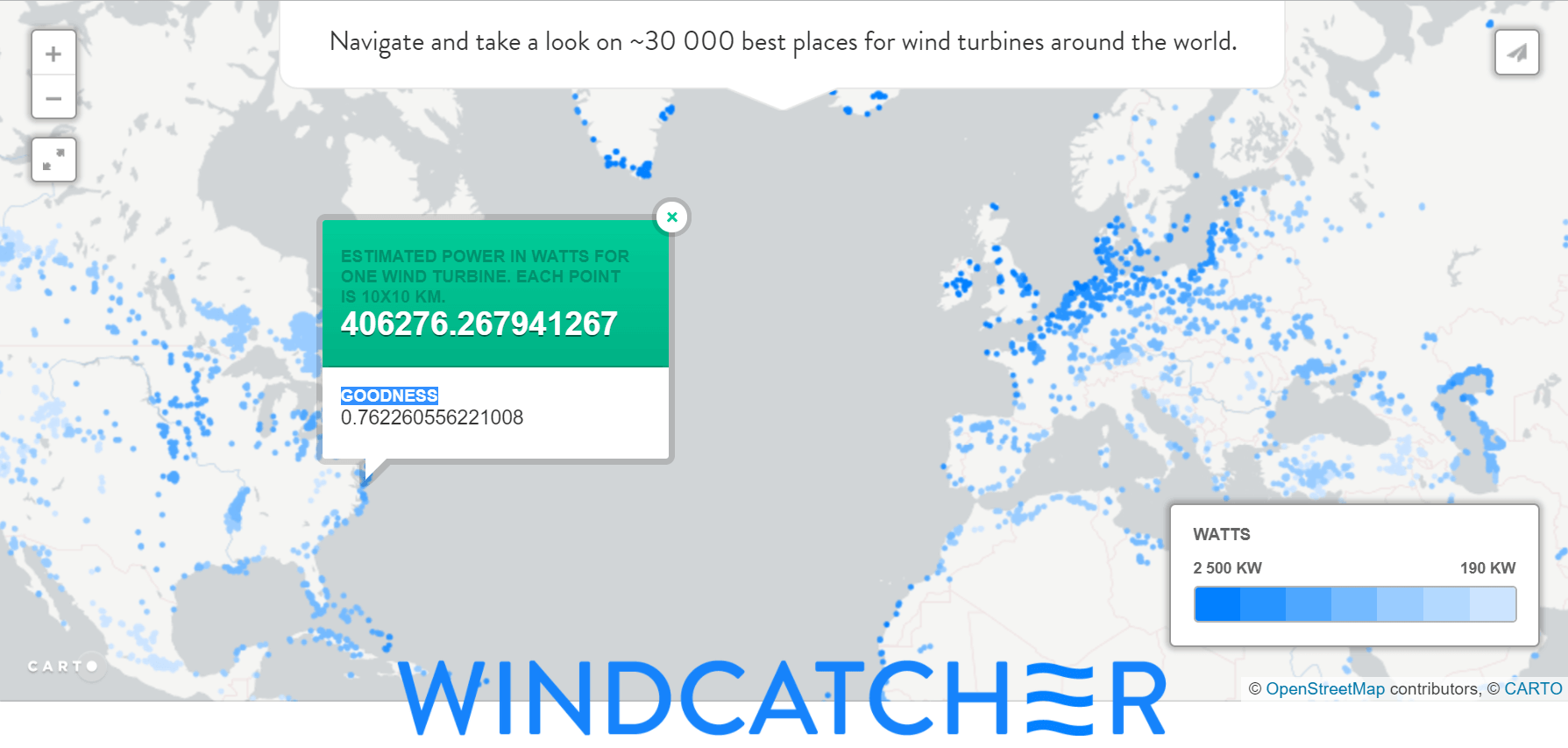
I made a small website using cartodb to render the map and uploaded the whole world map - windcat.ch . I also calculated for each point the approximate energy production from one industrial-sized windmill (50 m). The points here are colored according to the volume of energy, and not according to the Probability estimate from the model. You can click on each point and there the “confidence” of the model at that point will appear, I called it Goodness.
I also tried to verify the veracity of all this expertly.
Visual inspection: the model predicts points that creep along the shore, which seems to be true, since there will be a good even wind with a smooth surface.
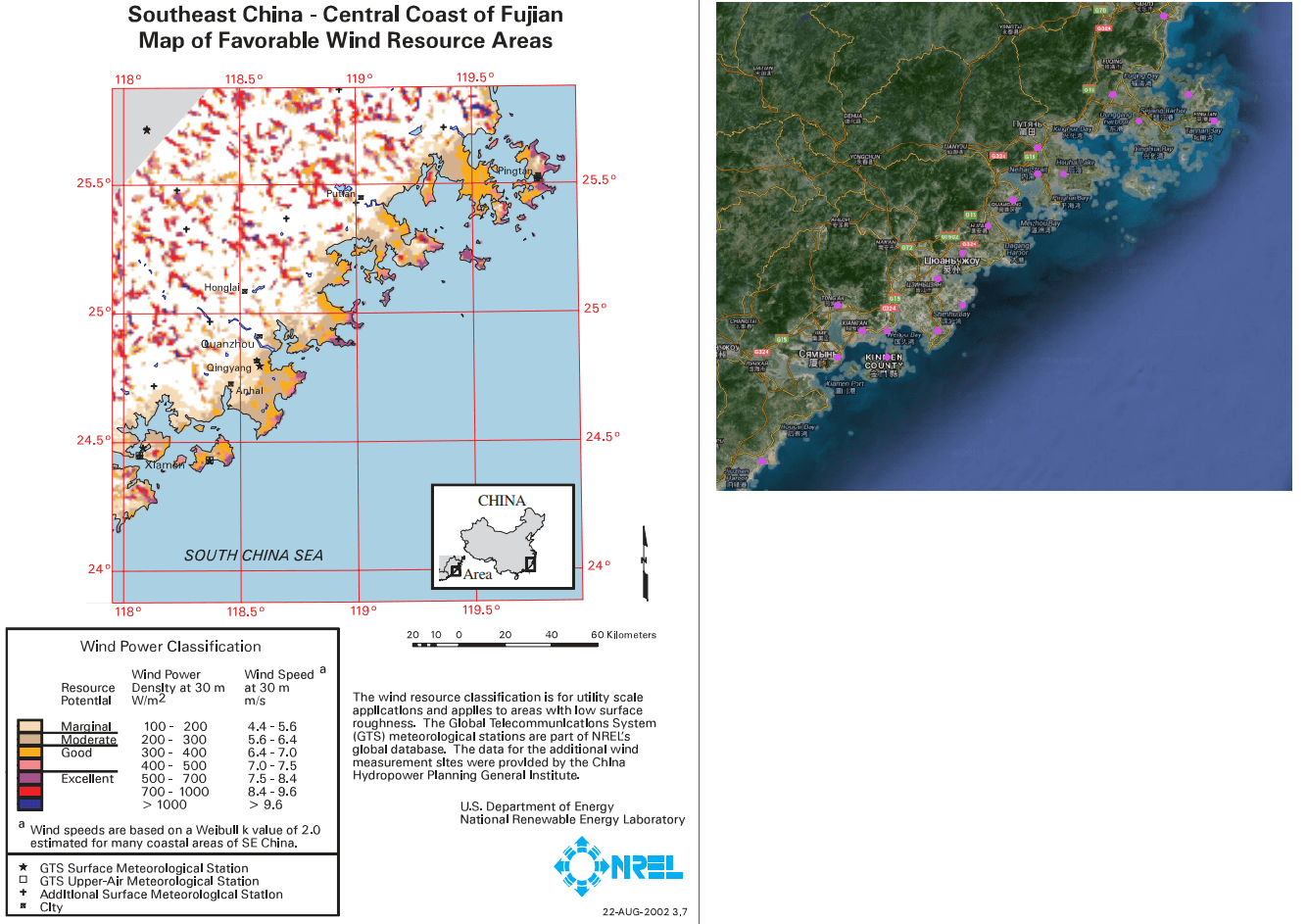
Visual inspection: the accumulation of points for the most part coincides with the places of good and excellent air velocity and density, when compared with wind charts. For example, here is Egypt and China:

Sometimes they write to me and ask me to send more detailed maps of places or explain some things on the map, but so far nothing has come of it. Theoretically, it is possible to recalculate the data not in increments of 10 km, but in 100 meters, and in theory the picture can change dramatically, and in theory it can predict not only the area, but also the specific location. But this requires a bit more computing power, which I do not have yet. If you have any ideas for the application, I will be glad to hear them.
Background
It seems that two years ago, or maybe already three, they announced a program for distributing free hectares in the Russian Far East . Looking quickly at the map, it became clear that just choosing the right hectare wasn’t so easy, and the best and most obvious places near cities would probably go away or were already left to the locals. Probably, it was at that moment that I had the idea that it was possible to somehow automate the search for the best place.
Starting to romantically think further, I thought that it was not necessary to look at the Far East. Now there is a lot of land that nobody needs anywhere, but that can change, 50 years from now, when fossil fuels begin to come to an end. And people will go look for new sources of energy. Then I began to look at renewable energy sources. And he quickly realized that the map of resources and territories where this new energy could be extracted would change dramatically. Having found such places now, you can purchase them in advance and be rich later.Having estimated still, it seemed to me that in a couple of days off it can be easily done ... Now, looking back, I understand that it took me about a year. I want to immediately note that at that time I was not very versed in energy, or in renewable sources, or in machine learning. Below is a brief retelling of my one-year project.
Choosing a Renewable Energy Source
Having decided on the idea, I quickly went to see what renewable energy sources are generally and which one is the most energetic. Here is an incomplete but most common list:
- solar radiation (solar energy);
- wind energy (wind power);
- energy of rivers and watercourses (hydropower);
- tidal energy;
- wave energy;
- geothermal energy;
- dissipated heat energy: the heat of air, water, oceans, seas and water bodies;
- biomass energy
But how to determine which one is the best and will defeat everyone else in the future? After reading some more interesting articles from the journals “Science and Life” and “Young Technician”. I went to the LCOE (levelized cost of electricity) methodology , which has a simple principle: smart guys are trying to estimate the total cost of a kilowatt hour of energy, taking into account production, materials, maintenance, etc. Below is a picture based on data from 2016 with some projection on 2022. I took a picture fresher from here , below is a boring plate from this document.
In general, I have such pictures for different countries made by different organizations and everything looks about the same:
- In the first place is Geothermal energy.
- Next, hydroelectricity, but it already depends heavily on the country.
- In third place is the Wind.
I did not like the geothermal and hydro, because in my opinion, the places where it would be possible to extract this energy can be counted on the fingers. Wind and the sun is another matter, since you can put them on almost every roof and balcony. The sun turned out to be more expensive, and three years ago the difference was 30 percent more; I chose Wind.
By the way, already in the middle of the project, I began to come across documents with similar thoughts of the US state, namely NREL organizations, the US Department of Energy and others that made forecasts and bets on different energy sources in order to understand now how to modernize the energy system countries. For example, in one of these documents it all came down to several options: the share of wind energy will be large or very large.
How I wanted to crank everything
The idea of how to crank this up was quite simple and looked like this:
- Find places where windmills are around the world.
- Gather information at these points:
a. Wind speed.
b. Direction.
c. Temperature.
d. Relief.
e. What local fishermen love for lunch.
f. Etc. - To transfer this information to a machine learning model that would be trained and find patterns, which parameters best influence the choice of a construction site by a person.
- Give away the trained model, all the points remaining points on the world with the same information on it.
- Get at the output a list of those points that are great for placing a windmill.
In graphical form, this plan, as it turned out later, looked like this famous picture:
How it really was
The first stage was quite easy. I just uploaded all the point records from OpenStreetMaps.
By the way, I want to note that OSM is just a storehouse of information about objects around the world with their coordinates, there is almost everything. Therefore, note to data lovers, OSM is the coolest Big Data source.
It wasn’t very difficult to do. At first I tried using online utilities, it seems overpass-turbo.eu, by the way, is a very cool thing, but it didn’t work out due to limitations on the number of points and not very fast work on a lot of data. Therefore, I had to deal with utilities that downloaded data from the OSM data cast locally. You can always download the current cast here? In compressed form, it takes about 40GB. Data can be downloaded from it using the Osmosis utility . As a result, I had a date set for 140 thousand points around the world with coordinates and heatmap. It looked something like this:
All problems began in the second stage , since I did not really understand what information needed to be collected. Therefore, for a couple of days I went into reading the principles of operation of windmills and recommendations for their placement, restrictions, etc. Even in the notes I have left here such amusing schemes about placement, wind gradients, wind roses and other other useful terms.
As a result, I got the following list of parameters, which, in my opinion, are important when choosing a place:
- The average wind speed per year (ideally 10-11m / s).
- Wind direction (The prevailing wind direction is wind rose).
- Minimum wind speed.
- The maximum wind speed.
- Power density.
- Average temperature.
- Average humidity.
- Medium pressure.
- Height above sea level.
- The distance to the water.
- Height difference.
- Smoothness of height differences.
- The maximum difference in the area of 5-10km.
- Percentage of trees or stands in the area (roughness).
- The distance to the village.
- The distance to the industrial facility.
- The average number of inhabitants per square.
- Distance to the road (sea, air).
- Distance to the electricity network.
- Visual and sound inconvenience.
- Protected areas: reserves and so on.
- Icing.
Big data
WIND . Actually, as 90% of all big data projects break down at the stage of “so now let's look at your data about which you talked so much”, mine also cracked. Having run to look for data on wind speed in Russia, I came across this:
And with a dozen similar and useless pictures. Then I began to guess that it is possible in Russia and there really is no wind energy, since we simply do not blow the wind in sufficient strength and somewhere at that moment Sechin's laughter was heard. But I clearly remember that in the Samara region there are only steppes and very often going out for bread as a child I was blown back to the porch.
Having started looking for data on Russia and what, I realized that it was not like the data with which you could do something useful. Therefore, I moved to foreign sources and immediately found beautiful wind maps from Tier3 (Vaisala). In appearance, the resolution was sufficient and the coverage of the whole world was simply excellent. Then I realized that such data cost good money about ~ $ 1000 per 10 square km (data from three years ago). Failure, I thought.
{kind=link}
After a sad week, I decided to write Vaisala, Tier3 and other consulting foreign agencies working with winds and other wind generators, and ask for data. I thought that after telling what a cool idea I was going to do, everyone would immediately download everything to me .. Only one answered - from the Sander-Partner company. Sander himself gave some advice, and also gave links to what I need: data from the MERRA programled by NASA. It is worth noting that it took me about a week in the evenings to figure out what Reanalysis, WRF is and roughly understand what is happening at all: collecting, aggregating, simulating and predicting weather, winds and other things.
In short, mankind has collected a bunch of weather data, a bunch of maps with average temperatures and wind speeds have been drawn, but it was still impossible to collect all this data at every point on the globe, so white spots were filled with weather simulation results for past years and called it Reanalysis . For example, here is a site with the visualization of such wind simulations, but here is how it looks:
This data was essentially a .csv grid file with an average wind speed with a large step, I made such a map using the coolest free QGIS package and the data grid interpolation method.
And then with the help of it he pulled out data on the wind speed from each pair of coordinates from this map. In fact, I got a map, and a data layer for each pixel on it.
Having understood the principle of working with QGIS in about a couple of weeks, I began to build the same maps for the rest of the data sources and pull out the values by coordinates. For temperature, humidity, pressure and other things. Here it should be noted that the data arrays themselves were mainly taken from NASA, NOAA, ESA, WorldClimetc. All of them are in the public domain. With the help of QGIS, I made calculations and searched for the distance to the nearest points, from cities, airports and other infrastructure facilities. Each card, according to one parameter, was considered to be about 6-8 hours for me. And if something was wrong, you had to do it again and again. My home computer rustled at night for about a couple of weeks, but after that even the neighbors got tired of listening to the loose cooler on it and I crawled into the cloud, where I picked up a small virtual machine for calculation.
After several months I came across this site,made by the Danish Department of Wind Energy (DTU Wind Energy). It quickly became clear that their permission was many times better than my card, I wrote to them and they gladly uploaded data to me all over the world, since only small impressions can be obtained through the site. By the way, they also made this map using a simulation of the movement of the wind layers by the WRF, WAsP models and achieved a data resolution of up to 50-100 meters, as I had about 1-10km.
RELIEF. Remember, I wrote that the terrain is very important, so I decided to use this parameter in the same way, but it turned out to be not easy either. First I wrote a utility that downloaded data from the Google Elevation API. She did a great job and downloaded the data on all my points of the whole world with a step of 10 km, it took only about 12 hours of work. But I also had the parameters of the smoothness of the relief or the average value of the difference in the territory around the potential location of the windmill. That is, I needed data with increments of meters in 100-200 of the whole world, with the help of which I could already calculate the average value of the difference.
In order to calculate the differences, it would take a couple of months to download data from Google Elevation. So I went looking for other options.
The first thing I found was Wolfram cloud , which already had the necessary data. Just by writing a formula, this thing began to count, using data from the Wolfram cloud. But there, too, a failure was waiting for me, since I came across some kind of limits that were not indicated anywhere and after receiving a funny correspondence with the support of this service, I went to look for another option.
Then NASA data sources and data from the STRM (NASA Shuttle Radar Topography Mission Global) space program helped me again. I honestly tried to pump them out of the site, but there the data was only for small territories. Having the courage, I wrote a letter to NASA and after about a week of correspondence, they uploaded the necessary data to me, for which many thanks to them. The truth is, the data turned out to be in some tricky satellite binary format, which I probably raked for a week.
Everything ended well, and I calculated the necessary elevation metrics for the whole world with a step of 10 km. By the way, by the way, I made my own API service, which returns the altitude by coordinates and published it herealgorithmia.com/algorithms/Gaploid/Elevation. It works on Azure Tables, where I cunningly fit the data and store it there literally for the centers. By the way, even someone bought access to the API a couple of times, since it is cheaper than from Google.
TOTAL . After spending about 4 months searching, cleaning, and calculating in QGIS, I got a data set data that I could use in machine learning models. And which contained about 20 different parameters in the following categories: Climate, Relief, Infrastructure, Necessity or Consumers.
Machine Learning and Prediction
At that time, I already had some knowledge and understanding of how machine learning algorithms work, but I didn’t really want to deploy all these Python and Anaconda. Therefore, I used the online service for dummies without SMS from Microsoft Azure ML Studio. Bribed that it is free and everything can be done with the mouse in the browser. Here, in theory, there should be a description of how I spent another month on creating a model, clustering data and other things. All these clustering was especially difficult because QGIS did them for a very long time on my old home PC. As a result, the experiment looks like this.
The total number of points that needed to be estimated was about 1.5 million . Each such point is a territory of 10 by 10 km and so the whole world. I removed the cells that already have windmills within a radius of 100 km, as well as some areas, and received a set date of ~ 1,500,000 records. The model assessed the suitability of each such square on planet Earth . I used mainly neural networks and boosted decision trees. Accuracy at those points where windmills are already standing and what my model predicted came out like this: Accuracy - ~ 0.9; Precision - ~ 0.9 . What, it seems to me, is pretty accurate, well, or somewhere, retraining took place. From this exercise, I got:
- Firstly, the points at which the model said it was a great new place for a windmill.
- Secondly, the points at which the model said where the places are not very good.
In total, I found about 30,000 of the most suitable places (these are new places where there are no windmills nearby at a distance of 100 km).
Result and Validation
Having received 30,000 points with new locations, I visualized them and it looks like a heatmap.
I made a small website using cartodb to render the map and uploaded the whole world map - windcat.ch . I also calculated for each point the approximate energy production from one industrial-sized windmill (50 m). The points here are colored according to the volume of energy, and not according to the Probability estimate from the model. You can click on each point and there the “confidence” of the model at that point will appear, I called it Goodness.
I also tried to verify the veracity of all this expertly.
Visual inspection: the model predicts points that creep along the shore, which seems to be true, since there will be a good even wind with a smooth surface.
Visual inspection: the accumulation of points for the most part coincides with the places of good and excellent air velocity and density, when compared with wind charts. For example, here is Egypt and China:
What's next
Sometimes they write to me and ask me to send more detailed maps of places or explain some things on the map, but so far nothing has come of it. Theoretically, it is possible to recalculate the data not in increments of 10 km, but in 100 meters, and in theory the picture can change dramatically, and in theory it can predict not only the area, but also the specific location. But this requires a bit more computing power, which I do not have yet. If you have any ideas for the application, I will be glad to hear them.