In the context: news aggregator on Android with a backend. Sequential integration system
The introductory part (with links to all articles) of the
“System of sequential integration”, I'm not sure that the translation is correct - it is better to call the system of continuous integration (continuous integration).
The first time I came across them at the beginning of my work, when 5-7 programmers intensively wrote code and tests, changed configuration files and poured all their results into trunk / master. As a result, quite often (so often that it was already enraging) something inoperative appeared in the main branch. Moreover, this was revealed when it was necessary to deploy a test bench, which greatly slowed down the work of the testing group (waiting for a fix) and developers (respectively fixed). Those. the performance of the code was not controlled after it was placed in the repository.

Then Hudson came to our aid (http://hudson-ci.org/)(Now better known as Jenkins (https://jenkins.io/) , although formally Hudson himself remained, but not so popular and not so actively developing) - he carried out many things:
This was a real step forward in terms of improving the quality and transparency of the development team (I'm not talking about minimizing the likelihood of a mess in the master / trunk):
But it was all earlier. Now the question is: what is the point of using a continuous integration system when working alone?
Until a certain point, there was really no sense. Until the project has grown (even with the participation of one developer) and here the presence of the integration server has shown its real value:
An additional interesting feature of Jenkins is its interface, which allows you to observe:
The most significant functional improvement of Jenkins after some time of its non-use was the appearance of the Pipeline plugin for me , which allows either to
This approach allows you to separate the steps for setting up a repository survey (performed in the Jenkins interface) and setting up the testing / integration procedures themselves (file
For example, in one of my sub-projects, the file
As you can see, this is actually a somewhat modernized groovy (DSL for Jenkins). Pilpeline consists of steps, steps and nodes. At the same time, the stages are reflected in the Stage View Plugin, which everyone loves to show in presentations and other performances.
At the same time, the developer has the right to determine what he plans to limit himself to during the verification phase: by launching unit tests, checking coding standards, launching integration tests, or placing artifacts that have been tested in the productive (thus realizing the Continuous Delivery principle).
At the moment, of the minuses of Jenkins can be noted only insufficient documentation for the product: often in the documentation section on the developer's website you can see the inscription: "This is still very much a work in progress" . However, this should not push away from a truly flexible and powerful product.
Thanks for attention!
“System of sequential integration”, I'm not sure that the translation is correct - it is better to call the system of continuous integration (continuous integration).
The first time I came across them at the beginning of my work, when 5-7 programmers intensively wrote code and tests, changed configuration files and poured all their results into trunk / master. As a result, quite often (so often that it was already enraging) something inoperative appeared in the main branch. Moreover, this was revealed when it was necessary to deploy a test bench, which greatly slowed down the work of the testing group (waiting for a fix) and developers (respectively fixed). Those. the performance of the code was not controlled after it was placed in the repository.
Then Hudson came to our aid (http://hudson-ci.org/)(Now better known as Jenkins (https://jenkins.io/) , although formally Hudson himself remained, but not so popular and not so actively developing) - he carried out many things:
- Build and run unit tests after each commit
- after committing to the release branch, he killed the old one and launched a new test stand for the testing team;
- generated reports on source codes (test coverage, indicators of compliance with testing standards);
- generated documentation for wiki.
- in addition, through its interface it was possible to track who made which commits, how the test coverage changed over time, how long the tests were built and run, and most importantly, because of which the build was broken.
This was a real step forward in terms of improving the quality and transparency of the development team (I'm not talking about minimizing the likelihood of a mess in the master / trunk):
- it was possible to find out what typical mistakes were made when working with the version control system (someone was punished, someone was trained);
- to prevent joint editing of one large file with configurations, its separation was performed, as well as the assembly logic was changed;
- rules for working with branches were developed and fixed (previously they worked on the principle “everyone understands ...”, i.e. there were no official rules).
But it was all earlier. Now the question is: what is the point of using a continuous integration system when working alone?
Until a certain point, there was really no sense. Until the project has grown (even with the participation of one developer) and here the presence of the integration server has shown its real value:
- due to the fact that the stand for launching integration tests is formed using configuration files that contain versions of other components, which are then pulled up by the storage system of ready-made artifacts (based on Nexus Sonatype), the correct indication of the component versions and checking their joint became a rather important issue health. However, this check is a time-consuming thing (time to download artifacts, assemble a stand, launch, run integration tests). Therefore, on the integration server, I configured the task on my work branch, into which I sometimes merge, in my opinion, work options and continue to work. After some time, I can check whether my assumption of working capacity is true or not;
- running unit tests for a local cluster with Apache Storm , even with the substitution of all components through Dependency Injection for Stub / Mock, takes a decent amount of time and sometimes I forget to run them all, which leads (also sometimes) to broken code in master - if the presence of CI, this is detected immediately after "git push";
- (not systematic, but it happened a couple of times), taking into account the presence in git of not only code, but also configuration files and data files, when adjusting “.gitignore” there were situations when the necessary files were excluded from the repository along with unnecessary ones. At the same time, they were saved on my machine and the tests worked, but on the CI server, this fact was instantly monitored.
An additional interesting feature of Jenkins is its interface, which allows you to observe:
- pipeline execution time and its stages
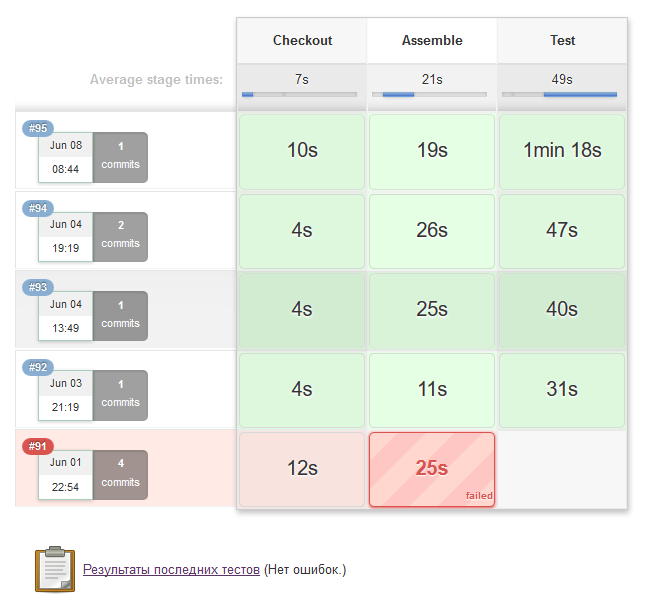 ;
; - graphic reflection of the number of worked / missed / tested tests
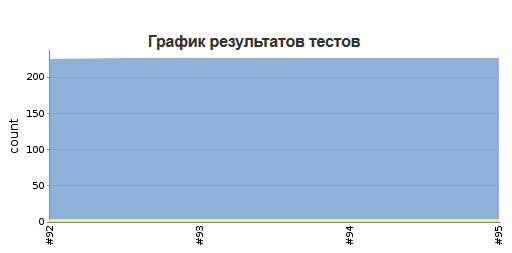 ;
; - tabular reflection of the number of tested / missed / tested tests
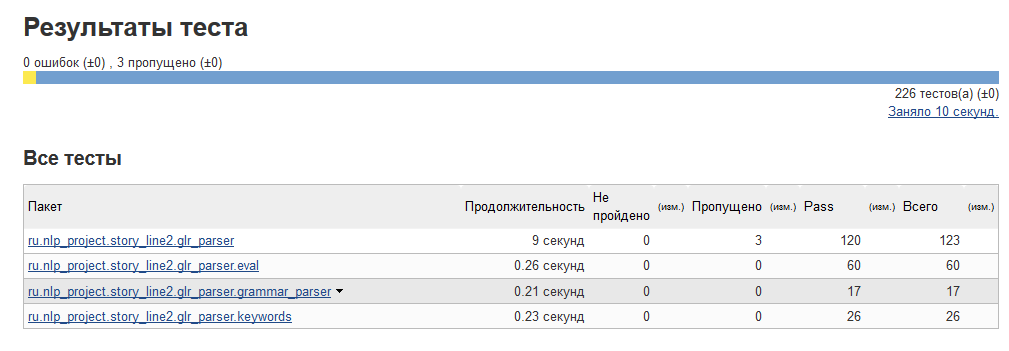 ;
; - detailed data on the latest commits that caused the assembly
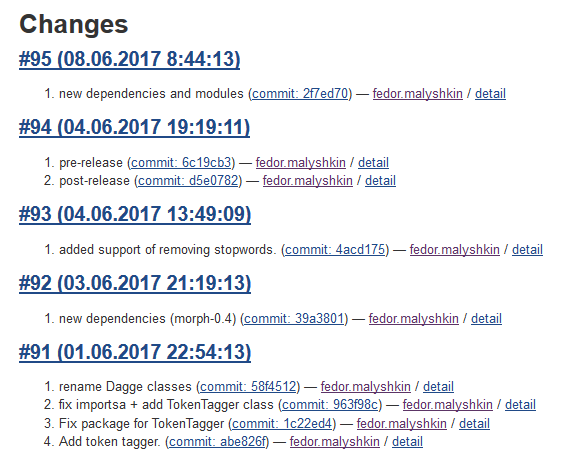 ;
; - detailed data on the commit that caused the specific assembly with the possibility of switching to the same GitHub for a detailed study of the changes
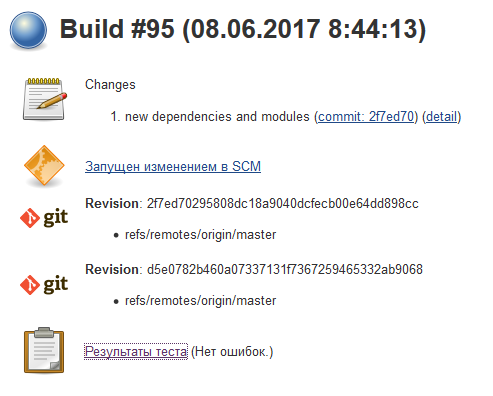 .
.
Pipeline
The most significant functional improvement of Jenkins after some time of its non-use was the appearance of the Pipeline plugin for me , which allows either to
Jenkinsfiledetermine what will be executed / launched / checked by the server through the Jenkins interface or through a separate configuration file of the project itself (file ) CI when receiving the code of your project / module. This approach allows you to separate the steps for setting up a repository survey (performed in the Jenkins interface) and setting up the testing / integration procedures themselves (file
Jenkinsfile), allowing the developer or the person responsible for the deployment to configure / modify / add the necessary testing / integration stages, without access to Jenkins. For example, in one of my sub-projects, the file
Jenkinsfile has the following content:#!groovy
node {
def projectName = 'glr_parser'
def gradleHome = tool name: 'gradle', type: 'gradle'
stage('Checkout') { // for display purposes
// Get some code from a GitHub repository
// parent directory
checkout changelog: true, poll: false, scm: [$class: 'GitSCM', branches: [[name: '*/master']], doGenerateSubmoduleConfigurations: false, extensions: [[$class: 'CleanBeforeCheckout']], submoduleCfg: [], userRemoteConfigs: [[url: 'story_line2_build.github.com:fedor-malyshkin/story_line2_build.git']]]
// project itself
checkout changelog: true, poll: true, scm: [$class: 'GitSCM', branches: [[name: '*/master']], doGenerateSubmoduleConfigurations: false, extensions: [[$class: 'RelativeTargetDirectory', relativeTargetDir: "${projectName}"]], submoduleCfg: [], userRemoteConfigs: [[url: "story_line2_${projectName}.github.com:fedor-malyshkin/story_line2_${projectName}.git"]]]
// deployment
// checkout changelog: true, poll: false, scm: [$class: 'GitSCM', branches: [[name: '*/master']], doGenerateSubmoduleConfigurations: false, extensions: [[$class: 'RelativeTargetDirectory', relativeTargetDir: 'deployment']], submoduleCfg: [], userRemoteConfigs: [[url: 'story_line2_deployment.github.com:fedor-malyshkin/story_line2_deployment.git']]]
}
stage('Assemble') {
dir(projectName) {
// Run the maven build
sh "'${gradleHome}/bin/gradle' -Pstand_type=test assemble"
}
}
stage('Test') {
dir(projectName) {
try {
sh "'${gradleHome}/bin/gradle' -Pstand_type=test test"
}
finally {
junit "build/test-results/test/TEST-*.xml"
}
}
}
}
As you can see, this is actually a somewhat modernized groovy (DSL for Jenkins). Pilpeline consists of steps, steps and nodes. At the same time, the stages are reflected in the Stage View Plugin, which everyone loves to show in presentations and other performances.
At the same time, the developer has the right to determine what he plans to limit himself to during the verification phase: by launching unit tests, checking coding standards, launching integration tests, or placing artifacts that have been tested in the productive (thus realizing the Continuous Delivery principle).
Tips
- The problem when setting up Jenkins tasks for me was the need to provide read access to the closed GitHub repository (there was not even the slightest desire to hammer passwords with accounts into the settings), this was solved using GitHub Deploy Keys ( see my earlier article )
- To track the status of tasks on a mobile device (Android) I use a surprisingly good client with the obvious name Jenkins .
A couple of screenshots:

- There is also an interesting thick client for PCs to track the build status of CatLight (but there is no experience).
At the moment, of the minuses of Jenkins can be noted only insufficient documentation for the product: often in the documentation section on the developer's website you can see the inscription: "This is still very much a work in progress" . However, this should not push away from a truly flexible and powerful product.
Thanks for attention!