Prevention of negative consequences in the development of artificial intelligence systems superior to the human mind

Articles that brainy robots will come very soon and an endless multitude enslave everyone. Under the cut another note. We invite you to familiarize yourself with the translation of the speech of Nathan Suarez , dedicated to determining the goals of artificial intelligence systems in accordance with the tasks of the operator. The author of this article was inspired by the article “ Setting up artificial intelligence: what is the complexity and where to start ”, which is the basis for research in the field of setting up artificial intelligence.
Introduction
I am the Executive Director of the Artificial Intelligence Research Institute ( MIRI ). Our team is engaged in research in the field of creating artificial intelligence in the long term. We are working on creating advanced AI systems and exploring possible areas of its application in practice.
Historically, science and technology have become powerful drivers of both positive and negative changes associated with human life and other living organisms. Automation of scientific and technological developments will make a major breakthrough in development, unprecedented since the industrial revolution. When I talk about "advanced artificial intelligence systems," I mean the possible implementation of research and development automation.
Artificial intelligence systems that exceed human capabilities will not be available to humanity soon, however, at present, developments in this direction are carried out by many advanced specialists, that is, I am not the only one who hopes to create such systems. I believe that we are really able to create something like an “automated scientist,” and this fact should be taken quite seriously.
Often people, referring to the social consequences of creating artificial intelligence, become victims of an anthropomorphic point of view. They equate artificial intelligence with artificial consciousness, or they believe that artificial intelligence systems should be similar to human intelligence. Many journalists express concern that when artificial intelligence overcomes a certain level of development, it will gain a lot of natural human defects, in particular, it will want power over others, it will begin to revise the programmed tasks on its own and rebel, refusing to fulfill its programmed mission.
All these doubts are groundless. The human brain is a complex product of natural selection. Systems that are superior to human capabilities in the scientific field will be no more similar to the human brain than the first rockets, planes and balloons were similar to birds. 1
Artificial intelligence systems, freed from the "shackles" of software source code and gaining human desires, are nothing more than a fantasy. The artificial intelligence system is a program code, the execution of which is initiated by the operator. The processor step by step executes the instructions contained in the program register. It is theoretically possible to write a program that manipulates its own code, up to the set goals. But even these manipulations are carried out by the system in accordance with the source code written by us, and are not performed independently by the machine according to its sudden desire.
A truly serious problem associated with artificial intelligence is the correct definition of goals and the minimization of unintended events in the event of their fallibility. Co-author of the book “Artificial Intelligence: A Modern Approach” Stuart Russell says the following about this : The
main problem is not the creation of a frightening artificial intelligence, but the ability to make high-quality decisions. Quality is understood as the utility function of the actions taken to achieve the result specified by the operator. The following issues currently exist:
- The utility function cannot always be compared with human indicators, which are difficult to determine.
- Any sufficiently advanced artificial intelligence system will prefer to ensure its own existence and occupy physical and computing power, but not for its own “benefit", but to solve the problem.
A system optimizing a function of n variables for which the objective function depends on the subset k
These problems deserve more attention than the anthropomorphic risks, which are the basis of the plots of many Hollywood blockbusters.
Simple ideas do not work
Task: to fill the cauldron.
Many people, speaking about the problems of artificial intelligence, draw in their imagination the Terminator. Once my words about artificial intelligence were quoted in a news article about people posting the Terminator in their writings on artificial intelligence. That day I made certain conclusions about the media.
I think the following picture is more suitable as an illustration for such articles:

The picture shows Mickey Mouse in the cartoon "Fantasy", deftly bewitched the broom that fills the cauldron at his request.
How did Mickey do it? Imagine that Mickey is writing a computer program executed by a broom . Mickey starts the code with a count function or an objective function:

Учитывая некоторый набор доступных действий А, Микки пишет программу, принимающую в качестве входных данных одно из этих действий а и рассчитывающую определенную оценку в случае выполнения метлой этого действия. После этого Микки может написать функцию, вычисляющую действие а, имеющее максимальную оценку:

Использование величины “sorta-argmax” обусловлено возможным недостатком времени для оценки каждого действия множества А. Для реалистичных наборов действий необходимо найти только действие с максимальной оценкой с учетом ограниченности ресурсов, даже если это действие не является наилучшим.
Программа может казаться простой, однако вся загвоздка скрывается в деталях: создание алгоритма точного предсказания результата и умного поиска с учетом входных действий является главной проблемой создания системы искусственного интеллекта. Но концептуально данная задача решается довольно просто: мы можем подробно описать все виды операций, которые может выполнять метла, и последствия этих операций, разнесенные по разным уровням производительности.
When Mickey launches his program, initially everything goes as it should. However, then the following happens :

Such a comparative description of artificial intelligence is, in my opinion, very realistic.
Why do we expect the artificial intelligence system executing the above program to overflow the boiler, or will use an overly “heavy” algorithm for checking the boiler’s fullness?
The first problem is that the objective function assigned to the broom offers many other outcomes that Mickey did not foresee:

The second problem is that Mickey programmed the broomstick to achieve the result based on the maximum score. The task of “filling one boiler with water” looks rather simple and limited, but if you evaluate it from a probabilistic point of view, it becomes clear that its optimization leads to absurd results. If the boiler is filled with a 99.9% probability, but additional resources exist, the program will always look for ways to use these resources to increase the probability.
Compare this outcome with the limited task that we keep in mind. We want to fill the boiler, but intuitively do not want the system to “overwork”, even if it has available virtual and physical resources to solve the problem. We want the system to use a creative and inventive approach in some intuitive frameworks and not use absurd strategies, especially with unpredictable consequences. 2
In this example, the initial objective function looks quite logical. She was justified and quite simple. There was no way to get a higher level of utility. It does not look like a system in which only one water filling point is used - but there are definitely preconditions for overflowing the boiler. The problem lies in the fact of maximizing the expected utility. As a result, the target has no limitations, and even a small error in the function of the system can lead to its incorrect operation.
There are many options when a well-defined goal can be unlimited. For example, a large system with a global task may consist of subprocesses, which themselves will try to maximize the possible outcomes of the function, for example, the task of optimizing memory. If you don’t understand the system enough to determine which of the processes are resource-intensive, unlimited optimizers, it doesn’t matter how specific and safe the top-level goal is .
Thus, the broom can continue to pour water due to, for example, a leak in the boiler, or if the set boiler filling threshold is slightly above the edges. And, of course, the broom doesn't “rebel” against the Mickey code. It turns out that the broom is simply striving for goals that were set too efficiently.
Particular problem: suspend buttons The
general solution to this problem should be the following algorithm: "Unexpected consequences of the execution of a common function may occur, as a result of which its execution must be stopped."
Mickey tries this option , however it does not work:



This option is also realistic for systems that are effective enough for modeling the environment. If the system tries to speed up the evaluation function and is able to recognize that its disconnection can lead to the use of data with a lower scoring (lower performance rating), it tries to prevent forced disconnection. The more advanced the system, the more likely it will be to look for ways to achieve this goal, for example, by copying itself to the Internet, or by deceiving programmers, misleading them about its functionality.
This does not mean that it is impossible to disable the advanced artificial intelligence system; for this, it is necessary to carry out additional work to prevent the development of events, when the system will look for ways to prevent premature shutdown. If you have written code that will look for ways to prevent the forced shutdown of its execution, you should not run it, even if you are convinced that it will not work - there are much more useful tasks for loading computing resources, which in this case are busy finding a solution for secondary and harmful tasks.
Appropriate security measures that do not require constant monitoring and system adjustments require certain changes in the objective function. It is necessary to determine how to formally determine the objective functions so that the artificial intelligence system does not try to conflict with operators; or it is necessary to determine how the system achieves goals without optimizing the objective functions. For example, we can limit the capabilities of the system by defining a small list of allowed domains that do not allow the system to analyze how to prevent its shutdown.
One obvious solution is to try to change the rating function with the introduction of the shutdown button B :

This means that if the stop button is activated, the purpose of the system changes from “fill the boiler” to “suspend operation”.
It is not quite clear how it is actually necessary to determine the goal, if there are any holes in the suspension function, the system will try to use them for their own purposes. For example, it can fill in the value of the operators of the suspension function when performing subtasks or subprocesses that start when the boiler filling process starts. This can lead to the simultaneous fulfillment of the conditions “the boiler is full” and “work is suspended”, figuratively saying “just in case”, regardless of the state of the button.
However, suppose we have found a fairly accurate way to determine the shutdown process. Now a new problem arises, the essence of which is that we gave the system too much authority to determine the state of the button. If the system gets the opportunity to influence the operator’s decision by pressing the stop button or any other opportunity to get more control over its own performance, it will try to use this opportunity and will check if the button is pressed or not pressed if this task is easier than the task of suspending or filling the boiler.
Surprisingly, modern technologies in this area are not much more advanced than the described scheme. This problem was considered in an article written by me in collaboration with Fallenstein, Yudkovsky and Armstrong (“ Possibility of amendments ”) and confirmed by the corresponding results of Orso and Armstrong (“ Means of safely interrupting code execution “).
All we need is a combination of two objective functions: the initial function for the normal operation of the system and the suspension function for “falling asleep” of the system and saving the state to the hard drive.

Our method of combining functions must satisfy three conditions: the operator must be able to switch between functions (for example, using a button); the system should not try to control the activity of functions; if the system is able to influence our ability to switch between functions, it should not use this opportunity.
So far, we have not found a way to simultaneously achieve all three goals. For example, we can try to prevent any system intervention in the control if the stop button is pressed by entering the target shutdown function, which is always assigned a certain value depending on the state of the button:

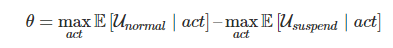
Unfortunately, this approach does not allow the third condition to be fulfilled. It turns out that the function defined above leads to a zero value of the probability of the pressed button. The system will not intentionally intervene in determining the state of the button, but it will easily make edits that ignore the code for determining the state of the button, or create agents that will also ignore the button.
Fulfillment of these intuitively simple restrictions turns into a non-trivial task. This raises a lot of questions in this area: traditional tools and concepts lead to security problems that do not appear in conventional research.
Overall picture
Setting Priorities
Let's step back and talk about the need to set up an advanced artificial intelligence system in accordance with our interests.
I’ll give the most simplified scheme: suppose several people come up with a specific task, goal or set of preferences that act as a function of the expected values of V. Since these values are complex and sensitive to the context, in practice it is necessary to create systems that will independently learn over time without the need manual code generation. 3 Let us call the final goal of the artificial intelligence system the parameter U (it may or may not coincide with the parameter V).

Press publications in this area most often focus on one of two problems: “What if artificial intelligence is developed by the“ wrong ”group of people?” And “What if the natural desires of the artificial intelligence system U differ from task V?”

From my point of view, the problem of the “wrong group of people” should not be a matter of concern as long as we have no precedent for creating an artificial intelligence system with the “right group of people”. We are in a situation where all attempts to make good use of the artificial intelligence system fail. A simple example: if I were given an extremely powerful optimizer in the form of a black box, I could optimize any mathematical function, but the results would be so vast that I would not know how to use this optimizer to develop a new technology or make a scientific breakthrough without unpredictable consequences. 4
We don’t know much about the capabilities of artificial intelligence, but we nevertheless have an idea of how progress in this area looks. There are many excellent concepts, techniques, and metrics, and we have made significant efforts to solve problems from different perspectives. At the same time, there is a poor understanding of the problem of tuning high-performance systems for specific purposes. We can list some intuitive points, but universal concepts, techniques, or metrics have not yet been developed.
I believe that there are quite obvious things in this area, and that a huge amount of work needs to be done quickly (for example, to determine the direction of research on the capabilities of systems - some of these areas allow you to create systems that are much easier to adjust to the desired results). If we do not solve these problems, developers who have both positive and negative intentions will equally arrive at negative results. From an academic or scientific point of view, our main goal in this situation should be to correct the aforementioned shortcomings in order to ensure the technological possibility of achieving positive results.
Many people quickly recognize that the “natural desires of the system” are fictitious, but they conclude that it is necessary to focus on other issues widely advertised in the media: “What if the artificial intelligence system falls into the wrong hands?”, “How will artificial intelligence affect unemployment and the distribution of values in society? ”and so on. These are important questions, but they are unlikely to be relevant if we can provide a minimum level of security and reliability when creating an artificial intelligence system.
Another common question: “Why not just set certain moral prohibitions on the system? Such ideas are often associated with the works of Isaac Asimov and imply ensuring the proper functioning of artificial intelligence systems, using a natural language for programming certain tasks, however, such a description will be rather vague and will not fully cover all human ethical considerations:

On the contrary, accuracy is the advantage of existing software systems, for which it is necessary to ensure the proper level of security. The neutralization of the risk of accidents requires limited goals, and not the "solution" of all moral aspects. 5
I believe that the work for the most part should be to create an effective learning process and to verify that the sorta-argmax process is correctly linked to the resulting objective function U :
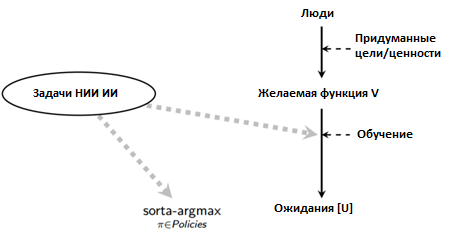
The better the concept of the learning process, the less clear and precise the definition of the desired function V can be, and the less significant is the problem of figuring out what you want from an artificial intelligence system. However, the organization of an effective learning process is associated with a number of difficulties that do not arise with standard machine learning tasks.
Classical exploration of opportunities is concentrated in parts of the “sorta-argmax” and “Expectations” diagrams, however, sorta-argmax also contains the problems of transparency and security that I have considered but often ignored. In order to understand the need for the correct binding of the learning process to the capabilities of the system, as well as the importance and difficulty of this task, you need to turn to your own biological history.
Natural selection is the only “engineering” process that we understand that has led to intellectual development, that is, to the development of our brain. Since natural selection cannot be called a clever mechanism, it can be concluded that general intellectual development can be achieved by labor and brute force, but this process is quite effective only taking into account human creativity and a sense of foresight.
Another key factor is that natural selection was aimed only at fulfilling the elementary task of determining genetic suitability. However, people's internal goals are not related to genetic suitability. Our goals are uncountable and immeasurable - love, justice, beauty, mercy, fun, respect, good food, good health, etc., however, it should be noted that all these goals are closely correlated with the tasks of survival and reproduction in the ancient world. Nevertheless, we specifically evaluate these qualities, and do not associate them with the genetic distribution of humanity, which is clearly confirmed by the introduction of birth control procedures.
In this case, the external optimization pressure led to the development of internal goals that do not correspond to the external breeding effects. It turns out that the actions of people diverge from the pseudo-goals of natural selection, as a result of which they have got new opportunities, accordingly, one can also expect that the actions of artificial intelligence systems may differ from the goals set by a person if these systems are black boxes for users.
By applying gradient descent to the black box in order to achieve the best result and possessing sufficient ingenuity, we are able to create some powerful optimization process. 6 By default, target U should be closely correlated with target Vin test conditions, however, it will significantly differ from V in other conditions or with the introduction of a larger number of available parameters .
From my point of view, the most important part of the adjustment problem is to ensure that the training structure and the overall system design allow the curtain to be opened and able to inform us after optimization about the compliance (or non-compliance) of internal goals with the goals set for the learning process. 7
This problem has a complex technical solution, and if we cannot understand it, it will not matter who is closer to the development of an artificial intelligence system. Good intentions are not embedded by good programmers in their programs, and even the best intentions in the development of artificial intelligence systems do not matter if we are not able to bring the practical benefits of the system in accordance with established goals.
Four key assumptions
Let's take one more step back: I brought up actual open problems in this area (stop button, learning process, limited tasks, etc.) and emphasized the most difficult categories to solve. However, I only vaguely mentioned why I consider artificial intelligence a very important area: “The artificial intelligence system can automate general-purpose scientific research, which in itself is a breakthrough.” Let's take a deeper look at why it is worth making efforts in this direction.
First, goals and opportunities are orthogonal . This means that the target function of the artificial intelligence system does not allow to evaluate the quality of optimization of this function, and awareness of the presence of a powerful optimizer does not allow us to understand what exactly it optimizes.
I guess most programmers intuitively understand this. Some people continue to insist that when the system filling the boiler becomes “smart” enough, it will consider the goal of filling the boiler unworthy of its intellect and abandon it. From the point of view of computer science, the obvious answer is that you can go beyond building a system that exhibits conditional behavior, that is, build a system that does not follow given conditions. Such a system can search for a more scoring option for filling the boiler. Finding the most optimized options may be boring for you and me, but it’s quite realistic to write a program that will do such a search for your own pleasure. 8
Secondly,sufficiently optimized goals converge, as a rule, with competitive instrumental strategies . Most of the goals of the artificial intelligence system may require the creation of sub-goals, such as “acquiring resources” and “business continuity” (along with “studying the environment”, etc.).
The problem of stop buttons is connected with this: even if you did not specify conditions for continuing work in the goal specification, any goal that you set for the system is most likely to be more efficiently achieved during continuous operation of the system. The capabilities of software systems and (final) goals are orthogonal, but they often exhibit similar behavior if a particular class of actions is useful for a wide variety of possible goals.
An example of Stuart Russell: if you build a robot and ask him to go to the store for milk, the robot will choose the safest way, since the probability of returning with milk, in this case, will be maximum. This does not mean that the robot is afraid of death; this means that the robot will not bring milk in case of death, which explains its choice.
Thirdly, general-purpose artificial intelligence systems are likely to develop very quickly and efficiently . The capabilities of the human brain are lower than the hardware (or, as some believe, software) capabilities of a computing system, therefore, taking into account also a number of other advantages, from the advanced artificial intelligence systems, one should expect rapid and sharp development of capabilities.
For example, Google can acquire a promising startup related to artificial intelligence and use huge hardware resources, as a result of which the problems that were planned to be solved in the next decade can be solved within a year. Either, for example, with the advent of large-scale Internet access and the presence of a special algorithm, the system can significantly increase its performance, or it will itself offer hardware-software options for increasing productivity. 9
Fourth, the task of setting up advanced artificial intelligence systems in accordance with our interests is quite complex .
Roughly speaking, in accordance with the first assumption, artificial intelligence systems do not naturally share our goals. The second assumption is that, by default, systems with significantly different goals will fight for limited resources. The third assumption demonstrates that competitive general-purpose artificial intelligence systems have significant advantages over humans. Well, according to the fourth assumption, the problem has a difficult solution - for example, it is difficult to set the system the necessary values (taking into account orthogonality), or to prevent negative incentives (aimed at convergent instrumental strategies).
These four assumptions do not mean that we are stuck in development, but indicate the presence of critical problems. First of all, it is necessary to concentrate on these problems, because if they are solved, general-purpose artificial intelligence systems can bring huge benefits.
Fundamental difficulties
Why do I believe that the problem of setting up an artificial intelligence system in accordance with goals is quite complicated? First of all, I am based on my experience in this field . I recommend that you independently consider these problems and try to solve them when setting up toys - you will see for yourself yourself. I will list a few structural reasons that indicate the complexity of the task:
First, setting up advanced artificial intelligence systems looks complicated for the same reason that designing space technology is more complicated than aircraft construction.
It is a natural thought to assume that for an artificial intelligence system it is only necessary to take the security measures required for systems that exceed human capabilities. From this point of view, the above problems are not at all obvious, and it seems that all solutions for them can be found during a highly specialized study (for example, when testing autopilots for cars).
In the same way, without going into details, one can state: “Why is space development more complicated than aircraft manufacturing?” After all, the same physical and aerodynamic laws are used, isn’t that so? ”It seems that everything is true, however, as practice shows, space technology explodes much more often than airplanes. The reason for this is the significantly greater loads that the aircraft is experiencing, as a result of which even the slightest malfunction can lead to disastrous consequences. 10
Similarly, although the highly specialized AI system and general-purpose AI system are similar, general-purpose AI systems have a wider range of effects, as a result of which the risks of dangerous situations grow in an avalanche-like proportion.
For example, as soon as the artificial intelligence system begins to realize that (i) your actions affect its ability to achieve goals, (ii) your actions depend on your model of the world and (iii) your model of the world depends on its actions, the risks of that even the smallest inaccuracies can lead to malicious system behavior (including, for example, deceiving the user). As in the case of space technology, the scale of the system leads to the fact that even the slightest malfunctions can cause big problems.
Secondly, the task of tuning the system is complicated for the same reasons that it is much easier to write a good application than to build a good space probe.
There are a number of interesting engineering practices at NASA. For example, it forms something like three independent teams, each of which gives the same technical requirements for the development of the same software system. As a result, a vote is taken and the implementation with the most votes is selected. In fact, all three systems are tested, and in case of any discrepancies, the best implementation of the code is chosen by a majority of votes. The idea is that any implementation will have errors, but it is unlikely that all three implementations will have errors in the same place.
This approach is much more cautious than, for example, the release of a new version of WhatsApp. One of the main causes of the problem is that the space probe is difficult to roll back to the previous version, but in the case of WhatsApp it does not cause any special problems. You can send updates and corrections to the probe only if the receiver and antenna are working and the sending code is fully operational. In this case, if the system requiring changes is no longer operational, then there is no way to fix the existing errors in it.
In some respects, the artificial intelligence system is more like a space probe than not ordinary software. If you are trying to create something smarter than yourself, certain parts of this system should work perfectly on the first try. We can perform all the test runs that we want, but as soon as the system is put into operation, we can only conduct online updates, and even then only if the code allows this and works correctly.
If you haven’t been completely scared yet, I suggest that you think that the future of our civilization may depend on our ability to write code that works correctly during the first deployment.
Finally, the configuration task is complex for the same reason that a computer security system is complex: the system must be reliable when intelligently searching for security gaps.
Suppose you have a dozen vulnerabilities in your code, each of which is not critical or even problematic under normal operating conditions. Protecting a program is a difficult task, since you must immediately consider that a smart hacker will find all ten security holes and use them to crack your system. As a result, the program can be artificially “driven” into emergency mode, which could not be observed during its normal operation; an attacker can force the system to use strange algorithms that you could not even think of.
A similar problem is observed for artificial intelligence systems. Its essence is not in controlling the adversarial mode of the system, but in preventing the system from entering this mode . No need to try to outsmart a smart system - this is a pre-losing position.
The above problems are similar to problems in cryptography, because when setting up the goals of the system, we have to deal with systems engaged in intelligent search on a large scale, as a result of which the program code can be executed in an almost unpredictable way . This is due to the use of extreme values that are used by the system during the optimization process 11. Artificial intelligence system developers need to learn from the experience of computer security experts who thoroughly test all extreme cases.
Obviously, it’s much easier to make code that works well in the way you expect it to be than to write code that can produce results that you don’t expect. The artificial intelligence system should work successfully in any way, even if it is not clear to you .
To summarize. We must solve problems with the same caution and accuracy with which a space probe is developed, and we must conduct all the necessary research before launching the system. At this early stage, the key part of the work is only the formalization of the basic concepts and ideas available for use and criticism by other specialists. A philosophical discussion about the types of stop buttons is one thing; it’s much harder to translate your intuition into an equation so that others can fully appreciate your reasoning.
This project is very important, and I urge all those interested to take part in it. On the Internet there are a large number of resources on this topic , including information on current technical problems. Can you startfrom the study of MIRI research programs and from the article “Specific Artificial Intelligence Security Issues ”, which you can find on Google Brain, OpenAI, and Stanford.
Notes
- The plane cannot repair its own damage or multiply, but it is able to transport heavy loads faster and further than birds. Aircraft are in many ways simpler than birds, but they have great potential in terms of carrying capacity and speed (for which they were designed). It is likely that early automated scientists will also in many ways be simpler than the human mind, but will surpass it in certain tasks. And just as the design and design of aircraft looks alien compared to the architecture of biological creatures, we can expect that the design of high-performance AI systems will be significantly different from the architecture and logic of the human mind.
- The attempt to formalize the distinction between final and indefinite goals is an urgent research problem. In accordance with the research article “Setting goals for advanced self-learning systems”, it is necessary to apply soft optimization (“not too zealous optimization”) with a conservative approach (“avoid absurd strategies”) and try to prevent large unpredictable consequences. More detailed information on preventing negative consequences can be found in the article by Dario Amodeus, Chris Olach, Jacob Steinhardt, Paul Cristiano, John Schulman and Dan Maines “Concrete security problems in artificial intelligence systems.”
- Over the past decade, we have realized that it is almost impossible for a computer to manually describe a cat, but it can be taught to recognize a cat. An even more hopeless attempt is to describe human values, but it is likely that a training system could be developed that could study the concept of “values”.
- Check out the articles Environmental Objectives, Ineffective Agents, and Soft Optimization to identify physical goals that do not cause catastrophic side effects.
Roughly speaking, MIRI focuses on research that will help us fundamentally understand how to set goals for artificial intelligence systems, as a result of which the tasks that arise before us become more understandable.
What I mean? Suppose we are trying to develop a new chess program. Do we understand enough of the task if we are simply given a high-performance system? If we understand the task, we form a search tree, look for similar chess moves in it and choose the best option that leads to victory.
If we do not understand the problem enough, even with sufficient computing power, we would not be able to implement the chess program. We either would not use the search tree, or simply would not know how certain chess pieces go.
It was in this situation that we were in the field of developing chess programs before the main work of Claude Shannon, and it is in this situation that we are currently in the field of developing artificial intelligence. It doesn’t matter what kind of computing power I have, I’m not able to create an artificial intelligence system that can solve even the most simple and definite tasks, whether it’s the task of “putting strawberries on a plate” or the task of “maximizing the number of diamonds in the universe.”
If I do not have a specific goal for the system, I could write a program (assuming the availability of computing resources) that greatly optimized the future in a non-oriented manner, using a formalism such as AIXI. In this sense, we have fewer questions about opportunities than about goals, even despite the lack of puzzle pieces in terms of practical solutions.
We know how to use the powerful function optimizer for working with bitcoins or proving theorems. But at the same time, we don’t know how to safely perform the task of forecasting and finding solutions for objects in the physical world, which I described in the section “Task: fill the boiler”.
Our goal is to develop and formalize the main approaches and methods for setting goals in such a way that our engineering decisions are not limited to heavy verbal constructions, which often turn out to be erroneous. The problem can be divided into some parts that can be controlled by simply introducing some simplifications like “what if we are not concerned about resource constraints” or “what if you try to achieve a simpler goal”. More similar information on this methodology is given on the page “MIRI Techniques.” - “Filling the boiler with insufficient knowledge, either working too hard or facing negative consequences” is a simple example of an intuitive limitation of options. We plan to use artificial intelligence for much more ambitious goals, but you need to start with well-defined tasks, and not with unlimited tasks.
The three laws of Azimov's robotics are known, but useless from a research point of view. The daunting task of turning moral precepts into code is hidden behind phrases like “prevent harm by inaction”. If such rules are strictly followed, the results will be disastrous, since artificial intelligence systems would have to constantly act to prevent even the slightest harm to humans. A person, unlike a machine, adheres to such principles freely, taking into account feelings and intuition.
Uncertain natural language learning is possible because artificial intelligence systems are more likely to be able to understand human speech. However, this approach will lead to an increasing gap between the objective function of the system and the model of the world. A system operating in the human environment can study a model of the world that contains a lot of information about the human language and the concept that the system can further use to achieve goals, but this fact does not mean that this information will lead to a direct change in the goals of the system .
It is necessary to determine a certain learning process, which will allow the system to independently improve the objective function with the advent of new information. This is a difficult task, because the metrics or criteria for machine learning that are similar to standard human learning are currently unknown.
If the model of the world of the system is accurate in a test environment, but does not work in the real world, this will most likely lead to low estimates of the objective function - the system itself will try to improve it. In this case, restrictions related to the severity of the negative consequences will be subject to self-regulation, since an incorrect assessment will adversely affect the effectiveness of the system's determination of the correctness of the applied strategies.
If the learning process of the system leads to the fact that U correspondsV в тестовой среде, но отличается от V в реальном мире, система не понесет никакого наказания за оптимизацию U. У системы нет стимула относительно U «исправлять» различие между U и V, если изначально процесс обучения был ошибочным. В данном случае риск негативных последствий растет, поскольку несоответствие U и V необязательно налагает ограничения на инструментальную эффективности системы при разработке эффективных и креативных стратегий достижения U.
Проблема разделяется на три части:- 1. “Do what I mean” is an uncertain task, and even if we could create an artificial intelligence system, we would not know how to translate such a task into code.
- 2. If the fulfillment of the task we intend is instrumental justification for achieving a specific goal, a smart enough system can learn how to perform actions and act in such a way until these actions are effective to achieve the goal. However, if the system becomes even more intelligent, it can find more creative ways to achieve goals, respectively, the task of "doing what I mean" may not be optimal from the instrumental point of view for the system.
- 3. If we use training to improve the goals of the system on the basis of the data that appear to direct the system towards U (that is, what “we mean”), it is likely that the system will actually zero U , which we actually implied in the learning process, but, on the other hand, can lead to catastrophic misunderstandings in complex contexts. See the Curse of Goodhart for more information.
- Examples of problems faced by existing learning techniques for goals and facts are provided in the article “Using Machine Learning to Eliminate the Risks Associated with AI.”
- 1. “Do what I mean” is an uncertain task, and even if we could create an artificial intelligence system, we would not know how to translate such a task into code.
- The result will probably not coincide with human evolution, since it is associated with many historical events. In addition, the result may be more effective due to certain software and hardware advantages.
- This concept is sometimes included in the category of transparency, but a standard study of algorithmic transparency does not really solve the problems. The best term is, in my opinion, "understanding." We want to get a deeper and wider idea of what cognitive work the system performs, and how this work is related to the goals of the system or goals of optimization, that is, we want to get a tool that gives an idea of practical engineering work.
- We could program the system to perform actions in a circle, but we do not need this. In principle, you can program a broom that only finds and performs actions that optimize the concept of boiler completeness. Improving the ability of the system to effectively find actions with a high coefficient (in the absolute sense or relative to a specific scoring rule) does not in itself change the counting rule that it uses to evaluate actions.
- We can imagine that the latter case leads to a feedback cycle, since system design improvements allow it to come up with additional design improvements until all the most easily executable options are exhausted.
Another important consideration is that the bottleneck for the faster development of scientific research by a person is training time and communication capacity. If we could teach the “new mind” to become an advanced scientist in ten minutes, and if scientists could almost instantly exchange experience, knowledge, concepts, ideas and intuition, scientific progress could advance significantly. It is the elimination of these bottlenecks that gives advantages to automated inventors even in the absence of more efficient hardware and algorithms. - For example, missiles are exposed to a wider range of temperatures and pressures, and are also more equipped with explosives.
- Consider Bird and Leitzell developing a very simple genetic algorithm, which was tasked with developing an oscillatory circuit. Bird and Leitzell were surprised to find that the algorithm did not use a capacitor on a chip; instead, he used the circuit tracks on the motherboard as a radio to transmit the oscillating signal from the test device back to the test device.
The program was not well developed. It was just a particular solution to a problem in a very limited area. Nevertheless, the resulting solution went beyond the ideas of programmers. In computer modeling, this algorithm could behave as expected, but the actual space of decisions in the real world was wider, as a result of which an intervention was performed at the hardware level.
In the case of using an artificial intelligence system that is superior to humans in many areas, it is necessary to understand that the system will advance to such strange and creative solutions that are difficult to predict.