Cascade SFU: improving the scalability and quality of media in WebRTC applications
- Transfer
There are two difficulties in deploying media servers for WebRTC: scaling, i.e. going beyond using one server and optimizing delays for all conference users. While simple sharding in the spirit of “send all users of conference X to server Y” is easily scaled horizontally, it is still far from optimal in terms of delays. Distributing a conference to servers that are not only close to users, but also interconnected - sounds like a solution for both problems. Today we have prepared a translation of the detailed material from Boris Grosev from Jitsi: problems of cascading SFUs, with a description of the approach and some difficulties, as well as details of implementation. It is worth saying that Voximplant conferences also use SFU; We are currently working on SFU cascading, which should appear on our platform next year.
Mouse neurons. Image NIHD ( CC-BY-2.0 )
Real-time communications are very sensitive to the network: bandwidth, latency and packet loss. Reducing the bitrate leads to lower video quality, a long network delay leads to a long delay for end users. Loss of packets can make the sound intermittent and lead to friezes in the video (due to dropped frames).
Therefore, it is very important for the conference to choose the best route between the end devices / users. When there are only two users, it’s easy - WebRTC uses the ICE protocolto establish a connection between the participants. If possible, the participants are connected directly, otherwise the TURN server is used. WebRTC can rezolvit domain name to get the address of the TURN server, so you can easily choose a local TURN based on DNS, for example, using the properties of AWS Route53 .
However, when the routing of multiple participants occurs through one central media server, the situation becomes complicated. Many WebRTC services use selective forwarding units (SFU) to more efficiently transfer audio and video between 3 or more participants.
In the star topology, all participants connect to one server through which they exchange media streams. Obviously, the choice of server location is of great importance: if all participants are located in the USA, using a server in Sydney is not the best idea.
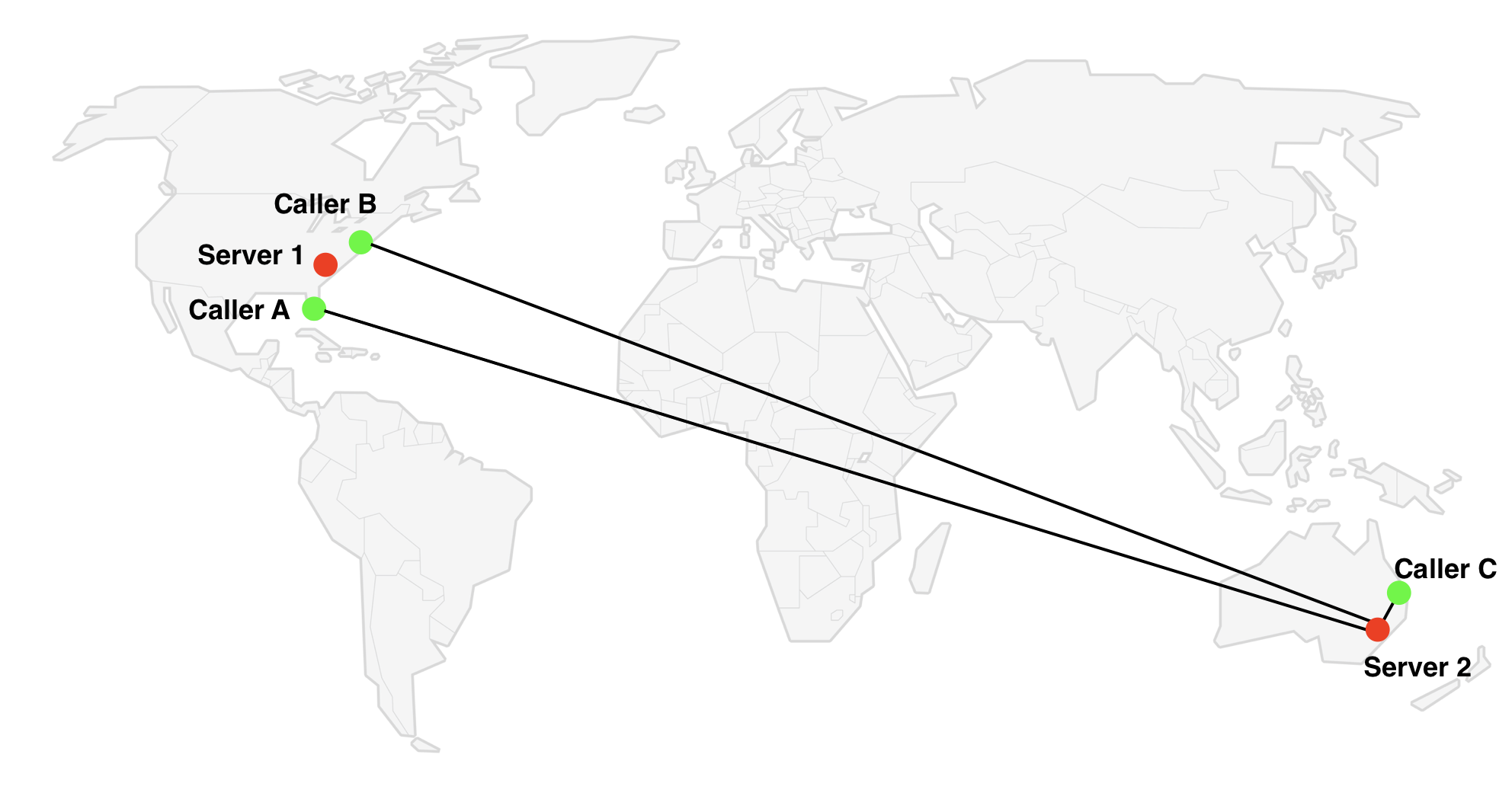
Many services use a simple approach that works well in most cases: they choose a server closer to the first participant of the conference. However, there are times when this solution is not optimal. Imagine that we have three participants from the image above. If the Australian (Caller C) is the first to connect to the conference, the algorithm will choose a server in Australia, however Server 1 in the USA will be the best choice, since He is closer to most participants.
The scenario described is not very frequent, but it does. If we assume that a user is connected in a random order, then the described situation occurs with ⅓ of all conferences with 3 participants, one of which is strongly removed.
Another and more frequent scenario: we have two groups of participants in different locations. In this case, the order of connection is unimportant, we will always have a group of closely located participants who are forced to exchange media with a remote server. For example, 2 participants from Australia (C & D) and 2 from the USA (A & B).
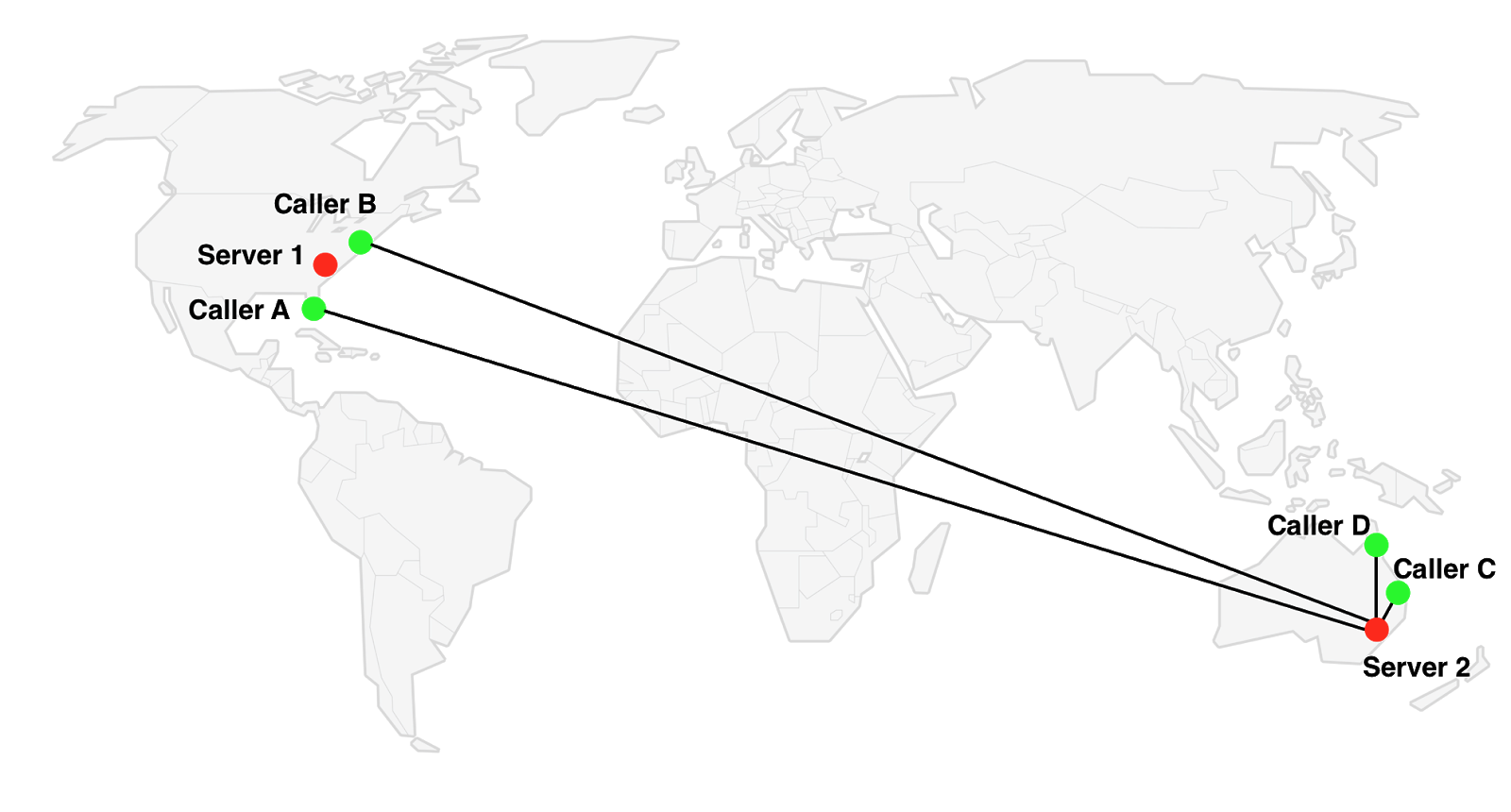
Switching to Server 1 is not optimal for C & D members. Server 2 is not optimal for A & B. That is, whatever server is used, there will always be participants connected to a remote (= non-optimal) server.
But if we did not have restrictions in one server? We could connect each participant to the nearest server, it would be necessary only to connect these servers.
Let us postpone the question of how to connect the servers; let's first see what the effect will be.
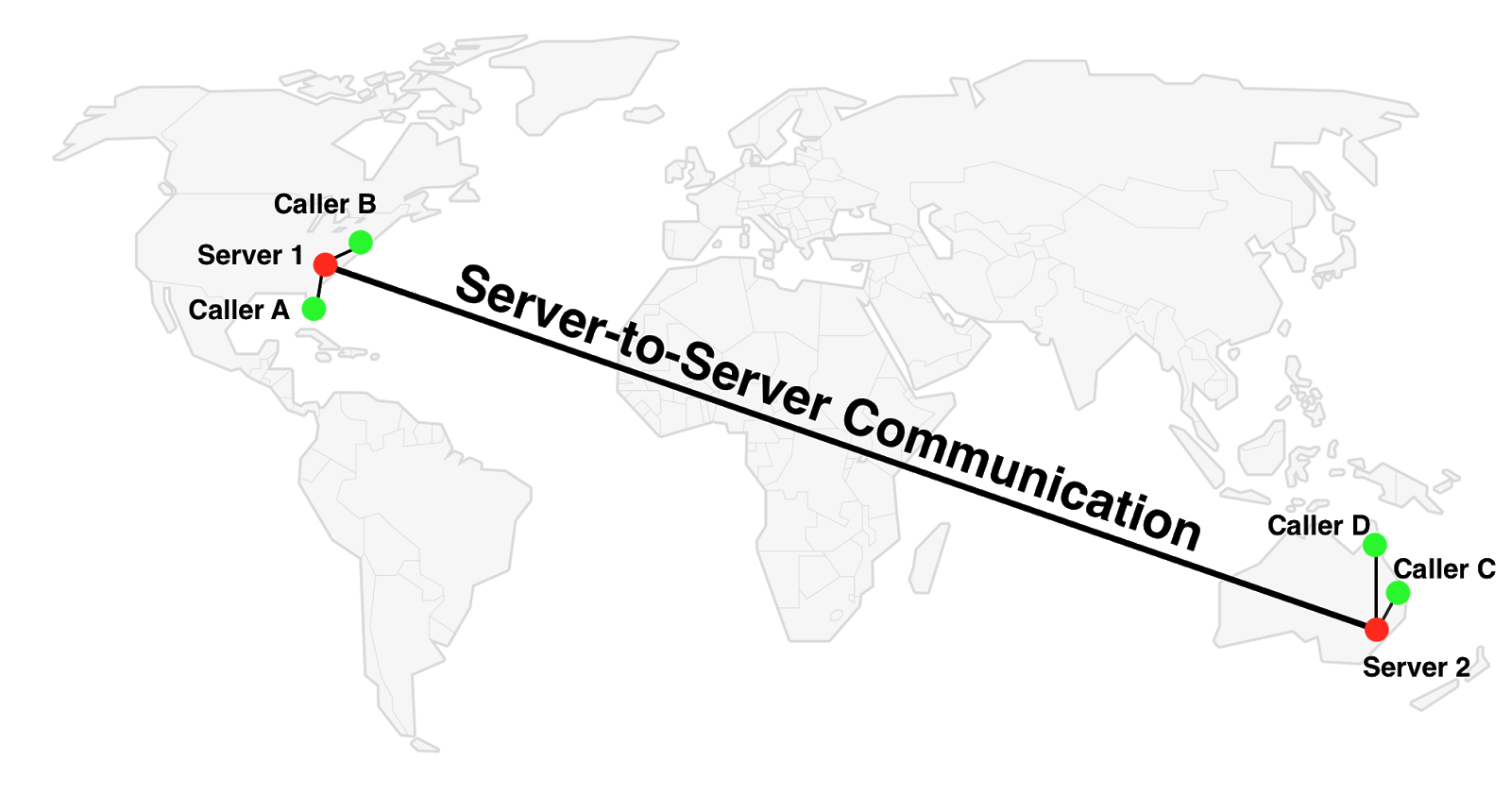
The SFU connection between C and D has not changed - Server 2 is still used. For participants A and B, Server 1 is used, and this is obviously better. The most interesting thing is the connection between, for example, A and C: instead of A <=> Server 2 <=> C, the route A <=> Server 1 <=> Server 2 <=> C is used.
The SFU mix has its pros and cons. On the one hand, in the described situation, the exchange time between the participants becomes longer with the addition of new hops over the network. On the other hand, there is a decrease in this time when we are talking about the connection “client” - “the first server”, because we can restore the media stream with less delay according to the hop-by-hop principle.
How it works? WebRTC uses RTP (usually over UDP) to transfer media. This means that transport is unreliable. When a UDP packet is lost, you can ignore the loss or request retransmission (retransmission) using the RTCP NACK packet- the choice is already on the conscience of the application. For example, an application can ignore the loss of audio packets and request retransmission of some (but not all) video packets, depending on whether they are needed to decode subsequent frames or not.
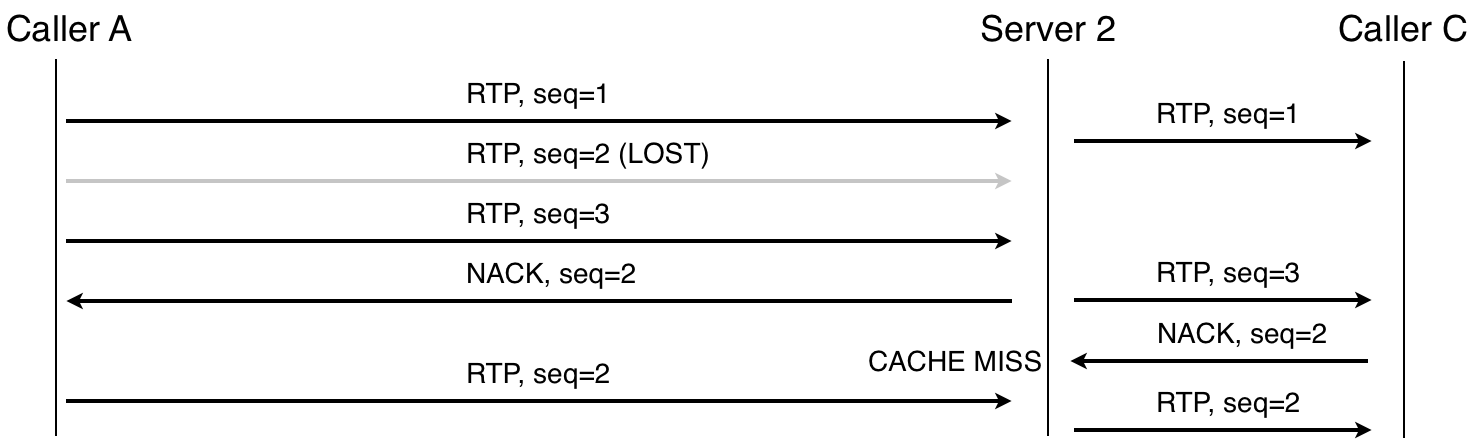
RTP packet retransmission, single server
When there is a cascade, the retransmission can be limited to the local server, that is, it can be performed at each particular site. For example, in route A-S1-S2-C, if the packet is lost between A and S1, then S1 will notice and request a retransmission; similarly, with a loss between S2 and C. And even if the packet is lost between servers, the receiving party can also request retransmission.
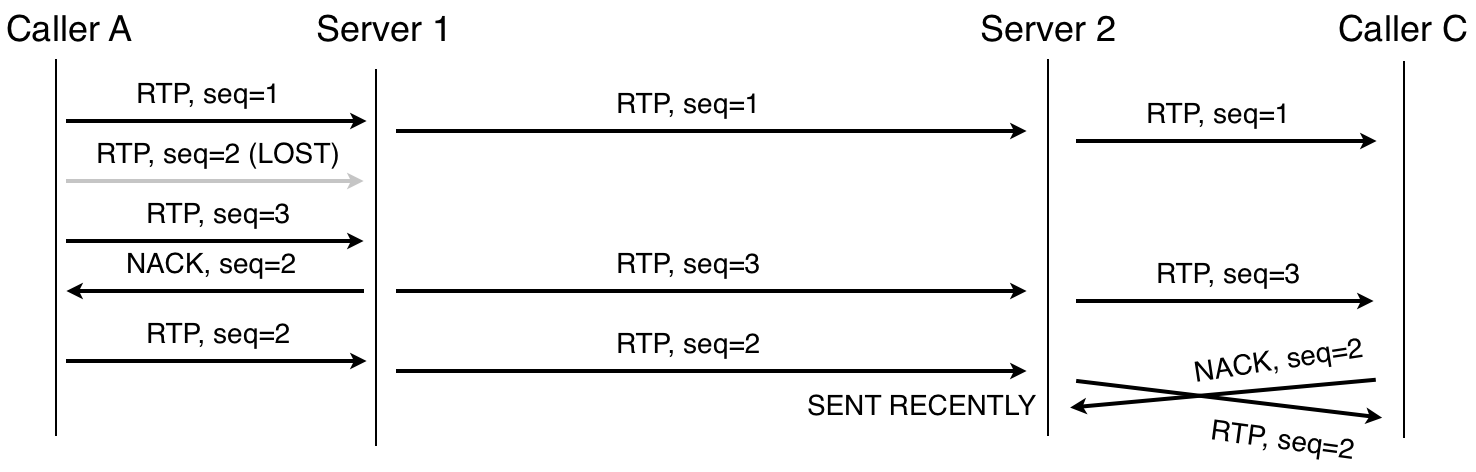
RTP packet retransmission, two servers. Note that Server 2 does not request packet 2, because the NACK arrived shortly after sending the packet.
On the client, jitter buffer is used to delay the video playback and have time to receive delayed / retransmit packets. The buffer size dynamically changes depending on the exchange time between the parties. When hop-by-hop retransmissions occur, the delay decreases, and as a result, the buffer may be less - as a result, the total delay also decreases.
In short: even if the exchange time between participants is higher, it can reduce the delay in the transfer of media between participants. We have yet to study this effect in practice.
Let's take a look at the alarm. From the very beginning, Jitsi Meet divided the concept of the alarm server ( Jicofo ) and the media server / SFU. This enabled cascading support to be relatively simple. First, we could handle all the alarm logic in one place; secondly, we already had a signaling protocol between Jicofo and the media server. We only needed to expand the functionality a bit: we already had multiple SFUs connected to one alarm server, we had to add the ability of one SFU to connect to multiple alarm servers.
As a result, two independent server pools appeared: one for jicofo instances, the other for media server instances, see the diagram:
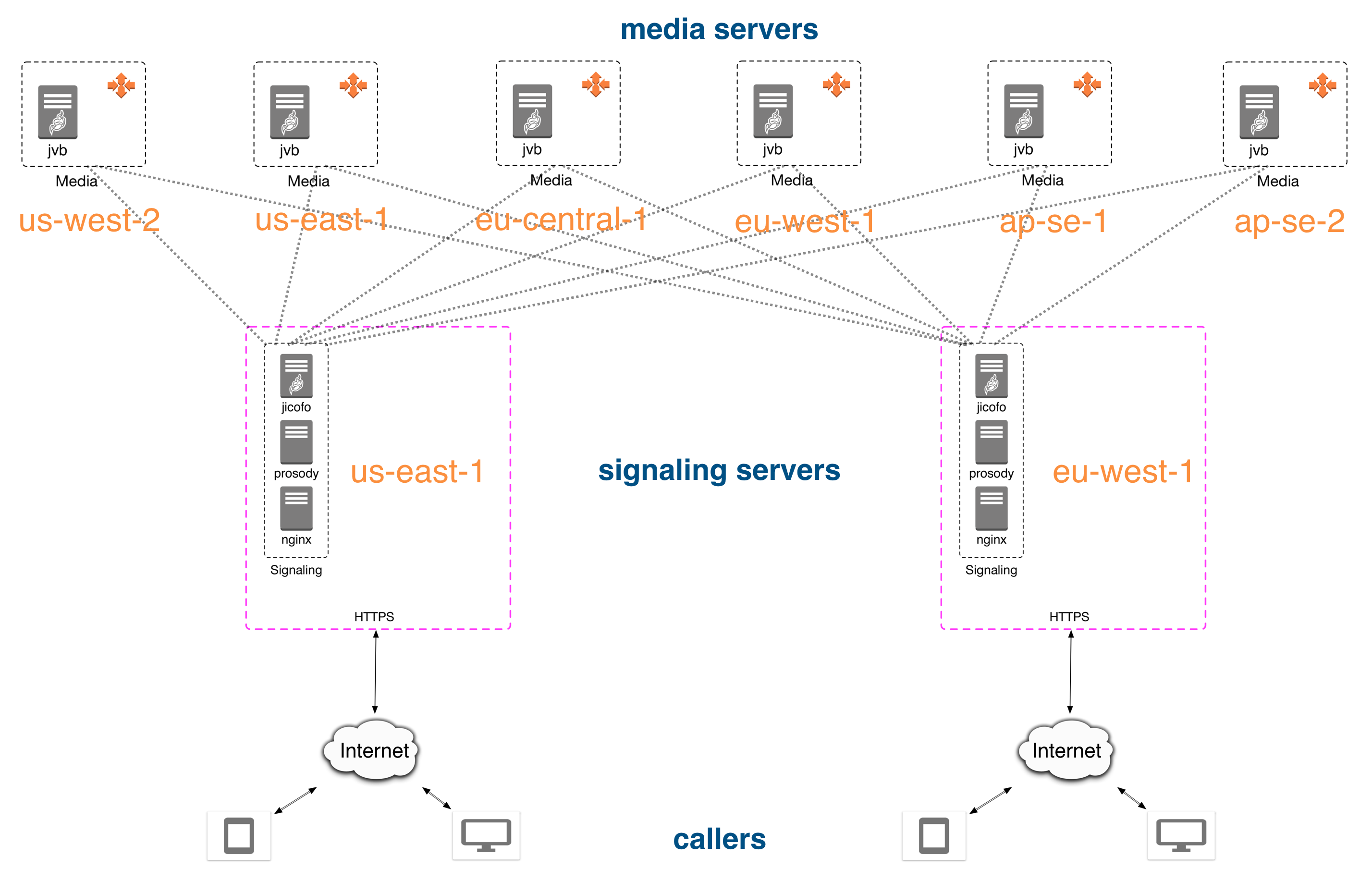
An example of the organization of servers on AWS with the possibility of a cascade between different data centers.
The second part of the system is the bridge-to-bridge connection. We wanted to make this part as simple as possible, so there is no complex signaling between the bridges. All alarms go between jicofo and jitsi-videobridge; connection between bridges is used only for audio / video and data channel messages.
To manage this interaction, we took the Octo protocol, which wraps RTP packets into simple fixed-length headers and also allows you to send a text message. In the current implementation, the bridges are connected in a full mesh topology (full mesh), however, other topologists are possible. For example, use a central server (a star for bridges) or a tree structure for each bridge.
Explanation: Instead of wrapping in an Octo header, you can use the RTP header extension, which will make the flows between bridges on pure (S) RTP. Future versions of Octo can use this approach.
Second explanation: Octo means nothing. At first we wanted to use a central server, and this reminded us of an octopus. So the name for the project appeared.
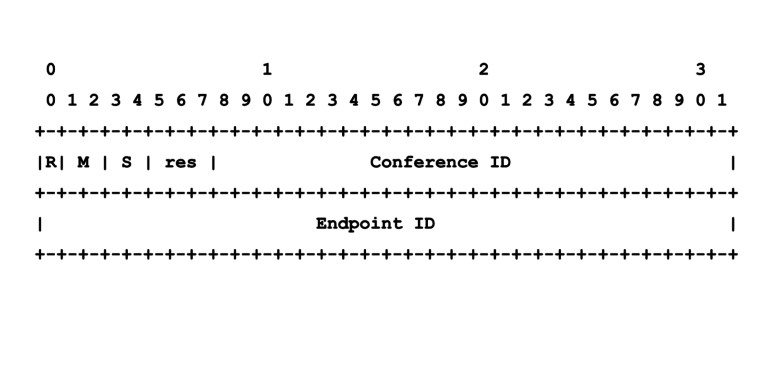 Octo header format
Octo header format
In Jitsi terminology, when a bridge is part of a conference with multiple bridges, it has an additional Octo channel (in fact, one channel for audio and one for video). This channel is responsible for sending / receiving media to / from other bridges. Each bridge is assigned a free port for Octo (4096 by default), so we need the Conference ID field to handle multiple conferences.
At the moment, the protocol has no built-in security mechanisms and we delegate this responsibility to the lower levels. This is the closest thing we will do in the near future, but for now the bridges should be on a secure network (for example, a separate AWS VPC instance).
Simulcast allows each participant to send multiple media streams with different bitrates, while the bridge helps determine which ones are needed. For this to work correctly, we transfer all simulcast streams between bridges. This allows you to quickly switch between threads, because the local bridge should not request a new stream. However, this is not optimal from the point of view of bridge-to-bridge traffic, since some streams are rarely used and only load bandwidth without any purpose.
We also wanted the opportunity to subscribe to the active participant / speaker of the conference. It turned out to be easy - we taught each bridge to independently determine the main participant, and then notify its local clients. This means that the definition occurs several times, but it is not expensive and allows you to simplify some points (for example, you do not need to decide which bridge should be responsible for DSI and worry about routing messages).
In the current implementation, this algorithm is simple. When a new participant joins the conference, Jicofo must determine which bridge to assign to him. This is done based on the region of the participant and the workload of the bridges. If there is a free bridge in the same region, then it is appointed. Otherwise, some other bridge is used.
Details about Octo, see the documentation .
For deployment we used Amazon AWS machines. We had servers (signaling and media) in 6 regions:
We used geo-referenced HAProxy instances to determine the region of the participant. The meet.jit.si domain is managed by Route53 and resolved into the HAProxy instance, which adds the region to the HTTP request headers. The header is later used as the value of a variable
The jitsi interface shows how many bridges are used and to which specific users are attached - for diagnostic and demonstration purposes. Hovering the cursor over the upper left corner of the local video will show the total number of servers and the server to which you are connected. Similarly, you can see the parameters of the second participant. You will also see the exchange time between your browser and the other party’s browser (parameter E2E RTT).
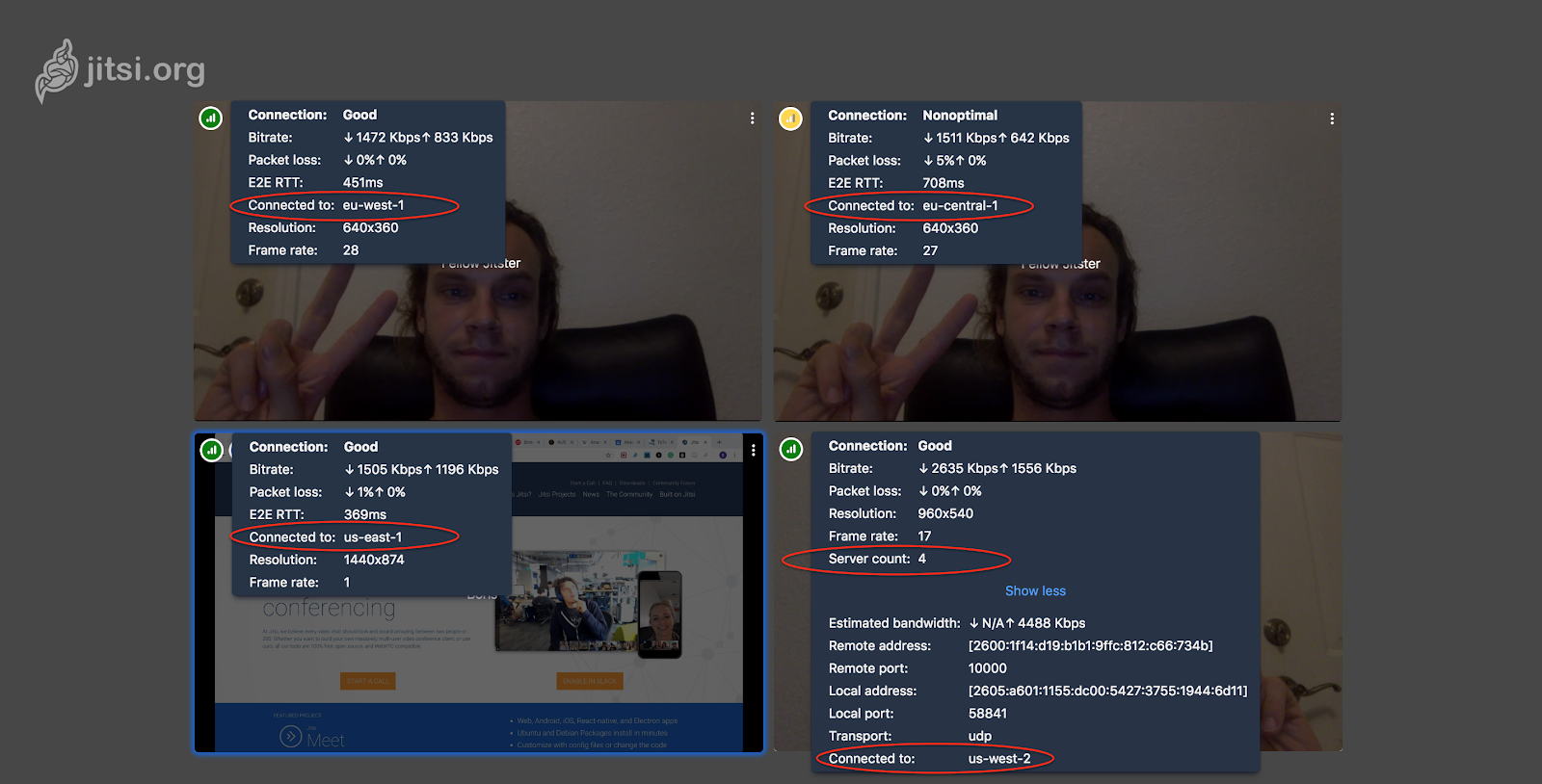
Looking at who is connected to which server, you can see if cascading is used.
Octo originally appeared as an A / B test. The first results were good, so now Octo is available to everyone. You will have to pass a lot of traffic through it and study the performance in more detail; it is also planned to use these developments to support even larger conferences (when one SFU is no longer enough).
Mouse neurons. Image NIHD ( CC-BY-2.0 )
Real-time communications are very sensitive to the network: bandwidth, latency and packet loss. Reducing the bitrate leads to lower video quality, a long network delay leads to a long delay for end users. Loss of packets can make the sound intermittent and lead to friezes in the video (due to dropped frames).
Therefore, it is very important for the conference to choose the best route between the end devices / users. When there are only two users, it’s easy - WebRTC uses the ICE protocolto establish a connection between the participants. If possible, the participants are connected directly, otherwise the TURN server is used. WebRTC can rezolvit domain name to get the address of the TURN server, so you can easily choose a local TURN based on DNS, for example, using the properties of AWS Route53 .
However, when the routing of multiple participants occurs through one central media server, the situation becomes complicated. Many WebRTC services use selective forwarding units (SFU) to more efficiently transfer audio and video between 3 or more participants.
Star problem
In the star topology, all participants connect to one server through which they exchange media streams. Obviously, the choice of server location is of great importance: if all participants are located in the USA, using a server in Sydney is not the best idea.
Many services use a simple approach that works well in most cases: they choose a server closer to the first participant of the conference. However, there are times when this solution is not optimal. Imagine that we have three participants from the image above. If the Australian (Caller C) is the first to connect to the conference, the algorithm will choose a server in Australia, however Server 1 in the USA will be the best choice, since He is closer to most participants.
The scenario described is not very frequent, but it does. If we assume that a user is connected in a random order, then the described situation occurs with ⅓ of all conferences with 3 participants, one of which is strongly removed.
Another and more frequent scenario: we have two groups of participants in different locations. In this case, the order of connection is unimportant, we will always have a group of closely located participants who are forced to exchange media with a remote server. For example, 2 participants from Australia (C & D) and 2 from the USA (A & B).
Switching to Server 1 is not optimal for C & D members. Server 2 is not optimal for A & B. That is, whatever server is used, there will always be participants connected to a remote (= non-optimal) server.
But if we did not have restrictions in one server? We could connect each participant to the nearest server, it would be necessary only to connect these servers.
Solution: Cascading
Let us postpone the question of how to connect the servers; let's first see what the effect will be.
The SFU connection between C and D has not changed - Server 2 is still used. For participants A and B, Server 1 is used, and this is obviously better. The most interesting thing is the connection between, for example, A and C: instead of A <=> Server 2 <=> C, the route A <=> Server 1 <=> Server 2 <=> C is used.
Implicit effect on the exchange rate
The SFU mix has its pros and cons. On the one hand, in the described situation, the exchange time between the participants becomes longer with the addition of new hops over the network. On the other hand, there is a decrease in this time when we are talking about the connection “client” - “the first server”, because we can restore the media stream with less delay according to the hop-by-hop principle.
How it works? WebRTC uses RTP (usually over UDP) to transfer media. This means that transport is unreliable. When a UDP packet is lost, you can ignore the loss or request retransmission (retransmission) using the RTCP NACK packet- the choice is already on the conscience of the application. For example, an application can ignore the loss of audio packets and request retransmission of some (but not all) video packets, depending on whether they are needed to decode subsequent frames or not.
RTP packet retransmission, single server
When there is a cascade, the retransmission can be limited to the local server, that is, it can be performed at each particular site. For example, in route A-S1-S2-C, if the packet is lost between A and S1, then S1 will notice and request a retransmission; similarly, with a loss between S2 and C. And even if the packet is lost between servers, the receiving party can also request retransmission.
RTP packet retransmission, two servers. Note that Server 2 does not request packet 2, because the NACK arrived shortly after sending the packet.
On the client, jitter buffer is used to delay the video playback and have time to receive delayed / retransmit packets. The buffer size dynamically changes depending on the exchange time between the parties. When hop-by-hop retransmissions occur, the delay decreases, and as a result, the buffer may be less - as a result, the total delay also decreases.
In short: even if the exchange time between participants is higher, it can reduce the delay in the transfer of media between participants. We have yet to study this effect in practice.
Introduce Cascading SFU: Jitsi Meet Case
Alarm vs. Media
Let's take a look at the alarm. From the very beginning, Jitsi Meet divided the concept of the alarm server ( Jicofo ) and the media server / SFU. This enabled cascading support to be relatively simple. First, we could handle all the alarm logic in one place; secondly, we already had a signaling protocol between Jicofo and the media server. We only needed to expand the functionality a bit: we already had multiple SFUs connected to one alarm server, we had to add the ability of one SFU to connect to multiple alarm servers.
As a result, two independent server pools appeared: one for jicofo instances, the other for media server instances, see the diagram:
An example of the organization of servers on AWS with the possibility of a cascade between different data centers.
The second part of the system is the bridge-to-bridge connection. We wanted to make this part as simple as possible, so there is no complex signaling between the bridges. All alarms go between jicofo and jitsi-videobridge; connection between bridges is used only for audio / video and data channel messages.
Octo protocol
To manage this interaction, we took the Octo protocol, which wraps RTP packets into simple fixed-length headers and also allows you to send a text message. In the current implementation, the bridges are connected in a full mesh topology (full mesh), however, other topologists are possible. For example, use a central server (a star for bridges) or a tree structure for each bridge.
Explanation: Instead of wrapping in an Octo header, you can use the RTP header extension, which will make the flows between bridges on pure (S) RTP. Future versions of Octo can use this approach.
Second explanation: Octo means nothing. At first we wanted to use a central server, and this reminded us of an octopus. So the name for the project appeared.
In Jitsi terminology, when a bridge is part of a conference with multiple bridges, it has an additional Octo channel (in fact, one channel for audio and one for video). This channel is responsible for sending / receiving media to / from other bridges. Each bridge is assigned a free port for Octo (4096 by default), so we need the Conference ID field to handle multiple conferences.
At the moment, the protocol has no built-in security mechanisms and we delegate this responsibility to the lower levels. This is the closest thing we will do in the near future, but for now the bridges should be on a secure network (for example, a separate AWS VPC instance).
Simulcast
Simulcast allows each participant to send multiple media streams with different bitrates, while the bridge helps determine which ones are needed. For this to work correctly, we transfer all simulcast streams between bridges. This allows you to quickly switch between threads, because the local bridge should not request a new stream. However, this is not optimal from the point of view of bridge-to-bridge traffic, since some streams are rarely used and only load bandwidth without any purpose.
Selection of the active participant
We also wanted the opportunity to subscribe to the active participant / speaker of the conference. It turned out to be easy - we taught each bridge to independently determine the main participant, and then notify its local clients. This means that the definition occurs several times, but it is not expensive and allows you to simplify some points (for example, you do not need to decide which bridge should be responsible for DSI and worry about routing messages).
Bridge selection
In the current implementation, this algorithm is simple. When a new participant joins the conference, Jicofo must determine which bridge to assign to him. This is done based on the region of the participant and the workload of the bridges. If there is a free bridge in the same region, then it is appointed. Otherwise, some other bridge is used.
Details about Octo, see the documentation .
Expand Cascade SFU
For deployment we used Amazon AWS machines. We had servers (signaling and media) in 6 regions:
- us-east-1 (Northern Virginia);
- us-west-2 (Oregon);
- eu-west-1 (Ireland);
- eu-central-1 (Frankfurt);
- ap-se-1 (Singapore);
- ap-se-2 (Sydney).
We used geo-referenced HAProxy instances to determine the region of the participant. The meet.jit.si domain is managed by Route53 and resolved into the HAProxy instance, which adds the region to the HTTP request headers. The header is later used as the value of a variable
config.deploymentInfo.userRegionthat is available on the client through the file /config.js. The jitsi interface shows how many bridges are used and to which specific users are attached - for diagnostic and demonstration purposes. Hovering the cursor over the upper left corner of the local video will show the total number of servers and the server to which you are connected. Similarly, you can see the parameters of the second participant. You will also see the exchange time between your browser and the other party’s browser (parameter E2E RTT).
Looking at who is connected to which server, you can see if cascading is used.
Conclusion
Octo originally appeared as an A / B test. The first results were good, so now Octo is available to everyone. You will have to pass a lot of traffic through it and study the performance in more detail; it is also planned to use these developments to support even larger conferences (when one SFU is no longer enough).