Centrifugo - 3.5 million rpm

Last time I wrote about Centrifugo a little over a year ago. The time has come to recall the existence of the project and tell what happened during this period of time. So that the article does not slip into a boring enumeration of changes, I will try to focus on some Go libraries that helped me with the development - perhaps you will learn something useful for yourself.
The best part is that this year a decent number of projects using Centrifugo in battle have appeared - and each such story is very inspiring. At the moment, the largest Centrifuge installation I know of is:
- 300 thousand users online
- 3.5 million fan-out messages per minute
- 4 Centrifugo nodes on Amazon c4.xlarge
- nodes are connected by the PUB / SUB mechanism of a single instance of Redis
- CPU consumption an average of 40%
By tradition, I must remind you of what I am writing to you here. I'll try to simplify my life and quote a last post :
Centrifugo is a server that works next to the backend of your application (the backend can be written in any language / framework). Application users connect to the Centrifuge using the Websocket protocol or the SockJS polyphile library. Having connected and logged in using the HMAC token (received from the application backend), they subscribe to the channels of interest. Having learned about a new event, the application backend sends it to the necessary channel in the Centrifuge using the HTTP API or the queue in Redis. The centrifuge, in turn, instantly sends a message to all connected interested (subscribed to the channel) users.
A year ago, the latest version was 1.4.2, and now 1.7.3 - a lot of work has been done.
Last year, the Centrifuge received HTTP / 2 support. It cost me a lot of work and many hours of work. Just kidding :) With the release of Go 1.6, projects on Go got HTTP / 2 support automatically. In fact, for Centrifugo, where the main transport is still a Websocket, HTTP / 2 support may seem useless. However, this is not entirely true - after all, Centrifugo is also a SockJS server. SockJS provides fallback to transports using the HTTP protocol (Eventsource, XHR-streaming, etc.) in case the browser cannot establish a Websocket connection for some reason. Well, or in case you for some reason do not want to use Websocket. For many years we struggled with the limit on constant connections to one host, which the HTTP specification sets (in reality, 5-6 depending on the browser), and now the time has come, when thanks to HTTP / 2, connections from different browser tabs are multiplexed into one. Tabs with persistent HTTP connections can now be opened a lot. So understand - what kind of transport is currently better for a more unidirectional stream of real-time messages from the server to the client - Websocket or something like Eventsource on top of HTTP / 2.
A little later, another interesting innovation appeared regarding the HTTP server - support for automatically receiving an HTTPS certificate with Let's Encrypt. Again I would like to say that I had to sweat, but no - thanks to the golang.org/x/crypto/acme/autocert package , writing a server that can work with Let's Encrypt is a matter of several lines of code:
manager := autocert.Manager{
Prompt: autocert.AcceptTOS,
HostPolicy: autocert.HostWhitelist("example.org"),
}
server := &http.Server{
Addr: ":https",
TLSConfig: &tls.Config{GetCertificate: manager.GetCertificate},
}
server.ListenAndServeTLS("", "")
In version 1.5.0, an important change was the fact that protobuf began to fly between the Centrifuge and Radish instead of JSON. To work with protobuf, I took the github.com/gogo/protobuf library - due to code generation and refusal to use the reflect package, the speed of serialization and deserialization is just outrageous. Especially compared to JSON:
BenchmarkMsgMarshalJSON 2022 ns/op 432 B/op 5 allocs/op
BenchmarkMsgMarshalGogoprotobuf 124 ns/op 48 B/op 1 allocs/op
At first, protobuf version 2 was used, but a bit later it turned out to switch to the current version 3.
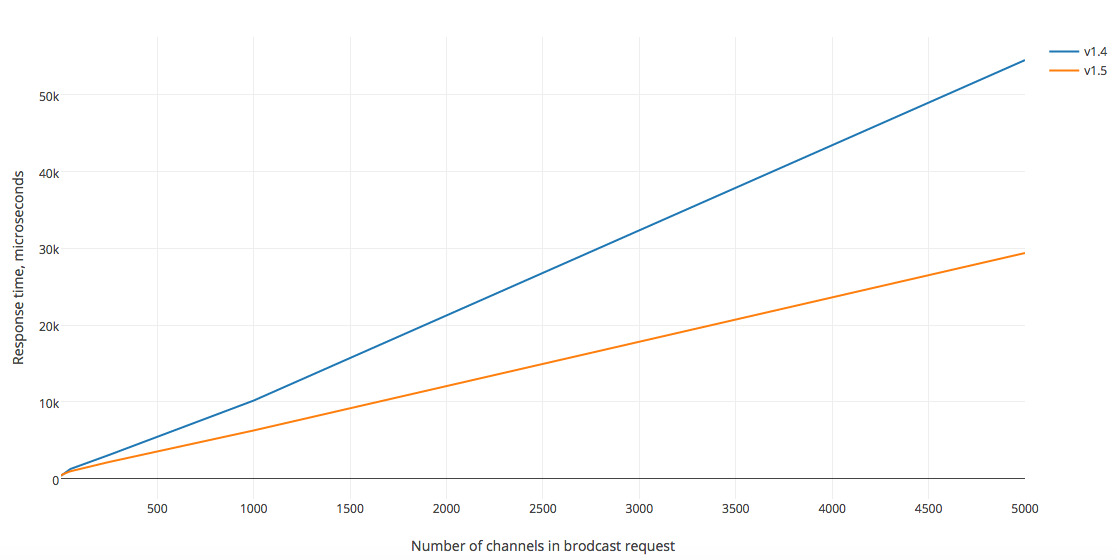
The graph shows how much less time it takes to process a request in version 1.5 using protobuf. Moreover, the more complex the request and the more data (the more channels to which you want to publish messages) it contains, the more noticeable the difference.
To add protobuf support to your Go project, just write a proto file similar to this one:
syntax = "proto3";
package proto;
import"github.com/gogo/protobuf/gogoproto/gogo.proto";
option (gogoproto.equal_all) = true;
option (gogoproto.populate_all) = true;
option (gogoproto.testgen_all) = true;
message Message {
string UID = 1 [(gogoproto.jsontag) = "uid"];
string Channel = 2 [(gogoproto.jsontag) = "channel"];
bytes Data = 3 [(gogoproto.customtype) = "github.com/centrifugal/centrifugo/libcentrifugo/raw.Raw", (gogoproto.jsontag) = "data", (gogoproto.nullable) = false];
}
As you can see - in the proto-file there is an opportunity to use not only the basic types, but also your custom types.
After the proto-file is written, all that remains is to set protoc on this file ( you can download it from the release page) using one of the code generators provided by the library
gogoprotobuf- as a result, a file with all the necessary methods for serializing and deserializing the described structures will be created. If you are interested in reading more about this, then here is an article , though in English. I also experimented a lot with alternative JSON parsers for deserializing API messages - ffjson , easyjson , gjson , jsonparser. He showed the best performance
jsonparser- it really speeds up JSON parsing by the declared 10 times and practically does not allocate memory. However, I did not dare to add it to Centrifugo - until it became a bottleneck I did not want to step aside from using the standard library. However, it is nice to realize that there is an opportunity to significantly improve the performance of parsing JSON data. JSON is also used to communicate with the client - in some particularly hot areas (for example, for new messages in the channel) I do not create JSON using the function
Marshal, but manually, it looks something like this:funcwriteMessage(buf *bytebufferpool.ByteBuffer, msg *Message) {
buf.WriteString(`{"uid":"`)
buf.WriteString(msg.UID)
buf.WriteString(`",`)
buf.WriteString(`"channel":`)
EncodeJSONString(buf, msg.Channel, true)
buf.WriteString(`,"data":`)
buf.Write(msg.Data)
buf.WriteString(`}`)
}The library github.com/valyala/bytebufferpool is used - it provides a pool of [] byte buffers to further reduce the number of memory allocations.
I also recommend the wonderful library github.com/nats-io/nuid - in the Centrifuge, each message receives a unique id, this library from the Nats.io developers allows you to generate unique identifiers very quickly. However, it is worth considering that you can use it only where you are not afraid that the attacker will be able to calculate the next id from the existing one. But in many places this library can be a good replacement for uuid.
Version 1.6.0 was the result of a complete refactoring of the server code that I worked on for about three months - this is where I really had to sweat. I still saw the Centrifuge during off-hours, so these 3 months are actually not so much translated into pure time. But still.
The result of refactoring was the separation of the code into small packages with a clear public API and interaction among themselves - before that, all the code for the most part lay in one folder. It also turned out to make certain parts of the server replaceable at the initialization stage. Now that almost half a year has passed since then, I won’t say that this breakdown into separate small packages had any significant impact or gave tangible benefits afterwards - no, there was nothing like that. But, most likely, this makes it easier to read the code for other programmers - who are not familiar with the project from the very first days.
In the process of refactoring, it was possible to significantly improve some parts of the code - for example, metrics, which now somewhat resemble how the addition of metrics is arranged in the Prometheus client for Go.
The centrifuge uses the github.com/spf13/viper package for configuration - this is one of the best libraries for configuring the application I have worked with - since with minimal effort the programmer can configure the application using environment variables, flags at startup and a settings file (using popular formats - YAML, JSON, TOML, etc.) + viper works in conjunction with github.com/spf13/cobra - one of the most convenient packages for creating cli-utilities. But there is one big BUT! Viper pulls some exorbitant amount of external dependenciessome of which pull their own - most of which are not used at all in Centrifugo at all - remote configuration (Consul, Etcd), support for the afero, fsnotify file system (who needs the server application to restart automatically when changing the config on the disk?), HCL and Java configuration file formats are also not needed. Therefore, I had to fork viper and make my own “lite” version, in which there are no dependencies unnecessary to me. Actually, this is not the best option - I would like viper to support plugins and library users themselves to determine at the initialization stage what pieces of functionality they need.
In version 1.6, Redis sharding by channel name was added to distribute the load among several Redis instances. I was always confused by the restriction to a single instance of Redis - although it is extremely fast in operations that the Centrifuge uses, I still wanted to have a way to scale this point. Now with the presence of sharding instead of just such a scheme:
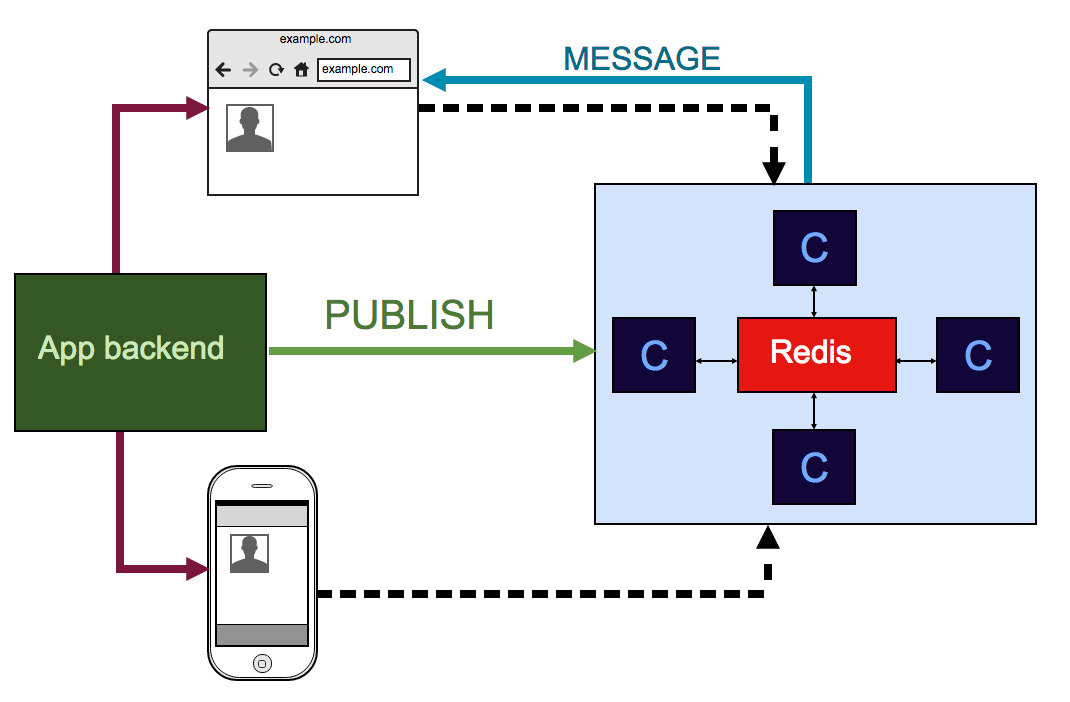
We get this:
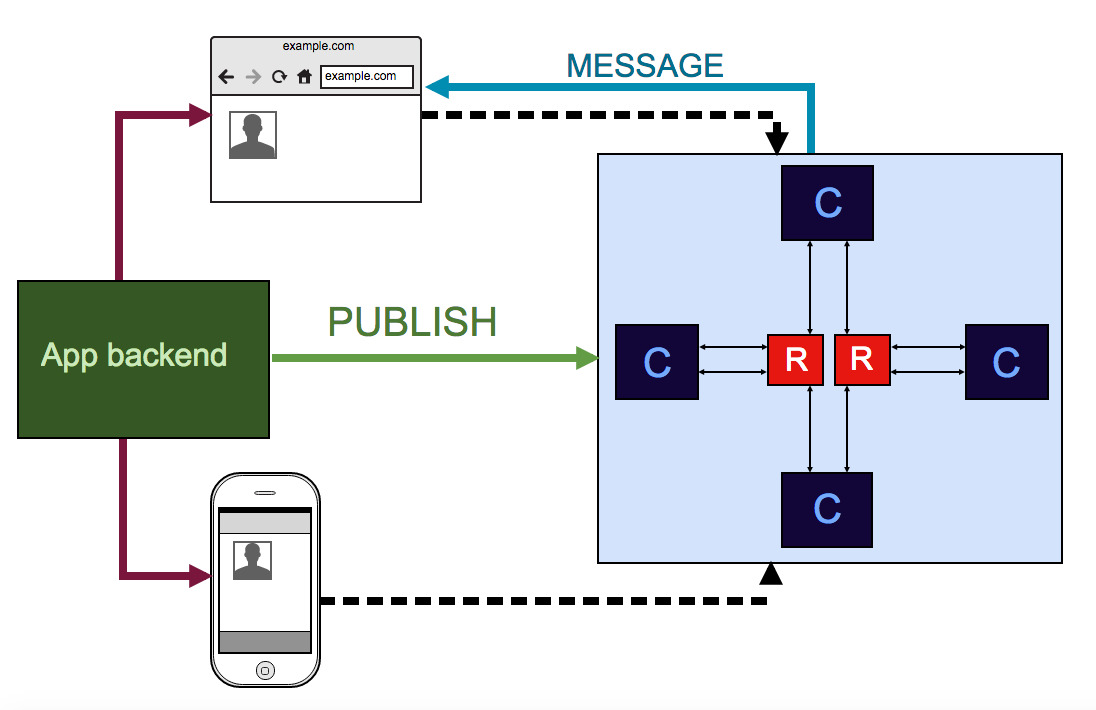
Unfortunately without re-matching, but in the case of the Centrifuge, re-striding is not so important in fact - the message delivery model is already at most once, but thanks to how the Centrifuge works , the state itself is restored after some time. Inside, a fast and not memory-allocating consistent sharding algorithm is used, which is called Jump - code from the library is usedgithub.com/dgryski/go-jump . More recently, the story of the successful use of sharding in production has appeared - in a Mesos environment with three shards. However, in some of my projects I have not yet been able to use sharding.
Perhaps you know that the Centrifuge has a web interface written in ReactJS, this interface lies in a separate repository and is embedded into the server at the build stage. Thus, the binary includes all the statics necessary for the web-interface to work - the Go FileServer built-in allows you to easily send statics to the desired address. Initially, I used github.com/jteeuwen/go-bindata in conjunction with github.com/elazarl/go-bindata-assetfs for these purposes . However, I came across a lighter and simpler library in my opiniongithub.com/rakyll/statik is from Jaana B. Dogan, a well-known Go community.
Finally, the last thing I would like to note from the server changes is the integration with the PreparedMessage structure from the Gorilla Websocket library. Has appeared
PreparedMessagein the Gorilla Websocket library just recently. The essence of this structure is that it caches the created websocket frame in order to reuse it whenever possible and not to create it every time. In the case of the Centrifuge, when there can be thousands of users in the channel and everyone sends the same message to the connection, this makes sense with a sufficiently large number of users (in my benchmarks, the gain appeared when the number of customers> 20k in one channel). But it makes even more sense when the compression of Websocket traffic is turned on - in the case of the Websocket protocol this is the extension permessage-deflate , which allows you to compress traffic using flate- compression. Go structureflate.WriterIt weighs more than 600kb (!), so with a large fan-out message (regardless of the number of clients in the channel) - PreparedMessageit helps a lot. A little sore point is customers for mobile devices. Since I do not know either Objective-C / Swift or Java at a sufficient level, I cannot help developing mobile clients for Centrifugo that allow connecting to the server with iOS and Android devices. These clients were written by members of the open-source community, for which I am immensely grateful to them. However, by writing clients, the authors, by and large, have lost interest in their support - and some features are still missing there. However, these are working clients who have proved the possibility of using the Centrifuge from mobile devices.
This situation cannot but upset me - therefore, for my part, I took a step to try writing a client on Go and use Gomobile to generate client bindings for iOS (Objective-C / Swift) and Android (Java). Well, in general, I did it - github.com/centrifugal/centrifuge-mobile . It was fascinating - the most difficult part was to try the bindings obtained in practice - for this I had to learn Xcode and Android Studio, as well as write small examples of using the Websocket Centrifuge client for all three languages - Objective-C, Swift and Java. About the features of Gomobile, I wrote an article - maybe someone will be interested in the details.
 Among the shortcomings of gomobile, I would like to note not even strict restrictions on supported types (which you can actually live with), but the fact that Go does not generate LLVM bitcode, which Apple recommends adding to each application. This bitcode in theory allows Apple to independently optimize applications in the App Store. At the moment, when creating an application for iOS, you can disable the bitcode in the project settings in Xcode, but what happens if Apple decides to make it mandatory? Unclear. And the lack of control over the situation is a little sad.
Among the shortcomings of gomobile, I would like to note not even strict restrictions on supported types (which you can actually live with), but the fact that Go does not generate LLVM bitcode, which Apple recommends adding to each application. This bitcode in theory allows Apple to independently optimize applications in the App Store. At the moment, when creating an application for iOS, you can disable the bitcode in the project settings in Xcode, but what happens if Apple decides to make it mandatory? Unclear. And the lack of control over the situation is a little sad.The most surprising thing for me is that I only found out about it when my library code was ready, tested on an Android device and I was completely sure that everything would go smoothly on iOS too - nowhere in the gomobile documentation did I mention this found (distracted and overlooked?).
That's basically all of the highlights. Try Centrifugo is not difficult - there are packages for popular Linux distributions, Docker image, binary releases and a couple of lines to put on MacOS using brew - all useful links can be found in README on Github.