How to love machine learning and stop suffering
- Tutorial
Our future is becoming increasingly associated with the development of artificial intelligence. Someone believes that this is the end of the era of mankind, and someone sits down, takes courses and saws the code to deal with machine learning. I belong to the second category. At one time, when I thought about mastering this science and started taking the first courses, I wanted to give up. The complexity of materials and suffering seemed to have no limit. Now, from the height of my experience, I understand that all of this could have been avoided. Therefore, under the cut, I want to share the basics of ML for beginners "without pain."

I took a Machine Learning course of my own free will. In the first lesson, we were told that an annual matan course, as well as a basic understanding of Python, would be enough for a normal course development. Sounds wonderful! Until it comes to the realization that the program at different universities is different. Linear algebra, discrete mathematics, asymptotic analysis, and so on, accidentally fell into the phrase "annual matan course".
About what is a "basic understanding of Python", I was also very mistaken. “This is one of the simplest languages!” - claimed all around. You can read good code as fiction. And I believed my friends, because, having not written anything in Python before, I myself often preferred to read on it the implementation of different algorithms. After all, he is so concise and perfectly conveys the essence.
The only problem is that reading the code and writing yourself are different tasks. Starting to write good Python code right away is a big problem (sorry for captaining).
After much suffering and attempts to learn the first dynamic interpreted language in my life, I have come a moment of happiness and pride. As you may have guessed, the moment was short-lived. Almost immediately, the realization came to me that this was not enough. Having learned to write at least somehow in python, it is necessary to retrain in order to correctly use the machine learning libraries. I heard that for many this does not cause much difficulty. Some may not even notice this stage. But it was very difficult for me at first to quickly master the standard collections and love them wholeheartedly, and then find out that the ML libraries have their own opinion on this matter. They are completely uninterested in how convenient and easy to use cute pet lists and dictionaries are. The numpy library is alien to any human feelings.
As you already understood, the course was catastrophically difficult for me. I could hardly pass the first part of the course, getting a rating of “satisfactory”. The course consisted of 2 parts and was designed for a year, but I decided not to hurt myself even more. I have an extremely depressing opinion about all machine learning in general. In all seriousness, I decided that it was just not for me.
However, like all other wounds, this one dragged on over time. Recently, I have increasingly begun to read various articles on how people conquer new heights using different methods of machine learning. Beautiful mysteries of galaxies or vital issues of medicine - we have a chance to get closer to solving them, just by teaching the computer to think in the right direction. This thought haunts me, and so I decided to try again, at the same time filling you with motivation.
If you are at the beginning of my journey, start with a simple one. For the first attempts, no deep knowledge in mathematics is needed. When I got to Microsoft, it came as a surprise to me that today you may not even be able to write code to learn ML. Let's walk along the general path, at the same time find the basic solution for a simple task.
Make yourself an account on Azure ML Studio. There is a free quota, without linking a bank card, for several attempts. All the algorithms and necessary procedures are implemented for us, and even more cool - everything will work quickly even on a weak laptop. All calculations take place in the cloud.
You can fill in your data, but for a start, the suggested samples are perfect for us. I chose a dataset about flight delays. Having a trained model, it will be possible to tell friends, for example, that their flight may be delayed ... (Although, if I want to stay alive, I will need to come up with a different application method)
In order to view the available datasets, click on Datasets → Samples :
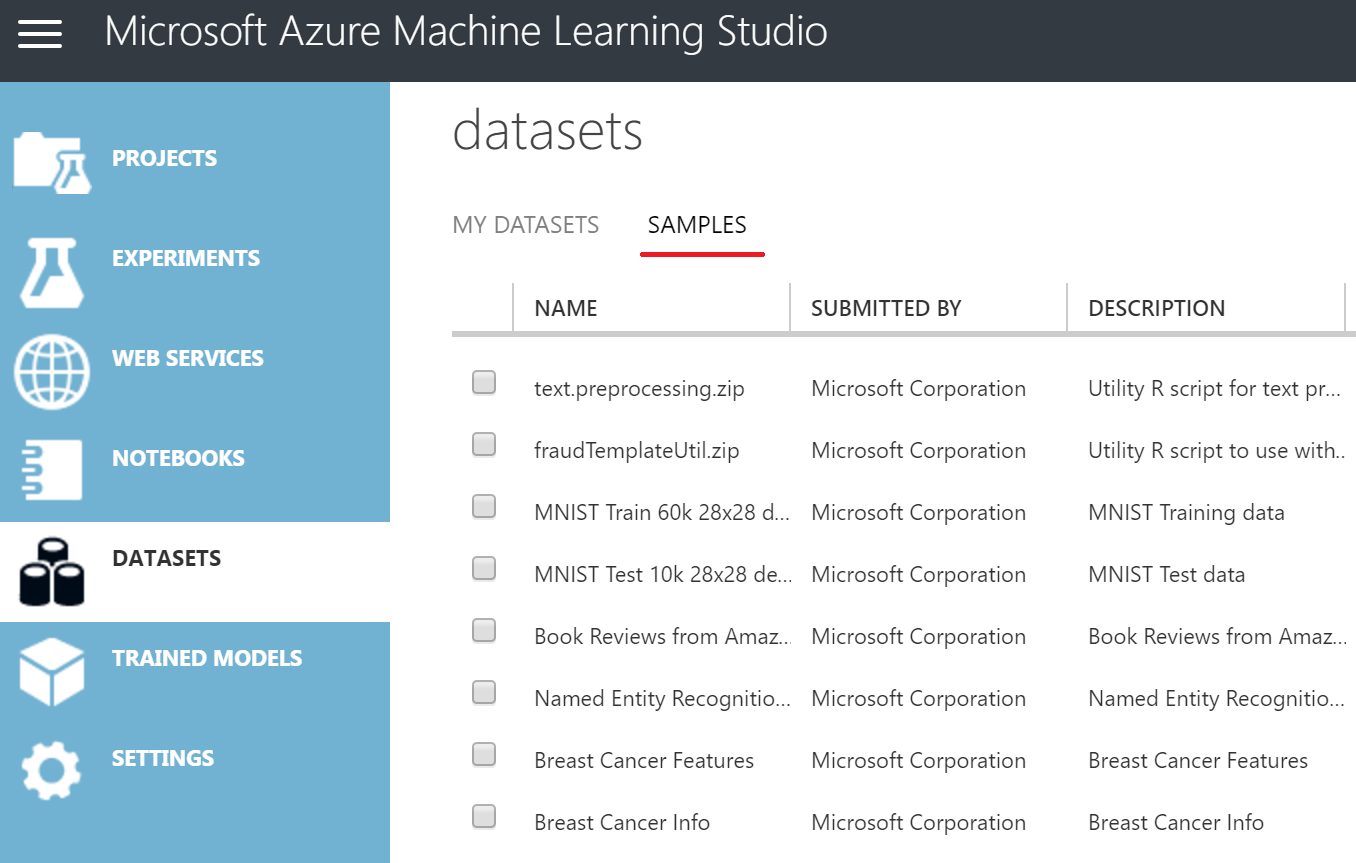
I have selected The dataset is called Flight Delays Data .
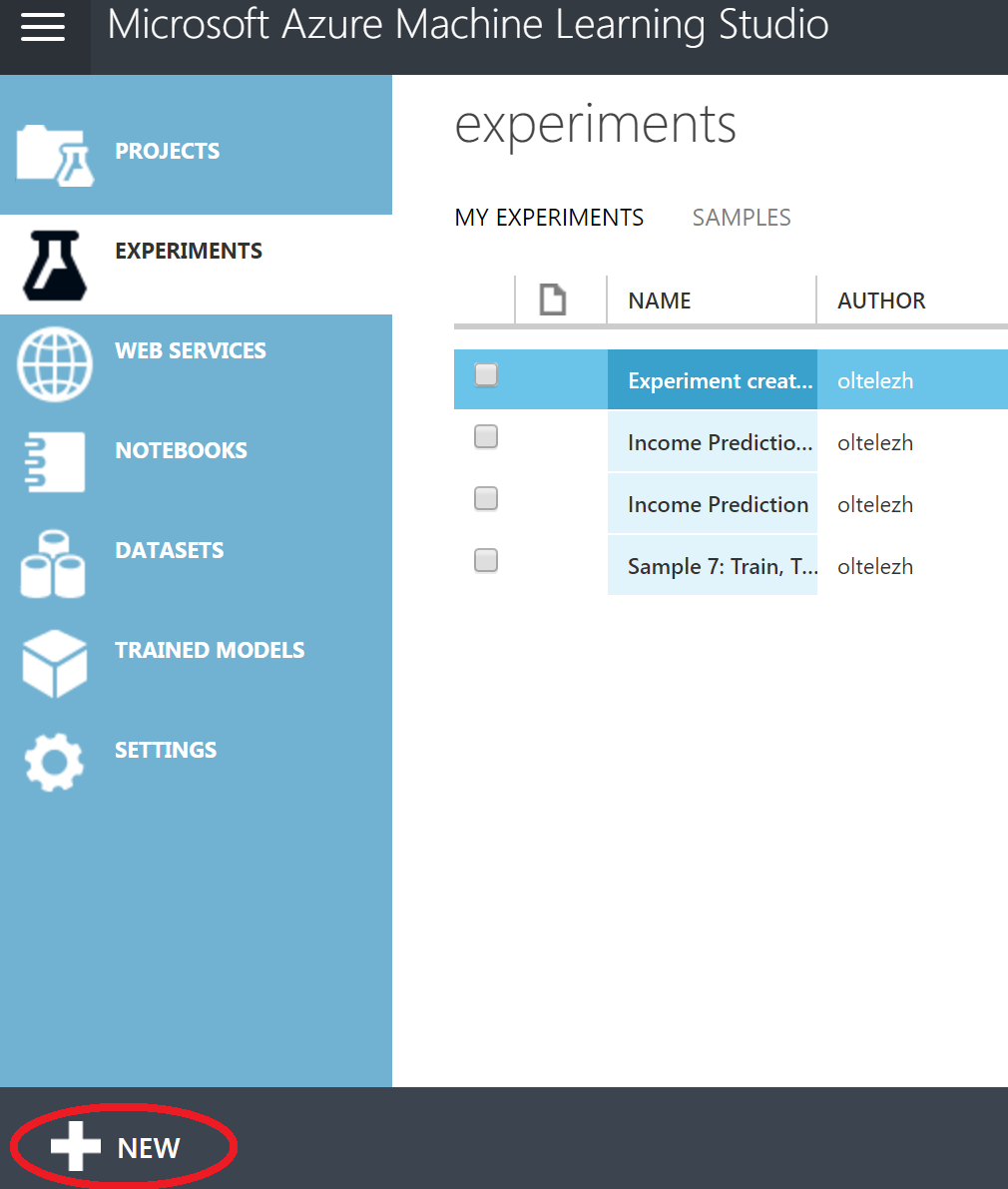
Let's create your experiment. To do this, click Experiment → New (at the bottom of the page) → Blank Experiment . By the way, the experiments also have a Samples tab, where you can study ready-made models. But now it’s more interesting for us to do everything ourselves.
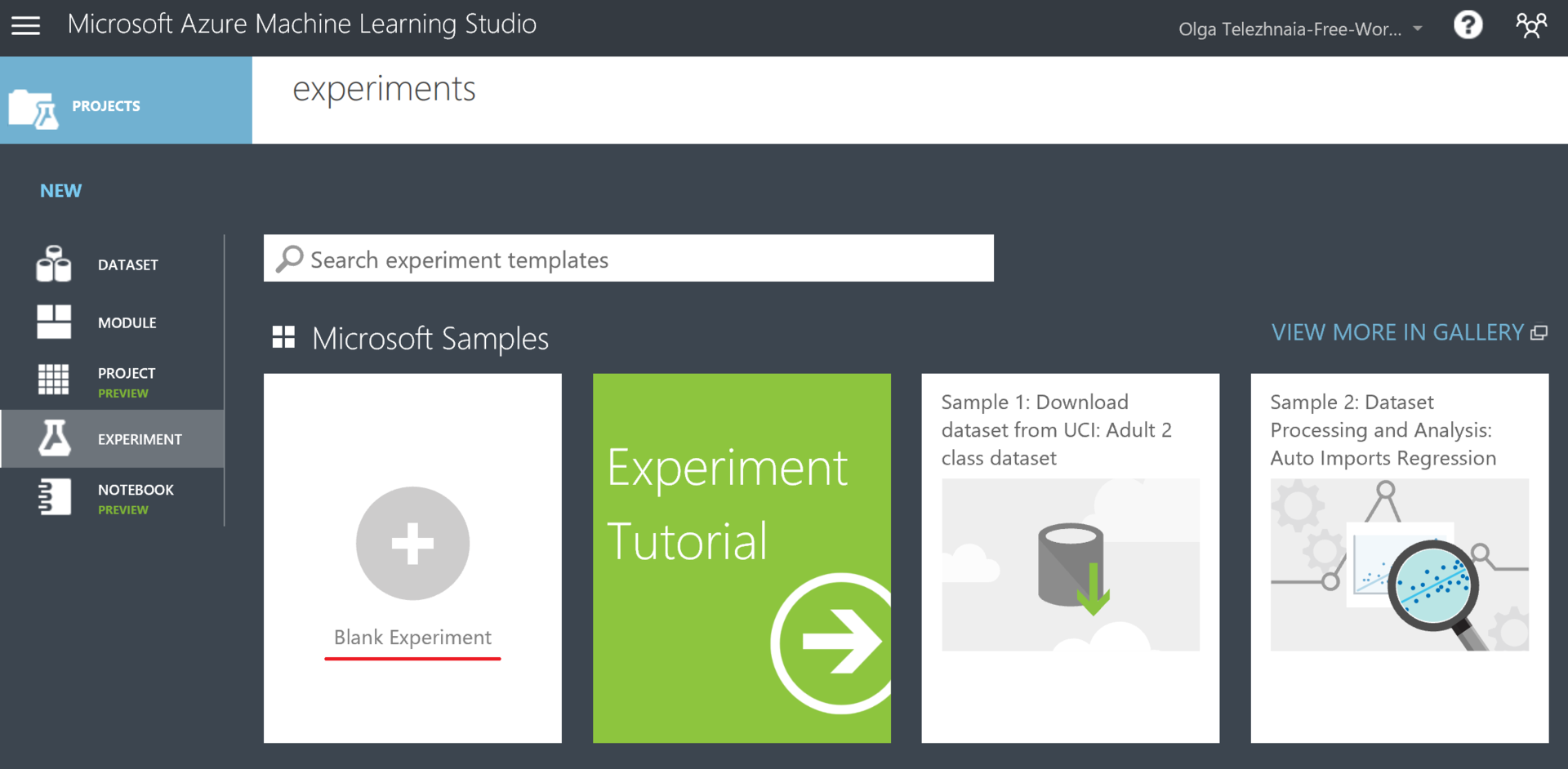
The Azure ML platform pleasantly surprised me with its flexibility and unobtrusiveness. In this article, I wanted to show that machine learning is accessible to everyone. The whole further process of work with us will look like "they selected the necessary blocks, threw them onto the work surface, logically connected, started, rejoice."
If you feel confident, you can create your own blocks, for this you need to write program code in Python or R. If you already have an army of trained models behind your back, then you are probably familiar and comfortable with the Jupyter Notebook, and you can work with Azure ML through him.
Even if you have an acute allergy to the web interface, but you want to taste the advantages of the cloud, the developers even took into account this situation and made it possible to connect to Azure through the console. More detailshere .
Back to our model. We will take all the necessary blocks in the menu on the left. They are conveniently divided into groups. During the first attempts, I advise you to search for the right one, while studying the neighboring sections along the way. But if you know the approximate name of the desired block, then you can use the search.
The classic scenario for applying the machine learning algorithm is as follows:
Of course, I simplified the process as much as possible. The art of preparing data, dividing it into parts, choosing an algorithm and measuring quality has been honed for years. Nevertheless, the fact of “assembling a model from scratch in just 10 minutes” gives me a second wind and revives a huge interest in this topic. But what if I take not Random Forest, but SVM? By the way, do you know how these algorithms differ? Both have a huge mathematical base and a rather complicated implementation, but everyone can understand the general idea. There would be a desire ;-) By the way, you can start by studying this cheat sheet .
I hope that my article will help you to avoid suffering and fall in love with ML, just like me. Share your opinion and experience in the comments, it will be interesting to chat!
If you would be interested in an article for beginners on a more specific topic, report it in the comments and I will try to share my experience in more detail. You can also read the article by Evgeny Grigorenko , in it you will find more practical scenarios aimed at more experienced users.
Library numpy alien to any human feelings
I took a Machine Learning course of my own free will. In the first lesson, we were told that an annual matan course, as well as a basic understanding of Python, would be enough for a normal course development. Sounds wonderful! Until it comes to the realization that the program at different universities is different. Linear algebra, discrete mathematics, asymptotic analysis, and so on, accidentally fell into the phrase "annual matan course".
About what is a "basic understanding of Python", I was also very mistaken. “This is one of the simplest languages!” - claimed all around. You can read good code as fiction. And I believed my friends, because, having not written anything in Python before, I myself often preferred to read on it the implementation of different algorithms. After all, he is so concise and perfectly conveys the essence.
The only problem is that reading the code and writing yourself are different tasks. Starting to write good Python code right away is a big problem (sorry for captaining).
After much suffering and attempts to learn the first dynamic interpreted language in my life, I have come a moment of happiness and pride. As you may have guessed, the moment was short-lived. Almost immediately, the realization came to me that this was not enough. Having learned to write at least somehow in python, it is necessary to retrain in order to correctly use the machine learning libraries. I heard that for many this does not cause much difficulty. Some may not even notice this stage. But it was very difficult for me at first to quickly master the standard collections and love them wholeheartedly, and then find out that the ML libraries have their own opinion on this matter. They are completely uninterested in how convenient and easy to use cute pet lists and dictionaries are. The numpy library is alien to any human feelings.
As you already understood, the course was catastrophically difficult for me. I could hardly pass the first part of the course, getting a rating of “satisfactory”. The course consisted of 2 parts and was designed for a year, but I decided not to hurt myself even more. I have an extremely depressing opinion about all machine learning in general. In all seriousness, I decided that it was just not for me.
However, like all other wounds, this one dragged on over time. Recently, I have increasingly begun to read various articles on how people conquer new heights using different methods of machine learning. Beautiful mysteries of galaxies or vital issues of medicine - we have a chance to get closer to solving them, just by teaching the computer to think in the right direction. This thought haunts me, and so I decided to try again, at the same time filling you with motivation.
Where to begin
If you are at the beginning of my journey, start with a simple one. For the first attempts, no deep knowledge in mathematics is needed. When I got to Microsoft, it came as a surprise to me that today you may not even be able to write code to learn ML. Let's walk along the general path, at the same time find the basic solution for a simple task.
Make yourself an account on Azure ML Studio. There is a free quota, without linking a bank card, for several attempts. All the algorithms and necessary procedures are implemented for us, and even more cool - everything will work quickly even on a weak laptop. All calculations take place in the cloud.
You can fill in your data, but for a start, the suggested samples are perfect for us. I chose a dataset about flight delays. Having a trained model, it will be possible to tell friends, for example, that their flight may be delayed ... (Although, if I want to stay alive, I will need to come up with a different application method)
In order to view the available datasets, click on Datasets → Samples :
I have selected The dataset is called Flight Delays Data .
Let's create your experiment. To do this, click Experiment → New (at the bottom of the page) → Blank Experiment . By the way, the experiments also have a Samples tab, where you can study ready-made models. But now it’s more interesting for us to do everything ourselves.
The Azure ML platform pleasantly surprised me with its flexibility and unobtrusiveness. In this article, I wanted to show that machine learning is accessible to everyone. The whole further process of work with us will look like "they selected the necessary blocks, threw them onto the work surface, logically connected, started, rejoice."
If you feel confident, you can create your own blocks, for this you need to write program code in Python or R. If you already have an army of trained models behind your back, then you are probably familiar and comfortable with the Jupyter Notebook, and you can work with Azure ML through him.
Even if you have an acute allergy to the web interface, but you want to taste the advantages of the cloud, the developers even took into account this situation and made it possible to connect to Azure through the console. More detailshere .
Back to our model. We will take all the necessary blocks in the menu on the left. They are conveniently divided into groups. During the first attempts, I advise you to search for the right one, while studying the neighboring sections along the way. But if you know the approximate name of the desired block, then you can use the search.
Predict flight delays
The classic scenario for applying the machine learning algorithm is as follows:
- We find good data and make them even better. We clean from garbage, add useful information.
Let me remind you, we chose a flight dataset.
Drag the desired block onto the work surface.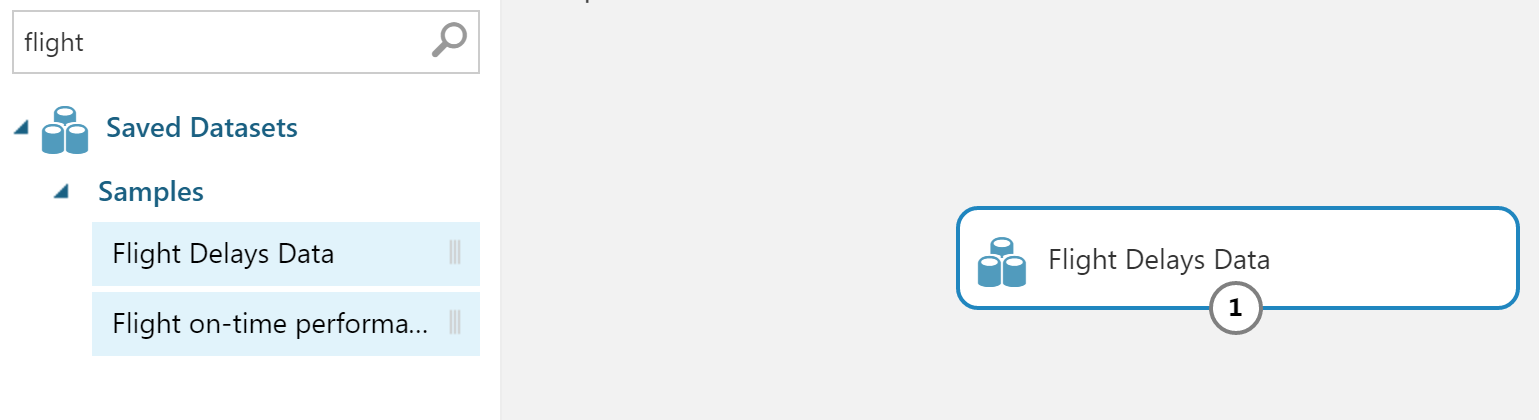
Better study and prepare the data. To do this, right-click on the exit from the block and select Visualize: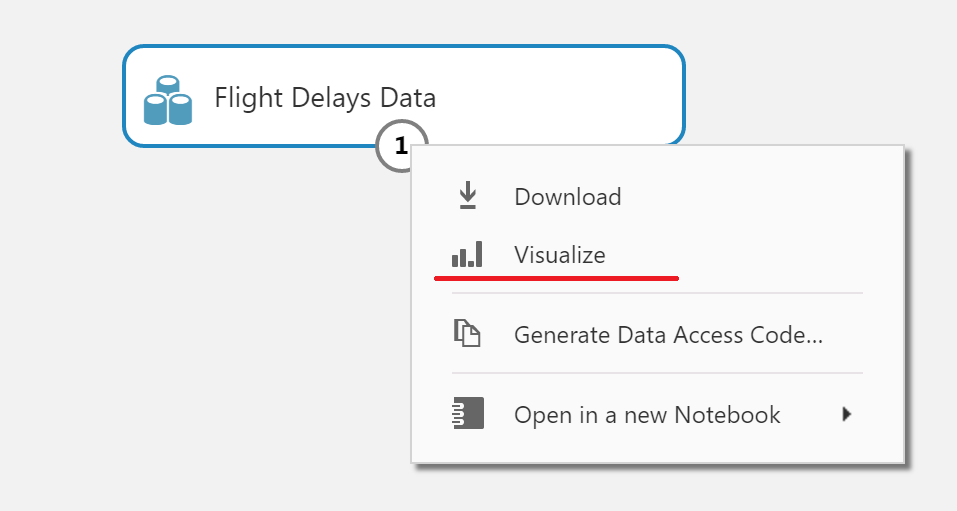
We see a beautiful table.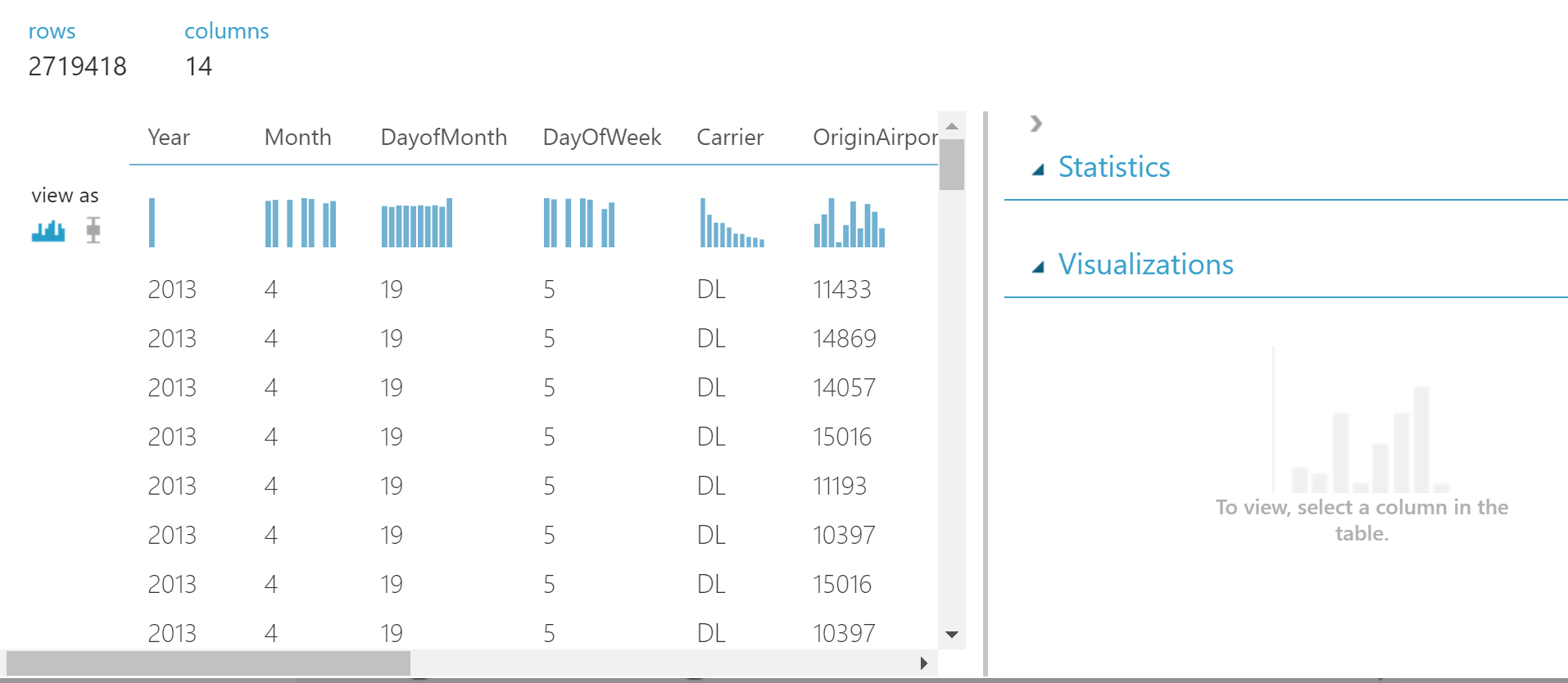
We can click on any column and see statistics for it.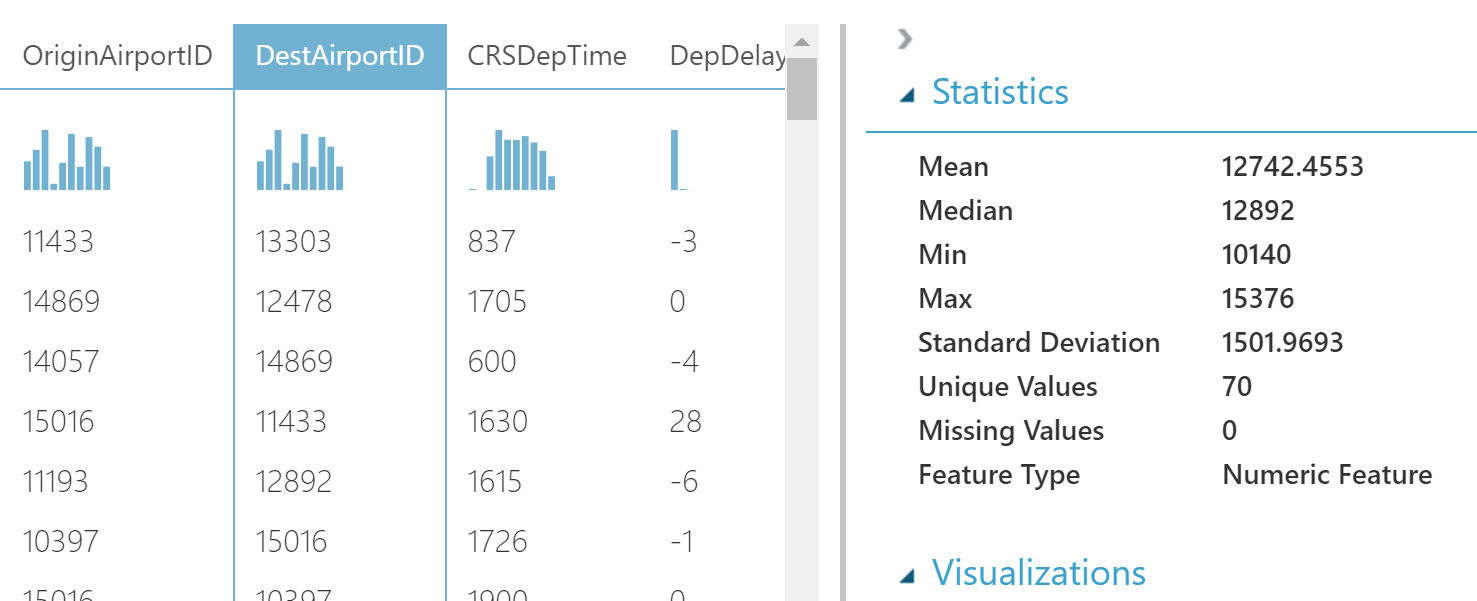
Studying the data, I found the DepDelay and DepDel15 columns. They contain gaps, and so I decided to delete these columns.
I plan to predict a binary sign - is it true that the plane will be more than 15 minutes late. The ArrDel15 column is responsible for it. In addition to her, there is also an ArrDelay column, which stores latency in minutes. Unfortunately, we are forced to delete it, otherwise the experiment will not be completely honest)
To remove the columns, select the Select Columns in Dataset block, connect it to the previous block, and then click on the Launch column selector button in the menu on the right.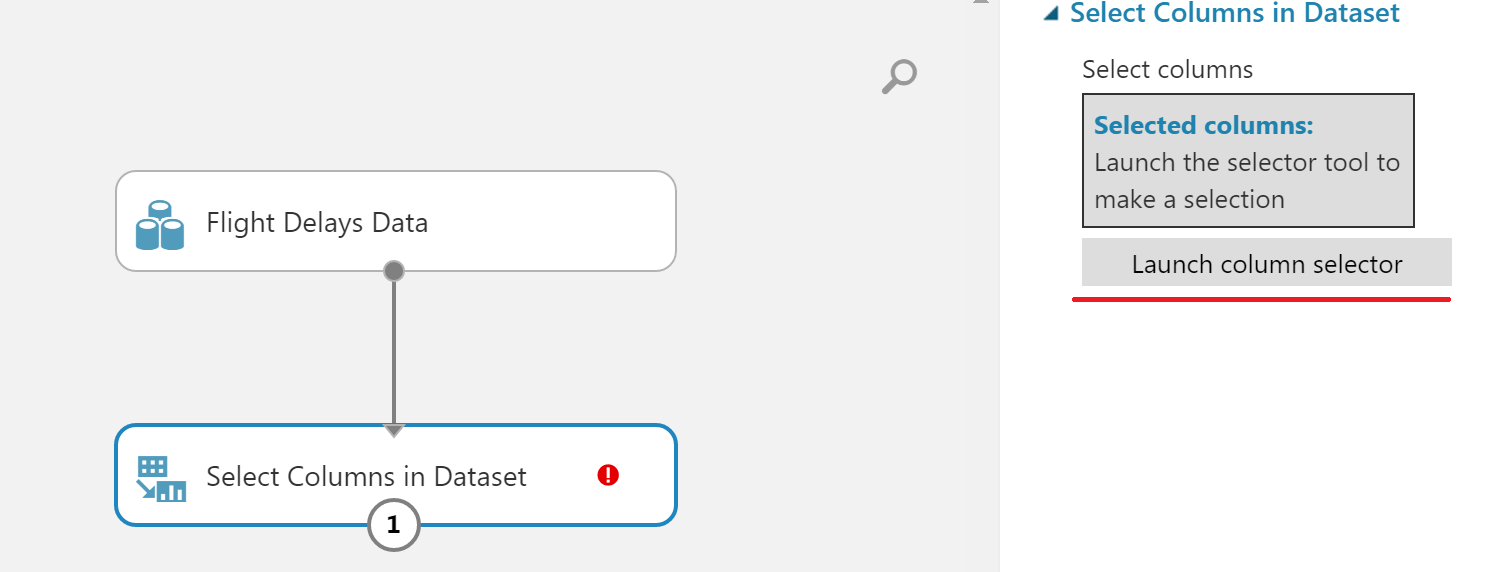
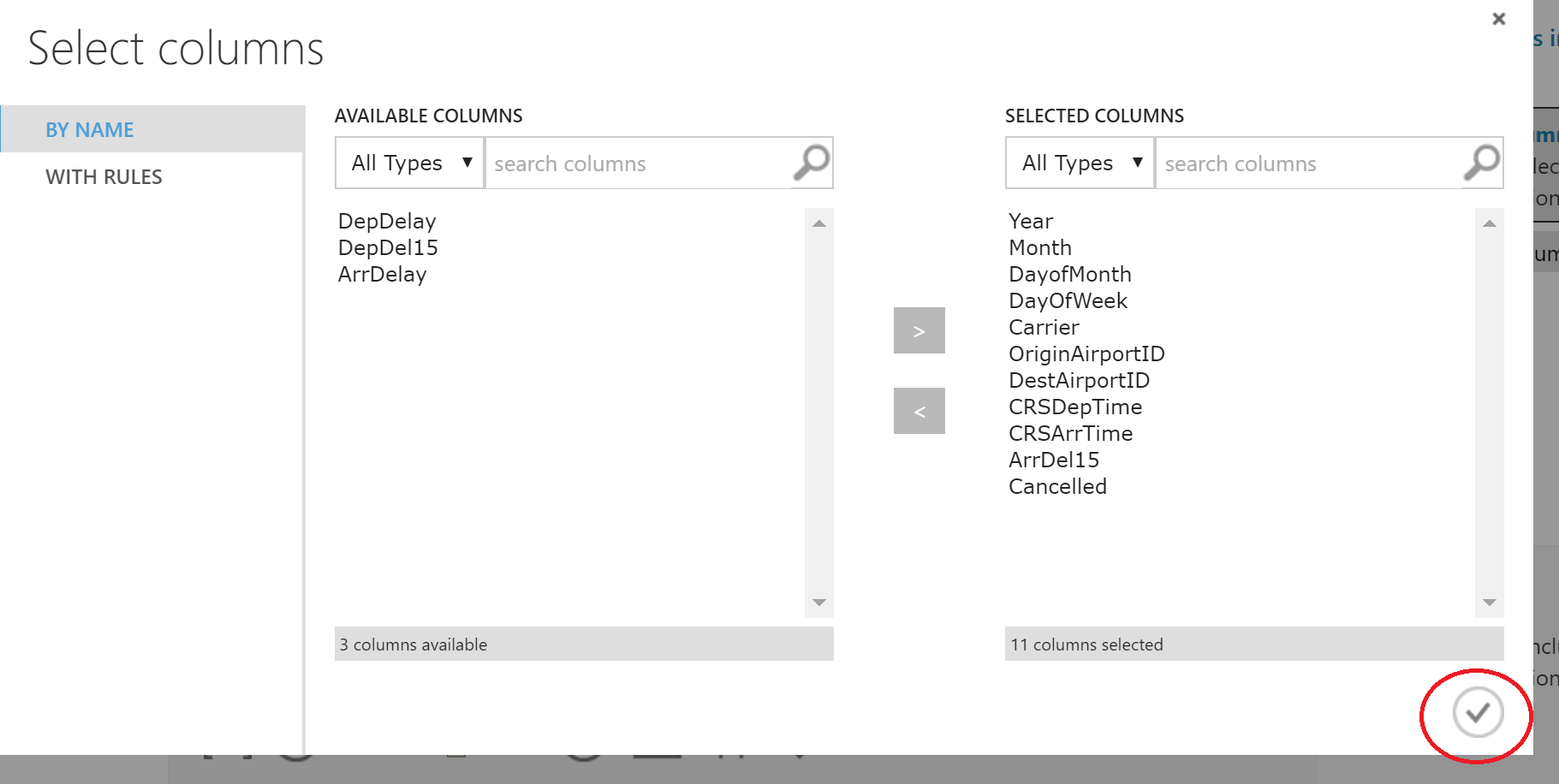
In the window that appears, select the desired columns.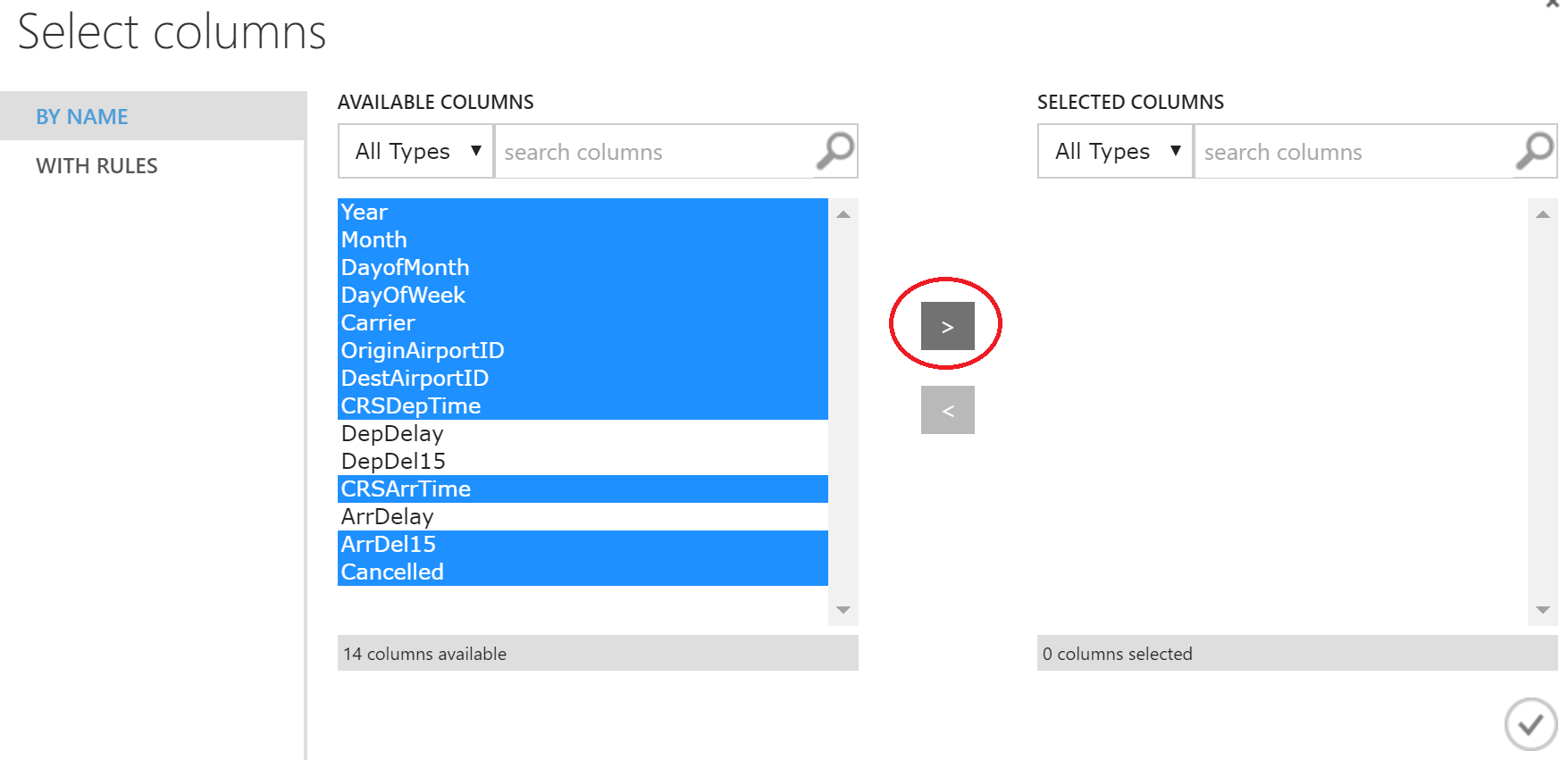
- We divide the data into 2 parts - train and test. Our task is to forget about the test part for a while.
Read more about what train / test set is here . The Split Data block will help us.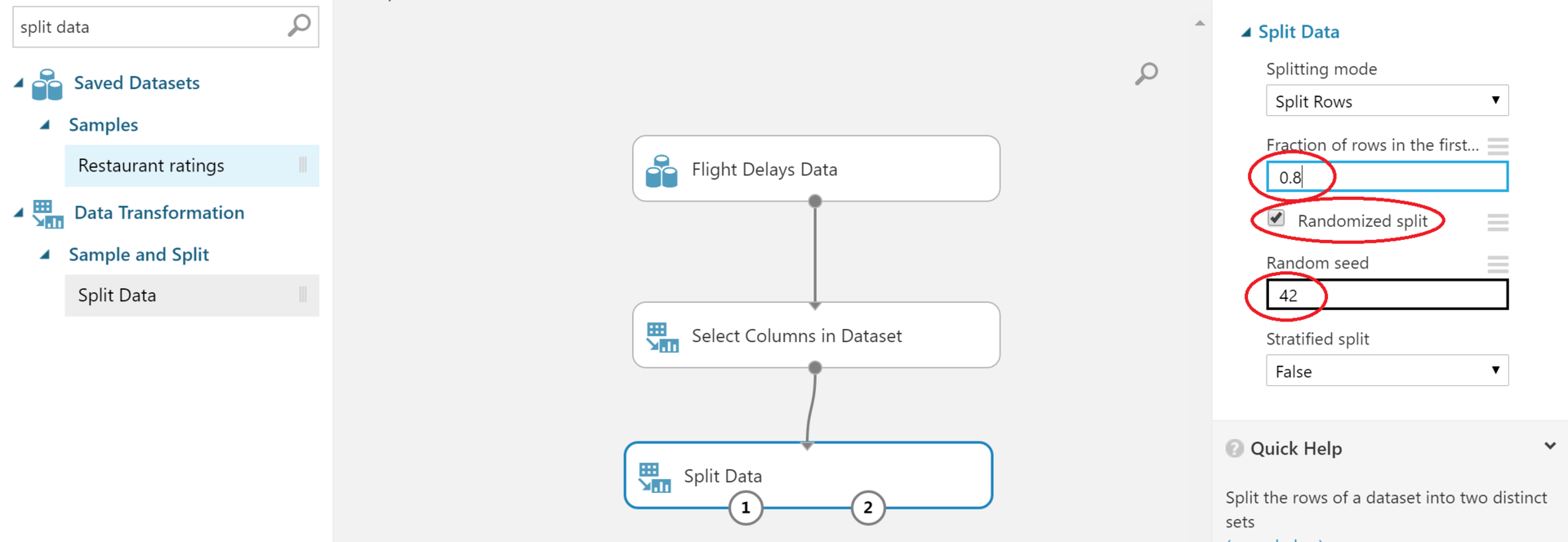
Be sure to fill in the circled fields on the right. The first - in what proportion to break - is usually set at about 0.7-0.8. The second is whether our partition is random. A checkmark is already there: make sure that you did not remove it by accident. It will also be nice to set Random seed, you can read about it here . - We give the train part to some machine learning algorithm.
The most difficult thing will be done for us. The choice of algorithm is a subtle point. From my memory, I took Random Forest (neatly - here it was called Decision Forest). Any two-class classification algorithm is suitable for us.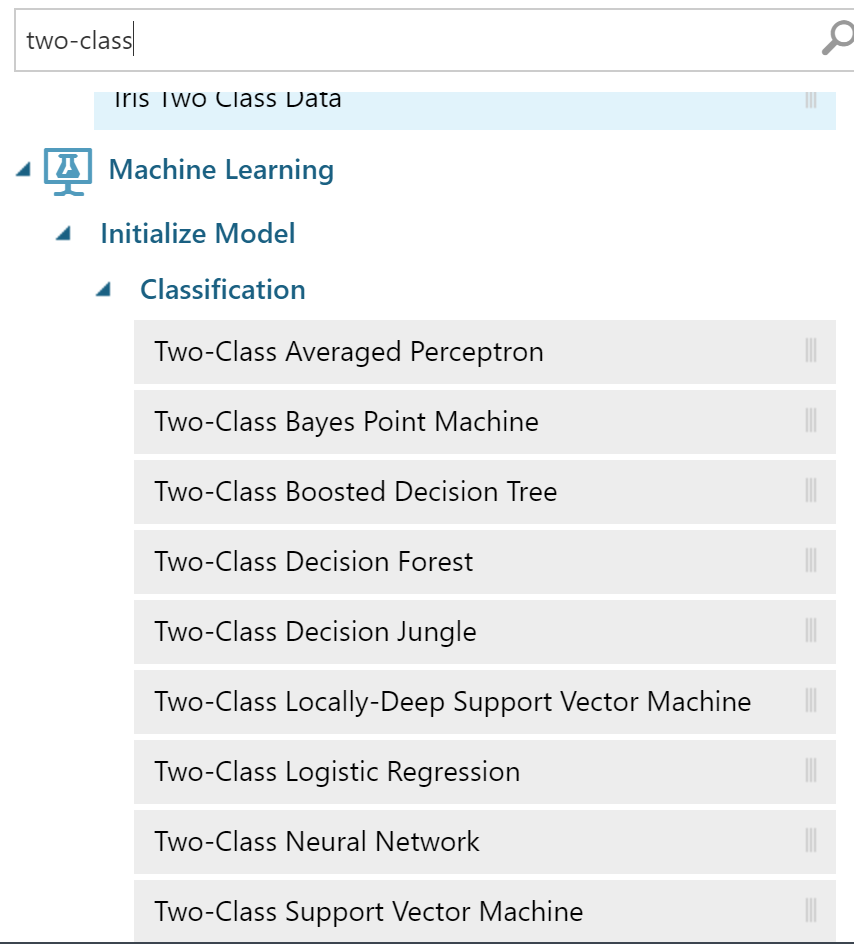
You can choose something else, get a better result and talk about it in the comments)
We also need the Train Model block. We will need to connect the blocks as shown in the screenshot below: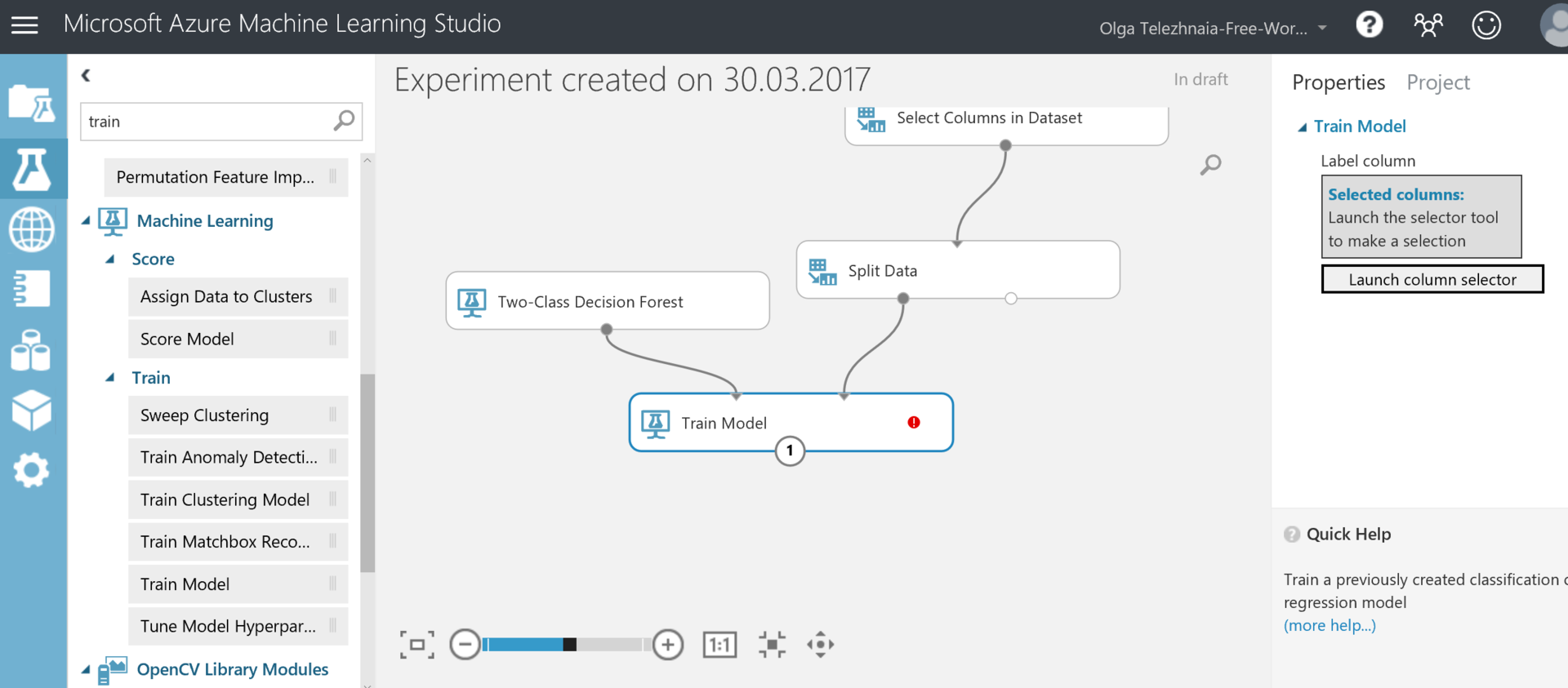
For the Train Model block, we will also need to click on the Launch Column Selector and select the column that we want to predict - in our case ArrDel15.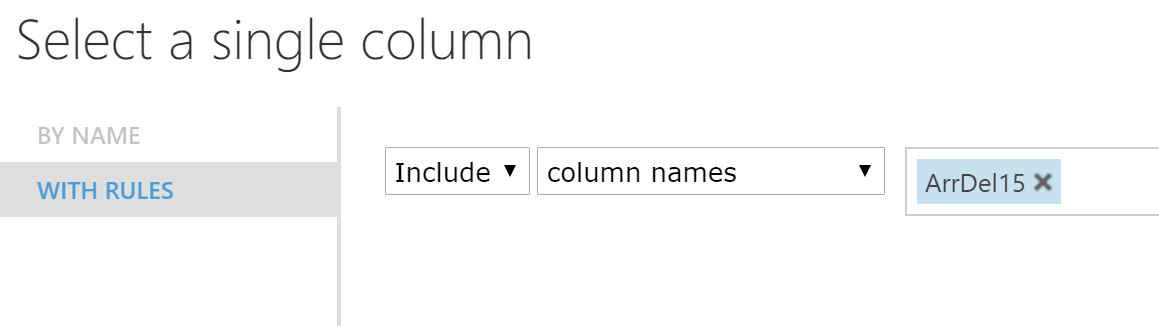
- We verify the obtained model using the test part
. The Score Model block will help us to cope with this. Do not forget to connect to it also the second part of the data after splitting.
The last block for today - Evaluate Model - will present us the result in a convenient form. The final graph looks like this: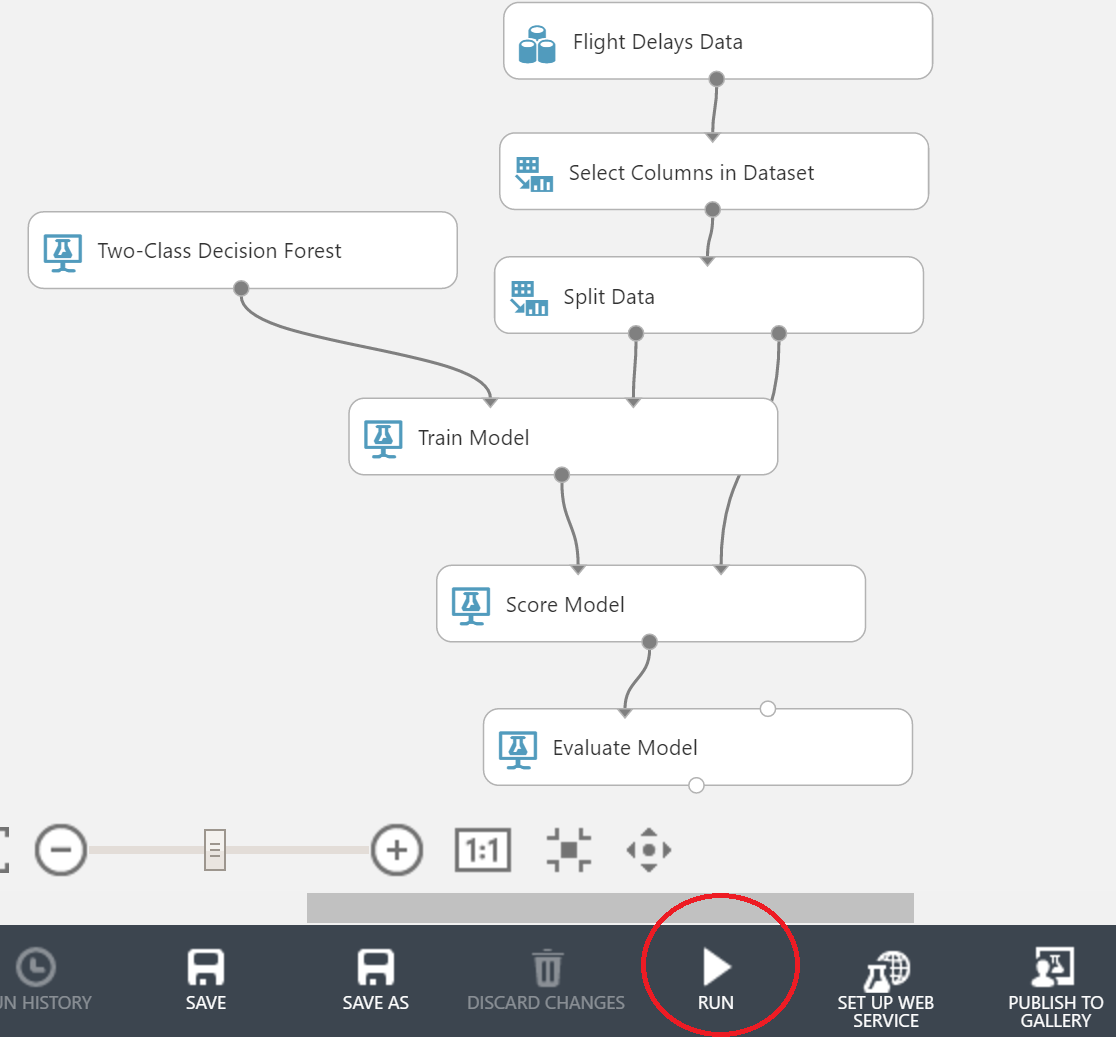
It's time to proudly press the Run button and go drink tea. Even for the cloud, learning is not the fastest process.
If tea is already finished, but the process has not ended, I advise you to study a couple of materials that will help us read data on the quality of the learning outcomes of our model.
This is what we could see if we had not deleted the linearly dependent ArrDelay column from the data. The model predicts perfectly, it was not mistaken a single time. I saw this, let out a stingy tear of joy and went to conduct the experiment again, to be honest)
But I got this result after deleting the ArrDelay column. Worse, but it looks like the truth.
- Are you satisfied with the quality? Congratulations! Now you can take new objects from the real world, and the computer will predict everything you need for them. I got a prediction accuracy of 80%, and this is not magic, but a great start.
- If the quality does not suit you, we return to the beginning of the task and look for what can be improved.
Of course, I simplified the process as much as possible. The art of preparing data, dividing it into parts, choosing an algorithm and measuring quality has been honed for years. Nevertheless, the fact of “assembling a model from scratch in just 10 minutes” gives me a second wind and revives a huge interest in this topic. But what if I take not Random Forest, but SVM? By the way, do you know how these algorithms differ? Both have a huge mathematical base and a rather complicated implementation, but everyone can understand the general idea. There would be a desire ;-) By the way, you can start by studying this cheat sheet .
I hope that my article will help you to avoid suffering and fall in love with ML, just like me. Share your opinion and experience in the comments, it will be interesting to chat!
If you would be interested in an article for beginners on a more specific topic, report it in the comments and I will try to share my experience in more detail. You can also read the article by Evgeny Grigorenko , in it you will find more practical scenarios aimed at more experienced users.