Recognition of numbers. Practical guide. Part 1

It all started out banal - my company had been paying a monthly service fee for a year, who knew how to find a region with license plates in the photo. This feature is used to automatically draw a number for some customers.
And one day, the Ministry of Internal Affairs of Ukraine opened access to the register of vehicles. Now according to the license plate, it became possible to check some information about the car (make, model, year of manufacture, color, etc.)! The boring routine of linear programming has faded away before the new supervisory task - to read the numbers throughout the entire photo database and validate this data with what the user specified. You know how it happens “the eyes are lit up” - the challenge is accepted, all other tasks for a while have become boring and monotonous ... We got to work and got quite good results, which we actually decided to share with the community.
For reference: on the site AUTO.RIA.com, about 100,000 photos are added per day.Datasaists have long known and are able to solve such problems, so dimabendera and I wrote this article for programmers. If you are not afraid of the phrase "convolutional networks" and know how to write "Hello World" in python - welcome under the cat ...
Who else recognizes
A year ago I studied this market and it turned out that not many services and software can work with exUSSR country numbers. Below is a list of companies we have worked with:
Automatic License Plate Recognition
There is opensource and commercial version. The Opensource version showed a very low recognition rate, in addition, it required specific dependencies for its assembly and operation (we didn’t particularly like it). A commercial version, or rather a commercial service works well. Able to work with Russian and Ukrainian numbers. Prices are moderate - $ 49 / 50K recognition per month. OpenALPR online demoRecognitor
We used this service for about a year. Good quality. The zone with the number is very good. The service does not know how to work with Ukrainian and European numbers. It is worth noting the good work with low-quality images (in the snow, photos of small resolution, ...). The price for the service is also acceptable, but they are reluctant to take for small volumes.
There are many commercial systems with closed software, but we did not find a good opensource implementation. In fact, this is very strange, since open source tools that have been the basis for solving this problem have long existed.
What tools are needed to recognize numbers
Finding objects in an image or in a video stream is a task from the field of computer vision, which is solved by different approaches, but more often with the help of so-called convolutional neural networks. We need to find not just an area in the photo in which the desired object is found, but also to separate all its points from other objects or background. This kind of task is called “Instance Segmentation”. The illustration below shows various types of computer vision tasks.
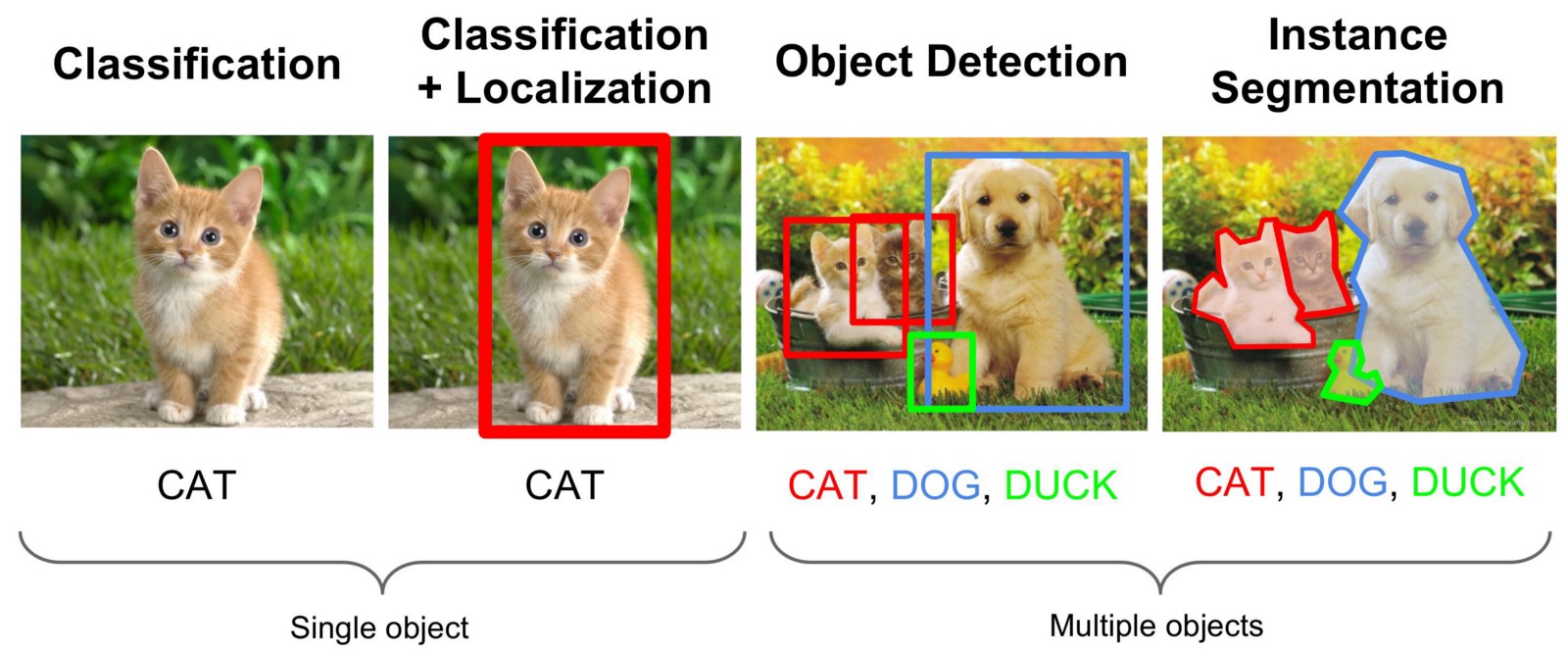
I will not write a lot of theory now about how the convolutional network works, this information is sufficient on the network and there are reports on youtube.
From modern architectures of convolutional streams, segmentation problems are often used: U-Net or Mask R-CNN . We chose Mask R-CNN.
The second tool we need is a text recognition library that can work with different languages and can be easily customized for the specificity of the texts that we will recognize. Here the choice is not so great, the most advanced is tesseract from Google.
There is also a number of less “global” tools, with the help of which we will need to normalize the area with a license plate (to bring it into a form in which text recognition will be possible). Usually for such transformations use opencv.
Also, it will be possible to try to determine the country and type to which the found license plate belongs, in order to apply in the post-processing a specifying pattern typical for this country and this type of number. For example, the Ukrainian license plate, starting from 2015, is decorated in blue and yellow design and consists of a two-letter four-digit two-letter pattern.

In addition, having the statistics of the frequency of "meeting" in the license plates of one or another combination of letters or numbers, you can improve the quality of post-processing in "controversial" situations. "
Nomeroff net
From the title of the article it is clear that we all implemented and named the project Nomeroff Net . Now part of the code for this project is already in production at AUTO.RIA.com . Of course, commercial analogues are still far away, everything works well only for Ukrainian numbers. In addition, an acceptable speed of work is achieved only with the support of the tensorflow module GPU! Without a GPU, you can also try, but not on the Raspberry Pi :).
All materials for our project: tagged datasets and trained models , we put in open access with the permission of RIA.com under a license Creative Commons CC BY 4.0
What we need
- Python3
- opencv-python no lower than version 3.4
- fresh Mask RCNN , tesseract
- through the pip3 package manager, you will need to install several modules on python3, they will be listed in a separate requirements.txt file
Dmitry and I have everything running on Fedora 28, I'm sure it can be installed on any other Linux distribution. I would not want to turn this post into a manual for installing and configuring tensorflow, if you want to try and something does not work out - ask in the comments, I will answer and tell you.
In order to speed up the installation, we plan to create a dockerfile - wait in the next project updates.
Nomeroff Net "Hello world"
Let's try to recognize something. We clone a repository with a code from github . We swing into the models folder, trained models for searching and classifying numbers, slightly correct variables with the location of folders.
UPD: This code is obsolete, it will only work in a branch 0.1.0 , the latest examples, see here :
All can be recognized:
import os
import sys
import json
import matplotlib.image as mpimg
# change this property
NOMEROFF_NET_DIR = "/var/www/nomeroff-net/"
MASK_RCNN_DIR = "/var/www/Mask_RCNN/"
MASK_RCNN_LOG_DIR = os.path.join(NOMEROFF_NET_DIR, "logs/")
MASK_RCNN_MODEL_PATH = os.path.join(NOMEROFF_NET_DIR, "models/mask_rcnn_numberplate_0700.h5")
REGION_MODEL_PATH = os.path.join(NOMEROFF_NET_DIR, "models/imagenet_vgg16_np_region_2019_1_18.h5")
sys.path.append(NOMEROFF_NET_DIR)
# Import license plate recognition tools.from NomeroffNet import filters, RectDetector, TextDetector, RegionDetector, Detector, textPostprocessing
# Initialize npdetector with default configuration file.
nnet = Detector(MASK_RCNN_DIR, MASK_RCNN_LOG_DIR)
# Load weights in keras format.
nnet.loadModel(MASK_RCNN_MODEL_PATH)
# Initialize rect detector with default configuration file.
rectDetector = RectDetector()
# Initialize text detector.
textDetector = TextDetector()
# Initialize numberplate region detector.
regionDetector = RegionDetector()
regionDetector.load(REGION_MODEL_PATH)
img_path = './examples/images/example1.jpeg'
img = mpimg.imread(img_path)
NP = nnet.detect([img])
# Generate image mask.
cv_img_masks = filters.cv_img_mask(NP)
for img_mask in cv_img_masks:
# Detect points.
points = rectDetector.detect(img_mask, fixRectangleAngle=1, outboundWidthOffset=3)
# Split on zones
zone = rectDetector.get_cv_zones(img, points)
# find standart
regionId = regionDetector.predict(zone)
regionName = regionDetector.getLabels(regionId)
# find text with postprocessing by numberplate region detector
text = textDetector.detect(zone)
text = textPostprocessing(text, regionName)
print('Detected numberplate: "%s" in region [%s]'%(text,regionName))
# Detected numberplate: "AC4921CB" in region [eu-ua-2015]Online demo
Sketched a simple demo for those who do not want to put all this and run it :). Be indulgent and patient to the speed of the script.
If you need examples of Ukrainian numbers (to test the operation of correction algorithms), take an example from this folder.
What's next
I understand that the topic is very niche and is unlikely to arouse great interest among a wide range of programmers, in addition, the code and models are still quite “raw” in terms of recognition quality, speed, memory consumption, etc. But there is still hope that there will be enthusiasts which will be interesting to train models for your needs, your country, which will help and tell you where there are problems and together with us will make the project no worse than commercial counterparts.
Known Issues
- The project has no documentation, only basic code examples.
- As a recognition module, the universal OCR tesseract was chosen and it can read a lot, but it makes a lot of mistakes. In the case of recognition of Ukrainian numbers, there is written a specialized correction system, which so far compensates for some of the errors, but there is a premonition that there can be done much better.
- "Square" numbers (license plates with a 1: 2 ratio) are quite rare and we just started to deal with them, so the error will be larger with them.
- Sometimes, instead of a number plate, our model finds road signs with the name of a settlement, an instrument panel inside the cabin, and other artifacts.
- In case of poor quality of the room or low resolution, a region of 4 points is not completely determined.
Announcement
If it is interesting to someone, in the second part we are going to talk about how and what to mark your dataset and how to train your models that can work better for your content (your country, your photo size). We will also talk about how to create your own classifier, which, for example, will help determine if the number is not drawn on the photo.
A few examples in Jupyter Notebook:
- An example of finding region masks with license plates
- An example of finding and converting regional masks into quadrangular polygons
- An example of license plate recognition with visualization