Lock-free data structures. Iterable list
 The lock-free list is the basis of many interesting data structures, the simplest hash map , where the lock-free list is used as a collision list, a split-ordered list , built entirely on a list with the original algorithm for splitting bucket, a multi-level skip list , which is essentially hierarchical list of lists. In the previousIn the article, we made sure that we can give such an internal structure to a competitive container that it supports thread-safe iterators in the dynamic world of lock-free containers. As we found out, the main condition for a lock-free container to become iterable is the stability of the internal structure: nodes must not be physically deleted (delete). In this case, the iterator is just a (maybe composite) pointer to a node with the ability to go to the next (increment operator).
The lock-free list is the basis of many interesting data structures, the simplest hash map , where the lock-free list is used as a collision list, a split-ordered list , built entirely on a list with the original algorithm for splitting bucket, a multi-level skip list , which is essentially hierarchical list of lists. In the previousIn the article, we made sure that we can give such an internal structure to a competitive container that it supports thread-safe iterators in the dynamic world of lock-free containers. As we found out, the main condition for a lock-free container to become iterable is the stability of the internal structure: nodes must not be physically deleted (delete). In this case, the iterator is just a (maybe composite) pointer to a node with the ability to go to the next (increment operator). Is it possible to extend this approach to the lock-free list? .. Let's see ...
A regular lock-free list has this node structure:
template
struct list_node {
std::atomic next_;
T data_;
};
In it, data is incorporated directly into the node, so deleting the key (data) leads to the removal of the entire node.
Separate the node and the data - let the node contain a pointer to the data that it carries:
template
struct node {
std::atomic next_;
std::atomic data_;
};
Then, to delete the key, it is enough to reset the field
data_at the node. As a result, our list will acquire such an internal structure: 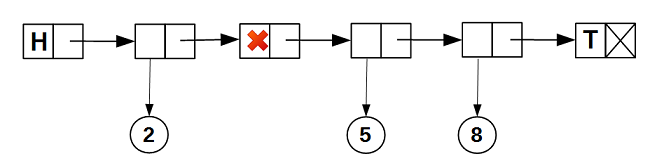
Nodes are never deleted, so the list is iterable: an iterator is actually a pointer to a node:
template
struct iterator {
guarded_ptr gp_;
node* node_;
T* operator ->() { return gp_.ptr; }
iterator& operator++() {
// проходим далее по списку, начиная с node_,
// пропуская узлы с пустыми данными
}
};
The presence
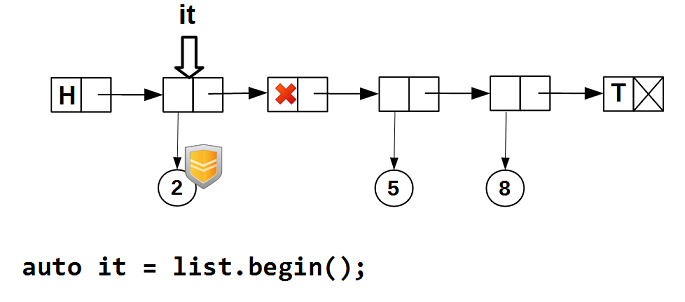
guarded_ptr(which contains a pointer to data protected by a hazard pointer) is necessary, since we cannot guarantee that another thread will not delete the data on which the iterator is positioned. It can only be guaranteed that at the time the iterator moves to the node, node_it (the node) contained data. The protected pointer guarantees that while the iterator is on the node node_, its data will not be physically deleted (delete). Let's see in the pictures how this works. We start crawling the list - the iterator is positioned on the first node with non-empty data:
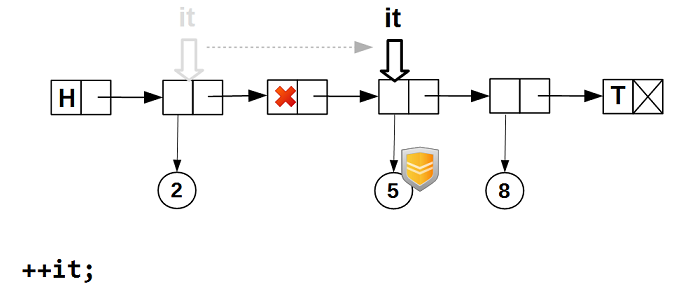
Next, increment the iterator - it skips the nodes with empty data:
Even if some other thread deletes the data of the node on which the iterator is positioned,
guarded_ptrthe iterator guarantees that the data will not be physically deleted while the iterator is on the node: 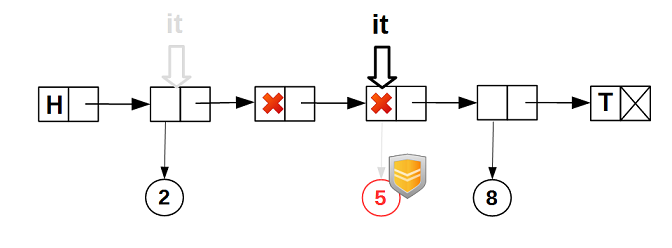
It is possible that the data will be deleted from the list and then
node_other data will be assigned to the same node . In this case, the iterator is positioned on the node node_. It would be strange if in this case the operator ->()iterator would return a pointer to different data. guarded_ptrguarantees us the immutability of the data returned by the iterator, but does not completely prevent it from being changed by other threads: 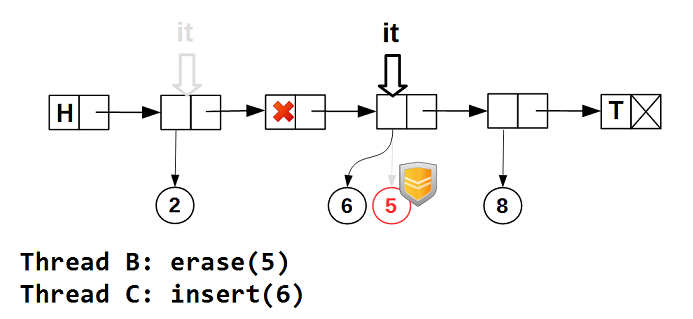
As you can see, the built iterable list supports thread-safe iterators and has a very simple operation to delete the key (data), which is reduced to zeroing (using the CAS primitive)
data_Node fields Operationinsert()adding new data is somewhat more complicated, since two cases are possible: - inserting a new node between existing nodes in the list with non-empty data:
This algorithm for inserting a node is already familiar to us from one of the previous articles.
- setting a field
data_on an empty node prev: 
This could end the article if the second case - reusing empty
data_- would not throw a couple of surprises.First surprise
The first (naive) version of the insert in the iterable list looked like this:

The function
linear_searchis a regular linear search in the list (well, not quite ordinary, we still have a competitive list, so we are provided with atomic squats and hazard pointers), returns trueif the key is found falseotherwise. The out-parameter of a function pos(type insert_pos) is always filled. The search stops as soon as a key of at least the required one is found data. For insertion we are interested in the failure of the search - in this case it poswill contain the insertion position. The node pos.curwill always be nonempty (or it will point to the end of the list - a specially allocated node tail), but here pos.previs the previous one forpos.cur- may indicate an empty node, - this is the case we are particularly interested in. Fields prevDataand curDatastructures insert_posare values data_for prevand, currespectively. We also note that we do not need to protect pointers to nodes prevand curhazard pointers, since nodes from our list are never deleted. But data can be deleted, so we protect it. So, the naive implementation simply checks: if the previous node is empty (
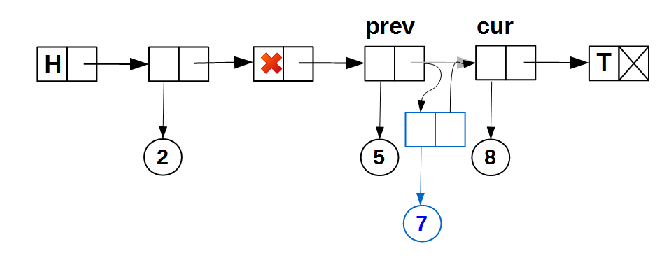
pos.prevData == nullptr), then we are trying to write a link to the inserted data into it. Since our list is competitive (moreover, while it’s even lock-free, but we will fix it soon), changing the pointerprev.data_We make atomic CAS: if it is successful, then no other thread has prevented us and we inserted new data into the list. Here we are waiting for the first surprise. Suppose thread A adds a certain key to the list:
linear_search()done, the insert_pos structure is initialized by the insertion position, and the thread is ready to call link(), but then its time passed and it 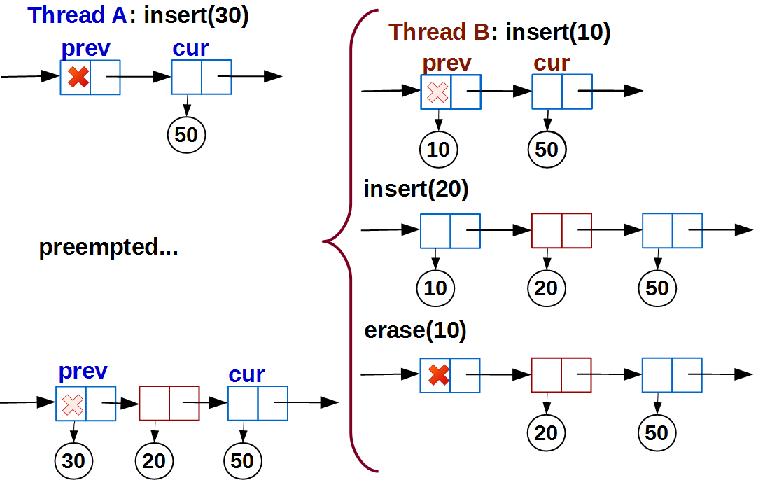
At the time of the resumption of thread A, the list has changed unrecognizably, but
posnothing has changed from the point of view of the found position of thread A. It prevremained empty. Therefore, stream A will write data with key 30 to prevand successfully complete the insertion, thereby breaking the order of the list.It is kind of ABA-a problem that is not solved by the use of hazard pointer'ov as a pointer
prev->data_we NULL. We have the right to link new data to an empty node only when the connection prev-> curwe have not changed after the search; moreover, the data of these nodes has not changed. To solve this problem, we use the marked pointer technique : the least significant bit of the pointer to the node data will be used as a sign “a new node is being inserted”. Moreover, it is necessary to mark both nodes - prevand cur, - otherwise the other thread may delete the data from curand the order of the list will be violated again (do not forget that the node is curalways empty). As a result, the structure of the node will change and the function of link()adding data will take the form:template
struct node {
std::atomic< node * > next_;
std::atomic< marked_ptr< T, 1 >> data_;
};
bool link( insert_pos& pos, T& data ) {
// маркируем данные prev и cur
if ( !pos.cur->data_.CAS( marked_ptr(pos.curData, 0),
marked_ptr(pos.curData, 1))) {
// не удалось — какой-то другой поток нам помешал
return false;
}
if ( !pos.prev->data_.CAS( marked_ptr(pos.prevData, 0),
marked_ptr(pos.prevData, 1))) {
// не удалось — опять нам мешают
// не забываем снять метку
pos.cur->data_.store( marked_ptr(pos.curData, 0));
return false;
}
// проверяем, что связка prev -> cur осталась прежней
if ( pos.prev->next_.load() != pos.cur ) {
// кто-то уже успел что-то добавить между prev и cur
pos.prev->data_.store( marked_ptr(pos.prevData, 0));
pos.cur->data_.store( marked_ptr( pos.curData, 0));
return false;
}
// все проверки удачны, можно добавлять
if ( pos.prevData == nullptr ) {
// устанавливаем новые данные у пустого узла
// быть может, здесь достаточно атомарного store
bool ok = pos.prev->data_.CAS( marked_ptr( nullptr, 1 ),
marked_ptr( &data, 0 ));
// снимаем метку у cur
pos.cur->data_.store( marked_ptr( pos.curData, 0));
return ok;
}
else {
// вставка новой ноды — алгоритм Harris/Michael
// здесь не рассматриваем
// но не забываем по окончании снять флаги
}
}
The introduction of a marked pointer also affects the data deletion function (which, as we recall, boils down to a simple nullification of the field
data_): now we need to reset only untagged data, but this does not add complexity to the deletion procedure. A list search completely ignores our marker. As a result, the iterable list ceased to be lock-free: if a thread marked at least one of the nodes, and then was killed (there is no place for an exception in the function
link()), the lock-free condition is violated, since the node will remain marked forever and eventually someday will lead to an endless active wait for unmarking. On the other hand, it’s a Second surprise
Unfortunately, testing has shown that this is not a complete solution. If the naive iterable list often showed a violation of data sorting, even in a debug build, then after the introduction of marked pointers, tests began to show a violation very rarely and only in the release build. This is a signal that we have a very unpleasant problem, which is practically not reproducible in a reasonable time and can only be solved analytically.
As analysis has shown, the problem is actually orthogonal to the first:
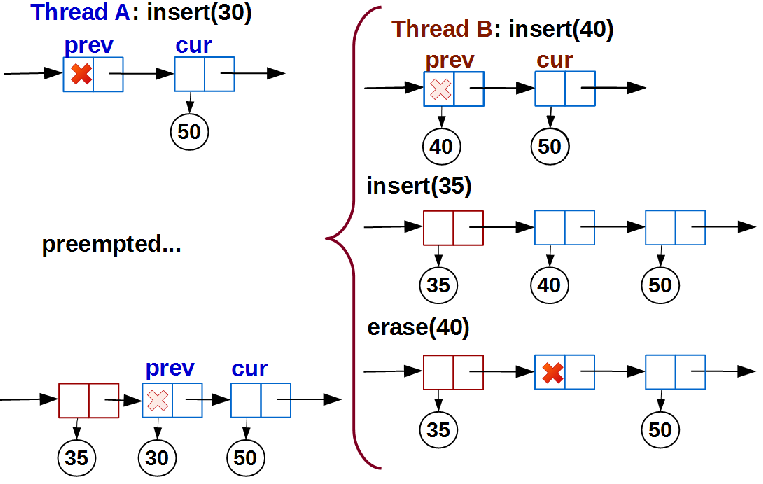
As in the first case, stream A is forced out before entering
link(). While A waits until it is planned again, other threads manage to link()stream A, but lead to a violation of the sorting of the list. The solution is to add one more condition to
link(): after we have marked the nodes prevand curbetween which we must insert a new one (or use an empty one prev), we must check that the insertion position has not changed . You can check this in the only way - find the node following the new data, and make sure that it is cur:bool link( insert_pos& pos, T& data ) {
// маркируем данные prev и cur
// ... как и было
// проверяем, что связка prev -> cur осталась прежней
// ... как и было
// проверяем, что позиция вставки не изменилась
if ( find_next( data ) != pos.cur ) {
// oops! Нам опять помешали…
pos.prev->data_.store( marked_ptr(pos.prevData, 0));
pos.cur->data_.store( marked_ptr( pos.curData, 0));
return false;
}
// все проверки удачны, можно добавлять
// ... как и было
}
Here the helper function
find_next()searches for the node closest to k data.
Conclusion
Thus, an iterable competitive list can be built. A search in it is lock-free, but insertion and, as a result, deletion from it is still not lock-free. Why is it so needed? ..
Firstly, the presence of thread-safe iterators in some tasks is important. Secondly, this list is interesting in that the operation of deleting a key in it is much easier than inserting - it is enough to reset the pointer to the data at the node; deletion is usually much harder, see two-phase deletion from the classic lock-free list. Finally, this task was for me personally a certain challenge, since before that I considered the concept of iterators in principle unrealizable for competitive containers.
I hope this algorithm will be useful, see libcds for implementation : MichaelSet / Map and SplitListSet / Map based
IterableList with support for thread safe iterators.Lock-free data structures