How Netflix Streaming Works
- Transfer
“If you can cache everything in a very efficient way , then you can often change the rules of the game.”
As software developers, we often encounter problems that require the distribution of a certain set of data that does not correspond to the name Big Data. Examples of problems of this type are the following:
- Online Product Metadata
- Search engine document metadata
- Movie and TV show metadata
Faced with this, we usually choose one of two ways:
- Storage of this data in some centralized storage (for example, a relational DBMS, NoSQL information warehouse or memcached cluster) for remote user access
- Serialization (like json, XML, etc.) and distribution to consumers who will keep a local copy
The application of each of these approaches has its own problems. Centralizing the data can allow your data set to grow indefinitely, however:
- There are delays and bandwidth limitations when interacting with this data.
- The remote information warehouse cannot be compared in reliability with a local copy of data
On the other hand, serializing and storing a local copy of the data completely in RAM can provide orders of magnitude shorter delay times and a higher access frequency, however this approach also brings scaling problems that become more complex as the data set grows:
- The amount of dynamic memory occupied by the data set is growing
- Getting a dataset requires downloading extra bits
- Updating a dataset may require significant CPU resources or interfere with automatic memory management.
Developers often choose a hybrid approach - they cache data with frequent access locally and use it remotely with rare access. This approach has its problems:
- Managing data structures may require a significant amount of dynamic cache
- Objects are often stored for a long time so that they can be distributed, and adversely affect the operation of automatic memory management
At Netflix, we realized that such a hybrid approach often creates the illusion of winning. The size of the local cache is often the result of a careful search for a compromise between the delay in remote access for many records and the requirement for storage (heap) when storing more data locally. But if you can cache everything in a very efficient way , then you can often change the game - and keep the entire data set in memory using a smaller hip and less CPU loading than when storing only part of this set. And here comes Hollow, the latest open source project from Netflix.

Hollow is a Java library and comprehensive toolkit for using in-memory small and medium-sized data sets that are distributed from one manufacturer to many read-only consumers.
“Hollow is changing the way ... Datasets for which such an opportunity could never be considered before can now be candidates for Hollow.”
Functioning
Hollow focuses solely on its prescribed set of problems: storing a complete set of read-only data in consumers' RAM. It overcomes the consequences of updating and uploading data from a partial cache.
Due to its performance characteristics, Hollow is changing the approach from the perspective of the dimensions of the corresponding data sets for the solution using RAM. Datasets for which such an opportunity could never be considered before can now be candidates for Hollow. For example, Hollow may be fully acceptable for datasets that, if represented in json or XML, would require more than 100 GB.
Speed of adaptation
Hollow not only improves performance - this package significantly enhances the speed of adaptation of the team when working with tasks related to data sets.
Using Hollow is straightforward right from the first step. Hollow automatically creates a user API based on a specific data model, so users can intuitively interact with the data, taking advantage of the IDE code.
But a major gain comes from using Hollow on an ongoing basis. If your data is constantly in Hollow, then there are many opportunities. Imagine that you can quickly go through the entire production dataset - current or from anywhere in the recent past, right up to the local development workstation: download it, and thenaccurately reproduce certain production scenarios.
Choosing Hollow will give you an edge on tools; Hollow comes with many ready-made utilities to help you understand and manage your datasets.
Sustainability
How many nines of reliability would you like to have? Three four five? Nine? Being a local storage of data in RAM, Hollow is not subject to environmental problems, including network failures, disk failures, interference from neighbors in a centralized data warehouse, etc. If your data producer fails or your consumer cannot connect to the data warehouse, then you can work with outdated data - but the data will still be present and your service will continue to work.
Hollow has been refined for more than two years of continuous rigorous use on Netflix. We use it to provide important datasets needed to communicate with Netflix on servers that quickly serve real-time client requests at maximum performance or close to it. Despite the fact that Hollow spends enormous efforts to squeeze every last bit of performance out of server hardware, enormous attention to detail has become part of strengthening this critical part of our infrastructure.
A source
Three years ago, we announced Zeno , our current solution in this area. Hollow replaces Zeno, but is largely its spiritual successor.
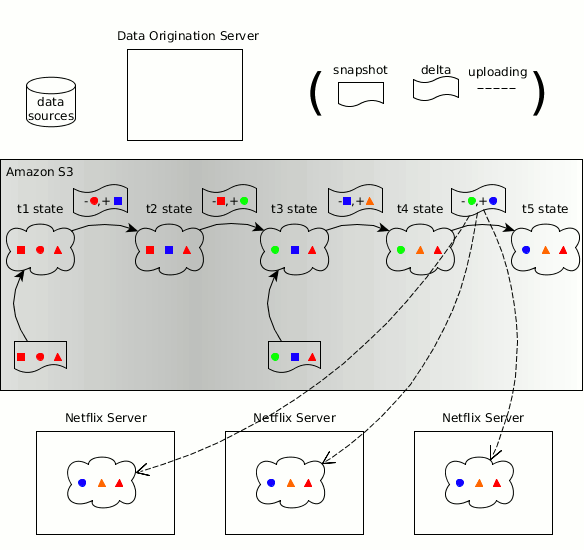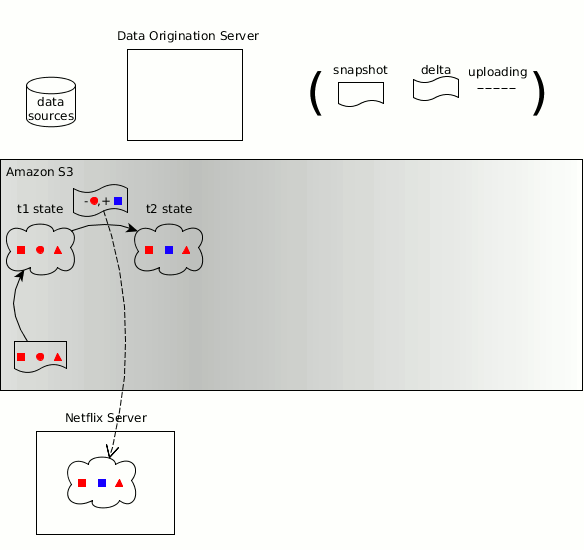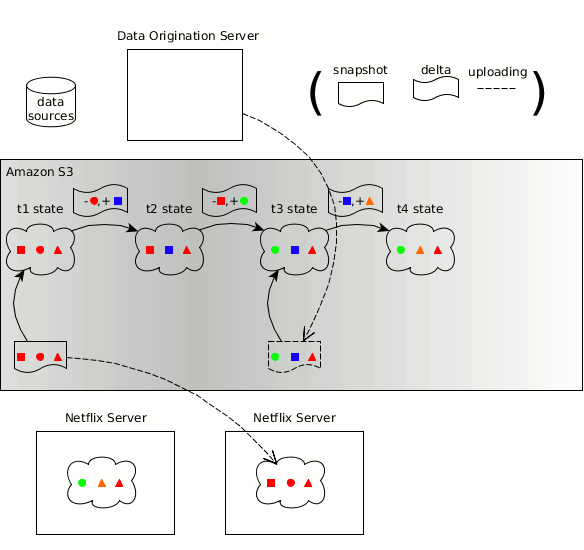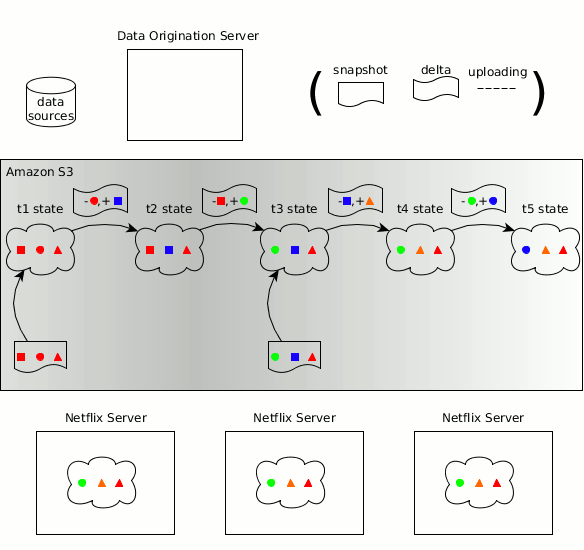
Zeno's concepts regarding the manufacturer, consumers, data state, copies of the object state and state changes passed to Hollow.
As before, the time sequence of a changing data set can be divided into discrete data states , each of which is a complete copy of the data state at a certain point in time . Hollow automatically detects state changes - the effort required by the user to maintain an updated state is minimal. Hollow automatically deduplicates data to minimize the dynamic memory size of our data sets at consumers.
Development
Hollow takes these concepts and develops them, improving almost every aspect of the solution.
Hollow avoids using POJOs as a representation in RAM - instead, replaces them with a compact, fixed-length, strongly typed data encryption. Such encryption is intended both to minimize the amount of dynamic memory in data sets and to reduce the share of the cost associated with the CPU while providing real-time access to data. All encrypted records are packaged in reusable memory blocks, which are located in the JVM-hep to prevent the automatic memory management from affecting working servers.

An example of the location of OBJECT-type records in memory
Data sets in Hollow are self-sufficient - for a serialized blob so that this blob can be used by the framework, tracking from the code specific to the use case is not required. Additionally, Hollow is designed with backward compatibility , so deployment can be less frequent.
"The ability to build powerful access systems , regardless of whether they were originally intended when developing the data model."
Since Hollow is completely built on RAM, the toolkit can be implemented provided that random access across the entire width of the data set can be performed without leaving the Java-heap. A lot of ready-made tools are part of Hollow, and creating your own tools thanks to the basic building blocks provided by the library is a snap.
The basis for using Hollow is the concept of indexing data in various ways . This provides O (1) access to the corresponding records in the data, which makes it possible to build powerful access systems regardless of whether they were originally intended when developing the data model.
Benefits
The Hollow toolkit is easy to install and has intuitive controls. You will be able to understand some aspects in your data that you were not aware of.

The change tracking tool allows you to track changes in certain records over time.
Hollow can enhance your capabilities. If something in some record seems to be wrong, then you can find out exactly what and when happened using a simple request to the change tracking tool. If an accident occurs and an improper data set is accidentally released, then your data set can be rolled back to the one that was before the error occurred, fixing production problems in their paths. Since the transition between states occurs quickly, this action can give a result in the entire fleet of cars in a few seconds.
“If your data resides in Hollow, there are many possibilities .”
Hollow proved to be an extremely useful tool on Netflix - we saw a widespread decrease in server startup time and a decrease in dynamic memory footprint with an ever-increasing need for metadata. Thanks to the focused data modeling efforts carried out based on the results of a detailed analysis of the use of dynamic memory , which became possible with the advent of Hollow, we will be able to further improve the performance.
In addition to the gain in performance, we see a huge increase in productivity related to the dissemination of our catalog data. This is partly due to the tools available in Hollow, and partly to the architecture that would not have been possible without it.
Conclusion
Wherever we see a problem, we see that it can be solved with Hollow. Today, Hollow is available for worldwide use.
Hollow is not designed to work with datasets of any size. If there is a lot of data, then storing the entire data set in memory is not possible. However, using the proper structure and some data modeling, this threshold can be much higher than you think.
The documentation is available at http://hollow.how , and the code is on GitHub . We recommend that you refer to the quick start guide.- It will take only a few minutes to view the demo and see the work, and familiarization with the fully industrial implementation of Hollow takes about an hour. After that, you can connect your data model and go ahead.
If you started working, you can get help directly from us or from other users through Gitter or Stack Overflow by placing a “hollow” label.