Made at MIT: Gitless Version Control System
All of you know the Git system. At least they heard - that's for sure. Developers who use the system either love it or scold it for its complicated interface and bugs. Git's version control system is the de facto standard in the industry. The developer may have opinions about the benefits of Mercurial, but most often you have to put up with the requirement to be able to use Git. Like any complex system, it has many useful and necessary functions. However, not everyone gets to brilliant simplicity, so the existing implementation left room for improvement.
In simple words - a tricky application was difficult to use. Therefore, the laboratory of the Massachusetts Institute of Technology took up improvements and cut off all the "problem elements" (because the fact that for one problem, for another can easily be an advantage). The improved and simplified version was called Gitless. It was developed taking into account 2400 questions related to Git and taken from the StackOverflow developers site.
A team of authors identified the most problematic places in Git, including two concepts of staging and stashing. Then they proposed changes designed to solve known problems.
What's wrong with git
Many users have complained that Git needs a new interface. The experts even drew up a document. What's wrong with Git? Conceptual design analysis. Authors: S. Perez De Rosso and D. Jackson.
Example
git checkout < file > // отбросить все изменения в одном файле с последней выгрузки в систему
git reset --hard // отбросить все изменения во всех файлах с последней выгрузки в систему
These two lines are one illustration of how much Git needed an advanced interface. Two different commands for one function with one difference is that one is for a single file, and the second is for multiple files. Part of the problem is also that the two teams are not really doing exactly the same thing.
Most Git users use it for a small number of teams, and the remaining units know the platform at a deeper level. It turns out that basically the platform is needed for basic functions, and a large layer of opportunities remains for too narrow a circle. This indicates that Git is not working properly.
A brief comparison of basic functions with the previous version
One of the striking features of Gitless is that the version ignores a feature called staging. It allows you to save individual parts of the file. Convenient, but can create problem situations. The key difference between this and the stashing function is that the second hides changes from the workspace.
The stashing function hides rough work in the working directory - monitored files that have been changed and save everything on the stack with incomplete changes. All changes can be applied later, when it is convenient. This is necessary when you are working in one branch and everything is in an erratic state, and you urgently need to switch to another branch. You do not want to unload the code with partially done work in the first branch during the pause.
The staging function indexes changes made to a file. If you tagged staged files, Git understands that you prepared them for upload.
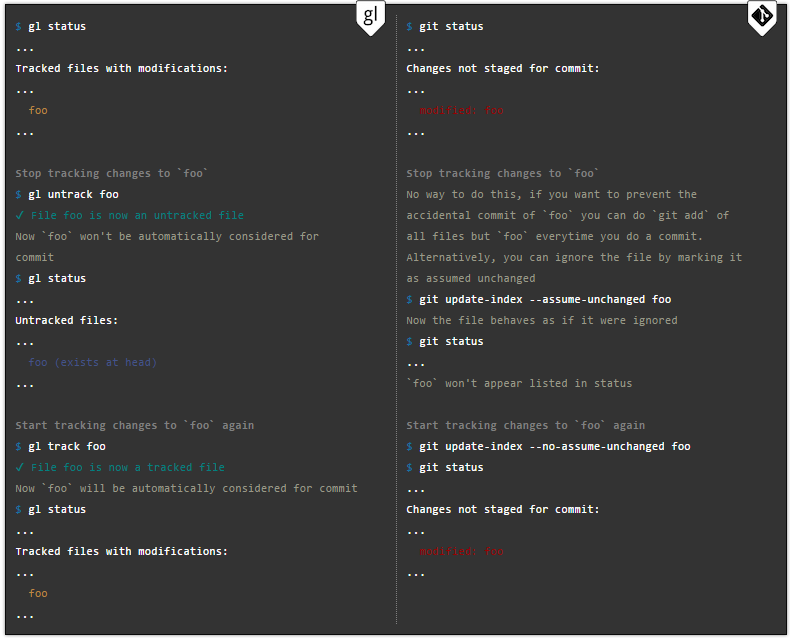
Gitless has no concept of stashing. Imagine the following situation. You are in the midst of project development and should switch to another branch of it, but you have not yet uploaded your half-completed work to the system. The stashing function takes the changes you have made and saves them on the stack with pending changes that you can restore later.
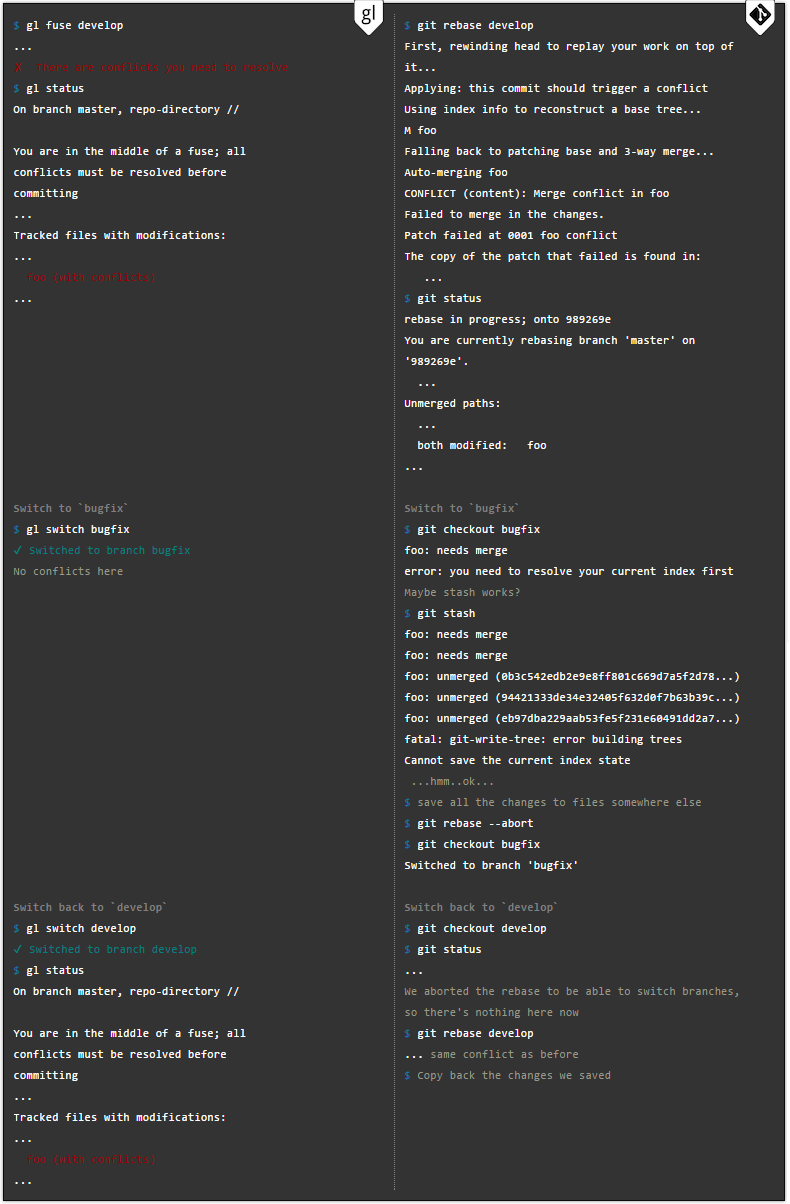
The author of the Gitless manual reports that the problem appears when switching between branches. It can be difficult to remember which of the stashes is located. Well, the top of all this was that the function does not help if you are in the process of a merge that includes conflicting files. This is the opinion of Perez de de Rosso.
Thanks to Gitless, this problem is solved. The branches have become completely autonomous in relation to each other. This makes the job much easier and allows developers to avoid confusion when they need to constantly switch between tasks.
Saving Changes
Gitless hides the stage area as a whole, which makes the process more transparent and less complicated for the user. There are much more flexible commit commands to solve problems. Moreover, they will allow you to do actions such as allocating code segments for a commit.
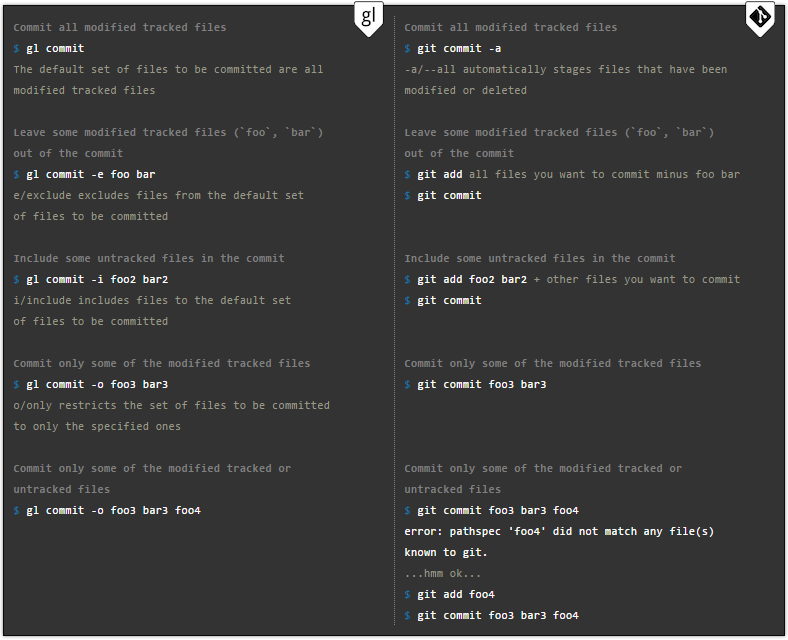
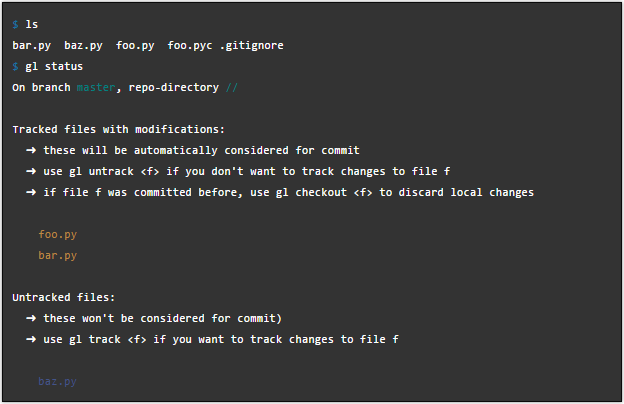
In addition, you can change the classification of any file to values: monitored, not monitored or ignored. It doesn't matter if this file exists in the header or not.
Branching development processes
The main idea needed to understand the new version: the branches in Gitless have become completely independent development lines. Each of them remains separate from the others with its working version of the files. There are no intersections and no problems. At any time you switch to another branch, the contents of your workspace are saved and files that are related to the destination branch are restored. File classification is also preserved. If the file is classified differently in two separate branches, then Gitless will take this into account.
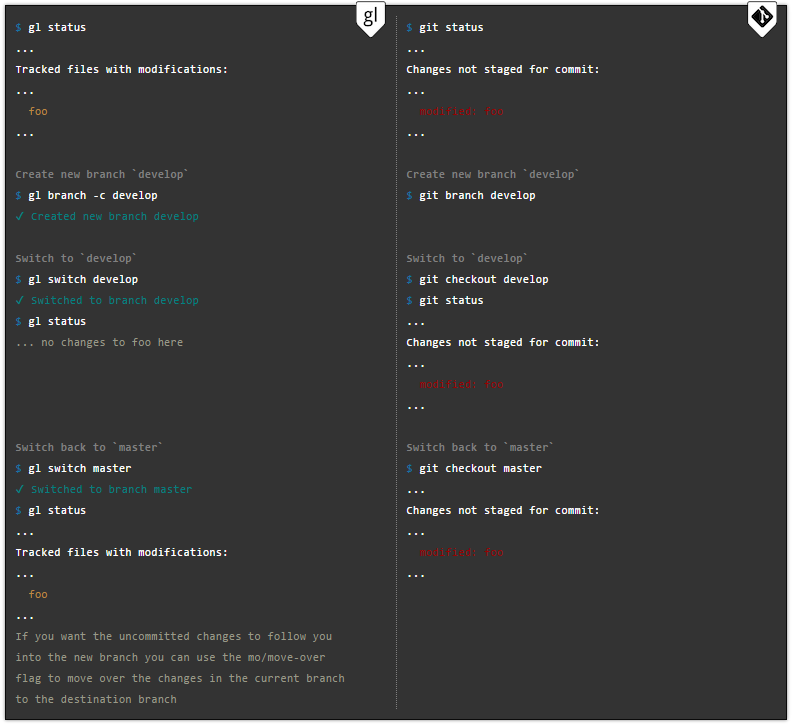
Simply put, in the Gitless version you do not need to remember about changes that are not loaded into the system, which are in conflict with changes in the destination branch.

Also, you can postpone the resolution of a conflict situation if you have a mid-merge or fuse. The conflict will remain until you switch back.
Work with remote repositories
Here, synchronization with other repositories occurs in both programs the same way.
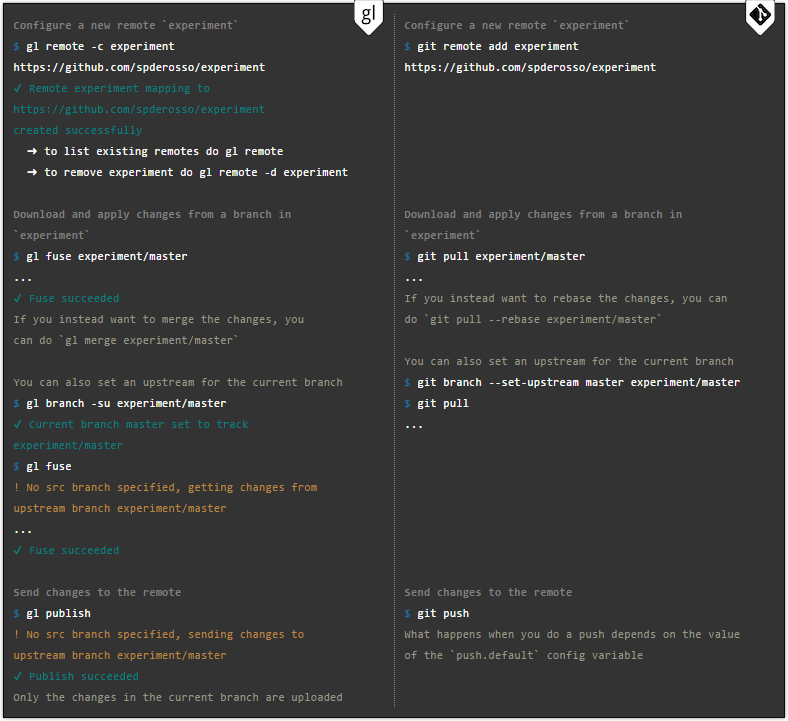
Another advantage of the new version is the ability to switch to the old one without losing code. At the same time, your colleagues may not even be aware that you are using other software. You can study the
manual for working with Gitless on the official website of the application. The documentation describes the following: how to create a repository, save changes; how to work with branches; how to use tags, work with remote repositories.
What is the result
It turned out an application that retains the functionality of Git, but at the same time has become easier to learn and use by development teams. In fact, there were already attempts to improve Git before Gitless. But according to Philip Guo (he is an assistant professor of cognitive science at the University of California, San Diego), this version for the first time achieved the goals of transforming the interface and really solving the main problems.
The project used rigorous software development techniques. This is necessary to isolate the shortcomings in one of the most widely used software projects worldwide. In the past, many users made ridiculous arguments for and against Git, but they were not all based on a scientific approach.
Using Gitless as an example, it becomes obvious that the simplification approach can be applied to other complex systems. For example, Google Inbox and Dropbox.