Transition to Google Cloud Platform (Google Cloud Platform - GCP)
- Transfer
[part 2 of 2]

How we did it
We decided to switch to GCP to improve application performance — while increasing the scale, but without significant costs. The whole process took more than 2 months. To solve this problem, we have formed a special group of engineers.
In this publication we will talk about the chosen approach and its implementation, as well as how we managed to achieve the main goal - to carry out this process as smoothly as possible and transfer the entire infrastructure to the cloud platform of the Google Cloud Platform, without compromising the quality of customer service.
Planning
- A detailed checklist has been prepared defining each possible step. Created a flowchart to describe the sequence.
- Developed a plan to return to its original state, which we, if anything, could use.
Several brain storms - and we have identified the most understandable and simple approach for implementing the “active-active” scheme. It lies in the fact that a small set of users is located on one cloud, and the rest - on the other. However, this approach caused problems, especially on the client side (related to DNS management), and caused delays in database replication. Because of this, it was almost impossible to implement it safely. The obvious method did not give the desired solution, and we had to develop a specialized strategy.
Based on the dependency diagram and operational security requirements, we divided infrastructure services into 9 modules.
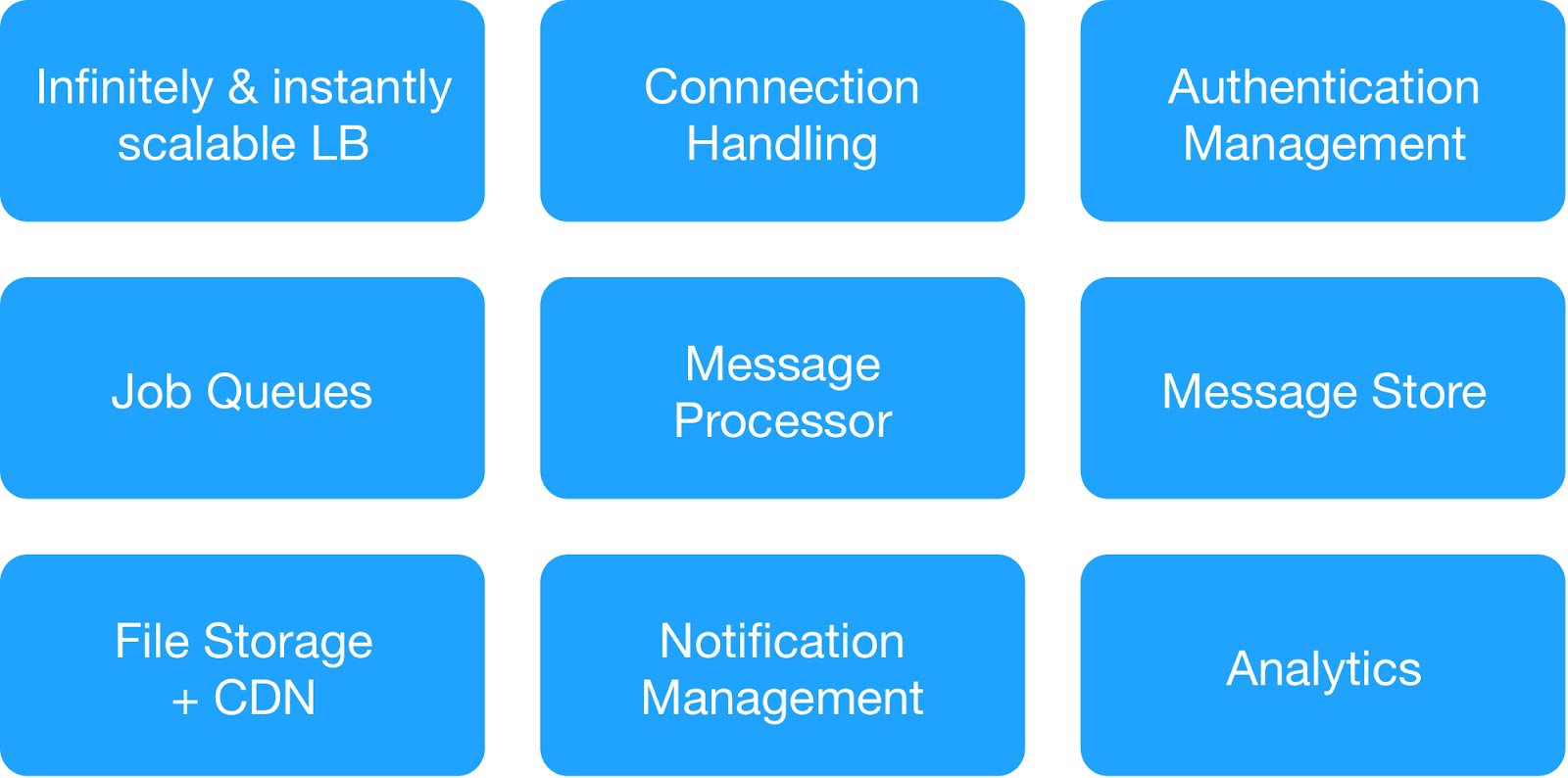
(Basic modules for infrastructure hosting deployment)
Each infrastructure group managed common internal and external services.
⊹ Infrastructure messaging service : MQTT, HTTPs, Thrift, Gunicorn server, queuing module, Async client, Jetty server, Kafka cluster.
Хранили Data Warehouse Services : MongoDB, Redis, Cassandra, Hbase, MySQL, and MongoDB distributed cluster.
⊹ Infrastructure analysis service : Kafka cluster, data storage cluster (HDFS, HIVE).
Preparing for a momentous day:
✓ Detailed GCP transition plan for each service: sequence, data storage, reset plan.
✓ Inter-project networking (VPC shared virtual private cloud [XPN]) in the GCP to isolate various parts of the infrastructure, optimize management, increase security and connectivity.
✓ Multiple VPN tunnels between the GCP and the running Virtual Private Cloud (VPC) to simplify the transfer of large amounts of data over the network during the replication process, as well as possible later deployment of a parallel system.
✓ Automate the installation and configuration of the entire stack using Chef.
✓ Scripts and automation tools for deploying, monitoring, logging, etc.
✓ Configure all required subnets and managed firewall rules for the system flow.
✓ Replication in multiple data centers (Multi-DC) for all storage systems.
✓ Configure load balancers (GLB / ILB) and groups of managed instances (MIG).
✓ Scripts and code to transfer the object storage container to the GCP Cloud Storage with checkpoints.
Soon we completed all the necessary prerequisites and prepared a checklist of the elements for transferring the infrastructure to the GCP platform. After numerous discussions, as well as considering the number of services and their dependency diagram, we decided to transfer the cloud infrastructure to GCP over three nights in order to cover all the server-side services and data storage.
Transition
Load Balancer Transfer Strategy:
We used the previously managed HAProxy cluster to replace the global load balancer to handle tens of millions of active users daily connections.
⊹ Stage 1:
- Created by MIG with packet forwarding rules to forward all traffic to the MQTT IP addresses in the existing cloud.
- Created SSL balancer and TCP Proxy with MIG as server side.
- For MIG, HAProxy is running with MQTT servers as server side.
- The weights added to the DNS in the routing policy is the external IP address of GLB.
Gradually deployed custom connections when tracking their performance.
⊹ Stage 2: Intermediate phase transition, the beginning of the deployment of services in the GCP.
⊹ Stage 3: The final stage of the transition, all services are transferred to the GCP.
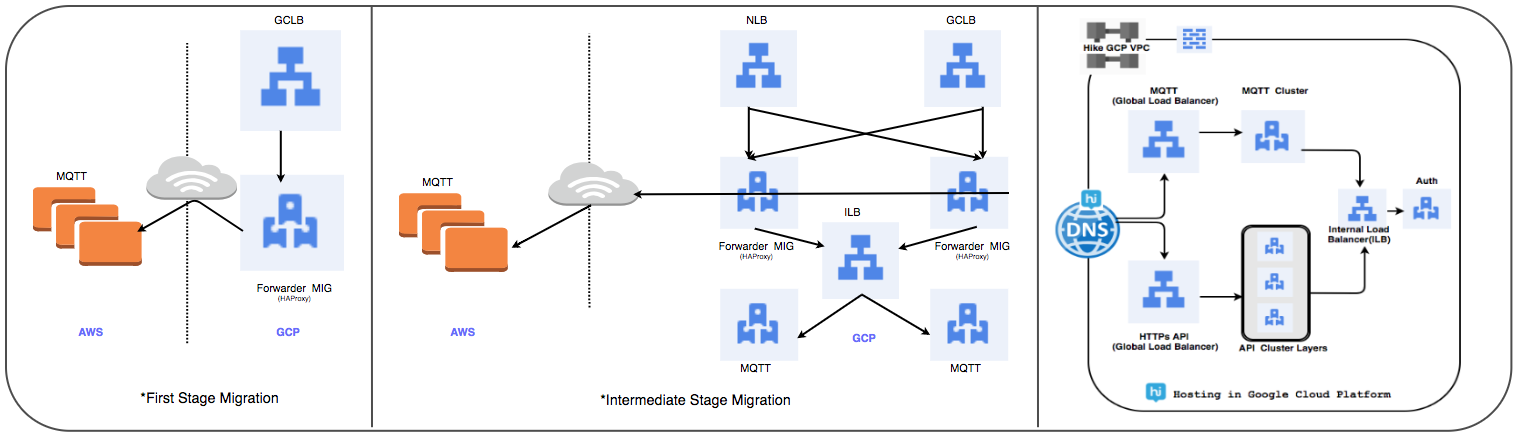
(Stages transfer load balancer)
At this stage, everything worked as expected. Soon it was time to deploy several internal HTTP services in GCP with routing — given the weight of the coefficients. We closely followed all indicators. When we started to gradually increase traffic, one day before the planned transition, delays during VPC interaction over VPN (delays of 40 ms - 100 ms were recorded, although they were less than 10 ms before) increased.
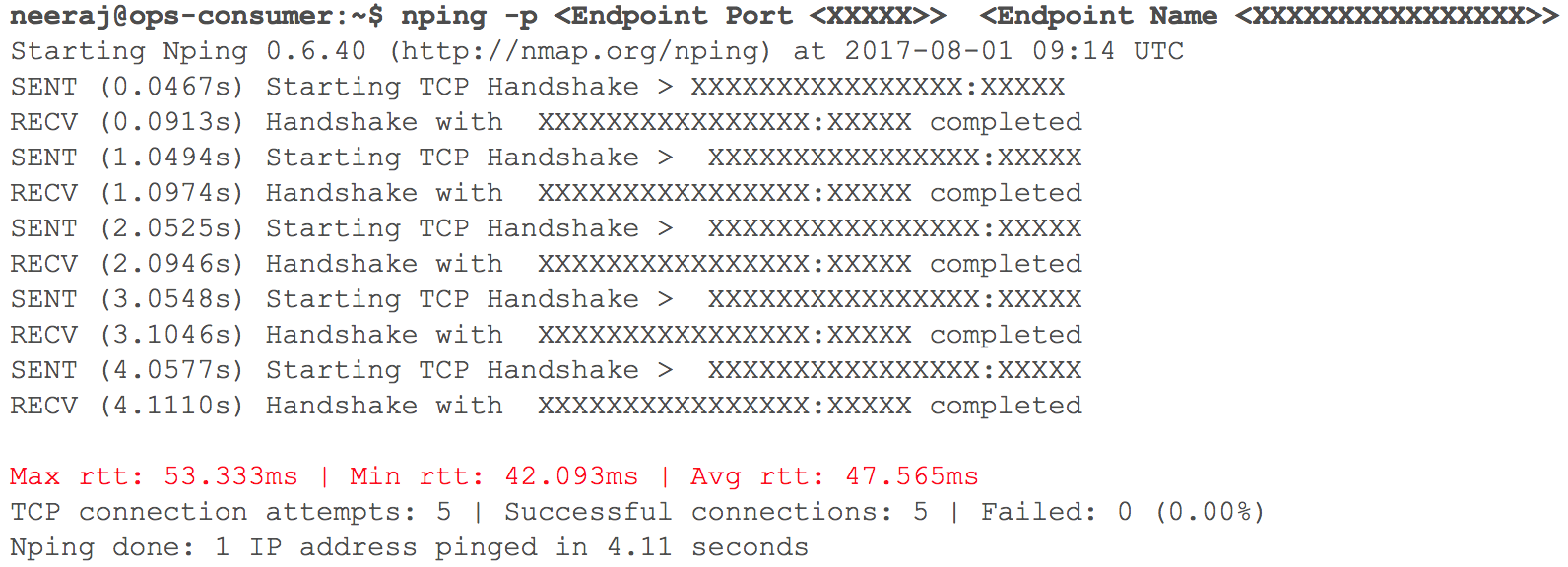
(Snapshot network latency check when two VPCs interact)
Monitoring clearly showed that there is something wrong with both cloud-based network channels using VPN tunnels. Even the throughput of the VPN tunnel did not reach the optimal level. This situation has begun to negatively affect some of our user services. We immediately returned all previously transferred HTTP services to their original state. I contacted the TAM and cloud services support teams, provided the necessary source data and started to figure out why the delays are growing. The support specialists concluded that the maximum network bandwidth in the cloud channel between the two cloud service providers was reached. From here and growth of delays in a network at transfer of internal systems.
This incident forced to suspend the transition to the cloud. Cloud service providers could not double the bandwidth fast enough. Therefore, we returned to the planning stage and revised the strategy. We decided to transfer the cloud infrastructure to GCP overnight instead of three, and included in the plan all the server-side and data storage services. When the “X” hour arrived, everything went like clockwork: the workloads were successfully transferred to Google Cloud without being noticed by our users!
Database migration strategy:
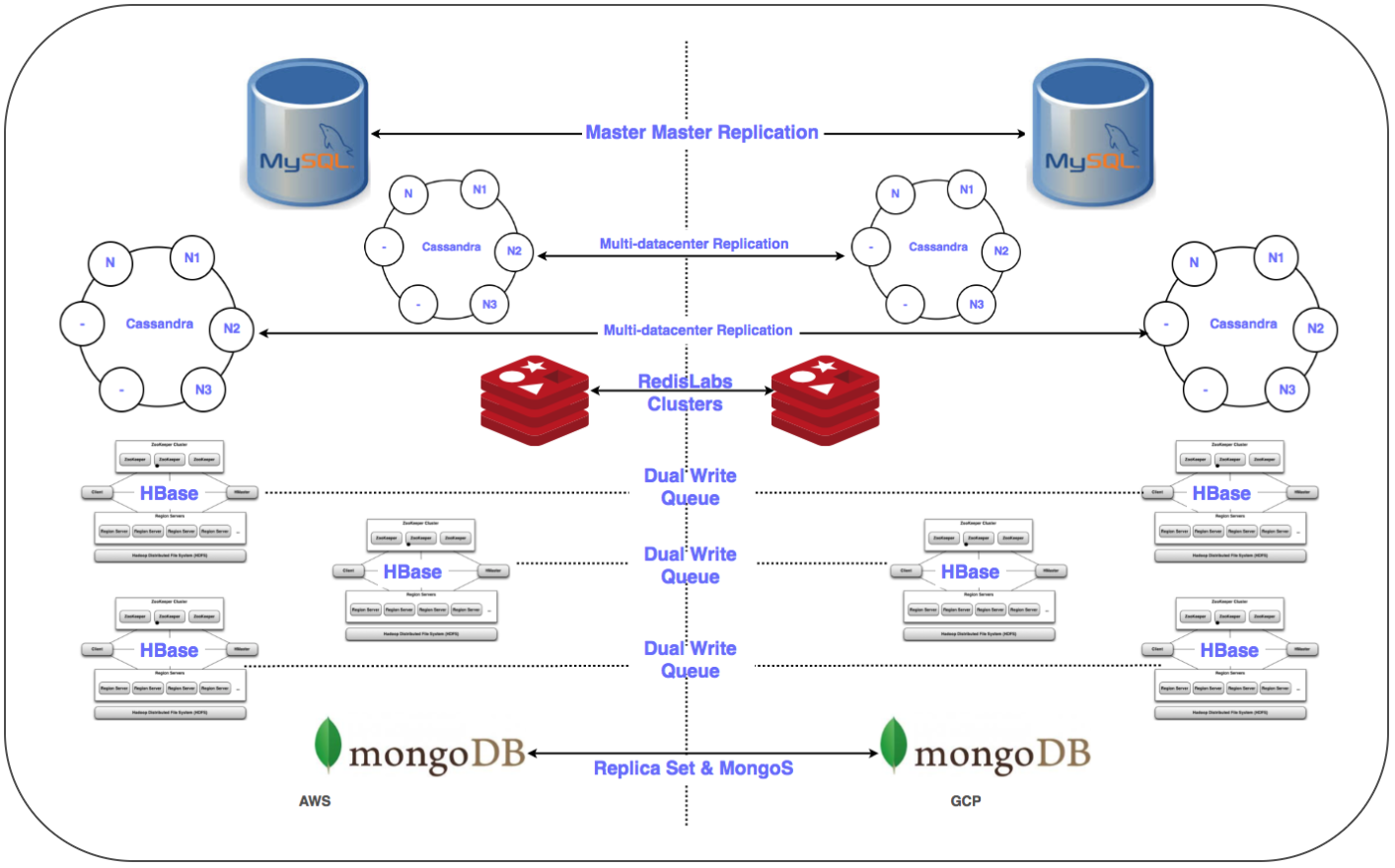
It was necessary to transfer more than 50 database endpoints for a relational DBMS, in-memory storage, as well as NoSQL and low-latency distributed and scalable clusters. Replicas of all databases we placed in GCP. This was done for all deployments, with the exception of HBase.
Вед master-slave replication: implemented for MySQL, Redis, MongoDB and MongoS clusters.
⊹ Multi-DC Replication: implemented for Cassandra clusters.
⊹ Dual Clusters: a parallel cluster has been configured for Hbase in GCP. Existing data was transferred, a double entry was set up in accordance with the strategy for maintaining data consistency in both clusters.
In the case of HBase, the problem was to configure with Ambari. We encountered some difficulties when placing clusters in several data centers, for example, there were problems with the DNS, the rack recognition script, and so on.
The final steps (after migrating the servers) included moving replicas to the main servers and disabling the old databases. As planned, determining the order of database transfer, we used Zookeeper for the necessary configuration of application clusters.
Application Services Migration Strategy
We used the lift-and-shift approach to transfer application service workloads from the current hosting to the GCP cloud. For each application service, we created a group of managed instances (MIG) with automatic scaling.
In accordance with the detailed plan, we began to transfer services to GCP, taking into account the sequence and dependencies of data warehouses. All messaging stack services have been ported to GCP without the slightest downtime. Yes, there were some minor failures, but we dealt with them immediately.
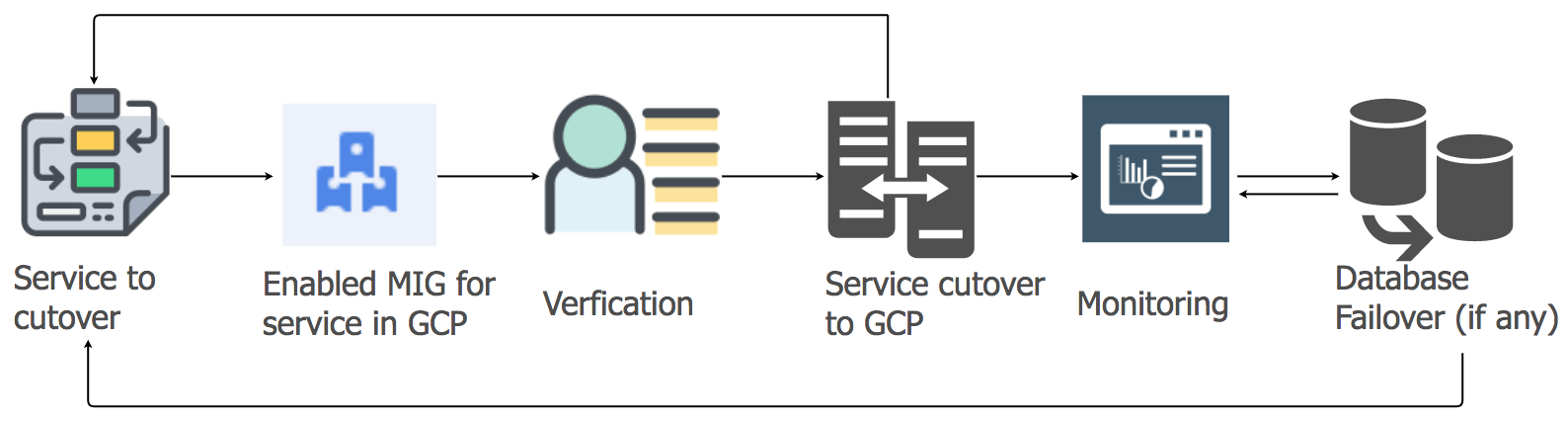
Since the morning, as the activity of users increased, we closely followed all information panels and indicators to quickly identify problems. Some difficulties and the truth arose, but we were able to quickly eliminate them. One of the problems was due to the limitations of the internal load balancer (ILB), capable of serving no more than 20,000 simultaneous connections. And we needed 8 times more! Therefore, we have added additional ILB to our compound management layer.
During the first hours of the peak load after the transition, we controlled all parameters especially carefully, since the entire load of the messaging stack was transferred to the GCP. There were a few minor glitches, which we very quickly figured out. When migrating other services, we followed the same approach.
Transferring object storage:
We use the object storage service mainly in three ways.
⊹ Storage of media files sent to a personal or group chat. The retention period is determined by the lifecycle management policy.
⊹ Storage of images and thumbnails of a user profile.
Storage of media files from the “History” and “Timeline” sections and corresponding thumbnails.
We used Google's storage transfer tool to copy old objects from S3 to GCS. We also used a custom Kafka-based MIG to transfer objects from S3 to GCS when special logic was required.
The transition from S3 to GCS included the following steps:
● For the first use case of the object storage, we began to write new data in both S3 and GCS, and after the expiration date, we began to read data from GCS using the application-side logic. Transferring old data does not make sense, and this approach is cost-effective.
● For the second and third use cases, we started recording new objects in GCS and changed the path for reading data so that the search is first performed in GCS and only then, if the object is not found, in S3.
The planning, validation of the concept, preparation and prototyping took months , but then we decided to go and implemented it very quickly. We assessed the risks and realized that fast migration is preferable and almost imperceptible.
This large-scale project has helped us take confident positions and increase team productivity in many areas, since most of the manual operations for managing cloud infrastructure are now in the past.
● As for users, we now have everything we need to ensure the highest quality of service. Downtime has almost disappeared, and new features are being introduced faster.
● Our team spends less time on maintenance tasks and can focus on automation projects and creating new tools.
● We have access to an unprecedented set of tools for working with big data, as well as ready-made functionality for machine learning and analysis. See details here.
● Google Cloud’s commitment to open source Kubernetes is also in line with our development plan for this year.