Creating your own graph processing application in Giraph

Be my friend by oosDesign
Large Internet companies often face such complex tasks as processing big data and analyzing social network graphs. The frameworks help in their decision, but first you need to analyze the possible options and choose the right one. In the laboratory at the Technosphere Mail.Ru, we study these issues using real-life examples from Mail.Ru Group projects (myTarget, Mail.Ru Search, Antispam). Tasks can be both purely practical and with a research component. Based on one of these tasks, this article appeared.
During the assembly and launch of their first project on Giraph, the employees of the Technosphere Data Analysis Lab Mail.Ru encountered a number of problems, which led to the idea of writing a short tutorial on how to build and launch their first Giraph project.
In this article, we will tell you how to create your own applications for the Giraph framework, which is an add-on for the popular Hadoop data processing system.
0. What is a Giraph
Giraph is a large graph iterative framework that runs on top of the highly popular Hadoop distributed data processing system. Just as the impetus for Hadoop and HDFS came from a Google article on the concept of MapReduce and GFS (Google File System), Giraph appeared as an open source version of Google's Pregel, an article about which was published in 2010. Giraph is used by large corporations like Facebook to process graphs.
What is the feature of Giraph? Its main “trick” is the so-called vertex-centric-model. As written in Practical Graph Analytics with Apache Giraph :
This model requires the developer to be in the shoes of the peaks, which can exchange messages with other peaks between iterations. During development, you don’t have to think about the problems of parallelization and scaling - this is what Giraph does.
Graph processing in Giraph is as follows: the process is divided into iterations called supersteps. At each superstep, the vertex executes the necessary program and, if necessary, can send messages to other vertices. At the next iteration, the vertex receives messages, executes the program, sends messages, etc. After completing all the supersteps, you will get the resulting graph.
Giraph supports a large number of possibilities for interacting with the graph, including creating / deleting vertices, creating / deleting edges, the ability to override the format in which the graph is specified or select from existing ones, control loading from disk and unloading parts of the graph to disk while working with it and much more. For details, see Practical Graph Analytics with Apache Giraph.
1. Required software
First you need Hadoop itself. If you do not have access to a cluster with Hadoop, you can deploy its single-node version. She is not very demanding on resources, on a laptop it will work quietly. For this, for example, you can use the Hadoop distribution called Cloudera. You can find the Cloudera installation manual here . During development and testing, Cloudera 5.5 (Hadoop 2.6.0) was used in this article.
Giraph is implemented in Java. When building projects, the Maven build manager is used . Giraph source code can be downloaded from the official website . Instructions for compiling Giraph itself and the examples that come with it can be found here and in the Quick Start Guide .
Any IDE, such as Eclipse or IntelliJ IDEA, can work with Maven in projects, which is very convenient during development. We used IntelliJ IDEA in our experiments.
2. Compiling Giraph
First, let's compile the contents of the Giraph sources and try to run something. As mentioned in the instructions , in the folder with the Giraph project, we execute the command:
mvn -Phadoop_2 -fae -DskipTests clean install
And we wait for a while while everything is going to go ... The jar-files collected will appear in the giraph-examples / target folder, we will need giraph-examples-1.2.0-SNAPSHOT-for-hadoop-2.5.1-jar-with-dependencies. jar.
Let's run, for example, SimpleShortestPathsComputation . First we need a file with input data. Take an example from the Quick Start Guide :
[0,0,[[1,1],[3,3]]]
[1,0,[[0,1],[2,2],[3,1]]]
[2,0,[[1,2],[4,4]]]
[3,0,[[0,3],[1,1],[4,4]]]
[4,0,[[3,4],[2,4]]]
Save this to tiny_graph.txt and put it in HDFS in our local folder:
hdfs dfs -put ./tiny_graph.txt ./
With this command, the file will go to your local directory. You can verify this by displaying the contents of the file:
hdfs dfs -text tiny_graph.txt
Ok, everything is cool, and now let's start:
hadoop jar \
giraph-examples-1.2.0-SNAPSHOT-for-hadoop-2.5.1-jar-with-dependencies.jar \
org.apache.giraph.GiraphRunner \
org.apache.giraph.examples.SimpleShortestPathsComputation \
-vif org.apache.giraph.io.formats.JsonLongDoubleFloatDoubleVertexInputFormat \
-vip tiny_graph.txt \
-vof org.apache.giraph.io.formats.IdWithValueTextOutputFormat \
-op shortestpaths \
-w 1
Let's see what is written here:
hadoop jar giraph-examples-1.2.0-SNAPSHOT-for-hadoop-2.5.1-jar-with-dependencies.jar- this part of the command tells Khadup to run the jar file;org.apache.giraph.GiraphRunnerIs the name of the ranner. Here the default is used. Rahner can be redefined. So that he, for example, at the start, deletes old data or performs some other preparatory actions. You can read more about this in the book Practical Graph Analytics with Apache Giraph;org.apache.giraph.examples.SimpleShortestPathsComputation- a class containing the compute method to be executed;-vifdefines the class that will read the input file with vertices. This class is selected depending on the format of the input file and may be different; you can even override it if necessary (see Practical Graph Analytics with Apache Giraph). Description of standard classes can be found here ;-vip- path to the input file that contains descriptions of the vertices;-vof- in what format the result of work will be saved. If desired, redefined; descriptions of standard classes see here ;-op- where to save;-w- the number of workers (processes that process the graph vertically).
You can learn more about startup options by typing in the console:
hadoop jar \
giraph-examples-1.2.0-SNAPSHOT-for-hadoop-2.5.1-jar-with-dependencies.jar \
org.apache.giraph.GiraphRunner \
org.apache.giraph.examples.SimpleShortestPathsComputation -h
After starting, we can read the result in shortestpaths by doing
hdfs dfs -text shortestpaths/*
3. Creating your own project
Now let's write an application that will calculate the degree of vertices in an undirected graph. I am creating a new Maven project. How to do this is written, for example, here . At the root of the project is pom.xml, fill it as follows:
4.0.0 ru.simple.giraph.project.org simple-giraph-project 1.0-SNAPSHOT cloudera
https://repository.cloudera.com/artifactory/cloudera-repos/
2.6.0-cdh5.5.1 maven-assembly-plugin 2.4 simple-giraph-project
${project.basedir}/src/main/assembly/single-jar.xml
single package org.apache.hadoop hadoop-client ${org.apache.hadoop.version} org.apache.hadoop hadoop-common ${org.apache.hadoop.version} org.apache.giraph giraph-core 1.1.0-hadoop2 com.google.guava guava 19.0 You can read about how to create pom-files and work with Maven in the official guide here . After that, in src, I create a new ComputationDegree.java file. This will be our class, which will take into account degrees of vertices:
/**
* This is a simple implementation of vertex degree computation.
*/
package ru.simple.giraph.project.org;
import com.google.common.collect.Iterables;
import org.apache.giraph.graph.BasicComputation;
import org.apache.giraph.graph.Vertex;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import java.io.IOException;
public class ComputeDegree extends
BasicComputation {
public void compute(Vertex vertex, Iterable iterable) throws IOException {
if (getSuperstep() == 0){
sendMessageToAllEdges(vertex, new Text());
} else if (getSuperstep() == 1){
Integer degree = Iterables.size(vertex.getEdges());
vertex.setValue(new IntWritable(degree));
}else{
vertex.voteToHalt();
}
}
}
It works like this:
- In the first step, each vertex sends messages to its neighbors.
- Each vertex counts the number of incoming messages and stores them in the vertex value.
- All vertices vote to stop computing.
At the output, we have a graph that stores the degree of the vertex in the value of the vertex. We compile with the command:
mvn package -fae -DskipTests clean install
Usually, after compilation, the target folder is created, which contains the giraph-test-fatjar.jar file. This file we will run. Let's take some very simple graph, for example this one:
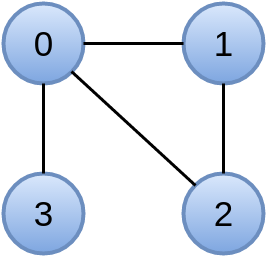
We will use org.apache.giraph.io.formats.IntIntNullTextVertexInputFormat as the input data format , so the file describing our graph will look like this:
0 0 1 2 3
1 0 0 2
2 0 0 1
3 0 0
We save it in the example_graph.txt file, put it on HDFS and run our program:
hadoop jar ./target/giraph-test-fatjar.jar org.apache.giraph.GiraphRunner \
ru.giraph.test.org.ComputeDegree \
-vif org.apache.giraph.io.formats.IntIntNullTextVertexInputFormat \
-vip example_graph.txt \
-vof org.apache.giraph.io.formats.IdWithValueTextOutputFormat \
-op degrees \
-w 1
We look at the result:
hdfs dfs -text degrees/*
And we see something like this:
0 3
2 2
1 2
3 1
So, in this article we learned how to compile Giraph and wrote our own little application. And the whole project can be downloaded here .
In the next article, we will talk about working with Giraph using the example of the Restricted Boltzmann Machine learning algorithm. We will try to speed up the algorithm as much as possible in order to understand the intricacies of Giraph settings and evaluate how convenient and efficient this system is.