Speech analytics for call centers based on SOLR
I want to talk about our experience in developing applications based on the Apache Solr full-text search platform.
Our task was to develop a speech analytics system for contact centers. The system is based on two basic technologies: speech recognition and indexed search. For recognition, we used our engines, and for indexing and searching we chose Solr.
Why choose Solr? We did not conduct our own comparative studies of indexed search engines, but carefully read the opinions of our colleagues . Of course, the choice could be made in favor of Elasticsearch or Sphinx, but, apparently, the stars in our project were in favor of Solr, and we “sawed” him. Already in the course of the project, we determined that the settings available in Solr are sufficient for configuring for our tasks.
The system was developed for analyzing customer calls, which are recorded in the contact center to monitor the quality of service. It is not the sound that is analyzed, but the text obtained as a result of automatic recognition of the dialogue. The texts of recognized speech are fundamentally different from the texts that we regularly encounter on websites or e-mail. Even with 100% recognition accuracy, the texts of recognized spontaneous speech may seem to be devoid of any meaning.
This is due to two main factors. First, in verbal speech, nonverbal and mimic means are often used that are not recognized in the text, but are important for understanding what has been said. Secondly, in speech, abbreviations and omissions of language structures are constantly used, which can be restored from the context of a communicative situation. This phenomenon in linguistics is called ellipsis.
To see with your own eyes the text of a recognized speech with all its features, look at the automatic subtitles for the video on youtube with the sound turned off. That's about the content of this material is fed to the input of speech analytics.
Although Solr supports standard conditional operators and groupings , often these capabilities are not enough to implement all the analytics work scenarios.
Often the analyst needs to build a query with parameters that are not part of the Solr index. For example, find all the words “thank you” that are spoken in the last 30 seconds of the conversation. Words are indexed by Solr, but temporary positions are not words. We call such queries “complex” - queries that include both the parameters of the Solr index and any other data selection parameters that are not included in the Solr index.
The analyst has no idea about the composition of the Solr index, it is important for him to search and cut across all the attributes of the phonograms of calls and their text transcripts. Therefore, the concept of “complex query” for the analyst is purely pragmatic: there are many requests in which there are many selection parameters, or requests are arranged in a hierarchy.
Describing the actions of the analyst in the language of set theory, it can be said that with the help of queries, the analyst explores the relationship between different subsets: intersections, differences, and additions. Using hierarchical queries, the analyst parses the array of data to the required level of detail of its structure.
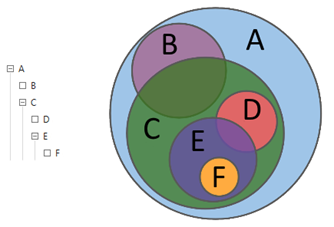
Figure 1. Hierarchical queries
Figure 2 presents a classic example of a complex query that contains both textual and numeric selection criteria.
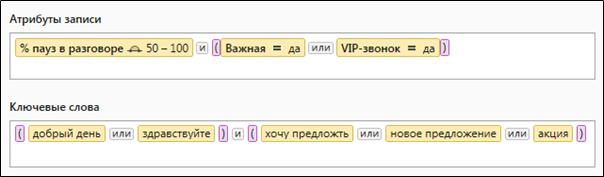
Figure 2. A complex query containing quantitative and lexical parameters for selecting data
Consider the general mechanism for executing a query in Solr using the example of query B in Figure 1. As we can see, query B has a parent query A , in other words, B⊆A . In speech analytics, the request cannot be executed until at least one of his “parents” is unfulfilled. Thus, first a request is made A and then B . Obviously, In should contain the query terms A .
The first thing that comes to mind is to combine the conditions of both requests through
However, if we simply merge all consecutive requests into one
Let's try adding parent queries as
If we look at the format of the query to Solr schematically, we can distinguish two main entities:
Splitting a request into
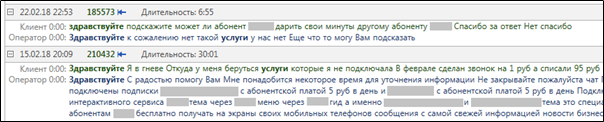
Figure 3.
Let's return to the example of a polite operator. In this example, we identified suitable calls based on the presence of the phrase “good afternoon” in the operator's speech, but did not specify the time period in which you need to search for keywords relative to the beginning or end of the conversation.
It seems that for this there is everything you need - a text transcript of a telephone conversation contains a timestamp timestamp for each word, as well as information about which of the participants in the dialogue it belongs to. This data can also be used when searching.
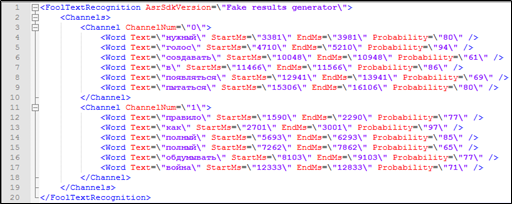
Figure 4. Fragment of text interpretation with markup, not included in the Solr index: the speaker belongs to it, time stamps.
But how to process a search query to Solr, if non-indexable parameters are involved in the query - the time the word is pronounced?
This suggests two obvious ways to solve this problem:
We have chosen the second option. To do this, we have developed a service that performs the calculation of collections for queries that contain any logical and numeric parameters that are not part of the Solr index. As a result of this service, a part of the collection that did not satisfy the request was marked with a special tag (“screened”) and then no longer participated in the calculation of the results of the request.
Imagine that we want to impose on the already familiar to us query B limit on the search only in the first 30 seconds of the dialogue. In the first stage, we perform Bas a simple query, we further “screen” words that fall outside the selected range so that they do not fall into the Solr index, but at the same time, we could recover the original document from them. The resulting documents are placed in a separate collection Solr and it restarts search for Bed and .
Here it must be said that restrictions on the beginning or end of a conversation are flowers, berries are restrictions on the results of the parent request. Consider the execution of a similar request.
In practice, behind balls 5 and 6, requests that occupy several screens in their textual representation are usually hidden. I am glad that we have implemented such a search for good reason - analysts often use queries with restrictions from the parent.
What have we learned, what have we learned and what have we achieved as a result of the project?
We know how to effectively use Solr to work with data of different types, we can “teach” Solr to process queries with parameters that are not included in its search index.
We have developed a high-load industrial speech analytics system: complex analytics search queries are calculated for samples of up to five million text documents. It is possible and more, but there was no practical need. The usual working sample of the analyst is approximately up to 500 thousand texts of recognized telephone calls, and the total number of calls can reach 15 million.
For our clients in contact centers, the system provides unprecedented opportunities for analytics of a very different nature: analysis of topics and reasons for calls, analysis of customer satisfaction, and many others.
Now we are connecting to our analytics new sources - text chat clients with operators. We are implementing a single application for analyzing customer requests through all channels of the contact center: telephone, chat, forms on websites, etc. We
will be happy to answer your questions.
Thank.
PS Solr is a very difficult thing and requires good tuning to get good results. We will tell about our experience in this field in the following articles.
Our task was to develop a speech analytics system for contact centers. The system is based on two basic technologies: speech recognition and indexed search. For recognition, we used our engines, and for indexing and searching we chose Solr.
Why choose Solr? We did not conduct our own comparative studies of indexed search engines, but carefully read the opinions of our colleagues . Of course, the choice could be made in favor of Elasticsearch or Sphinx, but, apparently, the stars in our project were in favor of Solr, and we “sawed” him. Already in the course of the project, we determined that the settings available in Solr are sufficient for configuring for our tasks.
Features of our project
The system was developed for analyzing customer calls, which are recorded in the contact center to monitor the quality of service. It is not the sound that is analyzed, but the text obtained as a result of automatic recognition of the dialogue. The texts of recognized speech are fundamentally different from the texts that we regularly encounter on websites or e-mail. Even with 100% recognition accuracy, the texts of recognized spontaneous speech may seem to be devoid of any meaning.
This is due to two main factors. First, in verbal speech, nonverbal and mimic means are often used that are not recognized in the text, but are important for understanding what has been said. Secondly, in speech, abbreviations and omissions of language structures are constantly used, which can be restored from the context of a communicative situation. This phenomenon in linguistics is called ellipsis.
To see with your own eyes the text of a recognized speech with all its features, look at the automatic subtitles for the video on youtube with the sound turned off. That's about the content of this material is fed to the input of speech analytics.
Complex queries
Although Solr supports standard conditional operators and groupings , often these capabilities are not enough to implement all the analytics work scenarios.
Often the analyst needs to build a query with parameters that are not part of the Solr index. For example, find all the words “thank you” that are spoken in the last 30 seconds of the conversation. Words are indexed by Solr, but temporary positions are not words. We call such queries “complex” - queries that include both the parameters of the Solr index and any other data selection parameters that are not included in the Solr index.
How does the analyst generate queries?
The analyst has no idea about the composition of the Solr index, it is important for him to search and cut across all the attributes of the phonograms of calls and their text transcripts. Therefore, the concept of “complex query” for the analyst is purely pragmatic: there are many requests in which there are many selection parameters, or requests are arranged in a hierarchy.
Describing the actions of the analyst in the language of set theory, it can be said that with the help of queries, the analyst explores the relationship between different subsets: intersections, differences, and additions. Using hierarchical queries, the analyst parses the array of data to the required level of detail of its structure.
Figure 1. Hierarchical queries
Figure 2 presents a classic example of a complex query that contains both textual and numeric selection criteria.
Figure 2. A complex query containing quantitative and lexical parameters for selecting data
What are the queries for Solr?
Consider the general mechanism for executing a query in Solr using the example of query B in Figure 1. As we can see, query B has a parent query A , in other words, B⊆A . In speech analytics, the request cannot be executed until at least one of his “parents” is unfulfilled. Thus, first a request is made A and then B . Obviously, In should contain the query terms A .
The first thing that comes to mind is to combine the conditions of both requests through
ANDand insert them into query: q=key:A AND key:BHowever, if we simply merge all consecutive requests into one
query, it will be big, for each request different and will be calculated entirely. Also, the conditions A will affect the relevance of the results of the query B , which would not be very desirable. Let's try adding parent queries as
FilterQuery. In this case, query A will not be affected by irrelevance, and we can expect that it has already been completed and its results are in the cache. Thus, Solr will have to calculate only query B , while Solr will sort the resulting sample in the necessary way: q=keyword:B &fq=keyword:AIf we look at the format of the query to Solr schematically, we can distinguish two main entities:
MainQuery- the main request with a set of parameters that must satisfy the desired document. For example, a search request courteous operators will look liketext_operator: ”добрый день”.
This means that the text_operator field of the document being searched for must contain the phrase“добрый день”FilterQuery- a set of additional filters that limit the resulting sample. Its format is theFilterQuerysame asMainQuery
Splitting a request into
Mainand Filterallows you to:- Explicitly indicate which query parameters should affect the rank of the document in the sample, and which serve only for selection in the resulting sample. The relevance for building the rank of documents is calculated when part of the query is executed MainQuery, and when part of the query is executed,
FilterQuerydocuments that do not satisfy the conditions of the query are eliminated - significantly reduce the load on the search engine, since the resulting sample obtained after the calculations
FilterQueryis cached completely, whereas the results of the calculationsMainQueryare stored in the cache only for the first 50 values in the rank
MainQuery and FiletrQuery affect Solr functions in different ways. For example, for highlighting - the function responsible for highlighting relevant fragments of a document - matters only MainQuery, and the parameters FilterQuery do not affect highlighting. This is logical, because the relevance is calculated in terms of the request MainQuery. This is how the results of work highlighting in a real search query with the words “hello” and “services” look like . Figure 3.
highlighting for relevant words after the query MainQuery.Complicated requests to Solr
Let's return to the example of a polite operator. In this example, we identified suitable calls based on the presence of the phrase “good afternoon” in the operator's speech, but did not specify the time period in which you need to search for keywords relative to the beginning or end of the conversation.
It seems that for this there is everything you need - a text transcript of a telephone conversation contains a timestamp timestamp for each word, as well as information about which of the participants in the dialogue it belongs to. This data can also be used when searching.
Figure 4. Fragment of text interpretation with markup, not included in the Solr index: the speaker belongs to it, time stamps.
But how to process a search query to Solr, if non-indexable parameters are involved in the query - the time the word is pronounced?
This suggests two obvious ways to solve this problem:
- add non-indexed parameters to the Solr index. At the same time, memory consumption will increase slightly, but significantly weighted index
- to select data on non-indexable parameters using your service, and in the collection of documents obtained after such a selection, search using the Solr index. In this case, the memory consumption will be much more than in the first case, but the performance will be predictable
We have chosen the second option. To do this, we have developed a service that performs the calculation of collections for queries that contain any logical and numeric parameters that are not part of the Solr index. As a result of this service, a part of the collection that did not satisfy the request was marked with a special tag (“screened”) and then no longer participated in the calculation of the results of the request.
Imagine that we want to impose on the already familiar to us query B limit on the search only in the first 30 seconds of the dialogue. In the first stage, we perform Bas a simple query, we further “screen” words that fall outside the selected range so that they do not fall into the Solr index, but at the same time, we could recover the original document from them. The resulting documents are placed in a separate collection Solr and it restarts search for Bed and .
Here it must be said that restrictions on the beginning or end of a conversation are flowers, berries are restrictions on the results of the parent request. Consider the execution of a similar request.
| Imagine that our documents consist of balls with numbers. Let's try to find all the balls “6” that are not more than two balls to the right of “5”. You have already understood that the numbers of the balls are included in the Solr index, but the distance between the balls is not. |  |
Find all documents with balls “6” and “5”. As the MainQuery use of the request for the balls “5”, and the request for the “6” will be sent to FilterQuery. As a result, Solr will highlight the balls “5” in the search results, which will greatly simplify our lives in the next step. | 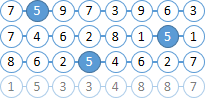 |
| We screen all the balls except those that are at the distance we need from “5”. The received documents (documents with the required balls) will be placed in a separate collection. |  |
Perform FilterQuery the balls “6” in the resulting collection, the result - the documents we are looking for. |  |
In practice, behind balls 5 and 6, requests that occupy several screens in their textual representation are usually hidden. I am glad that we have implemented such a search for good reason - analysts often use queries with restrictions from the parent.
Conclusion
What have we learned, what have we learned and what have we achieved as a result of the project?
We know how to effectively use Solr to work with data of different types, we can “teach” Solr to process queries with parameters that are not included in its search index.
We have developed a high-load industrial speech analytics system: complex analytics search queries are calculated for samples of up to five million text documents. It is possible and more, but there was no practical need. The usual working sample of the analyst is approximately up to 500 thousand texts of recognized telephone calls, and the total number of calls can reach 15 million.
For our clients in contact centers, the system provides unprecedented opportunities for analytics of a very different nature: analysis of topics and reasons for calls, analysis of customer satisfaction, and many others.
Now we are connecting to our analytics new sources - text chat clients with operators. We are implementing a single application for analyzing customer requests through all channels of the contact center: telephone, chat, forms on websites, etc. We
will be happy to answer your questions.
Thank.
PS Solr is a very difficult thing and requires good tuning to get good results. We will tell about our experience in this field in the following articles.