NetApp MetroCluster (MCC)
MetroCluster is a geo-distributed, fault-tolerant cluster built on the basis of NetApp FAS data storage systems. Such a cluster can be imagined as a single storage system stretched over two sites, where in case of an accident at one of the sites there is always a complete copy of the data. MetroCluster is used to create highly available (HA) storage and services. More details on MCC official documentation .
MetroCluster running on the old OS Data ONTAP 7-Mode (up to version 8.2.x) had the abbreviation "MC", and working on ClusteredONTAP (8.x and older), to avoid confusion, it is customary to call MetroCluster ClusteredONTAP (MCC).
An MCC may consist of two or more controllers. There are three MCC connection schemes:
The difference in these three options is essentially only in the network harness. The network binding affects two factors: the maximum possible distance over which the cluster can be stretched and the number of nodes in the cluster.
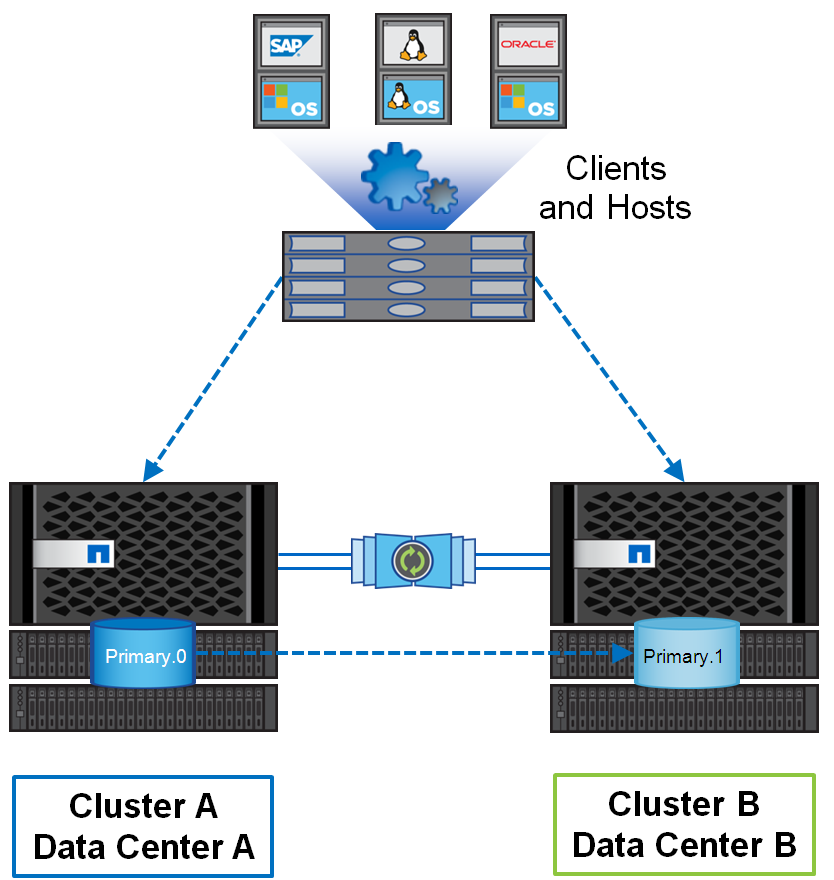
This configuration can consist of either two or 4 identical controllers. The two-node configuration (mcc-2n) can be converted to four-node configuration (mcc). In a two-day configuration, each site has one controller and, if one controller exits, the second one on the other site takes control, this is called switchover . If there is more than one node on each site, and one cluster node fails, then a local HA failover occurs without switching to the second site. MetroCluster can stretch up to 300 km.
This is the most expensive scheme of all connection options, since it requires the presence of:
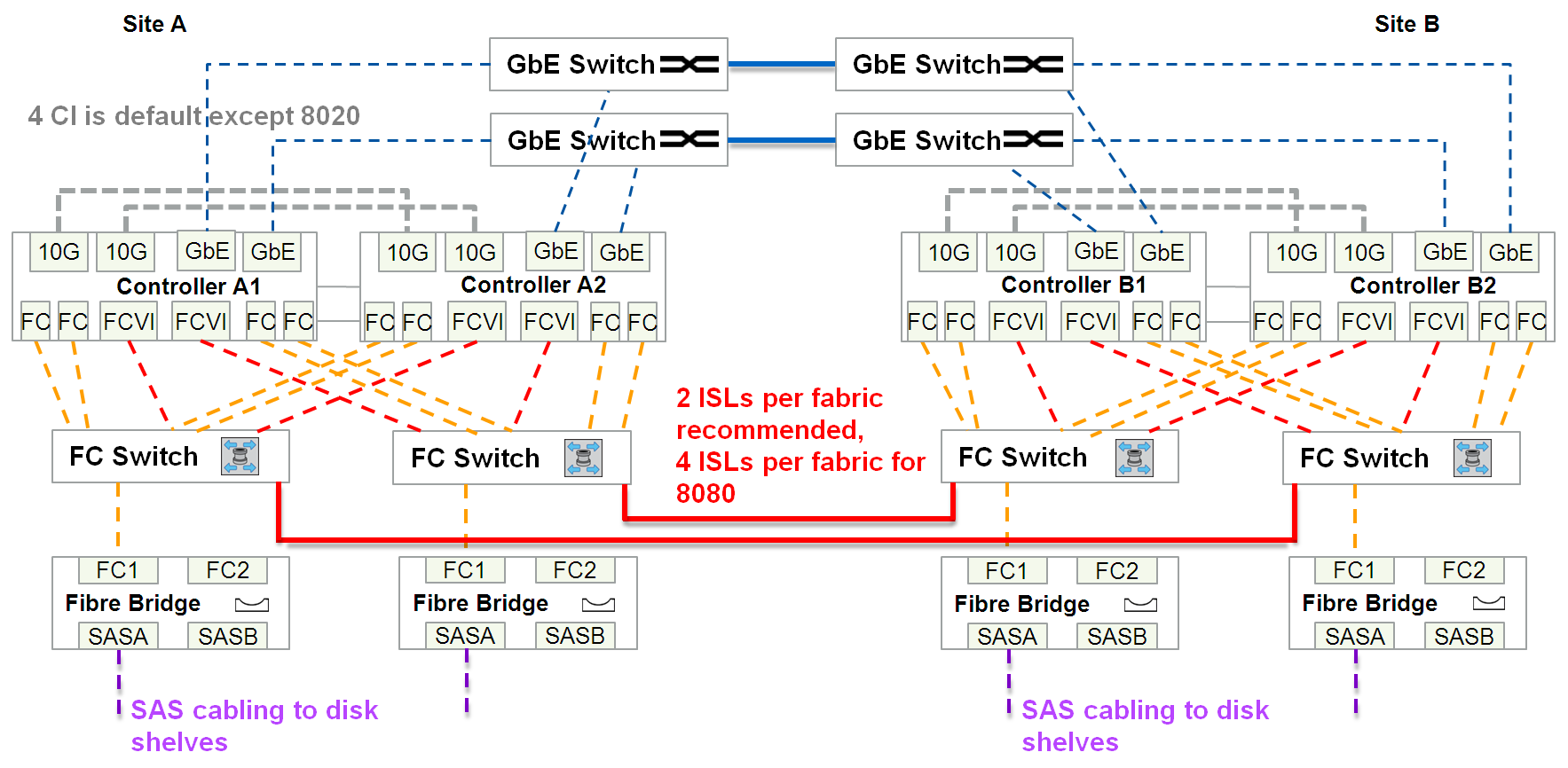
In total, between the two sites, at least 4 wires are required, plus Cluster peering.
By analogy with the 4-node Fabric-Attached MetroCluster configuration, there is an eight-node configuration, which so far supports only NAS access protocols and ONTAP 9 firmware. Four-node configuration can be updated to eight nodes. This configuration does not yet support SAN access protocols. In an eight-node configuration, 4 nodes are located on one site and 4 on another. From the network point of view, nothing changes much, in a similar Fabric-Attached MetroCluster 4-node scheme: the number of FC switches on the backend remains the same, only the number of required ports on each site for local switching increases, but cross-site connections and cross-site ports can be as many. In this scheme, we need cluster switches for 4-channel communication on each site, while 2 and 4 node configurations do not require cluster switches. The advantage of the 8-node configuration is the possibility of using two types of FAS systems in one cluster, for example, on one site you have FAS8040 (two nodes) and All Flash FAS 8060 (two nodes), on the other site we have exactly the same mirror configuration FAS8040 (two nodes) and All Flash FAS 8060 (two nodes). Data from one site on the FAS8040 system is replicated to the same FAS8040 system on another site and similarly for All Flash FAS 8060. Data within the site can transparently migrate to these cluster nodes. on another site we have exactly the same mirror configuration FAS8040 (two nodes) and All Flash FAS 8060 (two nodes). Data from one site on the FAS8040 system is replicated to the same FAS8040 system on another site and similarly for All Flash FAS 8060. Data within the site can transparently migrate to these cluster nodes. on another site we have exactly the same mirror configuration FAS8040 (two nodes) and All Flash FAS 8060 (two nodes). Data from one site on the FAS8040 system is replicated to the same FAS8040 system on another site and similarly for All Flash FAS 8060. Data within the site can transparently migrate to these cluster nodes.
It can stretch up to 500 meters and requires the presence of:
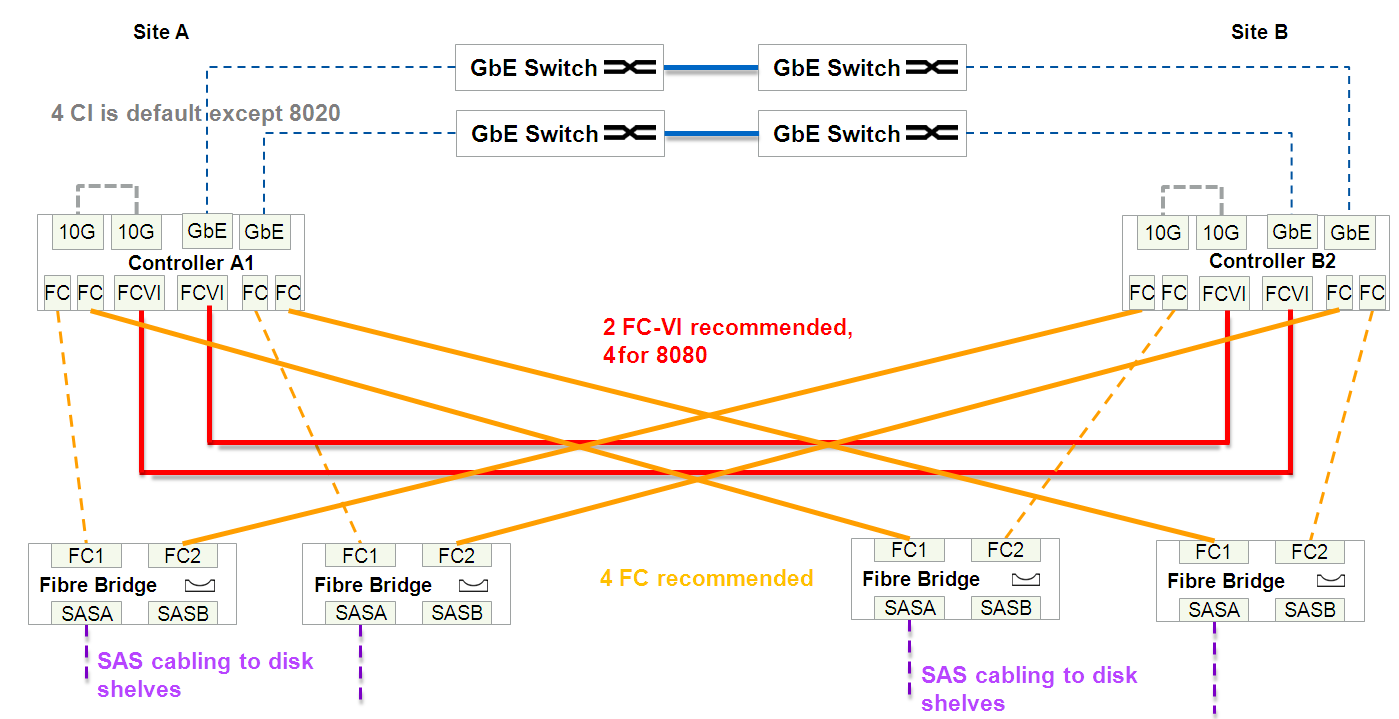
In total, between two sites a minimum of 4 + 8 = 12 cores is required, plus Cluster peering.
The cheapest option. It can stretch up to 500 meters and requires the presence of:
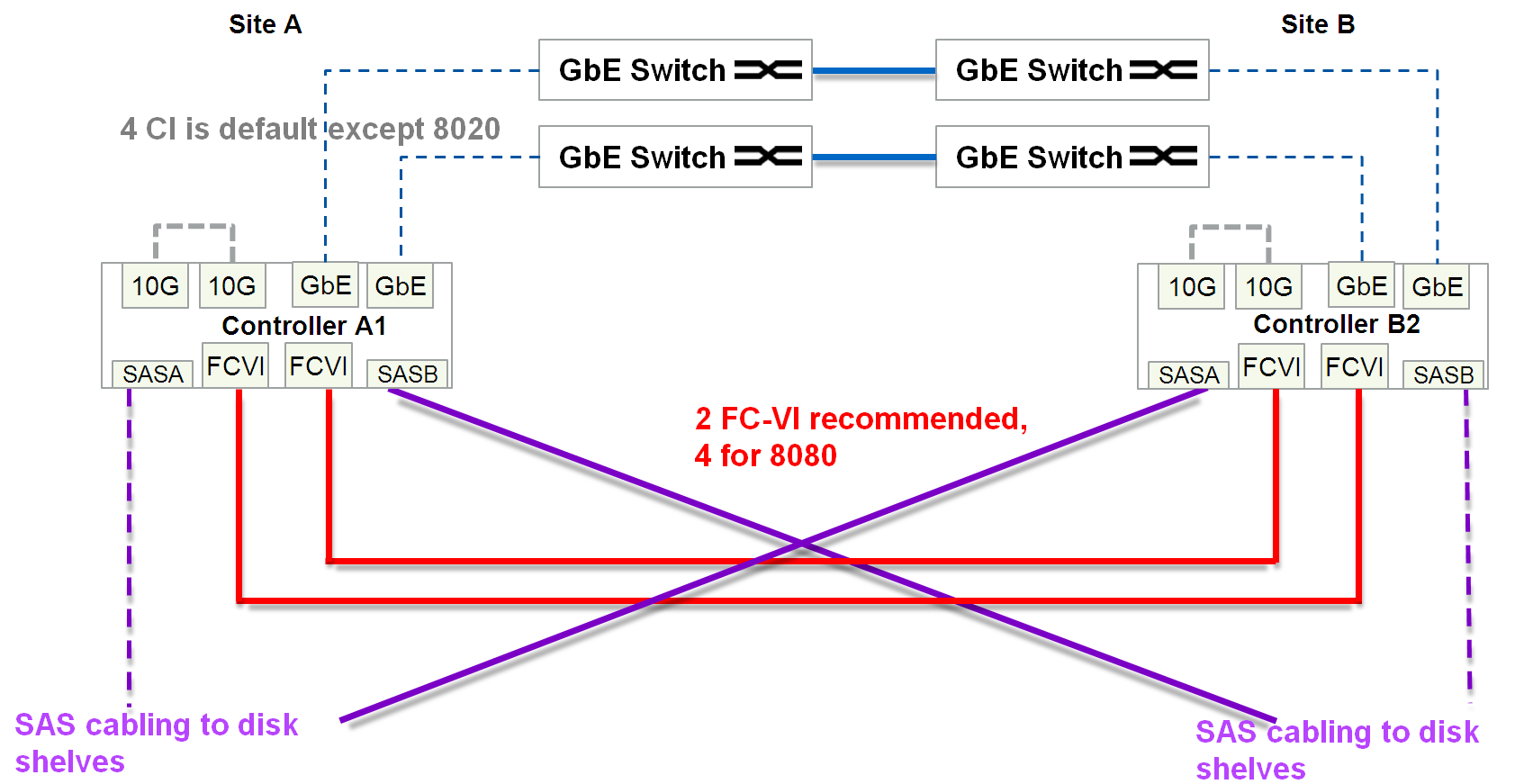
In total, between two sites a minimum of 4 + 16 = 20 cores is required, plus Cluster peering.
Depending on the distance and connection speed, a different optical cable is used for direct-connected Stretch MetroCluster configurations.
Usually, a specialized expansion board is installed on each FAS cluster metro controller, on which FC ports operate in FC-VI mode. On some 4-port FC HBA boards for FAS controllers, it is allowed to use 2 ports for FC-VI and 2 others as a target or initiator ports. On some FAS models, the ports on board the motherboard can switch to FC-VI mode. Ports with the FC-VI role use the Fiber Channel protocol to mirror NVRAM content between cluster metro controllers.
There are two main approaches to data replication:
These are, by definition, two mutually exclusive approaches.
The advantage of Approach B is that there are no synchronization delays between the two sites. Due to circumstances that are not known to me, some manufacturers of storage systems allow circuits in which Spit-Brain is possible. There are implementations, in fact, working according to “Approach A”, but at the same time emulating the ability to write on both sides simultaneously, as if hiding the Active / Passive architecture, but the essence of such a scheme is that while a particular one such write transaction is not synchronized between two sites , it will not be confirmed, let's call it the “Hybrid approach”, it still has the main data set and its mirror copy. In other words, this “Hybrid Approach” is just a special case of “Approach A”, and should not be confused with “Approach B”, despite the deceptive similarity. A “hybrid approach” has the ability to access its data through a remote site, in such implementations, at first glance, there is some advantage over the classic version of “Approach A”, but in essence it does not change anything - the delay in synchronizing the sites as it was, remains “Must Have” to protect against Spit-Brain. Let's look at an example in the figure below of all possible options for accessing data according to “Approach A” (including “Hybrid”).
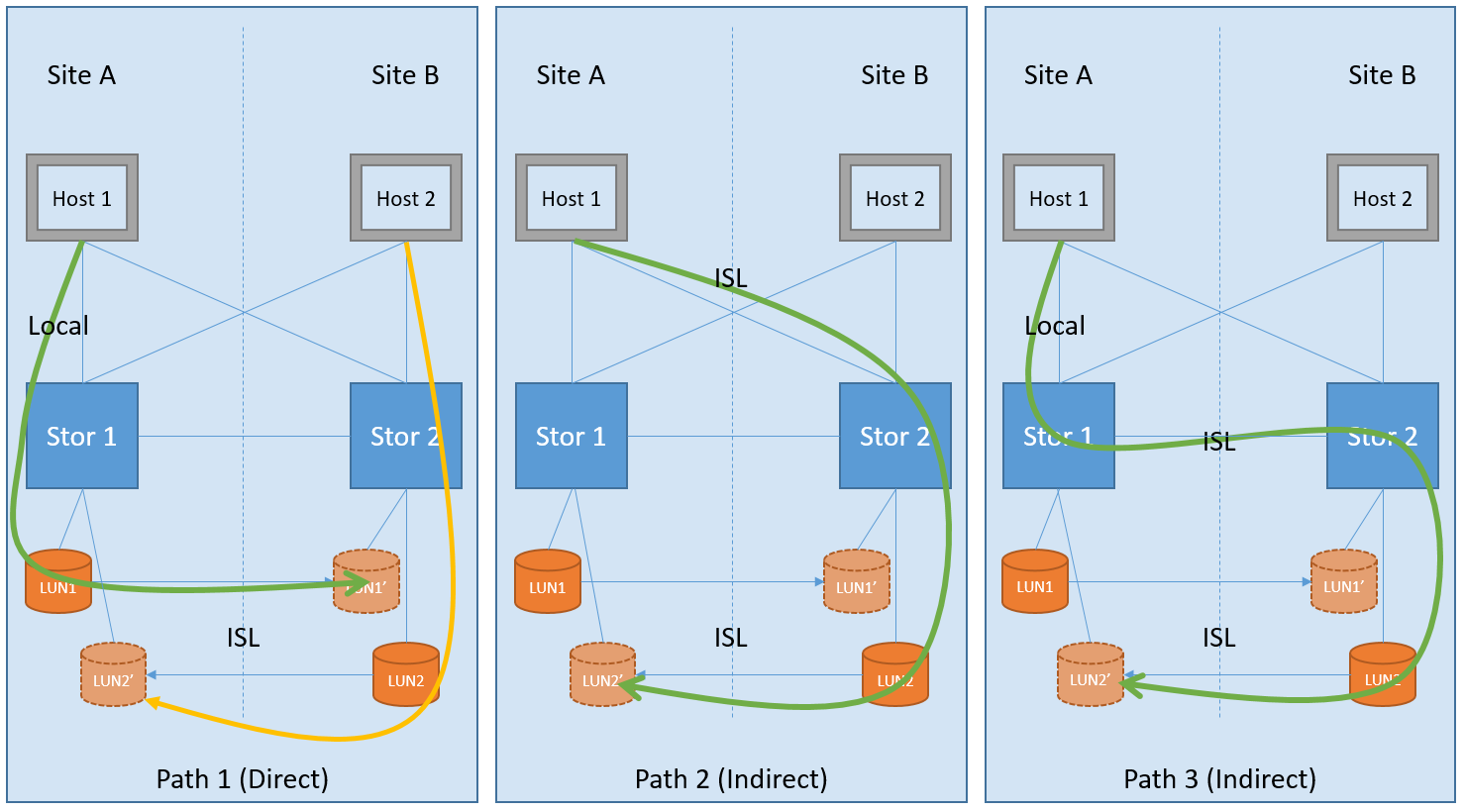
The figure visualizes 3 options for possible ways to access data. The first option (Path 1) is a classic implementation of the Split-Brain protection approach: data passes once through a local path and once through a long ISL (Inter Switch Link) intersite connection for mirroring. This option provides some sort of Active / Passive mode for cluster robots, but each site has its own hosts, each of which refers to its local Direct Path storage, where both sides of the cluster are disposed of, thus forming an Active / Active configuration. In such an Active / Active configuration (with “Approach A”), the host will switch to the backup site only in the event of an accident, and when everything is restored, it will return to using the previous “direct” path. While the “Hybrid scheme” (with emulation of the ability to record through both sites at the same time) allows you to work on all 3 path options. In the last two variants of Path 2 & Path 3, we have a completely opposite picture: the data crosses the long ISL (Indirect Path) ISL link twice, which increases the response speed. In the last two variants of Path 2 & Path 3, there is no sense either in terms of fault tolerance or in terms of performance compared to the first, and therefore they are not supported in the NetApp metro cluster, but work in the Active / Active configuration mode (according to the classic “ Approach A ”) that is, using direct paths on each site, as shown in the image of Path 1. data crosses the ISL (Indirect Path) long intersite link twice, which increases the response speed. In the last two variants of Path 2 & Path 3, there is no sense either in terms of fault tolerance or in terms of performance compared to the first, and therefore they are not supported in the NetApp metro cluster, but work in the Active / Active configuration mode (according to the classic “ Approach A ”) that is, using direct paths on each site, as shown in the image of Path 1. data crosses the ISL (Indirect Path) long intersite link twice, which increases the response speed. In the last two variants of Path 2 & Path 3, there is no sense either in terms of fault tolerance or in terms of performance compared to the first, and therefore they are not supported in the NetApp metro cluster, but work in the Active / Active configuration mode (according to the classic “ Approach A ”) that is, using direct paths on each site, as shown in the image of Path 1.
As stated in the Active / Active sectionThe metro cluster is architecturally designed so that local hosts work with the local half of the metro cluster. And only in the case when a whole site dies, the hosts switch to the second site. And what happens if both sites are live, but the connection between them just disappeared? In the architecture of the metro cluster, everything is simple - the hosts continue to work, write and read, in their local halves as if nothing had happened. Just at this moment, the synchronization between the sites stops. As soon as the links are restored, both halves of the metro cluster will automatically begin to synchronize. In this situation, the data will be read from the main plexus, and not as it usually happens through NVRAM, after both plexes become the same again, mirroring will return to the replication mode based on NVRAM memory.
MCC is a completely symmetrical configuration: how many disks on one site are so many and on another, what FAS systems are on one site, the same should be on another. Starting with the ONTAP 9 firmware version for FAS systems, it is allowed to have Unmirrored aggregates (pools). Thus, in the new firmware, the number of disks can now differ on two sites. Thus, for example, on one site there can be two aggregates, one of them is mirrored (on the remote site there is a full mirror by types of disks, their speeds, raid groups), the second aggregate, which is only on the first site, but it is not replicated to remote site.
It is worth separating two options for Active / Passive configurations:
Unmirrored aggregates allow you to create asymmetric configurations, and as an extreme, special case, the first option is the Active / Passive configuration: when only one site is used for productive workload, and the second accepts a synchronous replica and is safe in case of failure of the main site. In such a scheme, when one controller fails, it immediately switches to the spare site.
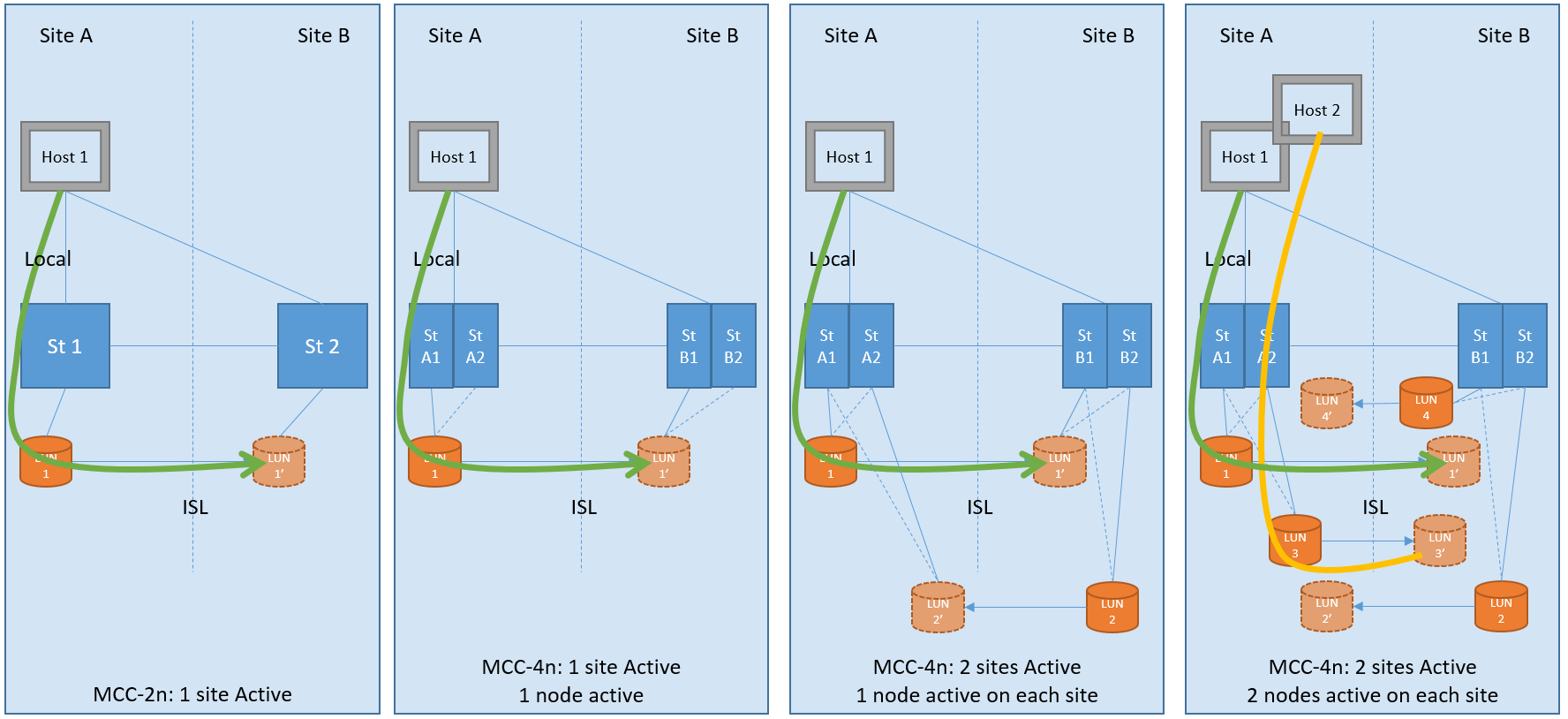
The second option is Active / Passiveconfigurations are collected to save disks in a cluster of 4 or more nodes: only part of the controllers will serve clients, while controllers that are idle will patiently wait for a neighbor to die to replace him. This scheme allows you not to switch between sites in the event of a failure of one controller, but to perform a local ON takeover.
SyncMirror technology allows you to mirror data and can operate in two modes:
The difference between the local SyncMirror and MCC SyncMirror is that in the first case, the data is always mirrored from NVRAM within one controller and immediately to two plexes, it is sometimes used to protect against the failure of an entire shelf. And in the second case, NVRAM mirroring is performed between several controllers . NVRAM mirroring between multiple controllers is done through dedicated FC-VI ports. MCC SyncMirror is used to protect against the failure of an entire site.
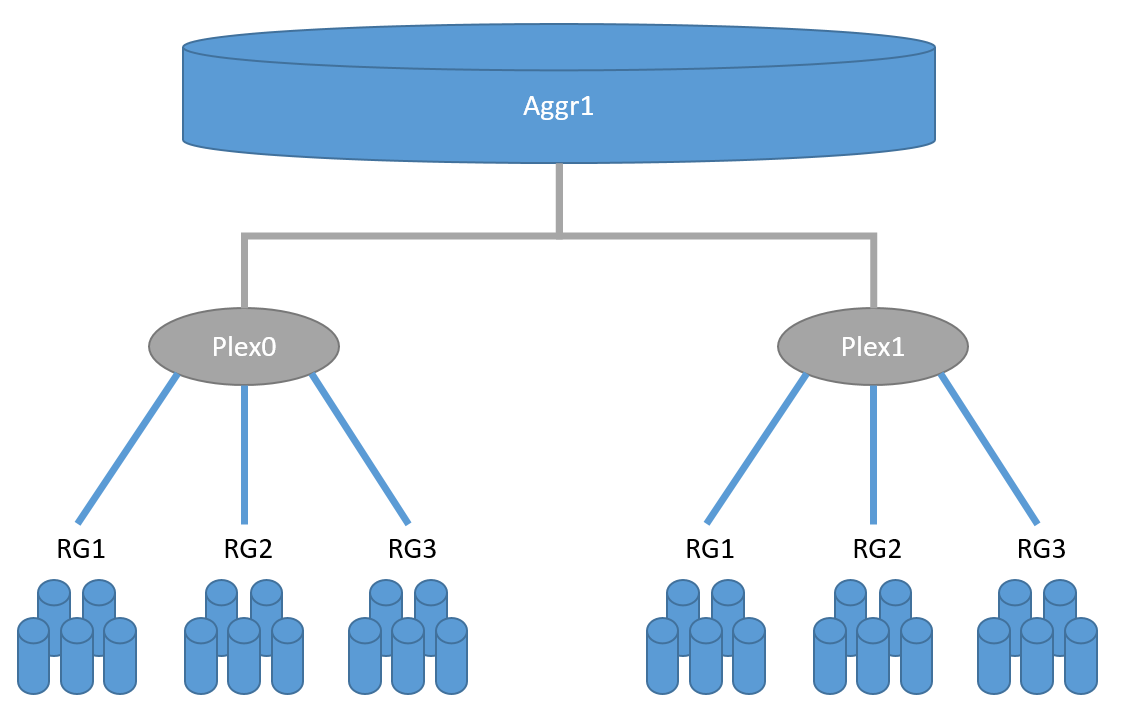
SyncMirror performs replication as it were at the RAID level, similar to mirrored RAID-60: there are two plexs, Plex0 (the main data set) and Plex1 (mirror), each plex can consist of one or more RAID-DP groups. Why "like"? Because these two plexes, they are visible as component, mirror parts of one unit (pool), but in fact, in a normally working system, mirroring is performed at the level of the NVRAM controller. And as you may already know, WAFL, RAID-DP, NVRAM, and NVLOG are all part of the same architecture.disk subsystem, and they can very conditionally be separated from one another. An important detail of SyncMirror technology is the need for full disk symmetry in two mirrored pools: the size, type, speed of disks, RAID groups must be completely identical. There are small exceptions to the rules, but for now I will not mention them so as not to mislead the reader.
Synchronous replication allows on the one hand to relieve the load on the disk subsystem by replicating only memory, on the other hand, to solve the Split-Brain problem and the consistency problem (from the point of view of the WAFL structure on the storage system), you need to make sure that the data is written to the remote system: as a result “Synchronization”, in any storage systems, increases the response speed by a time equal to the time of sending data to a remote site + the time of confirmation of this record.
Do not confuse
Sync Mirror replicates the contents of one plex to the second plex, which comprise one aggregate: all its RAID groups, relatively speaking “disk-like”, where the mirrors must have the same disks with the same number, volume, geometry and speed. In Sync by Mirror the MCC performed replica NVLOG. In case of local Sync Mirror, both plexes live and are served by one controller. And in the case of SyncMirror MCC, two halves of the Plex live, one on one controller, and the other on the remote. At one point in time, in the normal operation of the storage system, only one plex is active and working, the second only stores a copy of the information.
Each unit can contain one or more FlexVol volumes (data container), each volume is uniformly spread over all disks in the unit. Each volume is a separate WAFL structure. In the case of Snap Mirror, replica runs at the WAFL level and can run on disks with a completely different geometry, quantity, and volume.
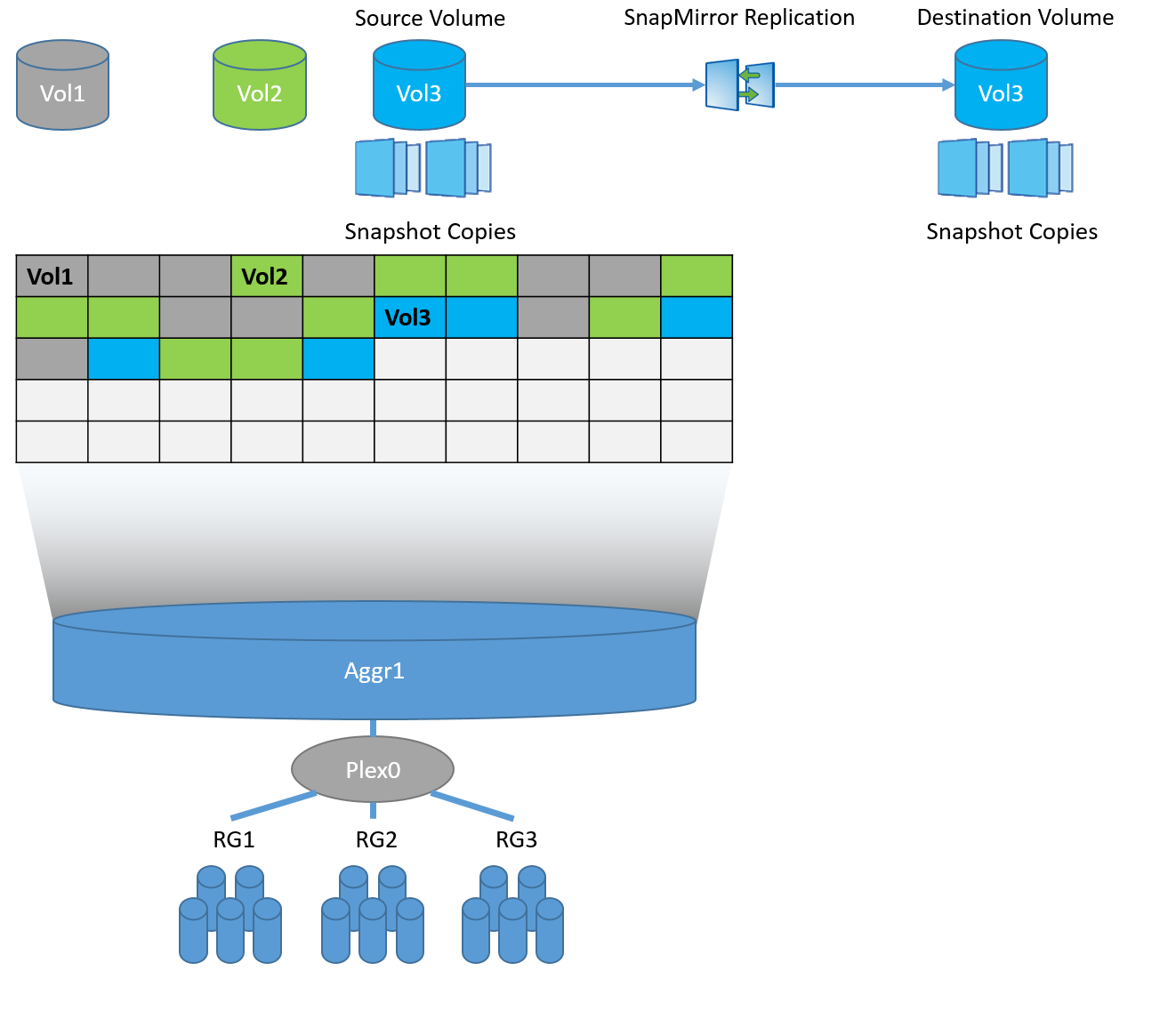
If you delve into the technology, in fact, both Snap and Sync Mirror use snapshots for data replication, but in the case of Sync Mirror they are system snapshots on the CP event (NVRAM / NVLOG) + snapshots at the aggregate level, and in the case of SnapMirror it snapshots removed at the FlexVol level (WAFL).
SnapMirror and SyncMirror can easily coexist with each other, so you can replicate data from / to the metro cluster from another storage system with ONTAP firmware.
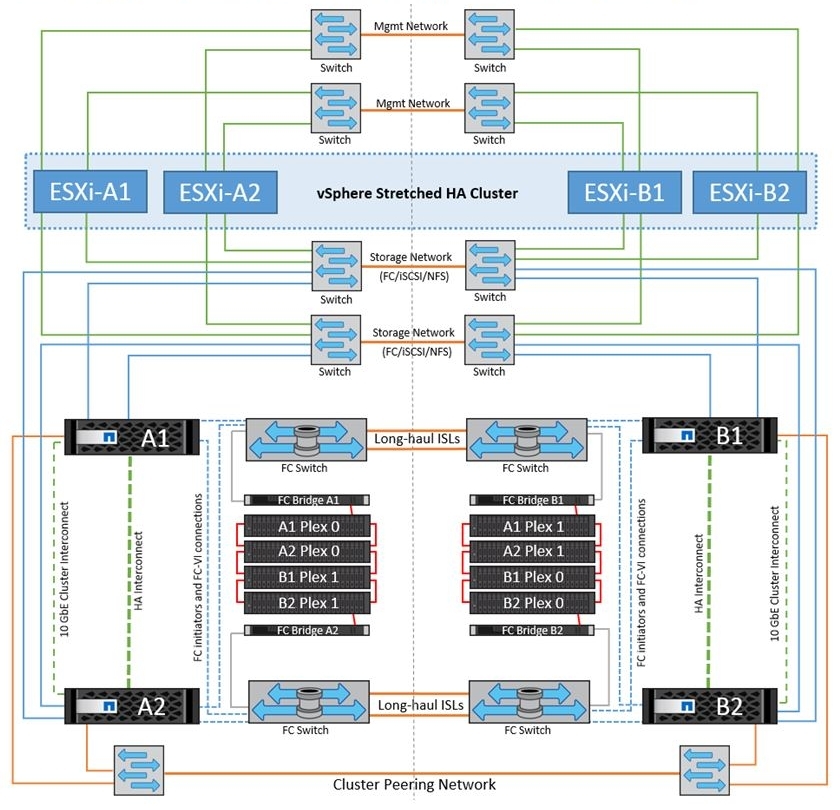
In order to protect data from Split-Brain, the data that is recorded goes to NVRAM in the form of logs (NVLOG) and to the system memory. Confirmation of the record to the host will come only after they get into the NVRAM of one locally controller, its neighbor (if the MCC consists of 4 nodes) and one remote neighbor. Synchronization between local controllers is performed via HA interconnect (this is usually an internal bus or sometimes an external connection), and synchronization to a remote node is performed through FC-IV ports. The local ON partner has only a copy of NVLOG, it does not create a full copy of the data, because he already sees the disks with this data of his ON neighbor. The remote DR partner has a copy of NVLOG and has a full copy of all the data (in Plex 1) on its own disks. This scheme allows switching within the site if the second HA pair controller has survived, or switching to the second site if all local storage nodes are out of order. switching to the second site occurs in a couple of seconds.
The picture shows a diagram for a four-node metro cluster. The two-node scheme is similar, but does not have a local ON partner. An eight-node circuit is the same two four-node circuit: i.e. in this configuration, the NVRAM replica is performed within these 4 nodes, and the combination of two of these four node configurations allows you to transparently move data between the cluster metro nodes within each site.
NVRAM complements SyncMirror technology: after data is received in NVRAM of the remote storage, write confirmation is immediately received, that is, RAID comes into fully synchronous state on the second plex with a delay, without compromising the consistency of the mirror copy - this allows you to significantly speed up the response when mirroring the halves of the cluster .
In order to automatically switch between two sites, human intervention or a third node is necessary, so to speak a witness of everything that happens, an impartial and all-seeing arbiter who could decide which of the sites should remain alive after the accident, he is called TieBreaker. TieBreaker is either NetApp freeware for Windows Server or specialized ClusterLion hardware .
If TieBreaker is not installed, you can switch between sites manually from the free OnCommand Unified Manager (OCUM) utility or from the command line using metrocluster switchover commands .
MCC supports All Flash FAS systems for Fabric-Attached and Bridge-Attached Stretch MetroCluster configurations; it is recommended to use ATTO 7500N FibreBridges in them.
FlexArray virtualization technology allows you to use third-party storage systems as a back-end, connecting them using the FCP protocol. It is allowed not to have native shelves with disk shelves manufactured by NetApp. Third-party storage systems can be connected through the same FC factories as for FC-VI connection, this can save money both on the fact that the Fabric-Attached MetroCluster scheme eliminates the need for FC-SAS bridges, and on the fact that existing ones can be recycled allowing you to save investment by recycling old storage systems. FlexArray requires this storage system to be in the compatibility matrix .
VMware can use with MCC to provide HA based on NetApp hardware replication. As with SRM / SRA, this is a vCenter plugin that can interact with MetroCluster TieBreaker to provide automatic switching in the event of an accident.
VVOL technology is supported with vMSC.
MCC technology is designed to create highly accessible storage and highly accessible services on top of it. Using hardware replication, SyncMirror allows you to replicate very large critical corporate infrastructures and automatically or manually switch between sites in the event of an accident, protecting against Split-Brain. MCC is designed in such a way that it looks like one device for end hosts, and switching for the host is performed at the network fault tolerance level. This allows you to integrate MCC with almost any solution.
This may contain links to Habra articles that will be published later.
Please send messages about errors in the text to the LAN .
Comments, additions and questions on the opposite article, please comment.
MetroCluster running on the old OS Data ONTAP 7-Mode (up to version 8.2.x) had the abbreviation "MC", and working on ClusteredONTAP (8.x and older), to avoid confusion, it is customary to call MetroCluster ClusteredONTAP (MCC).
An MCC may consist of two or more controllers. There are three MCC connection schemes:
- Fabric-Attached MetroCluster (FCM-MCC)
- Bridge-Attached Stretch MetroCluster
- Stretch MetroCluster
The difference in these three options is essentially only in the network harness. The network binding affects two factors: the maximum possible distance over which the cluster can be stretched and the number of nodes in the cluster.
Fabric-Attached MetroCluster
This configuration can consist of either two or 4 identical controllers. The two-node configuration (mcc-2n) can be converted to four-node configuration (mcc). In a two-day configuration, each site has one controller and, if one controller exits, the second one on the other site takes control, this is called switchover . If there is more than one node on each site, and one cluster node fails, then a local HA failover occurs without switching to the second site. MetroCluster can stretch up to 300 km.
This is the most expensive scheme of all connection options, since it requires the presence of:
- Double shelves
- One or two IP channels for Cluster peering network
- Additional SAN switches on the back-end (not to be confused with switches for connecting storage and hosts)
- Additional SAS-FC bridges
- FC-VI ports
- Possible xWDM multiplexers
- And at least 2 ISL long-wave FC SFP + link (4 wires: 2x RX, 2x TX). Those. “dark optics” is brought to the storage system (there can be only xWDM in the intervals, without any switches), these links are dedicated exclusively to the storage replication tasks (FC-VI & back-end connections)
In total, between the two sites, at least 4 wires are required, plus Cluster peering.
8-Node MCC
By analogy with the 4-node Fabric-Attached MetroCluster configuration, there is an eight-node configuration, which so far supports only NAS access protocols and ONTAP 9 firmware. Four-node configuration can be updated to eight nodes. This configuration does not yet support SAN access protocols. In an eight-node configuration, 4 nodes are located on one site and 4 on another. From the network point of view, nothing changes much, in a similar Fabric-Attached MetroCluster 4-node scheme: the number of FC switches on the backend remains the same, only the number of required ports on each site for local switching increases, but cross-site connections and cross-site ports can be as many. In this scheme, we need cluster switches for 4-channel communication on each site, while 2 and 4 node configurations do not require cluster switches. The advantage of the 8-node configuration is the possibility of using two types of FAS systems in one cluster, for example, on one site you have FAS8040 (two nodes) and All Flash FAS 8060 (two nodes), on the other site we have exactly the same mirror configuration FAS8040 (two nodes) and All Flash FAS 8060 (two nodes). Data from one site on the FAS8040 system is replicated to the same FAS8040 system on another site and similarly for All Flash FAS 8060. Data within the site can transparently migrate to these cluster nodes. on another site we have exactly the same mirror configuration FAS8040 (two nodes) and All Flash FAS 8060 (two nodes). Data from one site on the FAS8040 system is replicated to the same FAS8040 system on another site and similarly for All Flash FAS 8060. Data within the site can transparently migrate to these cluster nodes. on another site we have exactly the same mirror configuration FAS8040 (two nodes) and All Flash FAS 8060 (two nodes). Data from one site on the FAS8040 system is replicated to the same FAS8040 system on another site and similarly for All Flash FAS 8060. Data within the site can transparently migrate to these cluster nodes.
Bridge-Attached Stretch MetroCluster
It can stretch up to 500 meters and requires the presence of:
- Double shelves
- One or two IP channels for Cluster peering network
- Additional SAS-FC bridges
- FC-VI ports
- at least two links (4 wires: 2x RX, 2x TX) of dark optics allocated exclusively for connecting storage controllers (FC-VI)
- And at least four links (total 4x2 = 8 cores) of dark optics allocated exclusively for back-end communication
In total, between two sites a minimum of 4 + 8 = 12 cores is required, plus Cluster peering.
Stretch MetroCluster Direct On
The cheapest option. It can stretch up to 500 meters and requires the presence of:
- Double shelves
- One or two IP channels for Cluster peering network
- FC-VI ports
- at least two links (4 wires: 2x RX, 2x TX) of dark optics allocated exclusively for connecting storage controllers (FC-VI)
- And at least two 4-channel (for each channel 2 lived: RX and TX) cables (total 2x8 = 16 cores) of dark optics allocated exclusively for replication tasks for access to each shelf in two ways.
- For the back-end connectivity of the shelves, a special 4-channel (for each channel 2 lived: RX and TX) optical SAS connector and optical patch panel is used
In total, between two sites a minimum of 4 + 16 = 20 cores is required, plus Cluster peering.
Optical cable for Stretch MetroCluster
Depending on the distance and connection speed, a different optical cable is used for direct-connected Stretch MetroCluster configurations.
| Speed (Gbps) | Maximum distance (m) | |||
|---|---|---|---|---|
| 16Gbps SW SFP | 16Gbps LW SFP | |||
| OM2 | OM3 | OM3 + / OM4 | Single-Mode (SM) Fiber | |
| 2 | N / a | N / a | N / a | N / a |
| 4 | 150 | 270 | 270 | 500 |
| 8 | fifty | 150 | 170 | 500 |
| 16 | 35 | 100 | 125 | 500 |
FC-VI ports
Usually, a specialized expansion board is installed on each FAS cluster metro controller, on which FC ports operate in FC-VI mode. On some 4-port FC HBA boards for FAS controllers, it is allowed to use 2 ports for FC-VI and 2 others as a target or initiator ports. On some FAS models, the ports on board the motherboard can switch to FC-VI mode. Ports with the FC-VI role use the Fiber Channel protocol to mirror NVRAM content between cluster metro controllers.
Active / Active
There are two main approaches to data replication:
- Approach A: Provides Split-Brain Protection
- “Approach B”: In which there is the possibility of access (reading and writing) to all data through all sites
These are, by definition, two mutually exclusive approaches.
The advantage of Approach B is that there are no synchronization delays between the two sites. Due to circumstances that are not known to me, some manufacturers of storage systems allow circuits in which Spit-Brain is possible. There are implementations, in fact, working according to “Approach A”, but at the same time emulating the ability to write on both sides simultaneously, as if hiding the Active / Passive architecture, but the essence of such a scheme is that while a particular one such write transaction is not synchronized between two sites , it will not be confirmed, let's call it the “Hybrid approach”, it still has the main data set and its mirror copy. In other words, this “Hybrid Approach” is just a special case of “Approach A”, and should not be confused with “Approach B”, despite the deceptive similarity. A “hybrid approach” has the ability to access its data through a remote site, in such implementations, at first glance, there is some advantage over the classic version of “Approach A”, but in essence it does not change anything - the delay in synchronizing the sites as it was, remains “Must Have” to protect against Spit-Brain. Let's look at an example in the figure below of all possible options for accessing data according to “Approach A” (including “Hybrid”).
The figure visualizes 3 options for possible ways to access data. The first option (Path 1) is a classic implementation of the Split-Brain protection approach: data passes once through a local path and once through a long ISL (Inter Switch Link) intersite connection for mirroring. This option provides some sort of Active / Passive mode for cluster robots, but each site has its own hosts, each of which refers to its local Direct Path storage, where both sides of the cluster are disposed of, thus forming an Active / Active configuration. In such an Active / Active configuration (with “Approach A”), the host will switch to the backup site only in the event of an accident, and when everything is restored, it will return to using the previous “direct” path. While the “Hybrid scheme” (with emulation of the ability to record through both sites at the same time) allows you to work on all 3 path options. In the last two variants of Path 2 & Path 3, we have a completely opposite picture: the data crosses the long ISL (Indirect Path) ISL link twice, which increases the response speed. In the last two variants of Path 2 & Path 3, there is no sense either in terms of fault tolerance or in terms of performance compared to the first, and therefore they are not supported in the NetApp metro cluster, but work in the Active / Active configuration mode (according to the classic “ Approach A ”) that is, using direct paths on each site, as shown in the image of Path 1. data crosses the ISL (Indirect Path) long intersite link twice, which increases the response speed. In the last two variants of Path 2 & Path 3, there is no sense either in terms of fault tolerance or in terms of performance compared to the first, and therefore they are not supported in the NetApp metro cluster, but work in the Active / Active configuration mode (according to the classic “ Approach A ”) that is, using direct paths on each site, as shown in the image of Path 1. data crosses the ISL (Indirect Path) long intersite link twice, which increases the response speed. In the last two variants of Path 2 & Path 3, there is no sense either in terms of fault tolerance or in terms of performance compared to the first, and therefore they are not supported in the NetApp metro cluster, but work in the Active / Active configuration mode (according to the classic “ Approach A ”) that is, using direct paths on each site, as shown in the image of Path 1.
Split-brain
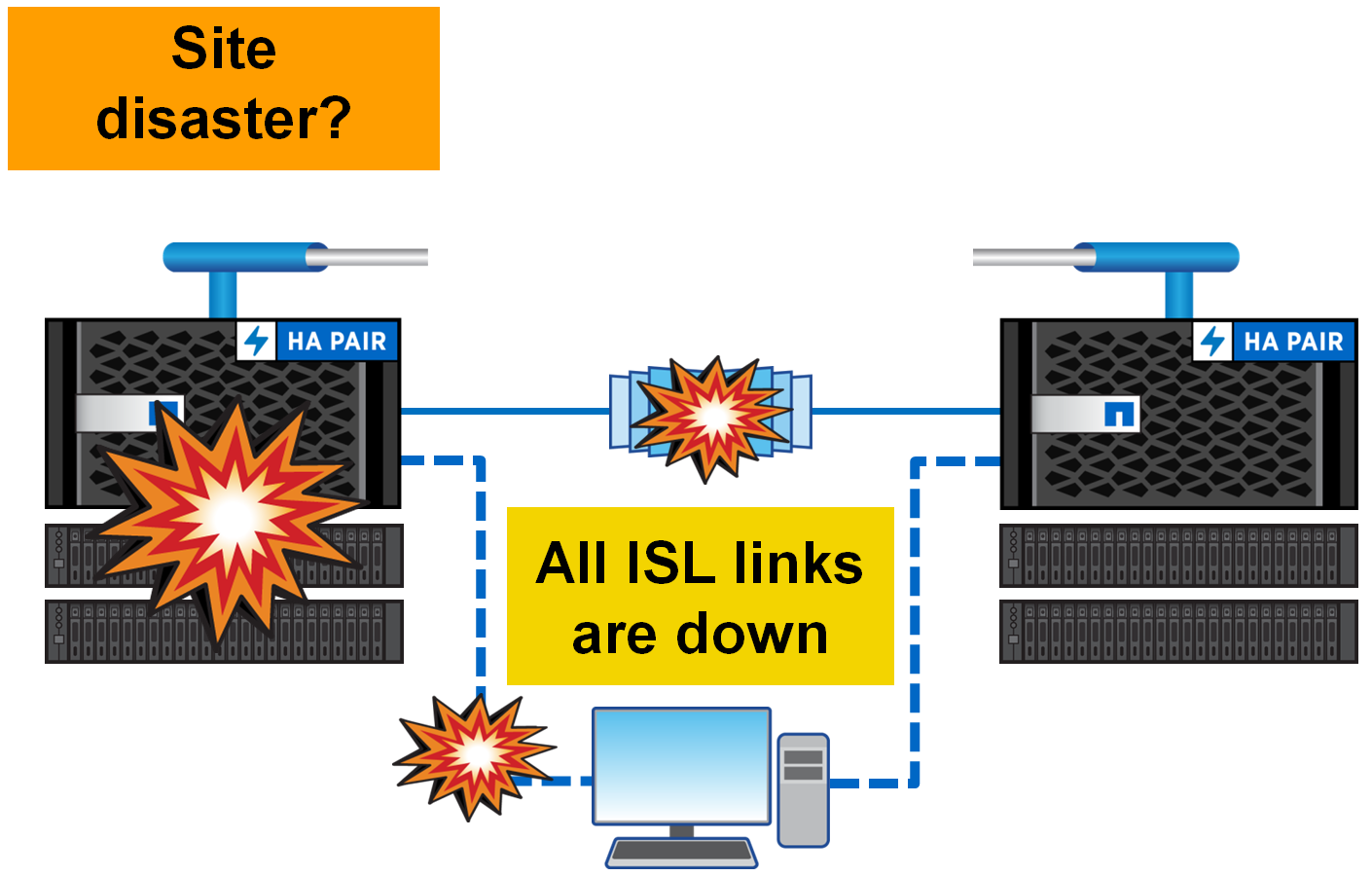
As stated in the Active / Active sectionThe metro cluster is architecturally designed so that local hosts work with the local half of the metro cluster. And only in the case when a whole site dies, the hosts switch to the second site. And what happens if both sites are live, but the connection between them just disappeared? In the architecture of the metro cluster, everything is simple - the hosts continue to work, write and read, in their local halves as if nothing had happened. Just at this moment, the synchronization between the sites stops. As soon as the links are restored, both halves of the metro cluster will automatically begin to synchronize. In this situation, the data will be read from the main plexus, and not as it usually happens through NVRAM, after both plexes become the same again, mirroring will return to the replication mode based on NVRAM memory.
Active / Passive and Unmirrored Aggregates
MCC is a completely symmetrical configuration: how many disks on one site are so many and on another, what FAS systems are on one site, the same should be on another. Starting with the ONTAP 9 firmware version for FAS systems, it is allowed to have Unmirrored aggregates (pools). Thus, in the new firmware, the number of disks can now differ on two sites. Thus, for example, on one site there can be two aggregates, one of them is mirrored (on the remote site there is a full mirror by types of disks, their speeds, raid groups), the second aggregate, which is only on the first site, but it is not replicated to remote site.
It is worth separating two options for Active / Passive configurations:
- First option. When only one main site is used, and the second accepts a replica and lives for safety in case the main site is turned off
- The second option. When there are 4 or more nodes in a cluster and not all controllers are used on each site
Unmirrored aggregates allow you to create asymmetric configurations, and as an extreme, special case, the first option is the Active / Passive configuration: when only one site is used for productive workload, and the second accepts a synchronous replica and is safe in case of failure of the main site. In such a scheme, when one controller fails, it immediately switches to the spare site.
The second option is Active / Passiveconfigurations are collected to save disks in a cluster of 4 or more nodes: only part of the controllers will serve clients, while controllers that are idle will patiently wait for a neighbor to die to replace him. This scheme allows you not to switch between sites in the event of a failure of one controller, but to perform a local ON takeover.
SyncMirror - Synchronous Replication
SyncMirror technology allows you to mirror data and can operate in two modes:
- Local syncmirror
- MetroCluster SyncMirror
The difference between the local SyncMirror and MCC SyncMirror is that in the first case, the data is always mirrored from NVRAM within one controller and immediately to two plexes, it is sometimes used to protect against the failure of an entire shelf. And in the second case, NVRAM mirroring is performed between several controllers . NVRAM mirroring between multiple controllers is done through dedicated FC-VI ports. MCC SyncMirror is used to protect against the failure of an entire site.
SyncMirror performs replication as it were at the RAID level, similar to mirrored RAID-60: there are two plexs, Plex0 (the main data set) and Plex1 (mirror), each plex can consist of one or more RAID-DP groups. Why "like"? Because these two plexes, they are visible as component, mirror parts of one unit (pool), but in fact, in a normally working system, mirroring is performed at the level of the NVRAM controller. And as you may already know, WAFL, RAID-DP, NVRAM, and NVLOG are all part of the same architecture.disk subsystem, and they can very conditionally be separated from one another. An important detail of SyncMirror technology is the need for full disk symmetry in two mirrored pools: the size, type, speed of disks, RAID groups must be completely identical. There are small exceptions to the rules, but for now I will not mention them so as not to mislead the reader.
Synchronous replication allows on the one hand to relieve the load on the disk subsystem by replicating only memory, on the other hand, to solve the Split-Brain problem and the consistency problem (from the point of view of the WAFL structure on the storage system), you need to make sure that the data is written to the remote system: as a result “Synchronization”, in any storage systems, increases the response speed by a time equal to the time of sending data to a remote site + the time of confirmation of this record.
SnapMirror vs SyncMirror
Do not confuse
- Sync mirror
- and snap mirror
Sync Mirror replicates the contents of one plex to the second plex, which comprise one aggregate: all its RAID groups, relatively speaking “disk-like”, where the mirrors must have the same disks with the same number, volume, geometry and speed. In Sync by Mirror the MCC performed replica NVLOG. In case of local Sync Mirror, both plexes live and are served by one controller. And in the case of SyncMirror MCC, two halves of the Plex live, one on one controller, and the other on the remote. At one point in time, in the normal operation of the storage system, only one plex is active and working, the second only stores a copy of the information.
Each unit can contain one or more FlexVol volumes (data container), each volume is uniformly spread over all disks in the unit. Each volume is a separate WAFL structure. In the case of Snap Mirror, replica runs at the WAFL level and can run on disks with a completely different geometry, quantity, and volume.
If you delve into the technology, in fact, both Snap and Sync Mirror use snapshots for data replication, but in the case of Sync Mirror they are system snapshots on the CP event (NVRAM / NVLOG) + snapshots at the aggregate level, and in the case of SnapMirror it snapshots removed at the FlexVol level (WAFL).
SnapMirror and SyncMirror can easily coexist with each other, so you can replicate data from / to the metro cluster from another storage system with ONTAP firmware.
Memory and NVRAM
In order to protect data from Split-Brain, the data that is recorded goes to NVRAM in the form of logs (NVLOG) and to the system memory. Confirmation of the record to the host will come only after they get into the NVRAM of one locally controller, its neighbor (if the MCC consists of 4 nodes) and one remote neighbor. Synchronization between local controllers is performed via HA interconnect (this is usually an internal bus or sometimes an external connection), and synchronization to a remote node is performed through FC-IV ports. The local ON partner has only a copy of NVLOG, it does not create a full copy of the data, because he already sees the disks with this data of his ON neighbor. The remote DR partner has a copy of NVLOG and has a full copy of all the data (in Plex 1) on its own disks. This scheme allows switching within the site if the second HA pair controller has survived, or switching to the second site if all local storage nodes are out of order. switching to the second site occurs in a couple of seconds.
The picture shows a diagram for a four-node metro cluster. The two-node scheme is similar, but does not have a local ON partner. An eight-node circuit is the same two four-node circuit: i.e. in this configuration, the NVRAM replica is performed within these 4 nodes, and the combination of two of these four node configurations allows you to transparently move data between the cluster metro nodes within each site.
NVRAM complements SyncMirror technology: after data is received in NVRAM of the remote storage, write confirmation is immediately received, that is, RAID comes into fully synchronous state on the second plex with a delay, without compromising the consistency of the mirror copy - this allows you to significantly speed up the response when mirroring the halves of the cluster .
Tie Breaker witness
In order to automatically switch between two sites, human intervention or a third node is necessary, so to speak a witness of everything that happens, an impartial and all-seeing arbiter who could decide which of the sites should remain alive after the accident, he is called TieBreaker. TieBreaker is either NetApp freeware for Windows Server or specialized ClusterLion hardware .
OnCommand Unified Manager (OCUM)
If TieBreaker is not installed, you can switch between sites manually from the free OnCommand Unified Manager (OCUM) utility or from the command line using metrocluster switchover commands .
All flash
MCC supports All Flash FAS systems for Fabric-Attached and Bridge-Attached Stretch MetroCluster configurations; it is recommended to use ATTO 7500N FibreBridges in them.
Flexarray
FlexArray virtualization technology allows you to use third-party storage systems as a back-end, connecting them using the FCP protocol. It is allowed not to have native shelves with disk shelves manufactured by NetApp. Third-party storage systems can be connected through the same FC factories as for FC-VI connection, this can save money both on the fact that the Fabric-Attached MetroCluster scheme eliminates the need for FC-SAS bridges, and on the fact that existing ones can be recycled allowing you to save investment by recycling old storage systems. FlexArray requires this storage system to be in the compatibility matrix .
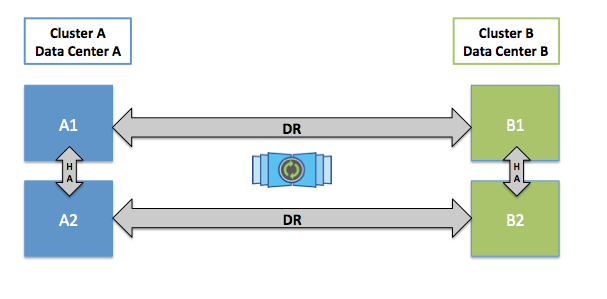
VMware vSphere Metro Storage Cluster
VMware can use with MCC to provide HA based on NetApp hardware replication. As with SRM / SRA, this is a vCenter plugin that can interact with MetroCluster TieBreaker to provide automatic switching in the event of an accident.
VMware VVOL
VVOL technology is supported with vMSC.
conclusions
MCC technology is designed to create highly accessible storage and highly accessible services on top of it. Using hardware replication, SyncMirror allows you to replicate very large critical corporate infrastructures and automatically or manually switch between sites in the event of an accident, protecting against Split-Brain. MCC is designed in such a way that it looks like one device for end hosts, and switching for the host is performed at the network fault tolerance level. This allows you to integrate MCC with almost any solution.
This may contain links to Habra articles that will be published later.
Please send messages about errors in the text to the LAN .
Comments, additions and questions on the opposite article, please comment.