XML, XQuery, and triple sadness with performance
- Tutorial
A trip to Dnepropetrovsk for a meeting with the Dnepr SQL User Group , a chronic lack of sleep over the last couple of days, but a nice bonus on arrival to Kharkov ... Winter weather, which motivates to write something interesting ...
For a long time there were plans to tell about the "pitfalls" when working with XML and XQuery , which can lead to tricky performance issues.
For those who often use SQL Server , XQuery and like to parse values from XML, it is recommended to familiarize yourself with the following material ...
First, we will generate a test XML on which we will conduct experiments:
For those who have xp_cmdshell disabled, you need to do:
As a result, on the specified path, we will create a file with the following structure:
Now we’ll start sampling experiments ...
What is the most efficient way to load data from XML ? Probably, you do not need to open the file with notepad, copy the contents and paste into a variable ... I think that it would be more appropriate to use OPENROWSET :
But there is a funny catch. As it turned out, the combination of loading operations and parsing values from XML can lead to a significant decrease in performance. Suppose we need to get obj_id values from a previously created file:
On my machine, this request takes a very long time:
Let's try to separate download and parsing:
Everything worked out very quickly:
So what was the problem? Let's analyze the execution plan:

As it turned out, the problem lies in type conversion, so try to pass the parameter in the XML type to the nodes function initially . Next, we will consider a typical situation when parsing requires filtering ... In such cases, remember that SQL Server does not optimize function calls for working with XML . For clarity, I will show that in this request, the value function will be executed twice:

This nuance can reduce performance, so it is recommended to reduce function calls:

Alternatively, you can filter it like this:
but we can’t talk about substantial gains. Although QueryCost says the opposite:
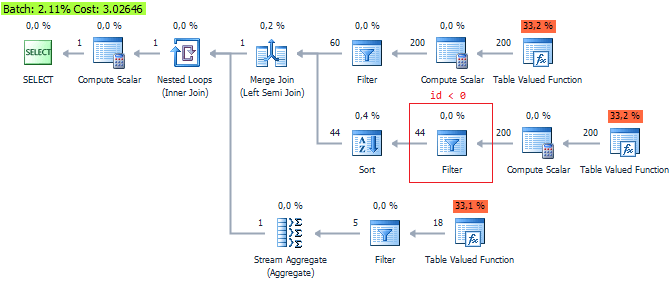
It is shown that the third option is the most optimal ... Let this be another argument not to trust QueryCost , which is just an internal assessment.
And the most interesting example for a snack ... There is another VERY important feature when parsing from XML . Run the request:
and look at the runtime, which can only suit those who are in no hurry:
Why is this happening? The SQL Server server has problems reading parent nodes from child nodes (to put it simply, SQL Server is hard to “look back”):

How can we be in this case? It's very simple ... start reading from the parent nodes and subtract the children using CROSS / OUTER APPLY :
It is also interesting to consider a situation where we need to look at 2 levels above. The problem with reading the parent element did not reproduce for me:
I also wanted to mention one interesting feature. OPENXML has no problems reading parents :
But you don’t need to think now that OPENXML has clear advantages over XQuery . In OPENXML too short stocks. For example, if we forget to call sp_xml_removedocument , then severe memory leaks may occur.
Everything was tested on SQL Server 2012 SP3 (11.00.6020) .
If you want to share this article with an English-speaking audience:
XML, XQuery & Performance Issues
For a long time there were plans to tell about the "pitfalls" when working with XML and XQuery , which can lead to tricky performance issues.
For those who often use SQL Server , XQuery and like to parse values from XML, it is recommended to familiarize yourself with the following material ...
First, we will generate a test XML on which we will conduct experiments:
USE AdventureWorks2012
GO
IF OBJECT_ID('tempdb.dbo.##temp') IS NOT NULL
DROP TABLE ##temp
GO
SELECT val = (
SELECT
[@obj_id] = o.[object_id]
, [@obj_name] = o.name
, [@sch_name] = s.name
, (
SELECT i.name, i.column_id, i.user_type_id, i.is_nullable, i.is_identity
FROM sys.all_columns i
WHERE i.[object_id] = o.[object_id]
FOR XML AUTO, TYPE
)
FROM sys.all_objects o
JOIN sys.schemas s ON o.[schema_id] = s.[schema_id]
WHERE o.[type] IN ('U', 'V')
FOR XML PATH('obj'), ROOT('objects')
)
INTO ##temp
DECLARE @sql NVARCHAR(4000) = 'bcp "SELECT * FROM ##temp" queryout "D:\sample.xml" -S ' + @@servername + ' -T -w -r -t'
EXEC sys.xp_cmdshell @sql
IF OBJECT_ID('tempdb.dbo.##temp') IS NOT NULL
DROP TABLE ##temp
For those who have xp_cmdshell disabled, you need to do:
EXEC sp_configure 'show advanced options', 1
GO
RECONFIGURE
GO
EXEC sp_configure 'xp_cmdshell', 1
GO
RECONFIGURE
GO
As a result, on the specified path, we will create a file with the following structure:
...
...
Now we’ll start sampling experiments ...
What is the most efficient way to load data from XML ? Probably, you do not need to open the file with notepad, copy the contents and paste into a variable ... I think that it would be more appropriate to use OPENROWSET :
DECLARE @xml XML
SELECT @xml = BulkColumn
FROM OPENROWSET(BULK 'D:\sample.xml', SINGLE_BLOB) x
SELECT @xml
But there is a funny catch. As it turned out, the combination of loading operations and parsing values from XML can lead to a significant decrease in performance. Suppose we need to get obj_id values from a previously created file:
;WITH cte AS
(
SELECT x = CAST(BulkColumn AS XML)
FROM OPENROWSET(BULK 'D:\sample.xml', SINGLE_BLOB) x
)
SELECT t.c.value('@obj_id', 'INT')
FROM cte
CROSS APPLY x.nodes('objects/obj') t(c)
On my machine, this request takes a very long time:
(495 row(s) affected)
Table 'Worktable'. Scan count 0, logical reads 20788, ..., lob logical reads 7817781, ..., lob read-ahead reads 1022368.
SQL Server Execution Times:
CPU time = 53688 ms, elapsed time = 53911 ms.
Let's try to separate download and parsing:
DECLARE @xml XML
SELECT @xml = BulkColumn
FROM OPENROWSET(BULK 'D:\sample.xml', SINGLE_BLOB) x
SELECT t.c.value('@obj_id', 'INT')
FROM @xml.nodes('objects/obj') t(c)
Everything worked out very quickly:
(1 row(s) affected)
Table 'Worktable'. Scan count 0, logical reads 7, ..., lob logical reads 2691, ..., lob read-ahead reads 344.
SQL Server Execution Times:
CPU time = 15 ms, elapsed time = 51 ms.
(495 row(s) affected)
SQL Server Execution Times:
CPU time = 47 ms, elapsed time = 125 ms.
So what was the problem? Let's analyze the execution plan:
As it turned out, the problem lies in type conversion, so try to pass the parameter in the XML type to the nodes function initially . Next, we will consider a typical situation when parsing requires filtering ... In such cases, remember that SQL Server does not optimize function calls for working with XML . For clarity, I will show that in this request, the value function will be executed twice:
SELECT t.c.value('@obj_id', 'INT')
FROM @xml.nodes('objects/obj') t(c)
WHERE t.c.value('@obj_id', 'INT') < 0
(404 row(s) affected)
SQL Server Execution Times:
CPU time = 116 ms, elapsed time = 120 ms.
This nuance can reduce performance, so it is recommended to reduce function calls:
SELECT *
FROM (
SELECT id = t.c.value('@obj_id', 'INT')
FROM @xml.nodes('objects/obj') t(c)
) t
WHERE t.id < 0
(404 row(s) affected)
SQL Server Execution Times:
CPU time = 62 ms, elapsed time = 74 ms.
Alternatively, you can filter it like this:
SELECT t.c.value('@obj_id', 'INT')
FROM @xml.nodes('objects/obj[@obj_id < 0]') t(c)
(404 row(s) affected)
SQL Server Execution Times:
CPU time = 110 ms, elapsed time = 119 ms.
but we can’t talk about substantial gains. Although QueryCost says the opposite:
It is shown that the third option is the most optimal ... Let this be another argument not to trust QueryCost , which is just an internal assessment.
And the most interesting example for a snack ... There is another VERY important feature when parsing from XML . Run the request:
SELECT
t.c.value('../@obj_name', 'SYSNAME')
, t.c.value('@name', 'SYSNAME')
FROM @xml.nodes('objects/obj/*') t(c)
and look at the runtime, which can only suit those who are in no hurry:
(5273 row(s) affected)
SQL Server Execution Times:
CPU time = 66578 ms, elapsed time = 66714 ms.
Why is this happening? The SQL Server server has problems reading parent nodes from child nodes (to put it simply, SQL Server is hard to “look back”):
How can we be in this case? It's very simple ... start reading from the parent nodes and subtract the children using CROSS / OUTER APPLY :
SELECT
t.c.value('@obj_name', 'SYSNAME')
, t2.c2.value('@name', 'SYSNAME')
FROM @xml.nodes('objects/obj') t(c)
CROSS APPLY t.c.nodes('*') t2(c2)
(5273 row(s) affected)
SQL Server Execution Times:
CPU time = 156 ms, elapsed time = 184 ms.
It is also interesting to consider a situation where we need to look at 2 levels above. The problem with reading the parent element did not reproduce for me:
USE AdventureWorks2012
GO
DECLARE @xml XML
SELECT @xml = (
SELECT
[@obj_name] = o.name
, [columns] = (
SELECT i.name
FROM sys.all_columns i
WHERE i.[object_id] = o.[object_id]
FOR XML AUTO, TYPE
)
FROM sys.all_objects o
WHERE o.[type] IN ('U', 'V')
FOR XML PATH('obj')
)
SELECT
t.c.value('../../@obj_name', 'SYSNAME')
, t.c.value('@name', 'SYSNAME')
FROM @xml.nodes('obj/columns/*') t(c)
I also wanted to mention one interesting feature. OPENXML has no problems reading parents :
DECLARE
@xml XML
, @idoc INT
SELECT @xml = BulkColumn
FROM OPENROWSET(BULK 'D:\sample.xml', SINGLE_BLOB) x
EXEC sys.sp_xml_preparedocument @idoc OUTPUT, @xml
SELECT *
FROM OPENXML(@idoc, '/objects/obj/*')
WITH (
name SYSNAME '../@obj_name',
col SYSNAME '@name'
)
EXEC sys.sp_xml_removedocument @idoc
(5273 row(s) affected)
SQL Server Execution Times:
CPU time = 47 ms, elapsed time = 137 ms.
But you don’t need to think now that OPENXML has clear advantages over XQuery . In OPENXML too short stocks. For example, if we forget to call sp_xml_removedocument , then severe memory leaks may occur.
Everything was tested on SQL Server 2012 SP3 (11.00.6020) .
If you want to share this article with an English-speaking audience:
XML, XQuery & Performance Issues