The evolution of automatic testing in 1C: Enterprise
Before the release of the new version of the testing framework “xUnitFor1C” there is very little left, which means it's time to talk about the work done and what the users expect.
The release will be really major, there are a lot of changes, and they are global in nature. But first things first.
As I understand it, at the time when the project was just born, the main goal was to understand how unit testing can be in demand in the 1C environment. It is clear that to think over and highlight the levels of abstractions at the prototyping stage is not a very promising business. The prototype does not have the elasticity of this code. A prototype is an experiment whose results must be discarded.
Further, the development flag passed from one enthusiast to another, while the basic architecture remained the same. With the growing popularity of the product and the awareness of what I would like to receive, it has become increasingly difficult to make changes.
I like the metaphor of Alan Cooper:
The architecture that existed from the prototype was the same deviation on the 5th brick, which did not allow adding the new functionality that we wanted so much - testing in the BDD style, in particular, the use of Gherkin. It is believed that you need to choose one thing. Either TDD or BDD. Having worked on the principles of flexible testing, I realized that unit and scenario tests should not be opposed in any way, they are a great addition to each other!
This is how the flexible testing matrix looks:

Unit tests refer to quadrant 1 - low-level tests. Designed for the design of loosely coupled, flexible, testable architecture. They play the same role for the developer as the safety rope for the climber. Moreover, they are quite cheap in development and maintenance.
Scenario tests belong to quadrant 2 - tests of a higher level. We need to make sure that we correctly understand what needs to be done. This is the bridge between business and development, the ability to speak the same language. Great documentation that never expires. Moreover, they are more expensive to create and more fragile.
For me, so great synergy. I believe that to create high-quality software, you need to use both approaches together! Combined tests of both types provide excellent protection against regression.
It is completely redesigned. The tool has become much more flexible and easier to develop. Now this is not processing with 8.5k lines of code, now it is the kernel with a plug-in system. Yes, yes, there is no mistake, in 1C you can make a framework that will be expanded by plugins.
The plug-ins are external processing, located in the “Plugins” folder and implementing the following basic interface:
The plugin is accessed by identifier, for example:
The kernel’s work can now be roughly expressed as a single function: A reasonable question arises: “What kind of canonical test tree and test result?”. The canonical test tree allows you to build a universal “launcher” of test methods. Represents a tree-like data structure. Consists of nodes of the following types:
The canonical test result is very similar to the test tree with the difference that it contains additional information about the results of execution:
Building trees with tests is done by a special type of plugins called “Loader”. Typical bootloader scenario:
Loader API:
Function SelectPathInteractive (CurrentPath = "") - a client method for interactively choosing a path for loading tests;
Function Download (Kernel Context, Path) - search for test scripts and build a canonical test tree;
Function GetContextPoPath (Kernel Context, Path) - receiving a test context on the transmitted path.
Currently 3 basic bootloaders are implemented:
After the kernel has processed the test tree into a test result, it transfers it to another special type of the “Report Generator” plugin.
Report generators transform canonical test results into any other representation. For example, now implemented:
Report generator API:
Create Report function (Kernel Context, Test Results) - report generation in the format proposed by the plugin. Test results are transmitted to the plugin in a canonical format for the kernel;
The Show (Report) procedure is a client method for interactively displaying the generated report. The plugin itself determines how it is necessary to draw up a report for the user;
Export procedure (Report, Full File Path) - saves the report on the specified path, mainly used for CI purposes.
All sorts of “useful things” are of the “Utility” plugin type. As a rule, they perform a library or service function. For example, the BDD-style claims library is the BDD Claims plugin that I wrote about in my last article. “Serializer MXL” is a service plugin that serializes database data into moxel format and vice versa.
Before entering the main development trunk, the sources are available here .
Now it can be argued that the framework has grown from “just a tool for unit testing” to “a tool that allows you to cover almost all possible types of automatic testing”. It is modular, clearly divided into layers, and can be easily refined and expanded. It seems that the current name has ceased to convey the purpose of the product. Maybe it's time to change the name? If you have a good idea for a title, feel free to share.
The release will be really major, there are a lot of changes, and they are global in nature. But first things first.
Why should I cut everything?
As I understand it, at the time when the project was just born, the main goal was to understand how unit testing can be in demand in the 1C environment. It is clear that to think over and highlight the levels of abstractions at the prototyping stage is not a very promising business. The prototype does not have the elasticity of this code. A prototype is an experiment whose results must be discarded.
Further, the development flag passed from one enthusiast to another, while the basic architecture remained the same. With the growing popularity of the product and the awareness of what I would like to receive, it has become increasingly difficult to make changes.
I like the metaphor of Alan Cooper:
Creating a large program can be compared to building a pillar of brick. This pillar consists of thousands of bricks laid one on top of the other. A pillar can only be built if you lay bricks with great accuracy. Any deviation will cause the bricks to fall. If the brick with the number 998 can be deflected by five millimeters, the pillar will probably be able to withstand a thousand bricks, but if the deviation is on the 5th brick, the pillar will never be higher than three tens.
The architecture that existed from the prototype was the same deviation on the 5th brick, which did not allow adding the new functionality that we wanted so much - testing in the BDD style, in particular, the use of Gherkin. It is believed that you need to choose one thing. Either TDD or BDD. Having worked on the principles of flexible testing, I realized that unit and scenario tests should not be opposed in any way, they are a great addition to each other!
This is how the flexible testing matrix looks:
Unit tests refer to quadrant 1 - low-level tests. Designed for the design of loosely coupled, flexible, testable architecture. They play the same role for the developer as the safety rope for the climber. Moreover, they are quite cheap in development and maintenance.
Scenario tests belong to quadrant 2 - tests of a higher level. We need to make sure that we correctly understand what needs to be done. This is the bridge between business and development, the ability to speak the same language. Great documentation that never expires. Moreover, they are more expensive to create and more fragile.
For me, so great synergy. I believe that to create high-quality software, you need to use both approaches together! Combined tests of both types provide excellent protection against regression.
I’ll get ahead a bit and say that the BDD-style testing has not yet been implemented on the new engine, but the foundation is fully prepared. Scenario testing is the next step.
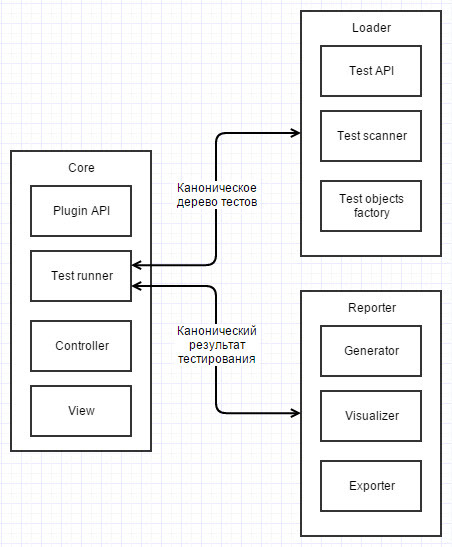
Architecture
It is completely redesigned. The tool has become much more flexible and easier to develop. Now this is not processing with 8.5k lines of code, now it is the kernel with a plug-in system. Yes, yes, there is no mistake, in 1C you can make a framework that will be expanded by plugins.
The plug-ins are external processing, located in the “Plugins” folder and implementing the following basic interface:
// { Plugin interface
Функция ОписаниеПлагина(ВозможныеТипыПлагинов) Экспорт
Результат = Новый Структура;
Результат.Вставить("Тип", ВозможныеТипыПлагинов.Утилита);
Результат.Вставить("Идентификатор", Метаданные().Имя);
Результат.Вставить("Представление", Метаданные().Синоним);
Возврат Новый ФиксированнаяСтруктура(Результат);
КонецФункции
// } Plugin interface
The plugin is accessed by identifier, for example:
НекийПлагин = КонтекстЯдра.Плагин("НекийПлагин");
The kernel’s work can now be roughly expressed as a single function: A reasonable question arises: “What kind of canonical test tree and test result?”. The canonical test tree allows you to build a universal “launcher” of test methods. Represents a tree-like data structure. Consists of nodes of the following types:
КаноническийРезультатТестирования = ВыполнитьТесты(КаноническоеДеревоТестов);
- container - serves for grouping purposes and may have subordinate nodes. Also for the container, you can specify the processing mode of the child nodes:
- random workaround - needed for unit tests, guarantees the independence of tests from each other and allows you to find all kinds of side effects;
- strict traversal order - needed for scenario tests, all child nodes will be processed in strict order. In addition, containers of this kind have an additional property “context”, access to which children and children have access to read and write.
- an element is essentially the metadata of the test method, which allows you to create a context and call the test method. It has the following basic properties:
- Path - a string that allows you to create an instance of an object from which you can call the test method;
- MethodName - the name of the test method that will be executed;
- Parameters - an array of parameters passed to the test method. The number and types of parameters must match the signature of the test method. Required for parameterized tests.
The canonical test result is very similar to the test tree with the difference that it contains additional information about the results of execution:
- For containers:
- State - the result of aggregation of states of child nodes;
- Statistics - the total number of tests in the container, the number of broken tests, the number of not implemented tests, the total execution time in ms.
- For items:
- Status - failed / passed / not implemented / broken;
- Lead time;
- Message - contains the text of the exception if the test is broken.
Where do canonical trees with tests come from and how does this contribute to universalization?
Building trees with tests is done by a special type of plugins called “Loader”. Typical bootloader scenario:
- The user selects the bootloader that he wants to use;
- Next, the path to search for test scenarios is determined (possibly interactively). In this case, the path is just a certain line that the selected bootloader can correctly interpret. For example, it can be a path in the file system or a path in the configuration metadata tree or ... anything;
- The selected path is used to search for test scenarios;
- According to the found scenarios, a test tree is formed for the kernel, while in the paths near the leaves of the tree some lines are indicated (similar to item 2), which the selected bootloader can correctly interpret;
- When tests are running, the kernel accesses the corresponding loader to resolve paths at the leaves of the tree.
Loader API:
Function SelectPathInteractive (CurrentPath = "") - a client method for interactively choosing a path for loading tests;
Function Download (Kernel Context, Path) - search for test scripts and build a canonical test tree;
Function GetContextPoPath (Kernel Context, Path) - receiving a test context on the transmitted path.
Currently 3 basic bootloaders are implemented:
- File Loader - the unit test loader from epf files. Uses file system file paths as paths;
- Directory Loader - built on top of the file loader. As a search path, takes the path to the file system directory. The rest relies entirely on a file downloader;
- Loader From Configuration Subsystem - uses the configuration metadata tree in a string representation as paths. For example, “Metadata. Processing. Test_Processing”. The test processing API borrows the file loader.
In the near future, we are planning to create a BDD Loader that will work with Gherkin feature files.
What to do with canonical test results?
After the kernel has processed the test tree into a test result, it transfers it to another special type of the “Report Generator” plugin.
Report generators transform canonical test results into any other representation. For example, now implemented:
- Report Generator MXL - moxel-format report, which is now used in interactive work with the tool;
- Report GeneratorJunitXML is a junit.xml report that is used in continuous integration (CI).
Report generator API:
Create Report function (Kernel Context, Test Results) - report generation in the format proposed by the plugin. Test results are transmitted to the plugin in a canonical format for the kernel;
The Show (Report) procedure is a client method for interactively displaying the generated report. The plugin itself determines how it is necessary to draw up a report for the user;
Export procedure (Report, Full File Path) - saves the report on the specified path, mainly used for CI purposes.
Useful
All sorts of “useful things” are of the “Utility” plugin type. As a rule, they perform a library or service function. For example, the BDD-style claims library is the BDD Claims plugin that I wrote about in my last article. “Serializer MXL” is a service plugin that serializes database data into moxel format and vice versa.
Afterword
Before entering the main development trunk, the sources are available here .
Now it can be argued that the framework has grown from “just a tool for unit testing” to “a tool that allows you to cover almost all possible types of automatic testing”. It is modular, clearly divided into layers, and can be easily refined and expanded. It seems that the current name has ceased to convey the purpose of the product. Maybe it's time to change the name? If you have a good idea for a title, feel free to share.