Development of acoustic dataset for neural network training
Once in an interview, one well-known Russian musician said: “We are working to lie and spit at the ceiling.” I can not disagree with this statement, because the fact that it is laziness that is the driving force in the development of technology cannot be disputed. And indeed, only in the last century we have moved from steam engines to digital industrialization, and now the artificial intelligence, about which science fiction writers and futurists of the last century have written, is becoming an increasing reality of our world every day. Computer games, mobile devices, smart watches and morebased on algorithms associated with machine learning mechanisms.
Nowadays, due to the growth of computing abilities of graphic processors and the large amount of data that has appeared, neural networks have become popular, using which they can solve classification and regression problems, teaching them using prepared data. There are already a lot of articles already written on how to train neural networks and what frameworks to use for this. But there is an earlier problem, which also needs to be solved, and this is the task of forming an array of data - dataset, for further training of the neural network. This will be discussed in this article.
Not so long ago there was a need to build an acoustic classifier of automobile noise capable of distinguishing from a general audio data stream: broken glass, opening doors and operating a car engine in various modes. The development of the classifier was not difficult, but where to get dataset to meet all the requirements?
Google came to the rescue (no offense to Yandex - I’ll speak about its advantages a little later), with the help of which it turned out to single out several main clusters containing the necessary data. I want to note in advance that the sources indicated in this article include a large amount of acoustic information, with various classes, allowing to form data for different tasks. We now turn to the review of these sources.
Freesound.org

Most likelyFreesound.org provides the largest amount of acoustic data, being a joint repository of licensed musical samples, which currently has more than 230,000 copies of sound effects. Each audio sample can be distributed under a different license, so it is better to get acquainted with the license agreement in advance . For example, a license of zero (cc0) has the status “Without copyright”, and allows you to copy, modify and distribute, including commercial use, and allows you to use the data absolutely legally.
For the convenience of finding elements of acoustic information in the freesound.org set, the developers have provided an APIdesigned to analyze, search and download data from repositories. To work with it, you need to gain access, for this you need to go to the form and fill in all the required fields, after which the generation of the individual key will take place.

The developers of freesound.org provide API for different programming languages, thus allowing to solve the same task with different tools. The list of supported languages and access links to them on GitHub are listed below.
Python was used to achieve the goal, since this beautiful programming language with dynamic typing gained its popularity due to its ease of use, completely crossing the myth about the complexity of software development.A module for working with freesound.org for python can be cloned from the github.com repository.
Below is the program code, which consists of two parts and demonstrates all the ease of use of this API. The first part of the program code performs the task of data analysis, the result of which is the density of data distribution for each requested class, and the second part unloads data from the repositories of freesound.org for selected classes. The distribution density when searching for acoustic information with the keywords glass, engine, door is presented below in a pie chart as an example.
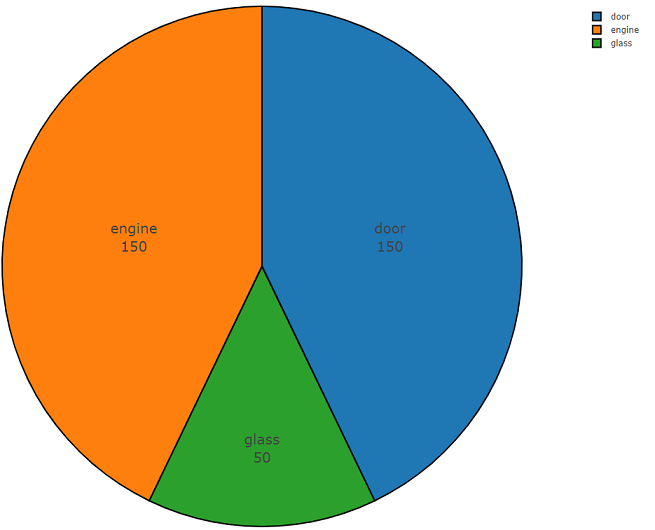
Sample code for analyzing freesound.org data
import plotly
import plotly.graph_objs as go
import freesound
import os
import termcolor
#Построение гистограммы в соответствии с даннымиdefhistogram(data, filename = "tmp_histogram.html"):
data = [
go.Histogram(
histfunc="count",
x=data,
name="count",textfont=dict(size=15)
),
]
plotly.offline.plot({
"data": data,
"layout": go.Layout(title="Histogram")
}, auto_open=True, filename=filename)
pass# Анализ запрашиваемых данных из пространства freesound.orgdeffreesound_analysis(search_tokens, output, lim_page_count = 1, key = None):
lim_page_count = int(lim_page_count)
try:
client = freesound.FreesoundClient()
client.set_token(key,"token")
print(termcolor.colored("Authorisation successful ", "green"))
except:
print(termcolor.colored("Authorisation failed ", "red"))
classes = list()
for token in search_tokens:
try:
results = client.text_search(query=token,fields="id,name,previews")
output_catalog = os.path.normpath(output)
ifnot os.path.exists(output_catalog):
os.makedirs(output_catalog)
page_count = int(0)
whileTrue:
for sound in results:
try:
classes.append(token)
info = "Data has been getter: " + str(sound.name)
print(termcolor.colored(info, "green"))
except:
info = "Data has not been getter: " + str(sound.name)
print(termcolor.colored(info, "red"))
page_count += 1if (not results.next) or (lim_page_count == page_count):
page_count = 0break
results = results.next_page()
except:
print(termcolor.colored(" Search is failed ", "red"))
histogram(classes)
passSample code to download freesound.org data
#Скачивание запрашиваемых данных deffreesound_download(search_tokens, output, lim_page_count = 1, key = None):
lim_page_count = int(lim_page_count)
#Попытка подключения клиента. Необходимо указать полученный ключtry:
client = freesound.FreesoundClient()
client.set_token(key,"token")
print(termcolor.colored("Authorisation successful ", "green"))
except:
print(termcolor.colored("Authorisation failed ", "red"))
for token in search_tokens:
try:
results = client.text_search(query=token,fields="id,name,previews")
output_catalog = os.path.normpath(output + "\\" + str(token))
ifnot os.path.exists(output_catalog):
os.makedirs(output_catalog)
page_count = int(0)
whileTrue:
for sound in results:
try:
sound.retrieve_preview(output_catalog)
info = "Saved file: " + str(output_catalog) + str(sound.name)
print(termcolor.colored(info, "green"))
except:
info = str("Sound can`t be saved to " + str(output_catalog) + str(sound.name) )
print(termcolor.colored(info, "red"))
page_count += 1ifnot results.next or lim_page_count == page_count:
page_count = 0break
results = results.next_page()
except:
print(termcolor.colored(" Search is failed ", "red"))
A feature of freesound is that sound data can be analyzed without downloading an audio file, allowing you to get MFCC, spectral energy, spectral centroid, and other factors. More information about lowlevel information can be found in the freesound.ord documentation .
Using the freesound.org API, the time spent on sampling and uploading data is minimized, saving working hours on exploring other sources of information, since high accuracy of the acoustic classifier requires a large dataset with high variability, representing data with different harmonics on one and same class of events.
YouTube-8M and AudioSet

I think that youtube is not particularly required in the submission, but still Wikipedia tells us that youtube is a video hosting site that provides video services to users, forgetting to say that youtube is a huge database, and this source just needs to be used in machine learning and Google Inc provides us with a project called YouTube-8M Dataset .
YouTube-8M Dataset is a data set that includes more than a million video files from YouTube in high quality. If you give more accurate information, then by May 2018 there were 6.1M videos with 3862 classes. This dataset is distributed under the Creative Commons Attribution 4.0 International (CC BY 4.0) license.. This license allows you to copy and distribute material in any medium and format.
You are probably wondering: where is the video data, when acoustic information is needed for the task, and you will be very right. The fact is that Google provides not only video content, but also separately allocated a subproject with audio data called AudioSet .
AudioSet - provides a set of data obtained from YouTube clips, where a set of data is represented in the class hierarchy, using an ontology file , its graphical representation is located below.
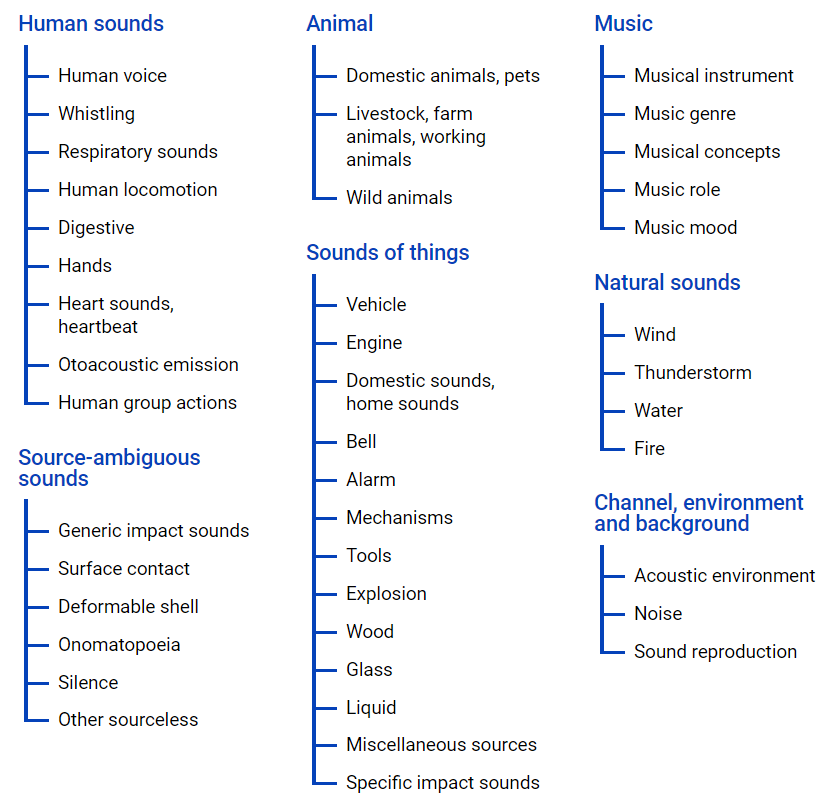
This file allows you to get an idea of the nesting of classes, as well as access to youtube videos. To upload data from the Internet space, you can use the python module - youtube-dl, which allows you to download audio or video content, depending on the required task.
AudioSet is a cluster divided into three sets: test, training (balanced) and training (unbalanced) datasets .
Let's consider this cluster and analyze each of the sets separately in order to have an idea of the classes contained.
Training (balanced)
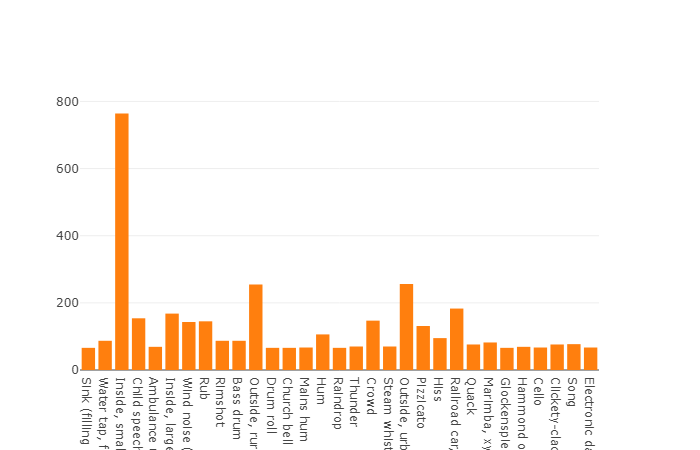
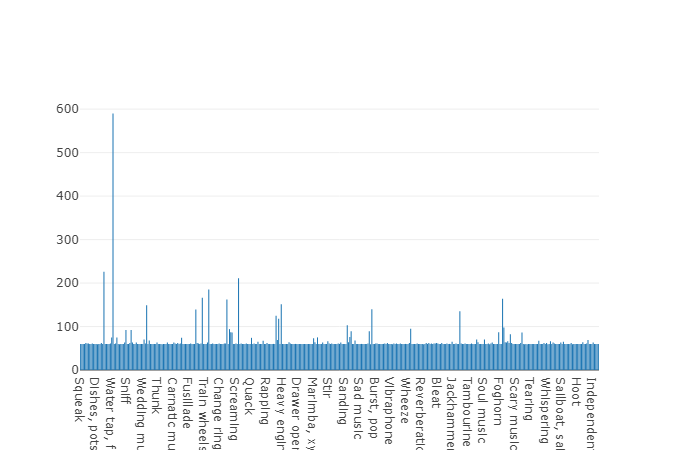
According to the documentation this dataset consists of 22,176 segmentsretrieved from various videos selected by keywords, providing each class with at least 59 copies. If you look at the density distribution of the root classes in the hierarchy of the set, then we see that the largest group of audio files is represented by the Music class.
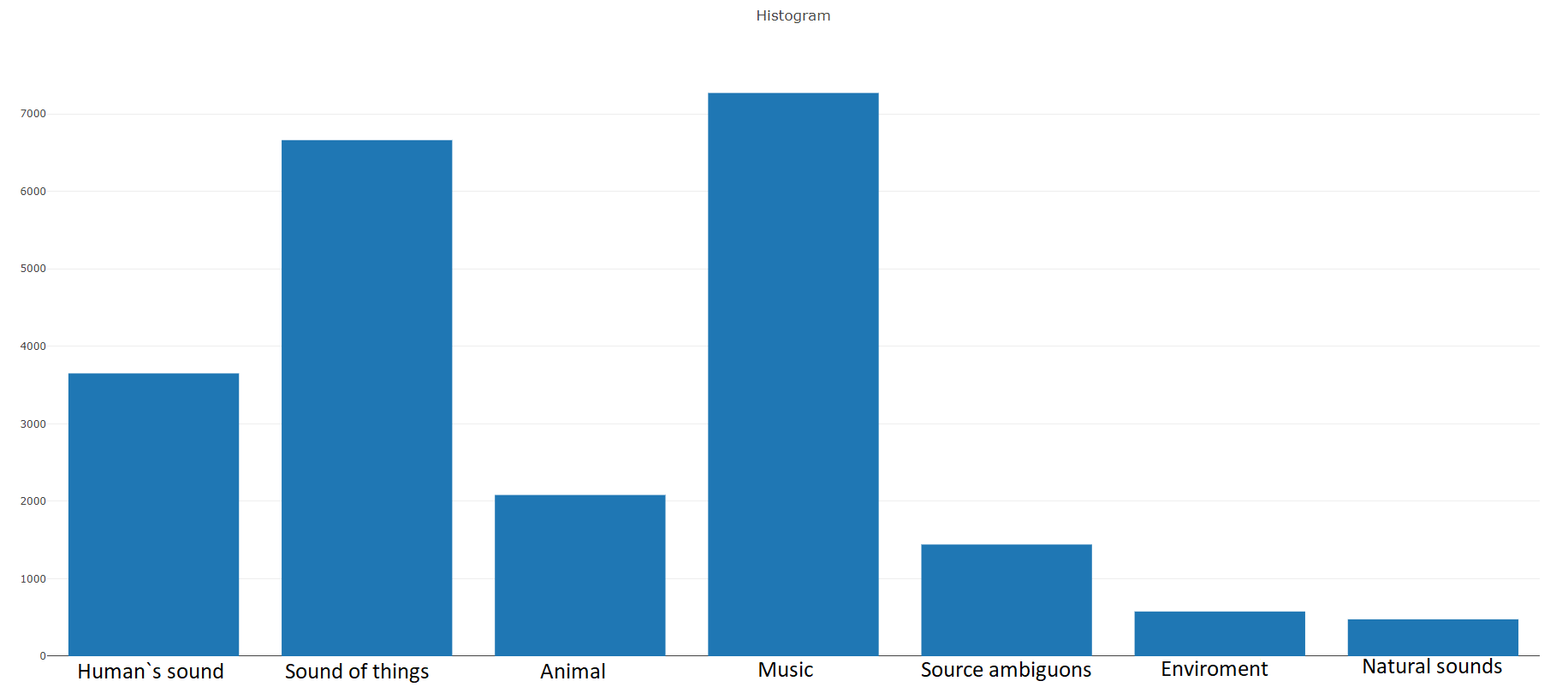
Organized classes are decomposed into subsets of classes, making it possible to obtain more detailed information when used. This balanced training set has a distribution density which shows that there is a balance, but also some classes stand out from the general view.
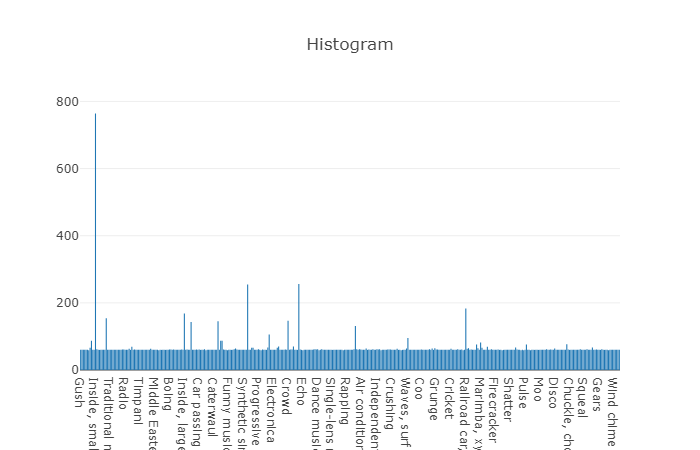
The distribution of classes, the number of elements which exceeds the average value
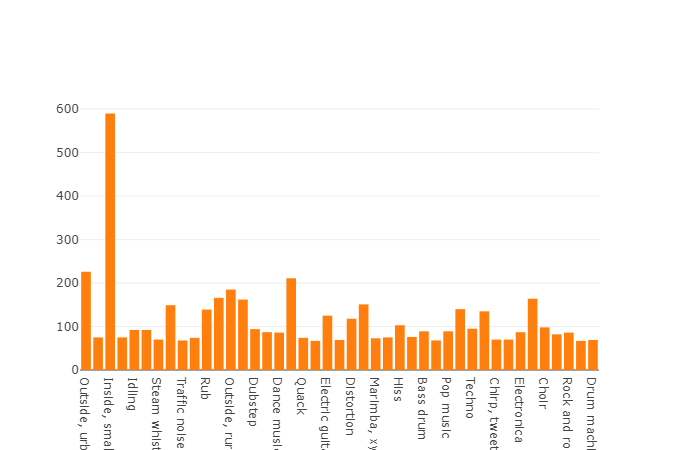
The average duration of each of the audio files is 10 seconds, more detailed information is presented on the disk diagram, which shows that the length of the part of the files differs from the main set. This diagram is also presented.
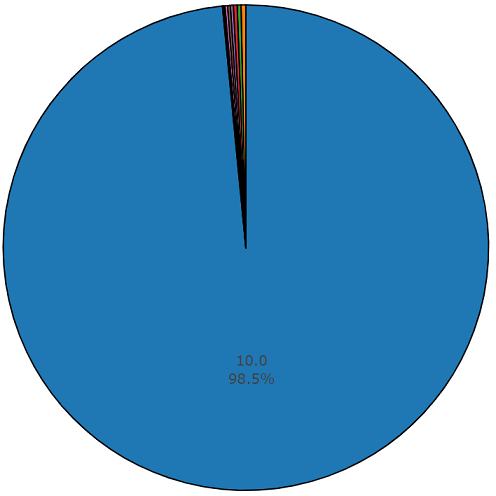
Diagram of the duration of one and a half percent, other than the average value, from a balanced set of audio sets.
Training (unbalanced)
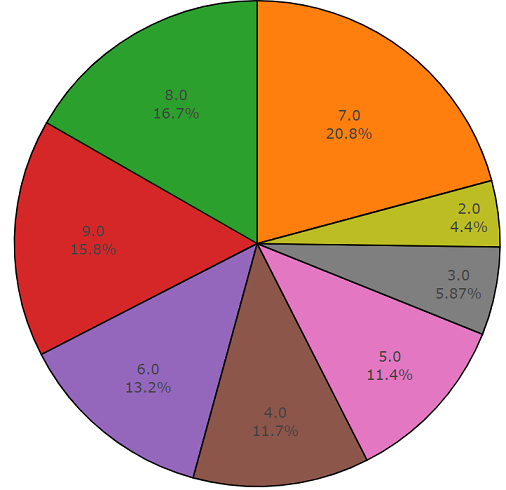
The advantage of this dataset is its size. Just imagine that, according to the documentation, this set includes 2,042,985 segments and in comparison with the balanced datasets represents a large variability, but the entropy of this set is much higher.
In this set, the average duration of each of the audio files is also equal to 10 seconds, the disk diagram for this dataset is presented below.
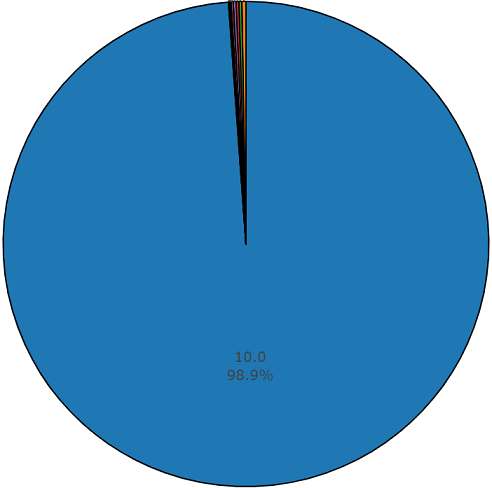
Duration diagram, other than the average, from an unbalanced audioset set
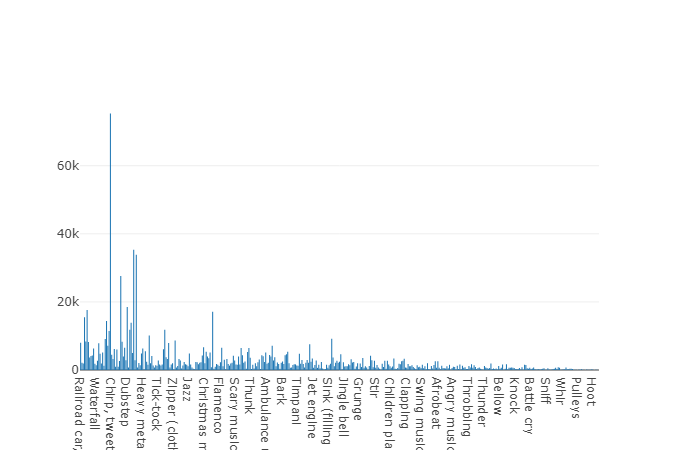
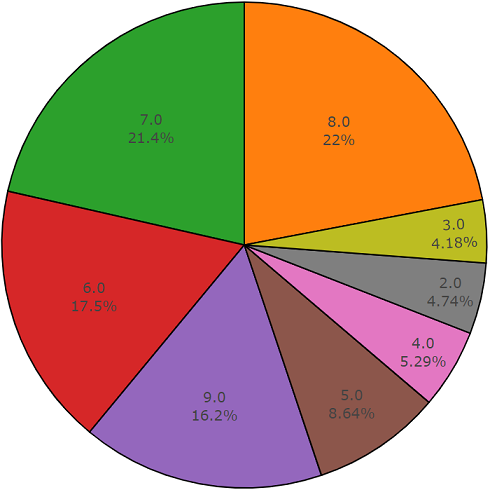
Test set
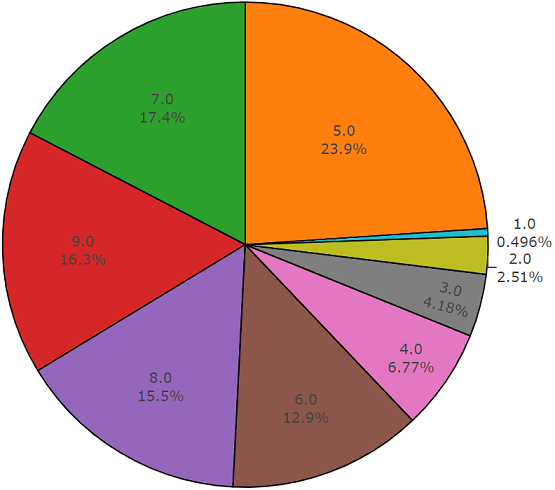
This set is very similar to a balanced set with the advantage that the elements of these sets do not overlap. Their distribution is presented below.
The distribution of classes whose number of elements exceeds the average value.
The average duration of one segment from a given dataset is also equal to 10 seconds
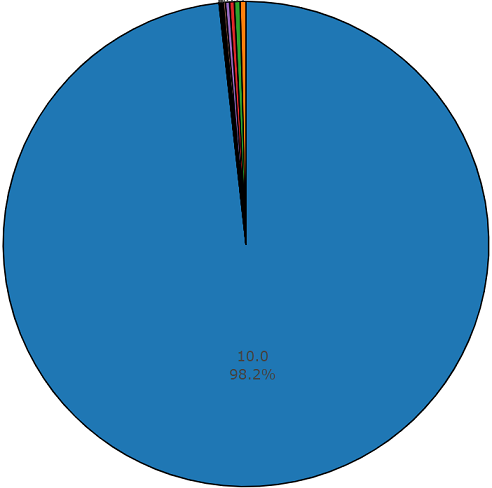
and the remaining part has a duration represented on the disk diagram.
An example of program code for analyzing and downloading acoustic data in accordance with the selected data set:
import plotly
import plotly.graph_objs as go
from collections import Counter
import numpy as np
import os
import termcolor
import csv
import json
import youtube_dl
import subprocess
#Построение гистограммы в соответствии с даннымиdefhistogram(data,hist_mean= True, filename = "tmp_histogram.html"):if hist_mean == True:
cdata = Counter(data)
mean_number_classes = np.asarray([cdata[x] for x in cdata]).mean()
ldata = list()
for name in cdata:
if cdata[name] > mean_number_classes:
ldata += list(Counter({name:cdata[name]}).elements())
trace_mean_data = go.Histogram(histfunc="count", x=ldata, name="count" )
trace_data = go.Histogram(histfunc="count", x=data, name="count", text="" )
trace = [ trace_data, trace_mean_data]
plotly.offline.plot({
"data": trace,
"layout": go.Layout(title="stack")
}, auto_open=True, filename=filename)
pass#Построение круговой диаграммы в соответствии с даннымиdefpie_chart(labels, values = None, filename = "tmp_pie_chart.html", textinfo = 'label+value'):if labels == None:
raise Exception("Can not create pie chart, because labels is None")
if values == None:
data = Counter(labels)
labels = list()
values = list()
for name in data:
labels.append(name)
values.append(data[name])
trace = go.Pie(labels=labels, values=values,textfont=dict(size=20),hoverinfo='label+percent', textinfo=textinfo,
marker=dict(line=dict(color='#000000', width=2))
)
plotly.offline.plot([trace], filename='basic_pie_chart')
pass#Анализ данных в соответствии с файлом онтологии и выбранного датасетаdefaudioset_analysis(audioset_file, inputOntology):ifnot os.path.exists(inputOntology) ornot os.path.exists(audioset_file):
raise Exception("Can not found file")
with open(audioset_file, 'r') as fe:
csv_data = csv.reader(fe)
sx = list()
with open(inputOntology) as f:
data = json.load(f)
duration_hist = list()
for row in csv_data:
if row[0][0] == '#':
continue
classes = row[3:]
try:
color = "green"
tmp_duration = str(float(row[2]) - float(row[1]))
info = str("id: ") + str(row[0]) + str(" duration: ") + tmp_duration
duration_hist.append(tmp_duration)
for cl in classes:
for dt in data:
cl = str(cl).strip().replace('"',"")
if cl == dt['id'] and len(dt['child_ids']) == 0:
sx.append(dt['name'])
info += str(" ")+str(dt['name']) + str(",")
except:
color = "red"
info = "File has been pass: " + str(row[0])
continue
print(termcolor.colored(info, color))
histogram(sx, filename="audioset_class")
pie_chart(duration_hist, textinfo="percent + label", filename="audioset_duration")
#Скачивание файла из youtubedefyoutube_download(filepath, ytid):
ydl_opts = {
'format': 'bestaudio/best',
'outtmpl': os.path.normpath(filepath),
'postprocessors': [{
'key': 'FFmpegExtractAudio',
'preferredcodec': 'wav',
'preferredquality': '192',
}],
}
with youtube_dl.YoutubeDL(ydl_opts) as ydl:
ydl.download(['https://www.youtube.com/watch?v={}'.format(ytid)])
pass#Обрезание файла с использованием ffmpegdefcutOfPartFile(filename,outputFile, start, end, frequency = 44100):
duration = float(end) - float(start)
command = 'ffmpeg -i '
command += str(filename)+" "
command += " -ar " + str(frequency)
command += " -ss " + str(start)
command += " -t " + str(duration) + " "
command += str(outputFile)
subprocess.call(command,shell=True)
pass#Преобразование выгруженных файлов из yotube к виду в соответствии с файлом датасетаdefaudioset_converter(incatalog,outcatalog, token = "*.wav", frequency = 44100):
find_template = os.path.join(incatalog,token)
files = glob(find_template);
for file in files:
_,name = os.path.split(file)
name = os.path.splitext(name)[0]
duration = str(name).split("_")[1:3]
filename = name.split("_")[0] +"."+ token.split(".")[1];
outfile = os.path.join(outcatalog,filename)
cutOfPartFile(file,outfile,start=duration[0],end=duration[1])
#Скачивание соответствующего датасета из audiosetdefaudioset_download(audioset_file, outputDataset, frequency = 44100):
t,h = os.path.split(audioset_file)
h = h.split(".")
outputDataset_full = os.path.join(outputDataset,str(h[0])+"_full")
outputDataset = os.path.join(outputDataset,str(h[0]))
ifnot os.path.exists(outputDataset):
os.makedirs(outputDataset)
ifnot os.path.exists(outputDataset_full):
os.makedirs(outputDataset_full)
with open(audioset_file, 'r') as fe:
csv_data = csv.reader(fe)
duration_hist = list()
for row in csv_data:
if row[0][0] == '#':
continuetry:
color = "green"
tmp_duration = str(float(row[2]) - float(row[1]))
info = str("id: ") + str(row[0]) + str(" duration: ") + tmp_duration
duration_hist.append(tmp_duration)
save_full_file = str(outputDataset_full) + str("//")+ str(row[0]).lstrip()+str("_") +str(row[1]).lstrip() + str("_").lstrip() + str(row[2]).lstrip() + str('.%(ext)s')
youtube_download(save_full_file,row[0])
except:
color = "red"
info = "File has been pass: " + str(row[0])
continue
print(termcolor.colored(info, color))
audioset_converter(outputDataset_full,outputDataset, frequency = frequency)
For more detailed information on analyzing the audioset data, or downloading this data from the yotube space in accordance with the ontology file and the selected audioset set , the program code is freely available in the GitHub repository .
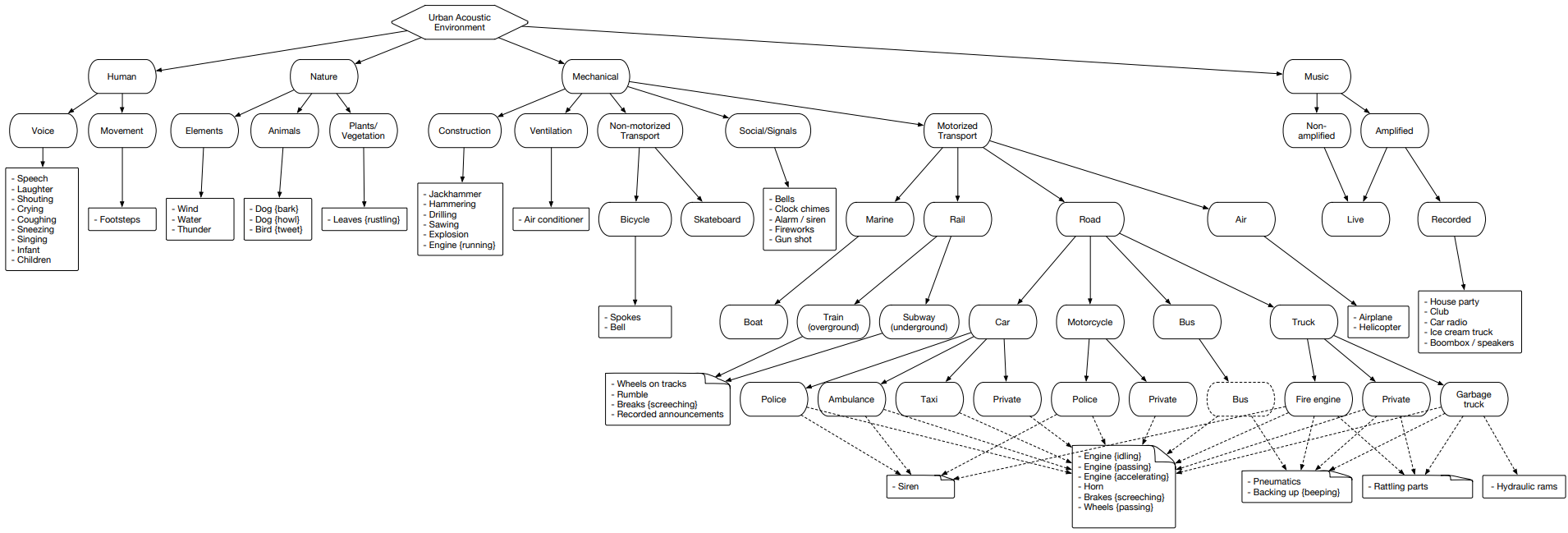
urbansound
Urbansound is one of the largest datasets with markup sound events whose classes belong to the urban environment. This set is called taxonomic (categorical), i.e. each class is divided into subclasses belonging to it. Such a set can be represented as a tree.
To unload urbansound data for later use, simply go to the page and click download..
Since there is no need to use all subclasses in the task, but only a single class associated with the car is needed, it is first necessary to filter the necessary classes using the meta file located in the root of the directory obtained when unzipping the downloaded file.
After unloading all the necessary data from these sources, it turned out to form a dataset containing more than 15,000 files. This amount of data allows you to go to the task of learning the acoustic classifier, but there remains an unsolved question regarding the “purity” of the data, i.e. training set includes data not related to the necessary classes of the problem to be solved. For example, when listening to files from the “broken glass” class, you can find people talking about “how not to beat the glass well”. Therefore, we face the task of filtering data and as a tool for solving this kind of problem, the tool, the core of which was developed by Belarusian guys and received the strange name “Yandex.Toloka”, is excellent.
Yandex.Toloka

Yandex.Toloka is a crowdfunding project created in 2014 to mark up or collect a large amount of data for further use in machine learning. In fact, this tool allows you to collect, mark up and filter data using a human resource. Yes, this project not only allows you to solve problems, but also allows other people to earn. The financial burden in this case falls on your shoulders, but due to the fact that the performers are more than 10,000 interpreters, the results of the work will be obtained in the near future. A good description of the work of this tool can be found in the Yandex company blog .
In general, the use of toloki is not particularly difficult, since only a registration on the site is necessary for publication of the assignment, the minimum amount of 10 US dollars, and properly executed task. How to formulate a task correctly, you can see the Yandex.Tolok documentation or there is not a bad article on Habré . From myself, I want to add to this article that even if the template does not fit the requirement of your task, it will take no more than a few hours to develop it, with a break for coffee and a cigarette, and the performers can be obtained by the end of the working day.
Conclusion
In machine learning in solving the problem of classification or regression, one of the primary tasks is the development of a reliable data set - dataset. This article examined the sources of information with a large amount of acoustic data allowing to form and balance the required data set for a specific task. The presented program code allows you to simplify the operation of uploading data to a minimum, allowing you to reduce the time to receive data and spend the rest on the development of the classifier.
As for my task, after collecting the data, from all the sources presented in this article and the subsequent filtering of the data, it was possible to form the necessary data for learning the acoustic classifier based on the neural network. I hope that this article will allow you and your team to save time and spend it on the development of new technologies.
PS A software module developed in python, for analyzing and uploading acoustic data for each of the submitted sources, you can find it in the github repository